小程序二进制图片 buffer存储_系统性学习 Nodejs(4)——Buffer
往期传送门
Node.js 基础概念
手写 require
手写 events(发布订阅)
Buffer 是什么
在 Node 中,我们总是会遇到处理二进制数据的情况,比如文件操作、图片处理、网络 IO 等等。为了能够处理二进制数据,Node 引入了 Buffer。
归根结底,Buffer 是一个存储二进制数据的特殊对象,它对外暴露了操作二进制数据的能力。
计算机是如何存储数据的
非科班出身的程序员可能对二进制都非常陌生,这里简单的科普一下,以助于更好的理解 Buffer,了解这方面的同学可以直接略过。
计算机的存储单位
- bit(位):最小的存储单位,1 位只能存储一个 0 或 1。
- byte(字节):计算机的基本存储单位,由 8 位组成。
- 字:计算机进行数据处理时,一次存取、加工和传送的数据长度称为字。常说的 64 位操作系统即是说,一次可以操作 64 位(8 字节)的数据。这里的 64 位称为一个字。
如下图所示,一个每个方格即是 1 位,8 个方格即是 一个字节。

原谅我这丑陋的画图技术。
如何存储数字
我们常见的数字进制有 10 进制、8 进制、16 进制。
以 10 进制为例:数字 8 转换为 2进制为 1 0 0 0 , 其存储结构大概如下图所示。

一个基本存储单元为 1 字节即 8 位,而这里只有 4 位,空余 4 位都补 0.
这里只是大概的描述,js 具体的存储规则遵循 IEEE 754 规范
如何存储英文
根据 ASCII 表将每个字符对应的 ASCII 值转成二进制存储到计算机中。
ASCII 表如下图所示:
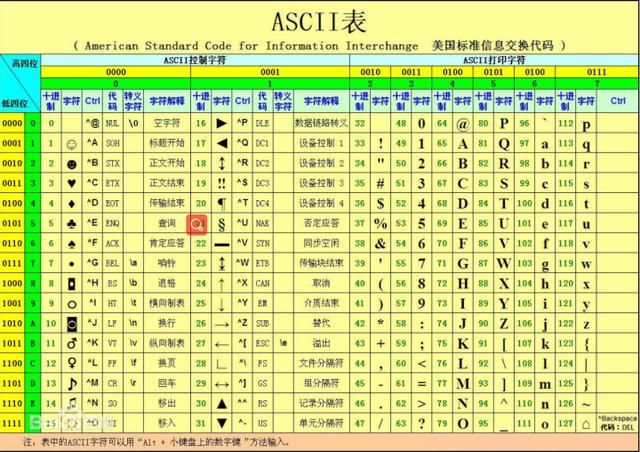
、
举个例子:
一个字母 A 对应的 ASCII 码为 81,81 对应的二级制为 1010001,所以其存储结构为:
0 0 1 0 1 0 0 0 1
如何存储汉字
一般都会根据 GBK 规范,将每个汉字转换成对应的编码,类似于 ASCII 码,只不过比它更复杂点。根据 GBK 编码,一个汉字占两个字节。毕竟汉字多嘛,一个字节肯定表示不了(因为一个字节最多能表示 2^8 - 1 即 255 个字符)。
如何存储所有字符
目前英文跟汉字都可以存储了,但是当两种字符都存在的情况下,我该按照哪种规范去编码呢?
- Unicode
这是 Unicode 国际组织用来容纳世界上所有字符的一个编码规范,它是一个字符集,包含了所有字符。由于编码众多,所以采用 4 个字节表示。
如果它仅是一个英文字符的话,就会白白浪费 3 个字节的空间(英文字符只占 1 字节的空间),所以浪费了极大的内存。
- utf-8
它是针对 Unicode 的一种可变长度字符编码,可以用来表示Unicode标准中的任何字符。它会根据不同的语言字符采用不同的字节数去编码,所以完美解决了 Unicode 字符集的问题。
使用 Buffer
OK OK OK
圆规正转,让我们进入正题。
使用 Buffer.from(string) 创建一个 Buffer 实例。
const buf = Buffer.form('hello word')console.log(buf) // 可以看到我们打印的是个 Buffer 的实例,但是奇怪的是这个实例展示的并不是我们所说的 2 进制,而十 16 进制。
这是为了方便我们查看,Node 在显示的时候,给转换成了 16 进制,其实内部仍然是 2 进制。
Buffer.from(string) 支持多种编码方式。
const buf = Buffer.from('runoob', 'ascii');// 输出 72756e6f6f62console.log(buf.toString('hex'));// 输出 cnVub29iconsole.log(buf.toString('base64'));如上所示,可以将字符串以 ASCII 码的方式转成对应的二进制 Buffer。打印的时候,可以用任何编码方式去查看。
Node 目前支持的编码方式有:
- ascii
- utf8
- utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符。
Buffer.from(array|arrayBuffer|buffer)
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。const buf1 = Buffer.from([1, 2, 3]);// 复制 buf1,并返回一个新的 bufferconst buf2 = Buffer.from(buf1);// 创建一个包含 8 个字节的 arrayBufferconst arrayBuffer = new ArrayBuffer(4)// 返回一个 Buffer 实例,它跟 arrayBuffer 共享同一个内存空间,这个空间从索引为 1 的内存开始,长度位 1 一个字节。const buf3 = Buffer.from(arrayBuffer, 1, 2)Buffer.alloc(size[, fill[, endcoding]])
返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0。
// 创建一个长度为 10、且用 0 填充的 Buffer。const buf1 = Buffer.alloc(10);// 创建一个长度为 10、且用 0x1 填充的 Buffer。 const buf2 = Buffer.alloc(10, 1);Buffer.allocUnsafe(size)
返回一个没有被初始化的 Buffer,由于没有内存没有被初始化,所以可能含有一些其它的数据。
// 创建一个长度为 10、且未初始化的 Buffer。// 这个方法比调用 Buffer.alloc() 更快,// 但返回的 Buffer 实例可能包含旧数据,const buf3 = Buffer.allocUnsafe(10);写入 Buffer
buf.write(string[, offset[, length]][, encoding])
参数描述:
- string:写入 buffer 的字符串
- offset:开始写入 buffer 的索引值,默认为 0
- length:写入 buffer 的长度
- encoding: 写入 buffer 字符串的字符编码
返回值:
返回实际写入的长度
const buf = Buffer.alloc(8)// 从索引为 1 的位置写入 0x61 0x61buf.write('aa', 1) // 输出:读取 Buffer
buf.toString([encoding[, start[, end]]])
参数:
- encoding - 使用的编码。默认为 'utf8' 。
- start - 指定开始读取的索引位置,默认为 0。
- end - 结束位置,默认为缓冲区的末尾。
buf = Buffer.alloc(26);for (var i = 0 ; i < 26 ; i++) { buf[i] = i + 97;}console.log( buf.toString('ascii')); // 输出: abcdefghijklmnopqrstuvwxyzconsole.log( buf.toString('ascii',0,5)); //使用 'ascii' 编码, 并输出: abcdeconsole.log( buf.toString('utf8',0,5)); // 使用 'utf8' 编码, 并输出: abcdeconsole.log( buf.toString(undefined,0,5)); // 使用默认的 'utf8' 编码, 并输出: abcde合并 Buffer
Buffer.concat(list[, totalLength])
- list - 用于合并的 Buffer 对象数组列表。
- totalLength - 指定合并后Buffer对象的总长度。
返回值:返回多个成员合并的新 Buffer 对象。
const b1 = Buffer.from(('w'));const b2 = Buffer.from(('y'));const b3 = Buffer.concat([b1,b]);console.log(b3);// 输出:// wy裁剪 Buffer
buf.slice([start[, end]])
- start - 数字, 可选, 默认: 0
- end - 数字, 可选, 默认: buffer.length
返回值:返回一个新的 Buffer,它与旧的 Buffer 执行同一块内存。
const b2 = Buffer.alloc(8)const w = b2.write('aa', 1)// 裁剪 b2const b3 = b2.slice(1, 4)// 输出 b3// 由于 b2 跟 b3 共用同一个内存空间,所以,改变 b2 的内存,b3 也会变。b2.write('a', 3)// 输出 b3// console.log(b3)以上就是 Buffer 的常用方法,更多的方法可以查看 Node 的官方文档。
Buffer 有什么用?
说了这么多,那 Buffer 到底有什么用呢?我们举个简单的例子。
假如让我们实现一个文件拷贝的功能,即把文件 A 复制到文件 B,我们要怎么做?
- 读取文件 A
- 将文件 A 的内容写入到文件 B
所以我们很容易写出这样的代码。
const fs = require('fs')fs.readFile('a', (err, data) => { console.log(11, data.toString()) fs.writeFile('b', data, () => {})})对 fs 不熟悉的朋友我先简单介绍一下,详细介绍会在下一篇文章给出。 fs.readFile: 读取文件 fs.writeFile: 写入文件
这里我们很轻松的实现了文件的拷贝,但是这里有个很严重的问题:读取的文件是一次性的写入到内存,如果我们的文件很大,比如有 8g,而我们的内存只有 4g,那电脑直接卡死,这显然不是我们想要的效果。
那我们该如何解决这个问题呢?
这时候我们就可以用 Buffer。每次读取的时候我们可以控制读取的大小,比如 4 字节。读完 4 字节之后,将这部分内容写入到 Buffer,然后再从 Buffer 写入到文件内。所以现在的步骤大概是这样:
- 从 A 内读取 4 字节内容
- 将这 4 字节内容写入到 Buffer
- 将 Buffer 内的内容写入到文件 B
- 重复上述步骤直到复制完成
这样我们就完美解决了这个问题,完整代码如下:
function copy() { const BUFFER_LEN = 4 // 每次读取的字节长度 const buf = Buffer.alloc(BUFFER_LEN) // 申请 4 字节的 Buffer let pos = 0 // 记录每次读取的位置 // 以可读的方式打开 a 文件,权限为 0o66,意为可读写 fs.open('./a', 'r', 0o666, (err, rfd) => { // 以可写的方式打开文件 b fs.open('./b', 'w', 0o666, (err, wfd) => { const next = () => { // 从 pos 位置开始读取 BUFFER_LEN 个字节, // 将读取的字节写入到 buf 内,写入的开始位置为 0 fs.read(rfd, buf, 0, BUFFER_LEN, pos, (err, bytesRead) => { // 将 buf 的内容写入到 b 文件内,开始索引为 0 // 写入到文件 b 的长度为实际读取的字节数(bytesRead),因为读取的字节可能小于 BUFFER_LEN,比如最后一次读取 // 从第 pos 个字节开始写入 fs.write(wfd, buf, 0, bytesRead, pos, () => { console.log('写入') pos += bytesRead if (!bytesRead) { return } next() }) }) } next() }) })}不熟悉的文件操作的同学不要着急,我下篇文章会专门介绍,这里先了解思路即可。 其实,这也是 流(stream) 的核心思路
如果你阅读完此文能够对你有帮助,希望能得到你的点赞认可。
这是系统性学习 Nodejs 的第四篇内容,后续会持续输出,如果感兴趣,欢迎关注我的专栏。