论文阅读-Self-Supervised Video Forensics by Audio-Visual Anomaly Detection-音视频异常检测
一、论文信息
论文名称:Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
作者单位:
Github: https://cfeng16.github.io/ audio-visual-forensics.
二、动机与创新
动机:
被操纵的视频通常包含视觉和音频信号之间的微妙不一致,并且很难收集捕获所有可能操作的大型带标签的数据集。为检测被操纵的视频,本文作者提出了检测同步特征的异常。
创新:
-
提出一种通过异常检测识别被操纵视频的方法,训练自回归生成模型来标记概率很低的视频。
-
仅使用真实的未标记数据训练模型,以了解音视频是如何共现的,测试时,模型标记的低概率视频即为假视频。
-
测试时的测试集可以为不同的说话人。(以前的方法的测试集都是在训练集基础上做一些数据增强得到)
三、方法
问题定义:异常检测,寻找视频中视觉和音频信号之间的不一致性。
具体采用基于异常检测的方法对视听示例分布进行建模。
同步特征提取过程如 (a) 所示,首先从视听同步的网络中提取特征:视频帧与音频之间的延迟帧数、每帧的延迟分布、来自视听子网的特征激活;(b)训练了一个自回归Transformer模型,将概率分配给同步特征,如果该特征概率很小,同时标记低概率的例子。让模型学习在特征集上的分布,该特征集携带了在被操纵的视频中不太可能被捕获的微妙属性。
1、估计视听同步
首先从视听同步网络中获得特征:
![]()
以上指示的是视频片段和音频片段暂时同时出现的可能性,总和取的是时间窗口内所有视频片段的总和,估计了所有视听对在时间窗口的同步分数(同步概率)。
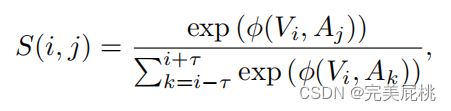
其中τ是两个流之间的最大时间差。其中,
![]()
上式是使用后融合的方式去融合的音视频特征。
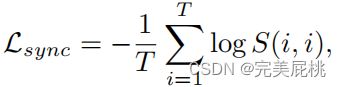
该方法利用 InfoNCE 损失最大限度地提高了真实视听配对的同步。
训练后,该方法可用于获得用于异常检测的特征集,该特征集提供视频片段和音频之间可能的对齐的概率分布。
2、视听异常检测
通过检测音频和视频信号之间的不一致性来识别被操纵的视频,该方法使用自回归模型生成一系列视听特征,这些特征捕捉了视频帧和声音之间的时间同步。
为了了解每个帧的特征分布,给定每一帧的特征,学习到一个概率分布:
![]()
又使用自回归模型,学习这个分布,对复杂分布进行建模。
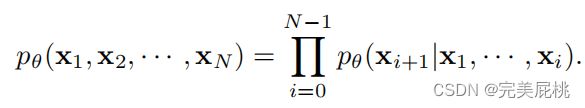
之后训练了一个模型根据之前所有帧的特征去估计下一帧的特征,这些模型采用条件概率乘积的形式,其中每个特征都以先前的特征为条件。该方法根据前一帧的所有特征,训练模型以估计下一个帧的特征。通过最小化每帧损失函数来最大化对数概率。
3、离散时间延迟
使用基于离散时间延迟的特征表示,离散时间延迟是根据每个视频帧与音频信号的前后距离来估算的。选择概率最高的时间延迟作为每帧的特征。并使用交叉熵损失来训练模型。
![]()
4、延迟分布
离散时间延迟在模型中很容易表示,但是当延迟存在歧义时,会丢弃重要信息。因此,所提出的模型直接预测时延分布的条目以捕捉这种歧义。特征 xi 设置为 S 的行,即每种可能延迟的概率。该模型使用交叉熵损失来计算预测概率和实际概率之间的差异。
5、视听网络激活
视听同步网络提供有关视频中音频和视频信号之间的时间延迟的信息。将视觉和音频子网的特征表示 gv 和 ga 连接起来,为了与timedelay模型比较,通过将特征投影到前2τ+ 1 主成分来降低特征的维度。
四、实验
1、同步模型:
视觉编码器:ResNet18 2D+3D;音频编码器:VGG-M
2、异常检测模型:
使用了两个Transformer的解码器学习同步特征的分布。
3、数据集:
训练集(都是真实视频):
Lip Reading Sentences 2 (LRS2, 97k videos)和Lip Reading Sentences 3 (LRS3, 120k videos)
验证集:FakeAVCeleb
4、实验结果(平均精确度AP和AUC):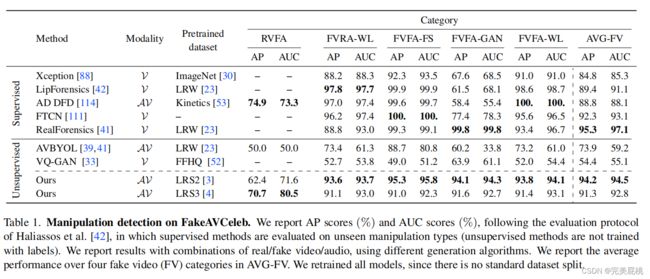 该表显示了 FakeavCeleb 上操作检测任务的 AP 和 AUC 分数。分数以百分比形式报告,并显示真实和虚假视频和音频的不同组合的结果。该表还显示了四个虚假视频类别的平均表现。结果表明,即使仅根据真实的未标记数据进行训练,所提出的方法在检测被操纵的视频方面也表现良好,并且具有良好的泛化和鲁棒性。
该表显示了 FakeavCeleb 上操作检测任务的 AP 和 AUC 分数。分数以百分比形式报告,并显示真实和虚假视频和音频的不同组合的结果。该表还显示了四个虚假视频类别的平均表现。结果表明,即使仅根据真实的未标记数据进行训练,所提出的方法在检测被操纵的视频方面也表现良好,并且具有良好的泛化和鲁棒性。
附录:
视听同步模型两阶段:第一阶段负样本来自不同视频;第二阶段负样本在相同视频中随机采样。