Node.js 中的 Buffer 和字符编码
众所周知,数据在网络中是通过二进制传输的,在 Node.js 中,Buffer 对象就是用于处理这些二进制数据。举个例子:
console.log(Buffer.from('abcde'))
会输出:
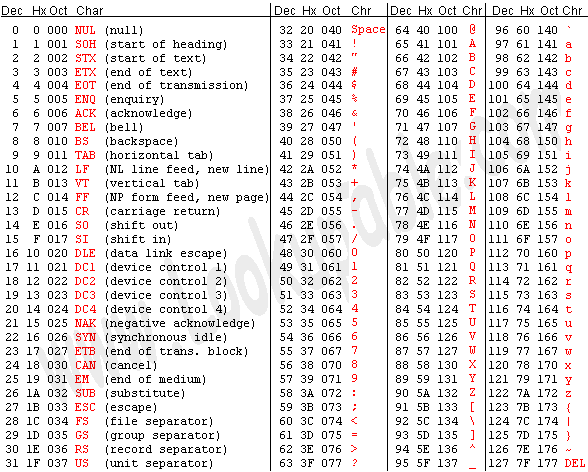
你可能会觉得奇怪,这里的 61、62 到 65 的数字是什么,其实这是字符 a 到 e 的 ASCII 码所对应的 16 进制,下图是标准 ASCII 码表:
ASCII 码
可以看到标准 ASCII 码使用 7 位二进制数来表示大小写字母、数字、标点符号以及控制字符。所以总共能够表示 2 的 7 次方,也就是 128 个字符。用哪些二进制数字表示哪个符号,每个人都可以约定自己的一套,这就是所谓的编码。而 ASCII 码就是标准化组织给出的标准答案,统一规定了上述常用符号用哪些二进制数来表示。在 ASCII 码中,前 0~31 个以及最后一个(即127),共 33 个控制字符,例如 LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格) 等:

剩下的都是可显示字符,或者叫可打印字符:
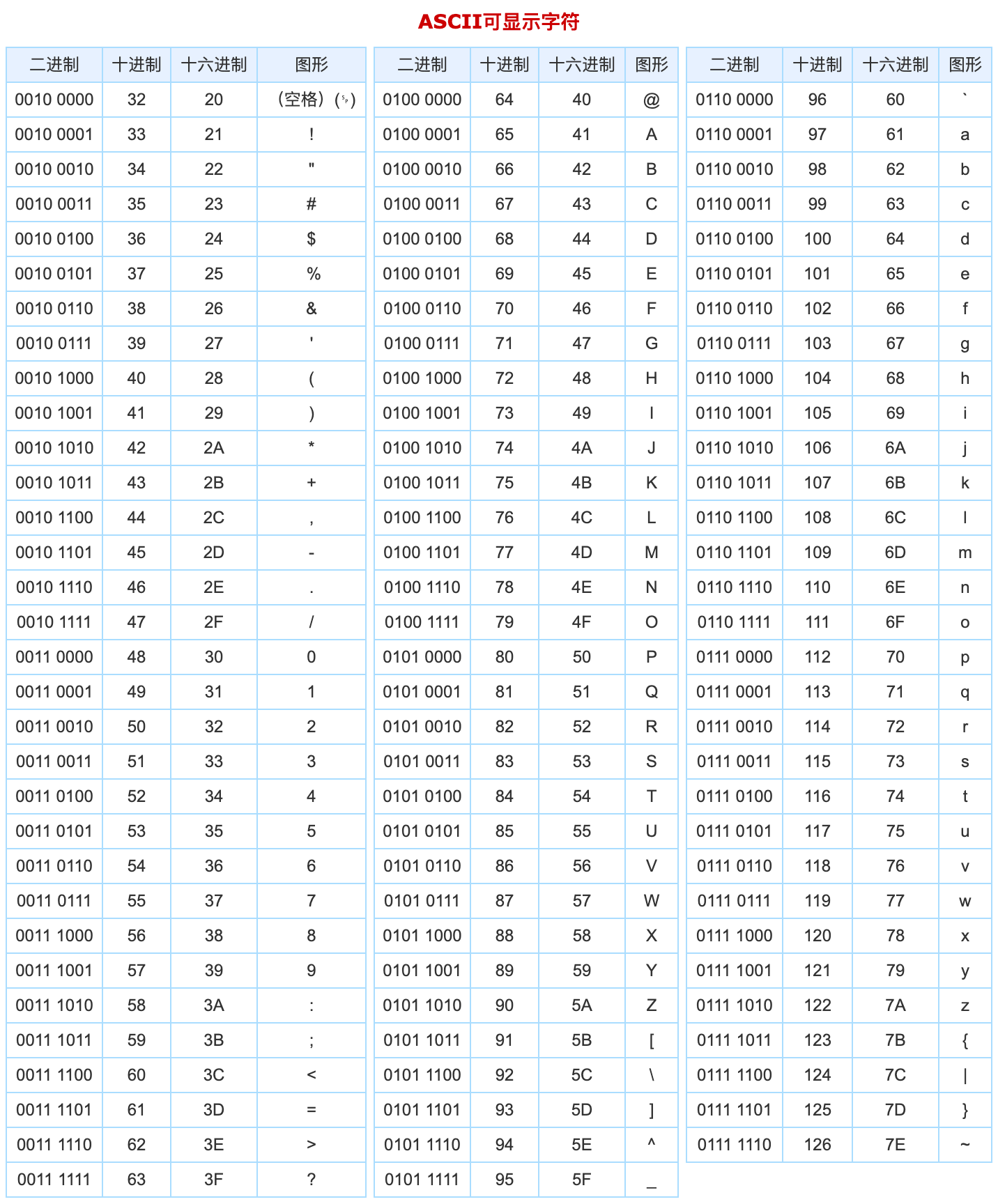
知道了 ASCII 码的编码规则之后,我们回到最开始的问题:
console.log(Buffer.from('abcde'))
// 其实答案很明显,我们去 ASCII 码表中找到 a 到 e 对应的十六进制表示,发现恰好是 61 到 65。因此,Buffer.from 方法除了可以接收字符串作为参数之外,还可以直接接收十六进制数组,即上述写法也可以写成:
console.log(Buffer.from([0x61, 0x62, 0x63, 0x64, 0x65]))
// 注意,61 到 65 是十六进制的数字,千万不能写成十进制:
console.log(Buffer.from([61, 62, 63, 64, 65]))
// 这个就不再表示 abcde,而是表示 =>?@A 了。另外,需要注意,当使用数组的时候,数组中的每一项只能填 0x00 到 0xff 之间的数,即十进制范围从 0 到 255,因为一个字节最多能表示 256 个字符。
Unicode 字符集和 UTF-8 编码
上面讲了,ASCII 码只能表示 128 个字符,那拉丁字符或中国汉字怎么表示呢?我们不妨试下:
console.log(Buffer.from('abcde')) // 可以发现,英文字母 e 占用了 1 个字节,法语中的 é 占用了 2 个字节 0xc3a9,中文 易 占用了 3 个字节 0xe69893。如果我们指定使用 ASCII 编码的话,结果如下:
console.log(Buffer.from('abcdé', 'ascii')) // 即 é 用 1 个字节 0xe9 表示,易 用 1 个字节 0x13 表示,这是怎么回事呢?
这就涉及到 Unicode 字符集了,由于 ASCII 编码能表示的字符实在是太少了,于是诞生了将世界上所有语言的所有字符放到一起想法,这就是 Unicode 集合,它从 0 开始,为每个符号指定一个编号,叫做码点(code point)。由于符号很多,Unicode 将其分成了 17 个平面(平面 0 至 16),码点范围从 0x0000 至 0x10FFFF,每个平面有 65536 个码点,能表示 100 多万个字符,第 0 个平面叫做基本平面,剩下 16 个平面都是辅助平面,各平面码点范围和作用如下:
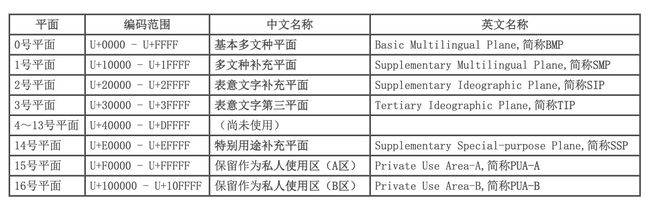
其中最重要的是 0 号平面 BMP,容纳了最前面的 65536 个字符位,大部分常用的字符都在这个平面内,比如 ASCII 字符和常用汉字等。通过查表发现 é 的 Unicode 的码点是 U+00E9,易 的码点是 U+6613,注意这里的码点只是一种排序方式,规定了 Unicode 字符的顺序,还没有涉及到字符编码层面。由于最大的码点是 U+10FFFF,所以编码的时候,至少需要 3 个字节。最直观的编码方法是,每个码点使用四个字节表示,字节内容一一对应码点,这种编码方法就叫做UTF-32。 这种编码的优缺点非常明显:
- 优点:能够与 Unicode 码点完全对应,查找效率非常高,是 O(1)。
- 缺点:存在空间的浪费,例如 ASCII 码用 1 个字节就能表示,保存后空间大 4 倍。
因此当强制使用 ASCII 编码解读二进制数据时,我猜测就只保留了码点的最后一个字节,即 UTF-32 编码的最后一个字节。
那为什么会用 0xc3a9 表示 é,0xe69893 表示 易 呢?这是 UTF-8 变长编码导致的,刚才也讲了,Unicode 只是个字符集,可以有很多种编码方式,Node.js 中默认使用 UTF-8 编码,而在 UTF-8 编码中,一个字符可能用 1 到 4 个字节来表示。它的规则非常简单:如果开头是 0,那么就占 1 个字节,兼容 ASCII 码,如果开头是 1,那么有多少个连续的 1 就表示占据多少个字节,例如:
- é 的 UTF-8 二进制表示为
11000011:10101001,开头是 11 所以占据 2 个字节 - 易 的 UTF-8 二进制表示为
11100110:10011000:10010011,开头是 111 所以占据 3 个字节
下图描述了不同码点的字符分别用几个字节表示:
| 编号范围 | 字节 |
|---|---|
| 0x0000 - 0x007F | 1 |
| 0x0080 - 0x07FF | 2 |
| 0x0800 - 0xFFFF | 3 |
| 0x010000 - 0x10FFFF | 4 |