【课程笔记】计算机体系结构复习笔记
文章目录
- 第一章 基本原理
-
- 计算机系统层次与体系结构
- 测量及分析性能
- 计算机设计量化原理
- 计算机体系结构分类
- 第二章 指令集体系结构
-
- 指令集分类
- 存储器地址的翻译
- 寻址模式
- 优化指令格式
- 指令集操作
- RISC与CISC
- 第三章 流水线
-
- 流水线
- MIPS基本流水线
- 流水线冒险
- 数据冒险
- 控制冒险
- 流水线多周期操作
- 利用动态调度解决数据冒险
- 减少动态预测分支惩罚
- 利用多发射提高ILP
- 第四章 存储器层次
-
- 简介
- 缓存基础
- 测量并提升Cache性能
- 虚拟存储器
- 储存结构框架
第一章 基本原理
计算机系统层次与体系结构
计算机系统层次:应用语言机、高级语言机、汇编语言机、操作系统机、传统机、微程序机
相同指令集体系结构可以有不同的组织(不同的内存系统、总线、CPU等),相同的指令集体系结构何组织在硬件实现上可以不同。
体系结构属性:指令集、I/O机制、寻址技术、数据类型的位数
体系结构在组织方面对程序员是不可见的(transparent)。
体系结构的设计考虑速度、成本、物理器件大小和功耗(power),如乘法单元(成本高、物理器件较大,但速度快)和加法单元迭代使用(相对速度低,但廉价)用以实现乘法。
摩尔定律:晶体管密度及性能每18-24个月翻一番。(已不再适用)
测量及分析性能
性能(performance)的影响因素:响应时间(response time, elapsed time)(反应快慢)、执行时间(运行快慢,评价性能的主要因素)、吞吐量(throughput)(一次性处理数据多少)
执行时间是性能的倒数。
反应时间的定义:硬盘访问、内存访问、I/O操作、系统开销(operating system overhead)所造成的延迟。
执行时间的定义:
- CPU时间:CPU执行计算所用时间,不包括I/O等待及运行其他程序所用时间。
- CPU时间又可分为:
- 用户CPU时间:程序所占用的CPU时间。
- 系统CPU时间:操作系统响应程序请求所占用的CPU时间(与响应时间不同)。
使用程序评估性能的方法:
- 真实应用进行评估(最精确)
- 核心应用(Kernels)进行评估:使用真实程序中的关键片段进行性能评估。
- 玩具测试基准(Toy benchmarks):小型程序进行评估,结果已知。
- 合成测试基准(Synthetic benchmarks):整合多种应用的benchmark,包括核心程序和真实程序。
比较性能方法:
-
总体执行时间:各测试程序总的执行时间,该方法在计算机执行程序次数相同时可用。
-
平均执行时间: 1 n ∑ i = 1 n T i m e i \frac{1}{n}\sum^{n}_{i=1}Time_i n1∑i=1nTimei
-
加权执行时间:程序执行频率不同时可用。
- 指明程序出现的相对频率或权值设定与执行时间成比例: ∑ i = 1 n W e i g h t i × T i m e i \sum_{i=1}^{n}Weight_i\times Time_i ∑i=1nWeighti×Timei
-
归一化执行时间:选定参考机,进行归一化,再利用归一化后的数值进行平均,求平均数可使用算数平均数或几何平均数( ∏ i = 1 n E x e c u t i o n t i m e r a t i o n \sqrt[n]{\prod_{i=1}^{n}Execution\ time\ ratio} n∏i=1nExecution time ratio),最终:
实 际 性 能 = 归 一 化 数 × 参 考 机 性 能 实际性能=归一化数\times 参考机性能 实际性能=归一化数×参考机性能
计算机设计量化原理
阿姆达尔定律(Amdahl’s Law):由某些部分加速所得到的性能提高受加速部分的百分率所限。
- 加速比(Speedup):
加 速 比 = 增 强 后 的 性 能 增 强 前 的 性 能 加速比=\frac{增强后的性能}{增强前的性能} 加速比=增强前的性能增强后的性能
- 新的执行时间:
执 行 时 间 n e w = 执 行 时 间 o l d × ( ( 1 − 未 增 强 部 分 占 比 ) + 增 强 部 分 占 比 加 速 部 分 加 速 比 ) 执行时间_{new}=执行时间_{old}\times((1-未增强部分占比)+\frac{增强部分占比}{加速部分加速比}) 执行时间new=执行时间old×((1−未增强部分占比)+加速部分加速比增强部分占比)
- 总加速比:
总 加 速 比 = 执 行 时 间 o l d 执 行 时 间 n e w = 1 ( 1 − 未 增 强 部 分 占 比 ) + 增 强 部 分 占 比 加 速 部 分 加 速 比 总加速比=\frac{执行时间_{old}}{执行时间_{new}}=\frac{1}{(1-未增强部分占比)+\frac{增强部分占比}{加速部分加速比}} 总加速比=执行时间new执行时间old=(1−未增强部分占比)+加速部分加速比增强部分占比1
回报递归法则(the law of diminishing returns):对于一部分性能的提高,总体加速比的提高呈递减状态,即贡献越来越少、有上界。
CPU性能方程:
C P U 时 间 = 时 钟 周 期 数 ( C P U c l o c k c y c l e s ) × 时 钟 周 期 时 间 ( C l o c k c y c l e t i m e ) CPU时间=时钟周期数(CPU\ clock\ cycles)\times时钟周期时间(Clock\ cycle\ time) CPU时间=时钟周期数(CPU clock cycles)×时钟周期时间(Clock cycle time)
C P U 时 间 = C P U 时 钟 周 期 数 时 钟 频 率 ( C l o c k r a t e ) CPU时间=\frac{CPU时钟周期数}{时钟频率(Clock\ rate)} CPU时间=时钟频率(Clock rate)CPU时钟周期数
CPI:
C P I = 程 序 所 需 总 C P U 时 钟 周 期 数 指 令 数 ( I n s t r u c t i o n c o u n t , I C ) CPI=\frac{程序所需总CPU时钟周期数}{指令数(Instruction\ count, IC)} CPI=指令数(Instruction count,IC)程序所需总CPU时钟周期数
从而可推出:
C P U 时 间 = 指 令 数 × C P I × 时 钟 周 期 时 间 CPU时间=指令数\times CPI\times 时钟周期时间 CPU时间=指令数×CPI×时钟周期时间
由于改变时钟周期时间、CPI、指令数其一时,很难不改变其他部分,故有以下计算CPI方法:
C P U 周 期 数 = ∑ i = 1 n I C i × C P I i CPU周期数=\sum_{i=1}^{n}IC_i\times CPI_i CPU周期数=i=1∑nICi×CPIi
测量CPU性能的各组成部分:
- 时钟周期:
- 已完成设计:利用时延评估器(timing estimators)或时延验证器(timing verifiers)
- 未完成设计:考察关键路径(critical paths)
- 指令数测量:利用编译器及测试指令集行为的工具
- 指令集模拟器(instruction set simulator):慢,但精确测量指令集行为的几乎所有方面。
- 基于执行的监控(execution-based monitoring):快,通过修改程序(插桩代码)。
- CPI测量困难:现代处理器存在流水线和存储层次,需要考虑流水线和cache结构。
C P I i = P i p i l i n e C P I i + M e m o r y s y s t e m C P I i CPI_i=Pipiline\ CPI_i+Memory\ system\ CPI_i CPIi=Pipiline CPIi+Memory system CPIi
引用局部性:程序倾向于重用刚使用过的数据和指令。
计算机体系结构分类
指令数据流类型:
- 单指令流单数据流(single instruction stream over a single data stream)
- 单指令流多数据流
- 多指令流多数据流
- 多指令流单数据流

传统顺序机器为SISD的。

向量计算机(vector computer,流水线结构的计算机)为SIMD的。

并行计算机(parallel computer)为MIMD的。

MISD的计算机仅存在于实验,尚无实际应用。
第二章 指令集体系结构
指令集分类
体系结构分类:

- 寄存器-存储器体系结构(register-memory architecture)
- 优点:数据可以不用被分别装入内存,并且指令格式也会更加简单。
- 缺点:操作数不等长,所用时时钟不同。
- 寄存器-寄存器体系结构
- 优点:指令简单,执行时时钟相似。
- 缺点:指令条数增加。
- 存储器-存储器体系结构(暂无,速度较慢,指令长短不一)
- 优点:不浪费寄存器。
- 缺点:指令长度不一,存储器不能被共享。
通用寄存器计算机(GPR,general-purpose register machine)优势:
- 寄存器速度快;
- 寄存器易于编译器有效使用。
GPR结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9kInLVnf-1655391892109)(https://s1.ax1x.com/2022/06/14/X5nfSO.png)]
- 三操作数模式(three-operand)
- 二操作数模式:一个操作数既是源操作数也是结果操作数。
存储器地址的翻译
所有指令集都是按字节寻址(byte addressed),可访问字节(8 bits)、半字(16 bits)、字(32 bits),多数计算机也可访问双字(64 bits)。
字节排序:
- 小端序(Little Endian):高对高,低对低。如x86-64。
- 大端序(Big Endian):高对低,低对高。如MIPS。
**对齐(align)**问题:某些存储可能要求对齐,⚠️需要注意

寻址模式
寻址时可使用常数(constant)、寄存器、存储地址(有效的存储地址为有效地址(effective address))。


一个指令集体系结构最少需支持位移寻址(displacement addressing)、立即数寻址(immediate addressing)、寄存器间址(register deferred)。
优化指令格式
指令格式构建主要使用哈夫曼编码(Huffman coding)。
每个字符平均最少所需位:
H = − ∑ i = 1 n P i ⋅ log 2 P i H=-\sum_{i=1}^{n}P_i\cdot \log_{2}{P_i} H=−i=1∑nPi⋅log2Pi
固定长度编码冗余度(redundancy):
R = 1 − − ∑ i = 1 n P i ⋅ log 2 P i ⌈ log 2 n ⌉ R=1-\frac{-\sum_{i=1}^{n}P_i\cdot \log_{2}{P_i}}{\lceil\log_{2}{n}\rceil} R=1−⌈log2n⌉−∑i=1nPi⋅log2Pi
构造哈夫曼树,从而得到前缀码(prefix )。

由于前缀码结构不整齐,故使用扩展码(extended opcodes)折中。扩展码保证了一定范围内的编码长度相同。
操作数 × {\times} ×寻址模式的组合最大时,每个操作数用寻址标识符(address specifier)。
指令集编码方式:
- 变长(variable):允许所有操作有任何寻址模式。
- 定长(fixed):将操作和寻址模式结合到操作码域。
- 混合(hybrid):折中。
指令集操作
控制流指令:
- 条件转移(conditional branches):有条件
- 跳转(jump):无条件
- 过程调用(procedure calls,procedure invocation)
- 过程返回(procedure returns)
控制流指令最常用的是PC相对(PC-relative)寻址。
条件转移选项:

条件码(CC)就是汇编里学的CF、OF、ZF,条件寄存器就是使用寄存器判断跳转,比较与分支就是直接将比较和跳转合二为一。
过程调用选项:
- 调用者保存(caller saving):谁调用谁保存
- 被调用者保存(callee saving)
RISC与CISC
RISC(reduced instruction set computer,精简指令集计算机)特点:
- 指令类型少,运行快
- 指令简单
- 使用更少的晶体管,设计制造便宜
- 硬连线控制(hardwired control),即固化在电路中
- 与存储器的寻址关联操作少,只用LOAD和STORE
- 所用寄存器多
CISC(complex instruction set computer,复杂指令集计算机)特点:
- 指令多
- 复杂且高效(efficient)
- 由于指令复杂,故需分步实现,即微命令
- 寻址能力强(extensive)
- 所用寄存器较少
指令执行步骤:取指(instruction fetching)、译码(decoding phase)、取操作数(operand fetching phase)、执行(execution phase)、写回(write-back phase)
MIPS是RISC体系结构的一种:
- load-store 指令集
- 定长编码,32 bits
- 高效
- 拥有32个寄存器,每个32 bits,0号寄存器总是保存0,31号及储存期用来存储一些MIPS指令;此外还有用于存储浮点数的浮点寄存器(FPR,32位或64位)
- 支持字节及半字
⚠️MIPS使用的是大端序,需对齐
MIPS指令格式(32位指令,6位操作码):

⚠️上图中的高低位标号应该相反(31-0)。
第三章 流水线
流水线
平衡流水段长度:
非 流 水 线 机 器 上 每 条 指 令 的 所 用 时 间 流 水 段 数 量 \frac{非流水线机器上每条指令的所用时间}{流水段数量} 流水段数量非流水线机器上每条指令的所用时间
MIPS基本流水线
MIPS流水线的五个步骤:IF、ID、EX、MEM、WB

IF阶段:取指到指令寄存器,PC+1。
ID阶段:对指令进行解码,从寄存器中取值。

EX阶段:ALU指令(ADD之类)进行计算,LOAD-STORE指令计算地址,Branch指令计算地址。

MEM阶段:ALU指令啥也不做,LOAD指令访问数据存入LMD,STORE指令访存存入数据。
WB阶段:ALU指令写回,LOAD指令将数据写入寄存器。
时钟周期与CPI取舍:降低CPI会导致电路复杂,进而时钟周期增加。
流水线结构:

流水线的基本性能问题:
- 流水线增加了吞吐量;
- 由于控制开销,指令运行时间增加;
- 但由于吞吐量的增加,程序运行更快。
影响流水线性能的因素:
- 存在水桶效应,不平衡;
- 流水线存在开销:
- 寄存器启动时间(register setup time):输入需要进行稳定,并且有传播(propagation)时延
- 时钟偏差(clock skew):信号传输时延
流水线冒险
解决冒险(hazards)最简单的方法:阻塞(stall)
加 速 比 = 未 流 水 化 C P I 或 流 水 线 段 数 1 + 流 水 线 阻 塞 周 期 加速比=\frac{未流水化CPI或流水线段数}{1+流水线阻塞周期} 加速比=1+流水线阻塞周期未流水化CPI或流水线段数
结构冒险(structural hazards):
- 不完全流水化造成阻塞
- 一些资源未足够复制
- 写冲突
- 访问冲突(只有一个内存入口时,从内存中,IF段取值,MEM段访问数据)
数据冒险
通过加入硬件结构,可以解决数据冒险:
- 设置指令缓存和数据缓存;
- 设置指令缓存存储指令。

数据冒险:使用前送(forwarding)解决数据冒险。特别需要注意的是,在同一阶段使用同一寄存器,也可能产生前送 。前送可以是相同时间,前送可以先获得数据旧数据,后续比较进行更新。

- 写后读(RAW)
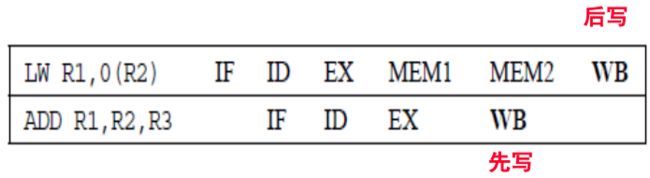
- WAW:该种不会在MIPS中出现,若出现那就stall。

- WAR:上图会造成读假数据。
- RAR:非数据冒险
由于某些冲突过于频繁,故可以通过调度来解决冲突。
发射(instruction issue):ID→EX,对于MIPS整数流水线,所有冒险都能在ID阶段检测出来。
- 早解决:不用将指令悬挂,降低硬件复杂性;
- 在使用操作数的周期才检测冒险或前送。
解决LOAD指令的RAW:
堵塞的实现:ID/EX流水线寄存器的控制部分(control portion)全部置零,做空操作(no-op);IF/ID寄存器内容循环(recirculate),保持停顿。
控制冒险
控制冒险可能比数据冒险造成的性能损失更大(great performance loss)。

最简单的方法:直接阻塞,知道到达MEM计算出新的PC
MIPS中将转移测试移动到了ID阶段(增加了额外的加法器和零测试),并且在IF阶段写PC,ID阶段计算出目标地址。从而转移在ID结束后就完成,未使用EX、MEM、WB。
降低转移造成的惩罚:
- 冻结(freeze)或泄放(flush):保持或删除转移指令后的指令,知道转移目的地址已知。
- 预测不成功,若成功在将已去除的指令变为no-op,并重新取值。
- 预测转移成功。
- 延迟转移:使用延迟槽(branch-delay slots)。延迟槽有三种分支调度方法:
- 指令来自以前,最好。
- 指令来自成功目标。
- 指令来自不成功目标。
流水线多周期操作

浮点操作会占用多个周期,需要充分很多次EX。
潜伏期(latency):从产生结果(假定在EX阶段第一周期产生结果)到使用结果之间的周期数。
初始/重复间隔(initiation/repeat interval):发射两个给定类型操作之间必须经过的周期数。


潜伏期和初始间隔:

其中,除法未完全流水化。其他则在EX中进行流水化。
长延迟流水线(Longer Latency Pipelines)的冒险和前送:
- 除法未完全流水化,可能导致结构冲突。
- 指令运行时间不同,可能导致同一周期有多个寄存器写操作,造成结构冲突。
- 指令不再按序到达WB,可能导致WAW冒险。
- 寄存器读总在ID发生,所以不会有WAR冒险。后续更改与前面无关。
- 长延迟导致RAW冒险更频繁。
EX阶段多种操作单元可以并行进行。
写寄存器冲突:可增加端口,从而解决结构冲突。
解决结构冲突的途径:
- 早解决,在ID阶段跟踪写端口的使用,并在发射前阻塞指令。
- 优点:其可以在ID阶段就完成互锁检测和阻塞插入。
- 成本:要加入移位寄存器和写冲突逻辑。
- 到时候再解决:在冲突指令要进入MEM或WB时再阻塞。
- 优点:直到MEM或WB才检测冲突,更容易。
- 缺点:流水线控制复杂化,可以从两个地方插入阻塞。
解决WAW途径:
- 早解决,延缓load发射,直到ADDD进入MEM。
- 到时候再解决: 检测到冒险,就改变控制,使ADDD不写结果。
检测所有可能的冲突:在ID阶段做三个检测
- 等待,直至功能单元能用。(仅除法)
- 检测RAW冒险。
- 检测WAW冒险。
利用动态调度解决数据冒险
解决冲突的途径:
- 静态调度
- 动态调度(Tomasulo方法):
- 发射(issue):取值。
- 若为FP操作,有空保留站,则发射。若操作数在寄存器中就送保留站。
- 若为L-S操作,有缓冲器空间,则发射。
- 无空保留站或空缓冲器,则结构冒险,指令阻塞等待。
- 执行(execute)
- 若有操作数计算出来,则放入相应保留站(Q置0,数放V)。
- 两个操作数都计算出来,就在功能单元中执行操作。
- 检测RAW冒险
- 写结果(write result):计算出结果,写道CDB上。
- 发射(issue):取值。


具体操作如下图:



减少动态预测分支惩罚
使用基本转移预测(Basic Branch Prediction)和转移预测缓冲器(Branch Prediction Buffers)。
基本转移预测:
- 2位预测方案:错两次才改变预测。
- N位预测方案:计数器可取值0到 2 n − 1 2^n-1 2n−1。当 ≥ 2 n – 1 2 ≥\frac{2^n– 1}{2} ≥22n–1时,预测转移; 否则,预测不转移。
转移目标缓冲器(Branch-Target Buffers):存储所预测的转移后的下条地址。
转移预测缓冲器和转移目标缓冲器的区别:
- 转移预测缓冲器:在ID阶段被访问,ID末才知道转移目标地址。
- 转移目标缓冲器:用IF阶段来取指令的地址访问缓冲器,命中就能知道预测地址。

图中,命中但预测错误、未命中但预测正确都要更新缓冲器并且重新取指,需消耗2个周期。
利用多发射提高ILP
超标量处理器(superscalar processors):
- 每个周期发射不同数量的指令,指令间不能互相干扰、互斥
- 可用编译器进行静态调度,或者采用Tomasulo进行动态调度
超长指令字处理器(VLIW processors)
- 发射固定数量的指令,格式化成一个大指令(固定指令包),负担在编译器上而非硬件
- 用调度器进行静态调度
第四章 存储器层次
简介
局部性原理(principle of locality):程序在任意时刻都是访问地址空间的一小部分。
- 时间局部性(temporal locality)
- 空间局部性(spatial locality)
存储器层次理论基础是局部性原理。
存储器:
- SRAM:静态RAM
- DRAM:动态RAM,较SRAM便宜但慢
- magnetic disk:磁盘
当命中率足够大,则访问时间接近最高层,大小接近最底层。
缓存基础
cache中寻找/储存数据的方法:
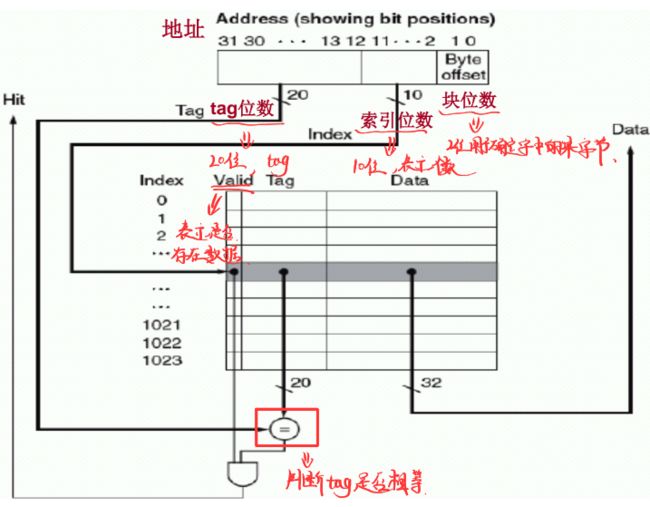
此处的块位数其实就是块内偏移,由于机器是32位机,有4 Bytes,所以2位。
- 直接映像:
- 低位部分用于索引;
- 剩余高位部分作为tag进行对比确认。
cache缺失问题解决:阻塞CPU,冻结所有寄存器中的内容;从存储器中取出数据放入cache;重新在导致缺失的地方进行执行。
对cache进行写操作时,可能遇见写缺失(write miss),仅需将数据写入cache并更新cache和数据。在写入cache时,可能需要将数据送回到内存:
- 通写(write-through):处理简单但效率不高,每次写cache都会导致数据写入主存。
- 解决写入主存慢的问题,可以使用写缓冲器(write buffer),从而使其进行匹配。
- 写回(write-back):当发生替换时,被修改的块才写入主存。
若要利用局部性原理,则cache可以使用类似组相联的结构,但其区别是该cache中同一行的数据必须同时写入。


测量并提升Cache性能
- 通过组相联、全相联。
- 通过多级cache。
⚠️减小CPI和提高时钟频率是不一样的,减小CPI是减小的指令执行的周期数,提高时钟频率是降低一个周期的时间。
直接映像:一个块对应cache中一个位置;
全相联:一个块对应cache(只有一行)中一行中的任意位置;
组相联:一个块对应cache中某一行中的任意位置。
C a c h e 大 小 = 组 数 × 相 连 性 Cache大小=组数\times 相连性 Cache大小=组数×相连性
多级Cache中初级专注于命中时间,二级专注于命中率
虚拟存储器
虚拟存储器和Cache类似,只不过Cache中存储的是数据,但是虚拟存储器中存储的是部分物理地址。
虚拟页可能在外存中,导致会发生缺页。
页表采用全相联。

页最开始存储在磁盘中,由OS决定所要的页存储在主存储器哪里。然后访问页时,页在内存中。
页表中页的替换使用的算法是最近最久未使用算法(LRU)。
页表还有对应的TLB(快表)。
TLB采用随机替换策略,全相联。
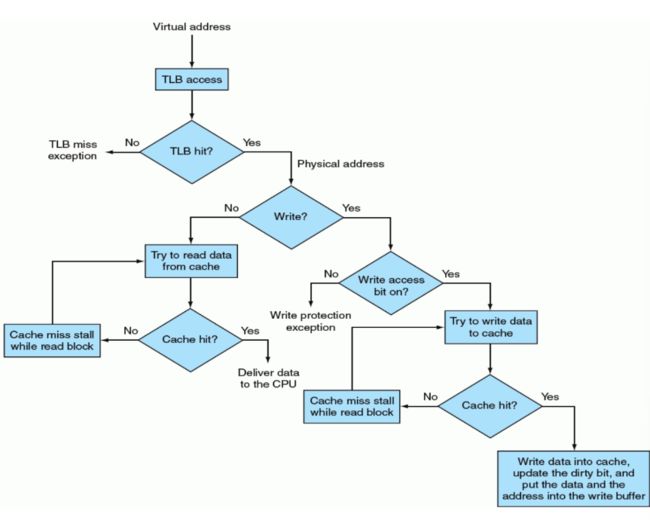
不可能出现TLB命中,页表中缺失的情况。

每个进程都有自己的虚拟空间。
降低缺失率的技术:
- 采用大的块以利用空间局部性;
- 采用页表,全相联;
- LRU和访问位来选择要替换的页。
储存结构框架
LRU可以采用硬件(移位寄存器)实现,或近似实现,甚至随机替换。
虚拟存储器只有回写是现实的,因为从内存想磁盘写数据用时太长。

3C模型:理解存储层次行为的直觉模型
- 强制缺失(Compulsory misses):第一次,从未进入cache;
- 缓解方法:增加块尺寸,利用局部性原理,但可能对性能有影响。
- 容量缺失(Capacity misses):Cache容量(并非组内)不够容纳运行中的所有模块;
- 缓解方法:增大Cache容量,但也增大访问时间。
- 冲突缺失(Conflict misses):多模块在一个组能竞争;
- 缓解方法:增加相连性,朝着全相联的方向走,但会降低性能。