STL学习笔记
STL概述
目的
为了建立数据结构和算法的一套标准,并降低它们之间的耦合关系,以提升各自的独立性、弹性、交互操作性(互相合作性),于是有了
STL,即Standard Template Library标准模板库
基本概念
STL是惠普实验室开发的一系列软件的统称。
STL从广义上分为容器、算法、迭代器,容器和算法之间通过迭代器进行无缝连接
STL几乎所有的代码都采用了模板类和模板函数
六大组件
相互关系:
容器通过空间配置器取得数据存储空间,
算法通过迭代器存储容器中的内容,
仿函数可以协助算法完成不同的策略的变化,
适配器可以修饰仿函数
容器
各种数据结构,如:
vector, list, deque, set, map等,用来存放数据
从实现的角度看,
STL容器是一种类模板
算法
各种常用的算法,如:
sort, find, copy, for_each等
从实现的角度看,
STL算法是一种函数模板
迭代器
扮演了容器预算法之间的胶合剂,共有五种类型
从实现的角度看,
STL迭代器是一种将operator*, operator->, operator++, operator--等指针相关操作予以重载的类模板
所有
STL容器都附带有自己专属的迭代器,且只有容器的设计者才知道如何便利自己的元素
原生指针(
native pointer)也是一种迭代器
仿函数
行为类似函数,可作为算法的某种策略
从实现的角度看,
STL仿函数是一种重载了operator()的类或者类模板
适配器(配接器)
一种用来修饰容器或仿函数或迭代器接口的东西
空间配置器
负责空间的配置与管理
从实现的角度看,
STL适配器是一个实现了动态空间配置、空间管理、空间释放的类模板
优点
STL是c++的一部分,内建在编译器中,无需额外安装STL将数据和操作分离
数据有容器类别加以管理;操作则由可定制的算法定义;迭代器充当两者之间的粘合剂,使得容器核算法交互运作- 高重用性:几乎多有代码都采用了模板编程
- 高性能:如
map采用红黑树实现,可高效地从十万条数据中找到指定的数据 - 高移植性:如在项目A上用
STL编写的模块,可以直接移植到项目B中
常用容器
string
介绍
- 是对
char*的一个封装
一个char*类型的容器 - 不用考虑释放和越界
string会管理char*所分配的内存,每一次string的赋值和取值都有string类去负责维护,不用担心复制越界和取值越界问题
构造函数
string(); //创建一个空字符串,同string str;
string(const string &str); //使用一个string来初始化
string(const char *s); //使用一个char *来初始化
string(int n, char c); //使用n个字符c来初始化
赋值
string & operator=(const char* s); //将char *类型字符串赋值给当前字符串
string & operator=(const string &s); //将string类型字符串赋值给当前字符串
string & operator=(char c); //将一个字符赋值给当前字符串
string & assign(const char *s); //将char *字符串赋值给当前字符串
string & assign(const char *s, int n); //将char *字符串的前n个字符赋值给当前字符串
string & assign(const string &s); //将string类型字符串赋值给当前字符串
string & assign(int n, char c); //将n个字符c赋值给当前字符串
string & assign(consg string &s, int start, int n); //将string字符串从start开始的n个字符赋值给当前字符串
存取字符
char& operator[](int n); //通过[]方式取字符,下标越界直接终止程序
char& at(int n); //获取指定位置n上的字符,下标越界抛出out_of_range异常
拼接
string & operator+=(const string &str);
string & operator+=(const char* str);
string & operator+=(const char c);
string & append(const char* s);
string & append(const char* s, int n); //将char*字符串的前n个字符连接到当前字符串后面
string & append(const string &s);
string & append(const string &s, int pos, int n); //将string字符串从pos开始的n个字符拼接到当前字符串后面
string & append(int n, char c); //在当前字符串后面拼接上n个字符c
查找和替换
int find(const string &str, int pos = 0) const; //从pos位置开始查找str第一次出现的位置
int find(const char* s, int pos = 0) const; //同上
int find(const char* s, int pos, int n) const; //从pos位置开始查找str前n个字符第一次出现的位置
int find(const char c, int pos = 0) const; //从pos位置开始查找字符c第一次出现的位置
int rfind(const string &str, int pos = npos) const; //从pos位置开始查找str最后一次出现的位置(从右边开始找)
int rfind(const char *s, int pos = npos) const; //同上
int rfind(const char *s, int pos, int n) const; //从pos位置开始查找str前n个字符最后一次出现的位置(从右边开始找)
int rfind(const char c, int pos = 0) const; //从pos位置开始查找字符c最后一次出现的位置(从右边开始找)
string & replace(int pos, int n, const string &str); //将从pos位置开始的n个字符替换为str
string & replace(int pos, int n, const char* s); //同上
比较
int compare(const string &s) const; //和string字符串比较
int compare(const char* s) const; //和char*字符串比较
取子串
string substr(int pos = 0, int n = npos) const; //返回从pos位置开始的n个字符所组成的字符串
插入与删除
string & insert(int pos, const char* s); //在pos位置上插入char*字符串
string & insert(int pos, const string &s); //在pos位置上插入string字符串
string & insert(int pos, int n, char c); //在pos位置上插入n个字符c
string & erase(int pos, int n = npos); //从pos位置开始删除n个字符
与char *的转换
//string 转 const char*
string str = "aaa";
const char * cstr = str.c_str();
//const char* 转 string
const char * cstr2 = "bbb";
string s = string(cstr2);
vector
头文件:
include
动态数组,使用的是动态空间,随着元素的加入,其内部机制会自动扩充空间以容纳新元素
数据存在一组连续空间上,空间不足则找到一块充足的空间,将元数据拷贝过去
缺点:头插需要移动后面的所有元素,效率非常差
构造函数与遍历方式
vector<T> v;
vector(v.begin(), v.end()); //将v[begin, end)区间中的元素拷贝给本身
vector(n, elem); //将n个elem拷贝给本身
vector(const vector &vec); //拷贝构造函数
#include )
std::for_each(v4.begin(), v4.end(), [&](const auto &item) {
cout << item << " "; //a a a
});
cout << endl;
//逆序遍历
for(vector<int>::reverse_iterator it = v1.rbegin(); it != v1.rend(); ++it) {
cout << *it << " ";
}
}
赋值
vector & operator=(const vector &vec);
assign(beg, end); //将[beg, end)区间的数据拷贝给自身
assign(n, elem); //将n个elem拷贝给自身
swap(vec); //和vec交换元素
大小与容量
size(); //当前容器中元素的个数
empty(); //是否为空(没有一个元素)
resize(int num); //重新指定容器的长度(不是容量,而是元素的个数),如果个数变大,则以默认值填充,如果变小则删除多余元素
resize(int num, elem); //和上面相比,指定填充元素为elem
capacity(); //容器的容量
reserve(int len); //申请len长度的内存空间,不初始化
存取
at(int idx); //获取索引为idx的位置上的元素
operator[]; //通过[]获取元素
front(); //获取容器第一个元素
back(); //获取容器最后一个元素
插入与删除
insert(const iterator pos, int count, ele); //从位置pos开始插入count个ele,count可不填(默认为1个)
push_back(ele); //尾插
pop_back(); //尾删
erase(const iterator start, const iterator end); //删除迭代器[start, end)区间的元素
erase(const iterator pos); //删除迭代器指定位置pos上的元素
clear(); //删除所有元素
void test(){
vector<int> v;
v.push_back(10);
v.push_back(20);
v.push_back(30);
v.push_back(40);
v.insert(v.begin(), 2, 100); //100 100 10 20 30 40
v.pop_back(); //100 100 10 20 30
v.erase(v.begin()); //100 10 20 30
v.erase(v.begin() + 1, v.end() -1); //100 30
v.clear(); //全删了
}
案例
巧用swap来收缩内存
void test() {
vector<int> v1;
for (int i = 0; i < 100000; ++i) {
v1.push_back(i);
}
cout << "capacity1: " << v1.capacity() << endl; //131072
cout << "size1: " << v1.size() << endl; //100000
v1.resize(3);
cout << "capacity2: " << v1.capacity() << endl; //131072,可见容量并未改变
cout << "size2: " << v1.size() << endl; //3
/**
* 利用swap收缩内存
* 解释:
* 1、vector(v1):创建匿名对象,创建时会用传入的v1的size作用capacity
* 2、.swap(v1):实质就是指针指向的交换,即v1指向了匿名对象,匿名对象指向v1对象
* 3、匿名对象特点:执行完该行代码就被回收,即匿名对象指向的v1对象被回收
*/
vector<int>(v1).swap(v1);
cout << "capacity3: " << v1.capacity() << endl; //3
cout << "size3: " << v1.size() << endl; //3
}
巧用reserve来预留空间
- 未使用
reserve时的扩容次数void test() { vector<int> v; int *p = nullptr; int num = 0; for (int i = 0; i < 100000; ++i) { v.push_back(i); if (p != &v[0]) { p = &v[0]; num++; } } cout << "扩容了 " << num << " 次" << endl; //18次 cout << "最后的首地址:" << p << endl; } - 使用
reserve后的扩容次数void test() { vector<int> v; v.reserve(100000); int *p = nullptr; int num = 0; for (int i = 0; i < 100000; ++i) { v.push_back(i); if (p != &v[0]) { p = &v[0]; num++; } } cout << "扩容了 " << num << " 次" << endl; //1次 }
deque
头文件
#include
双端数组,和
vector相比,deque的两端都可以操作
采用的是动态分段连续空间存储数据,随时可以增加一段新的空间并链接起来,
所以它没有reserve功能,但是头删和头插效率都很高(无需像vector那样移动后面的数据)

- 只读迭代器
#includevoid printDeque(const deque<int> &d) { //禁止修改内容(const deque &d)时,需要使用只读迭代器(deque for (deque<int>::const_iterator it = d.begin(); it < d.end(); ++it) { //*it = 1000; //报错,无法修改了 cout << *it << " "; } cout << endl; } void test() { deque<int> d; d.push_back(10); d.push_back(20); d.push_back(30); d.push_back(40); d.push_back(50); printDeque(d); }::const_iterator)来遍历
stack
头文件:
include
栈,先进后出
栈没有迭代器
构造函数
stack<T> stk;
stack(const stack &stk); //拷贝构造函数
赋值
stack & operator=(const stack &stk);
存取
push(elem); //栈顶入栈
pop(); //栈顶出栈
top(); //获取栈顶元素(不影响栈中数据)
queue
头文件:
include
队列,先进先出
队列没有迭代器
构造函数
queue<T> que;
queue(const queue &que); //拷贝构造函数
存取与增删
push(elem); //队尾插入元素
pop(); //队头删除元素
back(); //返回队尾元素
front(); //返回队头元素
赋值
queue & operator=(const queue &que);
list
头文件:
#include
链表,一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表由一系列结点组成(链表中每一个元素称为一个结点),结点可以在运行时动态生成,每个结点分为两部分:一个是存储数据元素的数据域;一个是存储下一个结点地址的指针域
list是个双向循环链表
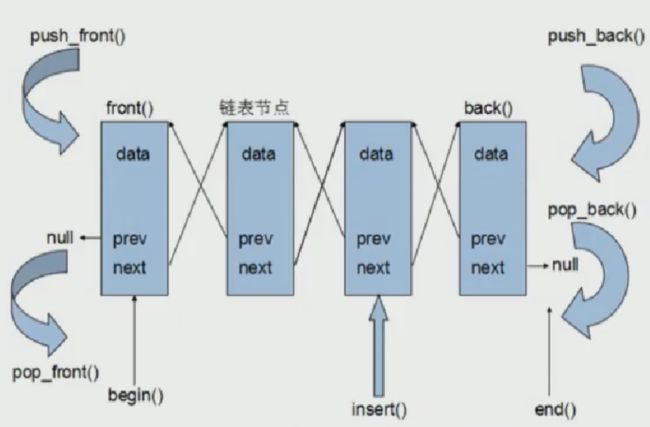
- 链表的特点
- 采用动态存储分配,不会造成内存浪费和溢出
- 执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
- 非连续空间,所以遍历没有
vector数组快 - 链表的迭代器不像
vector那样可以随机访问,即无法进行如begin() + num这样的操作
set
头文件:
#include
集合,底层为红黑树,
set中所有元素都会根据元素的键值自动排序
和map不同的是,set的元素即使键也是值,所以set的值具有唯一性,即不会重复
另外,无法通过set的迭代器去修改它的元素,因为其元素值本身又是自身的键,关系到set元素的排序,如果任意更改,会破坏它的组织结构,换句话说,set的迭代器是一种const_iterator
multiset
set一样,底层的实现也是红黑树,不过区别在于,它允许键值重复
pair
对组:
pair,无需引入任何头文件
//对组的创建方式
void test(){
//创建方式一:使用有参构造
pair<string, int> p1("张三", 21);
cout << "name=" << p1.first << ", age=" << p1.second << endl;
//创建方式二:使用make_pair
pair<string, int> p2 = make_pair("张三", 21);
cout << "name=" << p1.first << ", age=" << p1.second << endl;
}
#include 修改默认的升序排序规则
需要通过仿函数来实现排序规则的修改
class MyCompareInt {
public:
bool operator()(int a, int b) {
return a > b;
}
};
void test() {
set<int> s;
s.insert(10);
s.insert(30);
s.insert(40);
s.insert(20);
s.insert(50);
for (set<int, MyCompareInt>::iterator it = s.begin(); it != s.end(); ++it) {
cout << *it << " "; //10 20 30 40 50
}
cout << endl;
set<int, MyCompareInt> sc;
sc.insert(10);
sc.insert(30);
sc.insert(40);
sc.insert(20);
sc.insert(50);
for (set<int>::iterator it = sc.begin(); it != sc.end(); ++it) {
cout << *it << " "; //50 40 30 20 10
}
}
map
头文件:
#include
键值对,底层为红黑树实现,
map中所有的元素都会根据元素的键值自动排序
map中所有的元素都是pair,map不允许两个元素拥有相同的键
和set一样,map也无法通过它的迭代器去修改它的元素的键,不过可以修改它的值
multimap
和
map的区别在于,它允许相同的键存在
基本语法
#include
void test() {
map<int, int> m;
//第一种插入方式
m.insert(pair<int, int>(1, 10));
//第二种插入方式(推荐)
m.insert(make_pair(3, 30));
//第三种插入方式
m.insert(map<int, int>::value_type(2, 20));
//第四种插入方式
m[4] = 40;
//不推荐第四种:因为这样也会被插入,值为类型默认值(如int为0)
m[5];
//遍历
/*
* key=1, value=10
* key=2, value=20
* key=3, value=30
* key=4, value=40
* key=5, value=0
*/
for(map<int, int>::iterator it = m.begin(); it != m.end(); ++it) {
cout << "key=" << it->first << ", value=" << it->second << endl;
}
}
容器的选择
容器对比
| vector | deque | list | set | multiset | map | multimap | |
|---|---|---|---|---|---|---|---|
| 内存结构 | 单端数组 | 双端数组 | 双向循环列表 | 红黑树 | 红黑树 | 红黑树 | 红黑树 |
| 可随机存取 | 是 | 是 | 否 | 否 | 否 | 对key而言不是 | 否 |
| 查找速度 | 慢 | 慢 | 非常慢 | 快 | 快 | 对key而言快 | 对key而言快 |
| 增删速度 | 尾端 | 两端 | 任何位置 |
使用场景
vector
比如软件历史操作记录的存储,经常需要查看历史记录(遍历),但不会去删除记录,因为记录是事实的描述deque
比如排队购票系统,对排队者的存储可以采用deque,支持头端的快速移除,尾端的快速添加list
比如公交车乘客的存储,随时可能有乘客上下车,支持频繁的不确定位置元素的移除与插入set
比如对手机游戏的个人得分记录的存储,存储要求从高分到低分的顺序排列map
比如按ID号存储十万个用户,想要快速通过ID找到对应的用户
函数对象(仿函数)
仿函数可以拥有自己的状态
统计被调用的次数
class MyPrinter {
private:
int m_Count = 0;
public:
void operator()(string name) {
cout << "hello " << name << endl;
m_Count++;
}
int count() const {
return this->m_Count;
}
};
void test() {
MyPrinter myPrinter;
myPrinter("张三");
myPrinter("李四");
myPrinter("王五");
cout << "被调用了 " << myPrinter.count() << " 次" << endl;
}
仿函数可以作为函数参数
void print(MyPrinter myPrinter, const string name) {
myPrinter(name);
}
void test() {
MyPrinter myPrinter;
print(myPrinter, "c++");
}
谓词
指 普通函数或反函数者 返回值是布尔类型时
如果需要一个参数,则称为一元谓词;
如果需要两个参数,则称为二元谓词
一元谓词
找到第一个大于20的数
class MyCompare{
public:
bool operator()(int val) {
return val > 20;
}
};
void test() {
vector<int> v;
v.push_back(10);
v.push_back(20);
v.push_back(30);
v.push_back(40);
v.push_back(50);
vector<int>::iterator ret = find_if(v.begin(), v.end(), MyCompare());
if (ret != v.end()) { //找不到会返回v.end()
cout << "第一个大于20的数字为:" << *ret << endl; //30
}
cout << "未找到" << endl;
}
二元谓词
倒序输出数据
class MyCompare{
public:
bool operator()(int v1, int v2) {
return v1 > v2;
}
};
void test() {
vector<int> v;
v.push_back(10);
v.push_back(30);
v.push_back(20);
v.push_back(40);
v.push_back(50);
sort(v.begin(), v.end(), MyCompare()); //倒序
for_each(v.begin(), v.end(), [](int val){
cout << val << " "; //50 40 30 20 10
});
}
内建函数对象
头文件:
#include
算术类函数对象
template<class T> T plus<T> //加法仿函数
template<class T> T munus<T> //减法仿函数
template<class T> T multiplies<T> //乘法仿函数
template<class T> T divides<T> //除法仿函数
template<class T> T modulus<T> //取模仿函数
template<class T> T negate<T> //取相反数仿函数
#include 关系运算类函数对象
template<class T> bool equal_to<T> //等于
template<class T> bool not_equal_to<T> //不等于
template<class T> bool greater<T> //大于
template<class T> bool greater_equal<T> //大于等于
template<class T> bool less<T> //小于
template<class T> bool less_equal<T> //小于等于
void test() {
vector<int> v;
v.push_back(10);
v.push_back(30);
v.push_back(20);
v.push_back(40);
v.push_back(50);
sort(v.begin(), v.end(), greater<int>()); //倒序
for_each(v.begin(), v.end(), [](int val){
cout << val << " ";
});
}
逻辑运算类函数对象
template<class T> bool logical_and<T> //逻辑与
template<class T> bool logical_or<T> //逻辑或
template<class T> bool logical_not<T> //逻辑非
适配器
bind1st & bind2nd
class MyPrint: public binary_function<int, int, void> { //三个泛型对应两个参数类型和返回值
public:
void operator()(int val, int num) const {
cout << val + num << endl;
}
};
void test() {
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
for_each(v.begin(), v.end(), [](int val){cout << val << " ";});
cout << endl;
/*
* 需求:让所有的数字都加上num后再输出
* 问题:foreach的回调函数只有一个参数
* 方案:让num和foreach的参数绑定在一起,作为一个参数
* 步骤:
* 1、引入头文件#include
* 2、使用绑定适配器:bind2nd
* (2表示将数据绑定到第二个参数中,如果用bind1st则绑定到第一个参数中,两个都能实现效果)
* 3、让自定义的回调函数继承binary_function
* 4、operator()加入const
*/
int num = 1000;
for_each(v.begin(), v.end(), bind2nd(MyPrint(), num));
}
not1 & not2
- 一元取反 - 普通版
class GreaterFive: public unary_function<int, bool>{ public: bool operator()(int val) const { return val > 5; } }; void test() { vector<int> v; for (int i = 0; i < 10; ++i) { v.push_back(i); } /* * 需求:找到第一个大于5的数 */ vector<int>::iterator r = find_if(v.begin(), v.end(), GreaterFive()); cout << *r << endl; //6 /* * 需求:找到第一个小于5的数 * 方案:使用取反适配器not1 * 步骤: * 1、引入头文件#include* 2、继承unary_function<参数类型,返回值类型> * 3、添加const */ vector<int>::iterator rr = find_if(v.begin(), v.end(), not1(GreaterFive())); cout << *rr << endl; //0 } - 一元取反 - 增强版
void test() { vector<int> v; for (int i = 0; i < 10; ++i) { v.push_back(i); } /* * 需求:找到第一个大于等于5的数 */ vector<int>::iterator rr = find_if(v.begin(), v.end(), not1(bind2nd(less<int>(), 5))); cout << *rr << endl; //5 } - 二元取反
void test() {
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
/*
* 需求:倒序输出(不用greater)
* 方案:使用not2适配器
* 原因:less是二元仿函数,所以用not2
*/
sort(v.begin(), v.end(), not2(less<int>()));
for_each(v.begin(), v.end(), [](int val){cout << val << " ";});
}
ptr_fun
函数适配器:将函数指针适配成仿函数
void myPrint(int val, int num) {
cout << val + num << endl;
}
void test() {
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
int num = 1000;
for_each(v.begin(), v.end(), bind2nd(ptr_fun(myPrint), num));
}
mem_fun_ref
成员函数适配器
class Person {
private:
string m_Name;
int m_Age;
public:
Person(string name, int age) {
this->m_Name = name;
this->m_Age = age;
}
void show() {
cout << "name=" << this-> m_Name << ", age=" << m_Age << endl;
}
};
void test() {
vector<Person> v;
for (int i = 0; i < 10; ++i) {
v.emplace_back("小" + to_string(i), 10 + i);
}
for_each(v.begin(), v.end(), mem_fun_ref(&Person::show));
}
常用算法
算法主要由头文件
组成
:所有STL头文件中最大的一个,包括比较、交换、查找、遍历、复制、修改、反转、排序、合并等
:定义了一些模板类,用于声明函数对象
:体积很小,只包括在序列容器上进行的简单运算的模板函数
遍历算法
for_each(iterator beg, iterator end, _callback);
/**
* 作用:将指定容器区间元素复制到另一个容器中
* 回调:是个map操作
*/
transform(iterator beg1, iterator end1, iterator beg2, _callback);
void test() {
vector<int> v1;
for (int i = 0; i < 10; ++i) {
v1.push_back(i + 100);
}
vector<int> v2;
v2.resize(v1.size()); //不能直接将数据放入都一个没有内存的数组中,所以这里先分配内存
transform(v1.begin() + 1, v1.end(), v2.begin(), [](int val) {return val;});
for_each(v1.begin(), v1.end(), [](int val) { cout << val << " "; }); //100 101 102 103 104 105 106 107 108 109
cout << endl;
for_each(v2.begin(), v2.end(), [](int val) { cout << val << " "; }); //101 102 103 104 105 106 107 108 109 0
}
查找算法
/**
* 作用:找到[beg, end)中第一次出现的value的位置
* 返回:如果找到返回元素位置(迭代器),否则返回end()
*/
find(iterator beg, iterator end, value);
/**
* 和find对比:通过条件查找(即回调的返回值是个bool)
*/
find_if(iterator beg, iterator_end, _callback);
/**
* 作用:查找相邻重复数据
* callback:返回值为bool,即判断规则,二元的,
* 默认是 v1 == v2,这也是默认查找相邻重复数据的原因,
* 通过callback,可以自定义判断规则,如 v1 > v2
* 那么就会返回第一个满足 v1 > v2 的数据 v1 的位置
* 返回:第一个满足规则的、相邻两个数据的、前一个数据的位置(迭代器),
* 找不到返回end()
*/
adjacent_find(iterator beg, iterator end, _callback);
/**
* 作用:二分查找法查找value
* 返回:布尔,即是否找到了
*/
binary_search(iterator beg, iterator end, value);
/**
* 作用:统计value出现的次数
* 条件:必须是个有序序列
* 返回:出现的次数
*/
count(iterator beg, iterator end, value);
/**
* 和count相比,它用来统计符合条件的元素个数
*/
count_if(iterator beg, iterator end, _callback);
find_if
#include adjacent_find
void test() {
vector<int> v;
v.push_back(100);
v.push_back(21);
v.push_back(23);
v.push_back(23);
v.push_back(101);
v.push_back(101);
v.push_back(100);
v.push_back(23);
//默认规则为相邻数据是否相等
vector<int>::iterator r = adjacent_find(v.begin(), v.end());
if (r != v.end()) {
cout << *r << ", " << *(++r) << endl; //23, 23
}
//通过callback自定义规则
vector<int>::iterator r2 = adjacent_find(v.begin(), v.end(), [](int v1, int v2) {
return v1 == 23 && v2 == 101;
});
if (r2 != v.end()) {
cout << *r2 << ", " << *(++r2) << endl; //23, 101
}
}
排序算法
/**
* 作用:将两个容器指定区间元素合并并放入另一个容器中
* 前提:进行合并的两个容器是有序的
* 注意:目标容器接收数据前需要有内存分配
* 结果:还是一个有序序列
*/
merge(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator desst);
sort(iterator beg, iterator end, _callback);
/**
* 作用:随机调整次序
* 注意:结合随机种子使用,否则每次的随机顺序都一样
*/
random_shuffle(iterator beg, iterator end);
/**
* 作用:数据反转
*/
reverse(iterator beg, iterator end);
拷贝与替换算法
/**
* 作用:将容器指定范围元素拷贝到另一个容器中
* 注意:接收容器需要有内存分配
* 特殊:可以巧妙地进行打印操作
*/
copy(iterator beg, iterator end, iterator dest);
/**
* 作用:将[beg, end)范围内的oldvalue替换为newvalue
*/
replace(iterator beg, iterator end, oldvalue, newvalue);
/**
* 作用:将[beg, end)范围内满足条件的元素都替换为新元素
*/
replace_if(iterator beg, iterator end, _callback, newvalue);
/**
* 作用:互换两个容器的元素
* 提示:两个容器的大小可不一致
*/
swap(container c1, container c2);
copy的打印用法
#include 算术生成算法
/**
* 作用:计算容器中元素的累加和
* value:累加初始值
*/
accumulate(iterator beg, iterator end, value);
/**
* 作用:将指定区间[beg, end)中的数据用value填充
* 注意:如果区间已存在数据则被覆盖,没有数据时要保证已分配了内存
*/
fill(iterator beg, iterator end, value);
集合算法
/**
* 作用:将两个有序集合的交集放到另一个容器中
*/
set_intersection(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator desc);
/**
* 作用:将两个有序集合的并集放到另一个容器中
*/
set_union(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator desc);
/**
* 作用:将两个有序集合的差集放到另一个容器中
*/
set_difference(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator desc);