java中的UTF-16编码详解,什么是码点?什么是字符?
文章目录
- 说明
- UTF-16编码说明
- 码点和字符
- java中UTF-16
- 自己实现UTF-16编码规则
- 为什么java9中的String使用byte数组
- 总结
说明
我想大家应该都知道在java中的编码是UTF-16,但是细节不是很清楚,这里就来对UTF-16编码进行详细的说明。
UTF-16编码说明
每一个符号都对应一个唯一的码点。UTF-16的编码分为2个部分,码点值小于65536的编码成为1个16位值,也就是2个byte。其他就编码为2个16位值,也就是4个byte。
我这里着重讲一下
码点小于65536就直接转换了,没什么好说明的,这里说一下大于等于65536的
下面就给出了码点大于等于65536的计算过程

图片来自于https://www.bilibili.com/video/BV13U4y1y7LP中的截图
以为例子,的码点为128519,计算过程如下
- 码点值记为x,那么x的范围为[65536,1114111] ,65536表示0x10000 1114111表示0x10FFFF
- x` = x - 65536,所以实际值为 62983
- x` 转换为20位的二进制数字,不够补0 值为 0000 1111 0110 0000 0111
- 取出前10个比特,与0xD800相加,0000 1111 01转换为16进制为 0x003D,0x003D + 0xD800 = 0xD83D
- 取出后10个比特,与0xDC00相加,10 0000 0111转换为16进制为 0x0207,0x0207 + 0xDC00 = 0xDE07
- 二者合并,D8 3D DE 07,这就是最后UTF-16的编码。前10位产生的值称为高位代理项,后10位称为低位代理项
如果我们将符号复制进入idea的字符串,就会自动转换为如下情形
//
String s = "\uD83D\uDE07";
这个字符串中的2个字符也就和我们上面算出的结果相同了
细心的人应该发现了0xD800和0xDC00相差了0x0400,也就是 0100 0000 0000, 刚好比 0011 1111 1111多1,也就是说高位代理项和低位代理项不会重复。系统仅凭一个字符就能够判断是高位代理项还是低位代理项
说明. 需要说明的是在 [0xD800,0xDFFF]中的码点未定义任何字符,专用于UTF-16的代理项 0xD800就是高位相加的最小值,最小值就是0xD800 + 0x0000 = 0xD800. 0xDFFF就是低位相加的最大值,最大值就是0xDC00 + 0x03FF = 0xDFFF
码点和字符
在java中,字符char就只能够表示0~65535的Unicode字符,如果大于了65535,就使用2个字符进行存储。每一个字符都存在一个对应的码点(Unicode编码值),而码点可能对应着1个或2个字符。
- char对应的是一个UTF-16的代码单元
- char对应的不是一个Unicode字符
// 你好啊
String s = "你好啊\uD83E\uDD92";
// 返回的是char字符个数 5
System.out.println(s.length());
// 返回的是码点个数 4
System.out.println(s.codePointCount(0, s.length()));
// 并不能获取到
System.out.println(s.charAt(3));
// 获取
System.out.println("" + s.charAt(3) + s.charAt(4));
// 可以获取到所有的码点
IntStream intStream = s.codePoints();
java中UTF-16
在java中,char类型就只有是2个字节,所以就只能存储0~65535,所以一些字符使用一个char表示,一些字符使用2个char表示。就是使用2个char来进行表示,分别就是 \uD83D 和 \uDE07
我们都知道,在java中的String底层是使用char数组来进行存储的,我们来看一下,你好啊 是怎么存储的
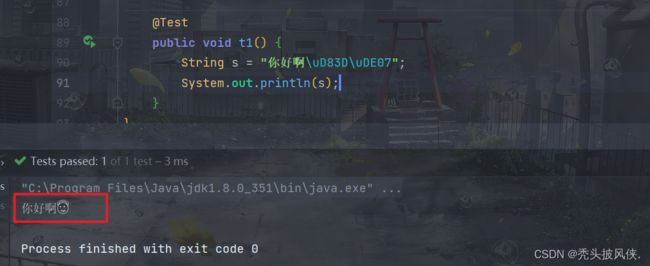
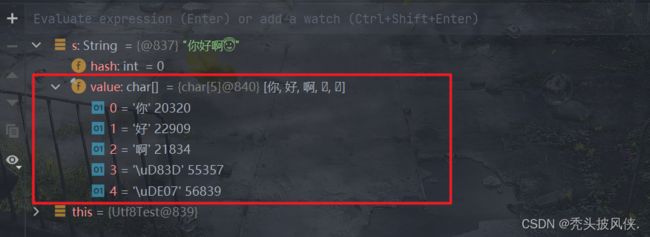
可以发现码点值大于等于65536的确实是使用2个字符来进行存储的。码点值经过转换变为了2个小于65536的值
相信大家还是很模糊,想要弄清楚还是得要自己按照规则写一个UTF-16转换的代码。大家根据下面的规则来进行编写,要求就是写2个方法,分别完成如下功能
/**
* 传入一个码点,返回码点对应的字符
* @param codePoint 码点
* @return 返回码点对应的字符
*/
public static String resolveCodePoint(int codePoint);
/**
* 传入一个字符串,返回字符串中每个字符的码点
* @param s 字符串
* @return 一个集合,里面包含了该字符串中所有字符的码点
*/
public static List<Integer> strToCodePoints(String s);
如果大家可以独自完成这2个功能,那么对应UTF-16就掌握的差不多了。如果毫无思路,那么就再去上面看看转换的例子。
自己实现UTF-16编码规则
下面就是对resolveCodePoint方法的实现
/**
* 传入一个码点,返回码点对应的字符
* @param codePoint 码点
* @return 返回码点对应的字符
*/
public static String resolveCodePoint(int codePoint) {
if (codePoint < 65536) {
return "" + (char) codePoint;
}
// 1. 码点值记为x,那么x的范围为[65536,1114111] 65536表示0x10000 1114111表示0x10FFFF
int x = codePoint;
// 2. x` = x - 65536
x -= 65536;
// 3. x` 转换为20位的二进制数字,不够补0
StringBuilder binaryString = new StringBuilder(Integer.toBinaryString(x));
int fillCount = 20 - binaryString.length();
for (int i = 0; i < fillCount; i++) {
binaryString.insert(0, 0);
}
// 4. 取出前10个比特,与0xD800相加
String high = binaryString.substring(0, 10);
int highValue = Integer.parseInt(high, 2) + 0xD800;
// 5. 取出后10个比特,与0xDC00相加
String low = binaryString.substring(10);
int lowValue = Integer.parseInt(low, 2) + 0xDC00;
// 6. 二者合并
return "" + (char) highValue + (char) lowValue;
}
这个代码可以完成输入一个码点,返回对应的Unicode字符。
写完代码肯定要测试一下,测试内容如下
@Test
public void test() {
// ㊎㊍㊌㊋㊏
String s = "\uD83D\uDEA9 \uD83D\uDC12 \uD83E\uDD81 \uD83E\uDD92㊎㊍㊌㊋㊏";
System.out.println(s);
System.out.println("---------解析开始-------");
// s.codePoints()会返回所有的码点
s.codePoints().forEach(x->{
System.out.print(resolveCodePoint(x));
});
}
输出如下
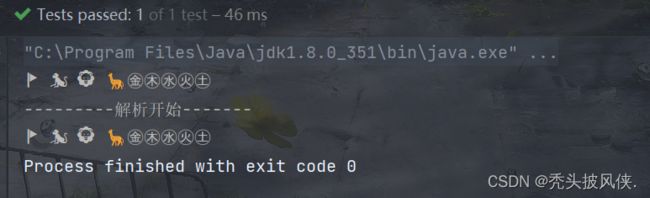
下面是对strToCodePoints的实现
/**
* 传入一个字符串,返回字符串中每个字符的码点
*
* @param s 字符串
* @return 一个集合,里面包含了该字符串中所有字符的码点
*/
public static List<Integer> strToCodePoints(String s) {
// 代理项的范围
int highStart = 0xD800;
int lowStart = 0xDC00;
int lowEnd = 0xDFFF;
// 返回的码点集合
List<Integer> list = new ArrayList<>();
int highV = 0;
// 循环判断每一个字符
for (char c : s.toCharArray()) {
int k = c;
if (k >= highStart && k < lowStart) {
// 高位代理项
highV = k - highStart;
highV <<= 10;
} else if (k >= lowStart && k <= lowEnd) {
// 低位代理项
k -= lowStart;
list.add(k + highV + 65536);
} else {
// 没有进行代理
list.add(k);
}
}
return list;
}
测试程序如下
@Test
public void testStrToCodePoints() {
// ㊎㊍㊌㊋㊏
String s = "\uD83D\uDEA9 \uD83D\uDC12 \uD83E\uDD81 \uD83E\uDD92㊎㊍㊌㊋㊏";
s.codePoints().forEach(x-> System.out.print(x+" "));
System.out.println("\n解析的结果为");
strToCodePoints(s).forEach(x-> System.out.print(x+" "));
}
测试结果为
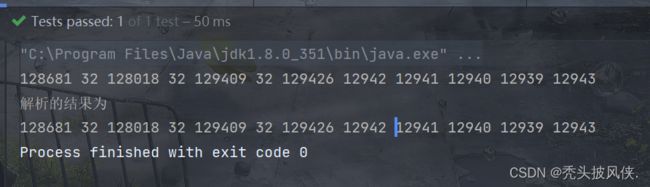
为什么java9中的String使用byte数组
原因就是使用char来进行存储,当我们存储英文字符时会浪费很多的空间,因为char占用2个字节,而英文字符用一个字节就能够存储完成。英文字符在字符串中使用的频率还特别高,所以在java9中就进行了优化,使用String底层就使用byte数组进行存储。
在java9的String中有一个字段coder

这个字段就用来表示当前采用的是什么编码,如果全是英文字符,那么就采用LANIN1编码,每个Unicode字符都只占一个字节,否则就使用UTF-16编码,每个Unicode字符都占2个字节或者4个字节。
总结
- 对于UTF-16,他是变长的,在0~65535使用2个字节进行存储,其余使用4个字节进行存储。
- [0xD800,0xDFFF]中的码点未定义任何字符,专用于UTF-16的代理项
- 对应大于等于65536的Unicode,会进行代理,最终变为2个小于65536的值
- 0xD800和0xDC00相差了0x0400,也就是 0100 0000 0000, 刚好比 0011 1111 1111多1,也就是说高位代理项和低位代理项不会重复。系统仅凭一个字符就能够判断是高位代理项还是低位代理项