PySpark Core(Checkpoint、共享变量、RDD持久化)
#博学谷IT学习技术支持#
RDD持久化
概述
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。

4.1 为什么使用缓存
使用缓存的原因是什么?
提升应用程序性能
容错
思考下面两个问题?
问题1:当在计算 RDD3 的时候如果出错了, 会怎么进行容错?
问题2:会再次计算 RDD1 和 RDD2 的整个链条, 假设 RDD1 和 RDD2 是通过比较昂贵的操作得来的, 有没有什么办法减少这种开销?

上述两个问题的解决方案其实都是 缓存, 除此之外, 使用缓存的理由还有很多, 但是总结一句, 就是缓存能够帮助开发者在进行一些昂贵操作后, 将其结果保存下来, 以便下次使用无需再次执行, 缓存能够显著的提升性能.
所以, 缓存适合在一个 RDD 需要重复多次利用, 并且还不是特别大的情况下使用, 例如迭代计算等场景.
因此,Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
4.2 缓存函数
可以将RDD数据直接缓存到内存中,函数声明如下:

但是实际项目中,不会直接使用上述的缓存函数,RDD数据量往往很多,内存放不下的。在实际的项目中缓存RDD数据时,往往使用如下函数,依据具体的业务和数据量,指定缓存的级别:
4.3 缓存级别
在Spark框架中对数据缓存可以指定不同的级别,对于开发来说至关重要,如下所示:

实际项目中缓存数据时,往往选择如下两种级别:
缓存函数与Transformation函数一样,都是Lazy操作,需要Action函数触发,通常使用count函数触发。
如何选择分区级别
1.Spark 的存储级别的选择,核心问题是在 memory 内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择:
2.如果您的 RDD 适合于默认存储级别(MEMORY_ONLY),leave them that way。这是 CPU 效率最高的选项,允许 RDD 上的操作尽可能快地运行.
3.如果不是,试着使用 MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
4.不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
5.如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用 Spark 来服务 来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在 RDD 上运行任务,而无需等待重新计算一个丢失的分区.
4.4 释放缓存
当缓存的RDD数据,不再被使用时,考虑释资源,使用如下函数:

4.5 何时缓存数据
在实际项目开发中,什么时候缓存RDD数据,最好呢?
第一点:当某个RDD被使用多次的时候,建议缓存此RDD数据
比如,从HDFS上读取网站行为日志数据,进行多维度的分析,最好缓存数据
第二点:当某个RDD来之不易,并且使用不止一次,建议缓存此RDD数据
比如,从HBase表中读取历史订单数据,与从MySQL表中商品和用户维度信息数据,进行关联Join等聚合操作,获取RDD:etlRDD,后续的报表分析使用此RDD,此时建议缓存RDD数据
案例:etlRDD.persist(StoageLeval.MEMORY_AND_DISK_2)
代码如下:
# -*- coding: utf-8 -*-
# Program function:Cache & Persist RDD
from pyspark import SparkContext, SparkConf
import os
import re
from pyspark.storagelevel import StorageLevel
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark RDD Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,创建RDD数据集
# TODO: 3、调用集合RDD中函数处理分析数据
fileRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt")
# 缓存RDD
fileRDD.cache()
fileRDD.persist()
# 使用Action触发缓存操作
print("fileRDD count:", fileRDD.count())
# 释放缓存
fileRDD.unpersist()
# 数据的相关操作
resultRDD2 = fileRDD.flatMap(lambda line: re.split("\s+", line)) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()RDD Checkpoint
概述
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
在Spark Core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;

5.1 检查点机制案例
if __name__ == '__main__':
print('PySpark checkpoint Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、RDD的checkpoint
sc.setCheckpointDir("file:///export/pyfolder1/pyspark-chapter02_3.8/data/checkpoint1")
# TODO: 3、调用集合RDD中函数处理分析数据
fileRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt")
# TODO: 调用checkpoint函数,将RDD进行备份,需要RDD中Action函数触发
fileRDD.checkpoint()
fileRDD.count()
# TODO: 再次执行count函数, 此时从checkpoint读取数据
fileRDD.count()
time.sleep(100)
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()
查看WebUI:http://192.168.88.161:4041/jobs/执行Action操作会触发Checkpoint,启动两个Job,其中一个Job是count,另外一个为checkpoint启动的Job。然后在执行count操作就能看到checkkpoint截断依赖链,速度很快。
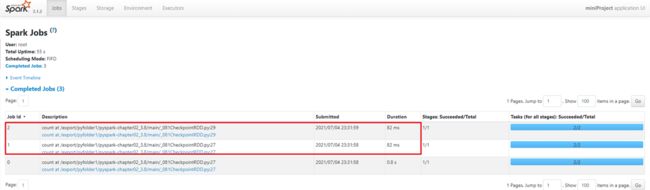
5.2 持久化和Checkpoint的区别
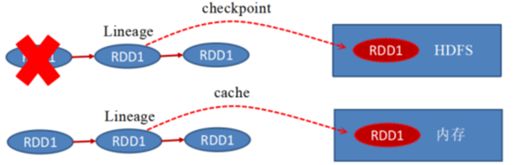
持久化和Checkpoint的区别:
1)、存储位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存);
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上;
2)、生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法;
Checkpoint的RDD在程序结束后依然存在,不会被删除;
3)、Lineage(血统、依赖链、依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来;
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链;
5.3 先cache在checkpoint测试
查看WebUi:
Spark容错机制:首先会查看RDD是否被Cache,如果被Cache到内存或磁盘,直接获取,否则查看Checkpoint所指定的HDFS中是否缓存数据,如果都没有则直接从父RDD开始重新计算还原。
if __name__ == '__main__':
print('PySpark cache&checkpoint Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、RDD的checkpoint
sc.setCheckpointDir("file:///export/pyfolder1/pyspark-chapter02_3.8/data/checkpoint1")
# TODO: 3、调用集合RDD中函数处理分析数据
fileRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt")
# TODO: 调用checkpoint和cache函数,将RDD进行容错,需要RDD中Action函数触发
print("=======1-同时做cache和Perisist========")
fileRDD.cache()
fileRDD.checkpoint()
print("=======2-启动Job1跑正常任务,启动Job2就会先从Cache读取数据,Web页面可以看到ProcessLocal========")
fileRDD.count()
# TODO: 再次执行count函数, 此时从checkpoint读取数据
fileRDD.count()
print("=======3-启动一个Job发现查询数据从checkpoint的hdfs中查找========")
# TODO:释放cache之后如果在查询数据从哪里读取? 答案是checkpoint的hdfs的数据中。
fileRDD.unpersist(True)
fileRDD.count()
查看WebUI:http://192.168.88.161:4041/jobs/共享变量
概述
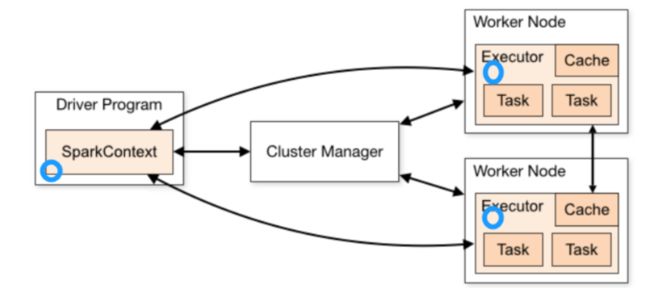
在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark提供了两种类型的变量:
1)、广播变量Broadcast Variables
广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本;
2)、累加器Accumulators
累加器支持在所有不同节点之间进行累加计算(比如计数或者求和);
官方文档:http://spark.apache.org/docs/3.1.2/rdd-programming-guide.html#shared-variables
7.1 广播变量
广播变量允许开发人员在每个节点(Worker or Executor)缓存只读变量,而不是在Task之间传递这些变量。使用广播变量能够高效地在集群每个节点创建大数据集的副本。同时Spark还使用高效的广播算法分发这些变量,从而减少通信的开销。
可以通过调用sc.broadcast(v)创建一个广播变量,该广播变量的值封装在v变量中,可使用获取该变量value的方法进行访问。


不使用广播变量

使用广播变量
广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。
Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。 Spark的动作通过一系列的步骤执行,这些步骤由分布式的洗牌操作分开。Spark自动地广播每个步骤每个任务需要的通用数据。这些广播数据被序列化地缓存,在运行任务之前被反序列化出来。这意味着当我们需要在多个阶段的任务之间使用相同的数据,或者以反序列化形式缓存数据是十分重要的时候,显式地创建广播变量才有用。
假如我们要共享的变量map,1M
在默认的,task执行的算子中,使用了外部的变量,每个task都会获取一份变量的副本。
在什么情况下,会出现性能上的恶劣的影响呢?
1000个task。大量task的确都在并行运行。这些task里面都用到了占用1M内存的map,那么首先,map会拷贝1000份副本,通过网络传输到各个task中去,给task使用。总计有1G的数据,会通过网络传输。网络传输的开销很大,也许就会消耗掉你的spark作业运行的总时间的一部分。
map副本,传输到了各个task上之后,是要占用内存的。1个map的确不大,1M;1000个map分布在你的集群中,一下子就耗费掉1G的内存。对性能会有什么影响呢?不必要的内存的消耗和占用,就导致了,你在进行RDD持久化到内存,也许就没法完全在内存中放下;就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能;
你的task在创建对象的时候,也许会发现堆内存放不下所有对象,也许就会导致频繁的垃圾回收器的回收,GC的时候,一定是会导致工作线程停止,也就是导致Spark暂停工作那么一点时间。频繁GC的话,对Spark作业的运行的速度会有相当可观的影响。
如果说,task使用大变量(1m~100m),明知道会导致性能出现恶劣的影响。那么我们怎么来解决呢?
广播,Broadcast,将大变量广播出去。而不是直接使用。
广播变量的好处,不是每个task一份变量副本,而是变成每个节点的executor才一份副本。这样的话,就可以让变量产生的副本大大减少。
广播变量,初始的时候,就在Drvier上有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,BlockManager,也许会从远程的Driver上面去获取变量副本;也有可能从距离比较近的其他节点的Executor的BlockManager上去获取,并保存在本地的BlockManager中;BlockManager负责管理某个Executor对应的内存和磁盘上的数据,此后这个executor上的task,都会直接使用本地的BlockManager中的副本。
使用广播变量
代码:
from pyspark import SparkContext, SparkConf
import os
import re
if __name__ == '__main__':
print('PySpark Broadcast Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、定义累加器
kvFruit = sc.parallelize([(1, "apple"), (2, "orange"), (3, "banana"), (4, "grape")])
print(kvFruit.collect())
fruitMap = kvFruit.collectAsMap()
# print(fruitMap)#{1: 'apple', 2: 'orange', 3: 'banana', 4: 'grape'}
# print(type(fruitMap)) # 字典类型
fruitIds = sc.parallelize([2, 4, 1, 3])
# TODO: 3、定义累加函数实现累加功能
fruitNames = fruitIds.map(lambda x: fruitMap[x])#这里根据字典的健得到value
print(fruitNames.collect())
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()7.2 累加器
原理
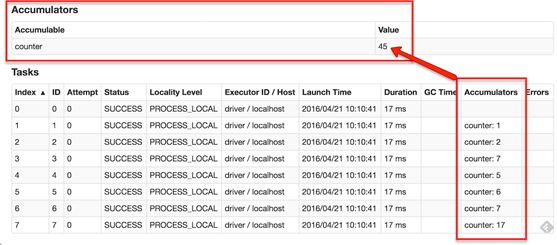
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值。创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名。
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
不使用累加器
# -*- coding: utf-8 -*-
# Program function:Cache & Persist RDD
from pyspark import SparkContext, SparkConf
import os
import re
from pyspark.storagelevel import StorageLevel
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark RDD Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、定义累加器
num =10 #如果这里改变为变量10,就得不到150累加值
# TODO: 3、定义累加函数实现累加功能
def f(x):
global num
num += x
rdd = sc.parallelize([20, 30, 40, 50])
rdd.foreach(f)
print(num) #如果num=10,此时打印num可以查看并没有实现分布式数据的累加
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()使用累加器
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器driver程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。这时使用累加器就可以实现我们想要的效果。
Python中用法:SparkContext.accumulator(v)
通过调用从初始值创建累加器SparkContext.accumulator(v)。
然后,可以使用add方法或+=运算符将在集群上运行的任务添加到集群中。
但是,他们无法读取其值。
只有驱动程序可以使用其value方法读取累加器的值。
下面的代码显示了一个累加器,用于累加一个数组的元素
>>> accum = sc.accumulator(0)
>>> accum
Accumulator
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
>>> accum.value
10 代码
if __name__ == '__main__':
print('PySpark RDD Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、定义累加器
num = sc.accumulator(10) #如果这里改变为变量10,就得不到150累加值
# TODO: 3、定义累加函数实现累加功能
def f(x):
global num
num += x
rdd = sc.parallelize([20, 30, 40, 50])
rdd.foreach(f)
# print(num) 如果num=10,此时打印num可以查看并没有实现分布式数据的累加
final = num.value
print("Accumulated value is -> %i" % (final))
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()累计器件还有两个小特性,
第一, 累加器能保证在 Spark 任务出现问题被重启的时候不会出现重复计算.
第二, 累加器只有在 Action 执行的时候才会被触发。
累加器只能在Driver端定义,在Executor端更新,不能在Executor端定义,不能在Executor端.value获取值。
7.3 PySpark累加器和广播变量案例演示
以词频统计WordCount程序为例,假设处理的数据如下所示,包括非单词符合,统计数据词频时过滤非单词的符合并且统计总的格式。

实现功能:
第一、过滤非单词符合
非单词符合存储列表List中
使用广播变量广播列表
第二、累计统计非单词符号出现次数
定义一个LongAccumulator累加器,进行计数

数据
hello shell # ! $ % nihao
hello shell nihao youhao haouos nihao
hello spark flink sql nihao haonirue
hello shell # ! $ % nihao
代码如下:
if __name__ == '__main__':
print('PySpark broadcast Program')
spark = SparkSession.builder.appName("broadcast").getOrCreate()
sc = spark.sparkContext
fileRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/main/broadcast/data.input")
# TODO: 字典数据,只要有这些单词就过滤: 特殊字符存储列表List中
acc_count=sc.accumulator(0)
# TODO: 通过广播变量 将列表list广播到各个Executor内存中,便于多个Task使用
list = [",", ".", "!", "#", "$", "%"]
broadcastList = sc.broadcast(list)
# TODO: 定义累加器,记录单词为符号数据的个数
def f(x):
global acc_count
listValue = broadcastList.value
if x in listValue:
#acc_count.add(1)
acc_count +=1
return 1
else:
return 0
#1)、过滤数据,去除空行数据
#2)、分割单词
#3)、过滤字典数据:符号数据
line__filter = fileRDD \
.filter(lambda line: (len(line.strip()) > 0)) \
.flatMap(lambda line: re.split("\\s+", line))\
.filter(f)
# 增加一个action算子count操作,触发累加器的计算
print("count:",line__filter.count())
print(f'the accumulator value is: {acc_count.value}')
# wordcount
print("非单词个数统计的结果")
key1 = line__filter.map(lambda word: (word, 1)) \
.reduceByKey(lambda k1, k2: k1 + k2) \
.sortBy(lambda x: x[1], ascending=False) \
.take(10)
print(key1)#[('#', 3), ('!', 3), ('$', 3), ('%', 2)]
sc.stop()7.4 累加器注意事项
这里演示累加器在遇到多次action操作的时候会出现重复累加求和的问题,以及如何给出解决方案。

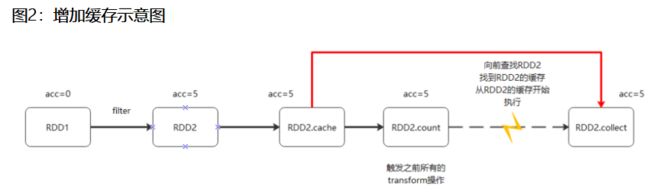
from pyspark.sql import SparkSession
import re
if __name__ == '__main__':
print('PySpark broadcast Program')
spark = SparkSession.builder.appName("broadcast").getOrCreate()
sc = spark.sparkContext
acc=sc.accumulator(0)
def judge_even(row_data):
"""
过滤奇数,计数偶数个数
"""
global acc
if row_data % 2 == 0:
acc += 1
return 1
else:
return 0
a_list = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
even_num = a_list.filter(judge_even)
print(f'the accumulator value is {acc}')
#the accumulator value is 0
'''
【分析】为什么会出现这个结果呢?
这是因为Spark中的一系列的转化(transform)算子操作会构成一长串的任务链,只有当存在行动(action)算子操作时,才会进行真正的运算。
累加器(accumulator)也同理。
上述代码中并没有action算子,因此累计器并没有进行累加。
'''
# 增加一个action算子count操作
print(f'even_num.count {even_num.count()}') #even_num.count 5
print(f'the accumulator value is {acc}') #accumulator value is 5
# 扩展2:
# print(f'even_num.count {even_num.count()}') #even_num.count 5
print(f'even_num.collect {even_num.collect()}') #even_num.collect [2, 4, 6, 8, 10]
print(f'the accumulator value is {acc}') #the accumulator value is 10
'''
【分析】我们可以看到实际上经过过滤之后的偶数为5个,但是累加器给出的数值是10个,为两倍的关系,那么为什么会是这种结果呢?
这就涉及到Spark运行机制的问题了
当我们遇到第一个action算子count的时候,他就会从头开始计算,这是累计器就会累加到5,直到输出count的值。
当我们遇到第二个action算子collect时,由于前面没有缓存数据可以直接加载,因此也只能从头计算,在从头计算时,这时accumulator已经是5了,在计算过程中累计器同样会被再执行一次,因此最后会输出10
'''
# 扩展3:继续验证
print(f'even_num.count {even_num.count()}')#even_num.count 5
print(f'after the first action operator the accumulator is {acc}')#after the first action operator the accumulator is 5
print(f'even_num.collect {even_num.collect()}')#even_num.collect [2, 4, 6, 8, 10]
print(f'after the second action operator the accumulator is {acc}')#after the second action operator the accumulator is 10
# 扩展4
'''
【分析】遇到以上问题我们应该怎么解决这个问题呢
解决这个问题只需要切断他们之间的依赖关系即可,
即:在累加器计算之后进行持久化操作,这样的话,第二次action操作就会从缓存的数据开始计算,不会再重复进行累计器计数
'''
# 增加cache
even_num = a_list.filter(judge_even).cache()
print(f'even_num.count {even_num.count()}')#even_num.count 5
print(f'after the first action operator the accumulator is {acc}')#after the first action operator the accumulator is 5
print(f'even_num.collect {even_num.collect()}')#even_num.collect [2, 4, 6, 8, 10]
print(f'after the second action operator the accumulator is {acc}')#fter the second action operator the accumulator is 5
# 扩展5:释放缓存位置不对
even_num = a_list.filter(judge_even).cache()
print(f'even_num.count {even_num.count()}')#even_num.count 5
print(f'after the first action operator the accumulator is {acc}')#after the first action operator the accumulator is 5
# 对缓存进行释放
even_num.unpersist()
print(f'even_num.collect {even_num.collect()}')#ven_num.collect [2, 4, 6, 8, 10]
print(f'after the second action operator the accumulator is {acc}')#after the second action operator the accumulator is 10
'''
【分析】这是因为第一次action算子操作后,存在一步释放缓存的操作,当执行第二个action算子时,
首先会将rdd的缓存释放,然后再对rdd进行collect操作,而由于rdd没有被缓存,
因此想要被collect必须从头计算,那么累加器又一次被重新计算,因此又变为两倍。
'''
sc.stop()