Coordinate Attention和BiFPN
文章目录
-
-
- 1 坐标注意力机制(Coordinate Attention)
-
- 原理:
- 结构:
- 代码:
- 优缺点:
- 2 加权双向特征金字塔(BiFPN)网络结构
-
- 原理
- 结构
- 代码
- 优缺点
-
1 坐标注意力机制(Coordinate Attention)
论文:http://arxiv.org/abs/2103.02907
源码:https://github.com/Andrew-Qibin/CoordAttention
推荐文章(参考文章):https://blog.csdn.net/zhouchen1998/article/details/114518727
原理:
通过将位置信息嵌入到通道注意力中,使得轻量级网络能够在更大的区域上进行注意力,同时避免了产生大量的计算开销。为了缓解2D全局池化造成的位置信息丢失,论文作者将通道注意力分解为两个并行的1D特征编码过程,有效地将空间坐标信息整合到生成的注意图中。更具体来说,作者利用两个一维全局池化操作分别将垂直和水平方向的输入特征聚合为两个独立的方向感知特征图。然后,这两个嵌入特定方向信息的特征图分别被编码为两个注意力图,每个注意力图都捕获了输入特征图沿着一个空间方向的长程依赖。因此,位置信息就被保存在生成的注意力图里了,两个注意力图接着被乘到输入特征图上来增强特征图的表示能力。由于这种注意力操作能够区分空间方向(即坐标)并且生成坐标感知的特征图,因此将提出的方法称为坐标注意力(coordinate attention)。
结构:
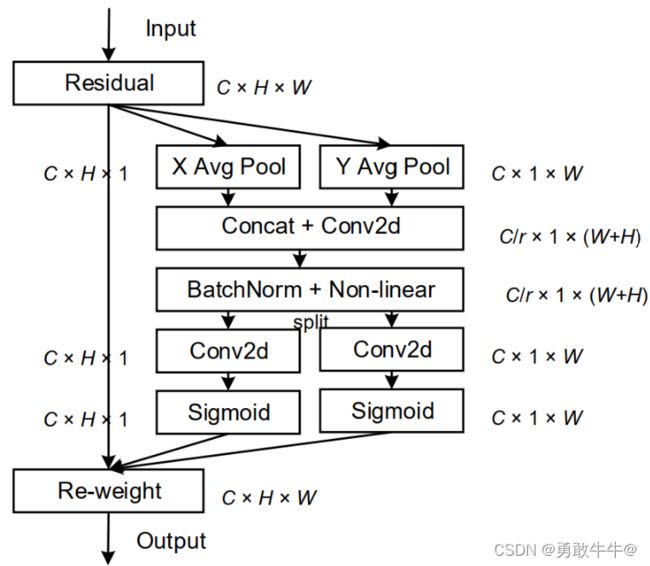
从结构图上不难看出
- 其中 X A v g P o o l X Avg Pool XAvgPool是对 W W W方向做平均池化,得到 C × H × 1 C \times H \times 1 C×H×1,同样 Y A v g P o o l Y Avg Pool YAvgPool是对 H H H方向做平均池化,得到 C × 1 × W C \times 1 \times W C×1×W
- 对两个多通道的一D向量在做空间维度的 c o n c a t concat concat,然后用 1 × 1 1 \times 1 1×1卷积压缩通道数
- 然后再通过BN和Non-linear来编码垂直方向和水平方向的空间信息
- 在进行split分离(就是将完整的特征向量重新分为两个方向的向量),通过 1 × 1 1 \times 1 1×1卷积重新调整两个方向特征向量的通道数,然后经过 S i g m o i d Sigmoid Sigmoid函数
- 最后在与原输入信息进行两个方向的加权
代码:
源码地址:https://github.com/Andrew-Qibin/CoordAttention
下面是原作者github上传的源代码:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
优缺点:
- 1.它捕获了不仅跨通道的信息,还包含了方向感知和位置感知的信息,这使得模型更准确地定位到并识别目标区域。
- 2.其次就是论文中所说的,插入到MobileNetV2网络中,在不增加太多的参数前提下,分类精度提升较明显
- 3.其次提到的下游任务:检测分割等,效果也很好,但是从论文的角度去看,在他们的训练策略下,坐标注意力就已经比SE、CBAM参数多,如果是我们自己改进,参数量肯定是需要考虑的方面。(不过作为一种新的注意力机制,创新性还是很很可观的)
2 加权双向特征金字塔(BiFPN)网络结构
推荐文章:https://zhuanlan.zhihu.com/p/96773680
原理
BiFPN主要思想有两点:一是高效的双向跨尺度连接,二是加权特征图融合。
结构
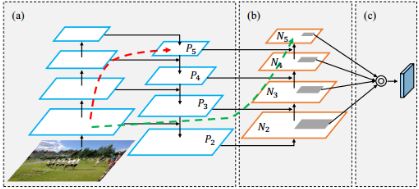
上图为比较经典的PANet结构
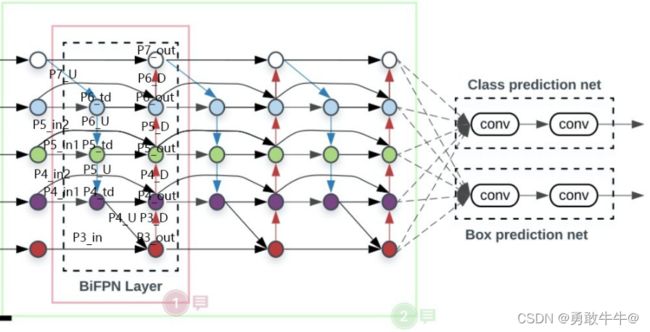
上图为BiFPN结构
下面将FPN,PANet,BiFPN结构进行对比:

- 图(a) FPN 引入了一条自顶向下的通道来融合特征
- 图(b) PANet 在 FPN 基础上增加了一条自底向上的通道
- 图© BiFPN:不同于其他的FPN结构(不同 resolution 的特征融合时直接相加),但实际上它们对最后 output 的贡献是不同的,所以作者希望网络来学习不同输入特征的权重,即 weighted feature fusion。在PANet的基础上,若输入和输出都是同一水平的(好多文章都说水平二字,我认为应该是在网络结构图上来看,他们处于同一水平,并且通道数一致),则添加一条额外的边。在EfficientDet文章中,BiFPN当做一个小的网络模块来使用,并且叠加多次。
加权特征融合
先前的特征融合方法大多平等地对待所有输入特征。然而,因为不同的特征具有不同的分辨率,他们对特征融合的贡献是不平等的。为解决此问题,本文提出在特征融合期间为每个输入添加一个额外的权重,让网络去学习每个输入特征的重要性。
代码
代码(源码)链接:https://github.com/xuannianz/EfficientDet
优缺点
- 特征复用更绝对化,而不是平均化
- 作为改进当下的网络模型可以进行参考
注:参考的原文出处已经给出,本着学习的态度去搜的参考文章,而不仅仅是搬运工~~