panbas学习篇(一)数据的聚合,最大值最小值标准差分位数数据透视表 交叉表
最大值最小值
Series.sum : Return the sum.
Series.min : Return the minimum.
Series.max : Return the maximum.
Series.idxmin : Return the index of the minimum.
Series.idxmax : Return the index of the maximum.
DataFrame.sum : Return the sum over the requested axis.
DataFrame.min : Return the minimum over the requested axis.
DataFrame.max : Return the maximum over the requested axis.
DataFrame.idxmin : Return the index of the minimum over the requested axis.
DataFrame.idxmax : Return the index of the maximum over the requested axis.
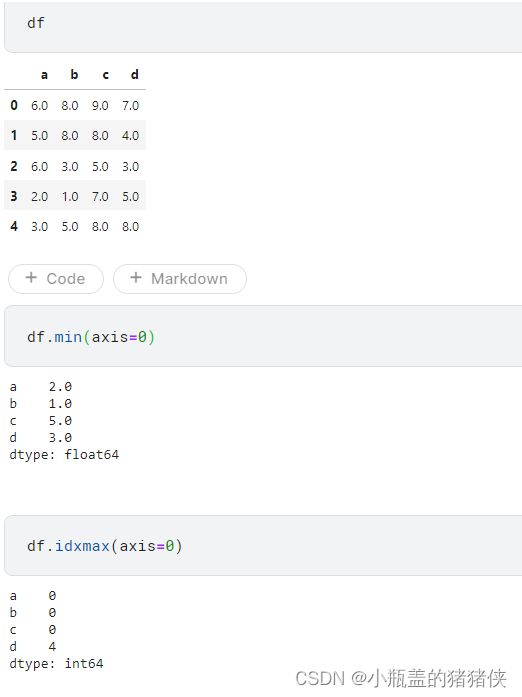
求标准差
DataFrame.std(axis=None,ddof=1)
求标准差

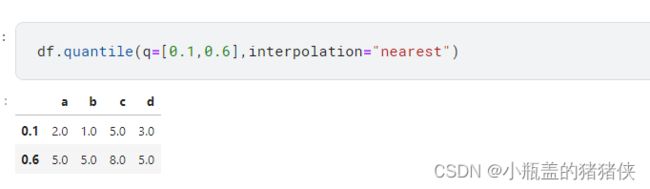
分位数
DataFrame.quantile(q=0.5,axis=1,interpolation: str = "linear",)
其中interpolation :取值包括{‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}
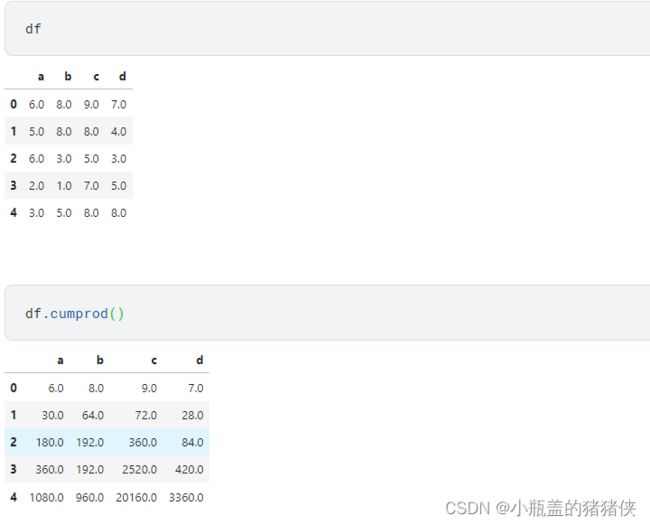
累计求和、累计求积
DataFrame.cumsum(axis=None, skipna=True, *args, **kwargs)
DataFrame.cumprod(axis=None, skipna=True, *args, **kwargs)
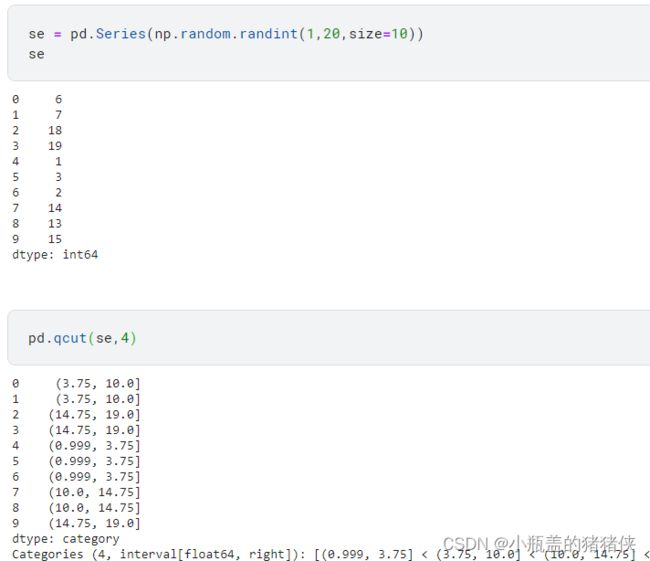
分箱处理
pandas.cut(x,bins,right=True,labels=None)
bins中的数据需要包含x中的最大值和最小值,不然不在bins中的数据就会被分为了
NaN值。

pandas.qcut(x,q,labels=None,rebins=False)
基于分位数来做分割的, q : int or list-like of float Number of quantiles. 10 for deciles, 4 for quartiles, etc. Alternately array of quantiles, e.g. [0, .25, .5, .75, 1.] for quartiles.
数据透视表
pandas.pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')


交叉表
pd.crosstab(index, columns, values=None, rownames=None,
colnames=None, aggfunc=None, margins=False,
margins_name: str = 'All', dropna: bool = True,
normalize=False)
index:类数组,在行中按分组的值。
columns:类数组的值,用于在列中进行分组。
values:类数组的,可选的,要根据因素汇总的值数组。
aggfunc:函数,可选,如果未传递任何值数组,则计算频率表。
rownames:序列,默认为None,必须与传递的行数组数匹配。
colnames:序列,默认值为None,如果传递,则必须与传递的列数组数匹配。
margins:布尔值,默认为False,添加行/列边距(小计)
normalize:布尔值,{‘all’,‘index’,‘columns’}或{0,1},默认为False。 通过将所有值除以值的总和进行归一化。
