C++类和类之间的关系(Boolan笔记第三周)
C**++的类与类之间的关系好像很复杂,其实只需了解三种就够了:
Composition 复合,表示has-a的关系
Inheritance 继承,表示Is-a的关系
Delegation 委托
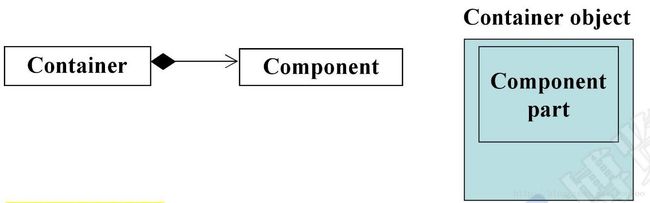
首先来看复合关系。如图所示,如果类Container包含了类Component,那就是复合关系,Container的object里面会包含Component这一部分。
复合关系代码举例如下:
template T>
class queue {
protected:
deque<T> c;
...
}
template T>
class deque {
protected:
Itr<T> start;
Itr<T> finish;
T** map;
unsigned int map_size;
};
template T>
struct Itr{
T* cur;
T* first;
T* last;
T** node;
...
}; 这里类queue包含了类deque, 类deque又包含了类Itr, 它们之间就是复合的关系。
我们来看看满足复合关系的两个类(比如说类Container包含类Component),它们之间的构造和析构顺序如何呢?谁先谁后? 我们可以知道在Container的object里面肯定包含了Component这个成分,也就是说Container在外,Component在内。
注意: 在C++里面有个准则,构造是永远由内而外,析构是永远由外向内。这和我们搭积木,拆积木的顺序是一样的。
那有了这个准则就好说了,满足复合关系的两个类的构造顺序如下:
构造由内向外:
Container的构造函数先调用Component的缺省构造函数,然后才执行自己。
Container::Container (…): Component() {…};
注意这里为什么说是缺省构造函数呢?因为这里没办法给Component赋一些非缺省的值让它初始化,也不能调用Component的拷贝构造函数和拷贝赋值函数,所以只能用缺省构造函数。
析构由外向内:
Container的析构函数先执行自己,然后才调用Component的析构函数。
Container::~Container(…) {…~Component() };
如果Container里面包含了两个或多个Component呢?构造和析构谁先谁后? 我在Code::Block 8.02上做了以下实验:
class B{
public:
B() {cout<<"B constructor"<cout<<"B destructor"<class C{
public:
C() {cout<<"C constructor"<cout<<"C destructor"<class A{
public:
A() {cout<<"A constructor"<cout<<"A destructor"< 运行结果是:
B constructor
C constructor
A constructor
A destructor
C destructor
B destructor
可见当Container包含多个Component时,构造顺序仍然是由内向外(先Component再Container),并且这些Component的构造顺序是按其在Container中的定义顺序。析构顺序也是由外向内(先Container再Component),并且这些Component的析构顺序是按其在Container中的定义逆序。所以我个人认为可以进一步将构造/析构顺序阐明为:
构造由内向外,同一个容器内则由上到下;
析构由外向内,同一个容器内则由下到上。
这里所说的容器可以是container,也可以是component。
我在另外一篇文章“ C++类实例内存结构分析”里面有个图解释C++类实例的内存分布,可以看到父类的内容是在子类的最上部。所以我个人认为:C++类的构造/析构顺序可以再进一步阐明为:
构造由上而下,
析构由下而上。
这样,不管是子类/父类,还是同一个类里面包含的多个component,都可以按这个原则来构造/析构。这样也更好理解,毕竟编译器不知道什么内外之别,只知道内存里面的先后顺序。
下面我们来看看委托(Delegation),委托其实就是带指针的复合关系。委托关系用图表示如下,其中菱形空心表示用的是指针。

委托关系的一个实例如下:
class StringRep;
class String {
public:
String();
String(const char* s);
String(const String& s);
String &operator=(const String& s);
~String();
...
private:
StringRep* rep; //
}
class StringRep{
friend class String;
StringRep(const char* s);
~StringRep();
int count;
char *rep;
} 以上的这种委托关系叫Handle/Body,也叫pImpl(pointer to Implementation)。它可以实现reference counting,如图所示:

String类的实例a,b,c的rep都指向同一个StringRep的实例,因此a,b,c的字符串都指向同一段内存空间。count这里记录一共 有多少个String的实例指向其所在的StringRep实例。a,b,c可以根据n的值来决定要不要对字符串进行修改,删除动作。
下面来重点谈谈继承关系(Inheritance)。
继承关系是表示Is-a的关系,如下图所示:

我们可以看出,继承关系下基类的部分是在里面,子类的部分是在外面,所以子类对象的object的size是肯定比基类对象的object的size要大些(至少相等)。
继承关系的代码例子如下:
struct _List_node_base
{
_List_node_base* _M_next;
_List_node_base* _M_prev;
};
template<typename _Tp>
struct _List_node : public _List_node_base
{
_Tp _M_data;
}这里_List_node_base是基类,_List_node是子类,继承了_List_node_base的数据成员和函数,并有自己的数据成员_M_data。
我们先简单看一下继承关系下的构造和析构顺序是怎么样的。跟复合关系一样,继承关系下的构造也是由内向外,所以Derived的构造函数先调用Base的构造函数,然后再执行自己 。
Derived::Derived(...): Base() {...};同样,继承关系下的析构也是由外向内,所以Derived的析构函数先调用自己的析构函数,然后再调用Base的析构函数。
Derived::~Derived(...) {... ~Base() };下面来看看继承关系下的重头戏 - 虚函数(virtual function)。C++类里面的函数可以分为三种:非虚函数(non-virtual),虚函数(virtual)和纯虚函数(pure virtual):
非虚函数: 你不希望子类重新定义(override)它
虚函数:你希望子类会重新定义(override)它,并且你对它已有默认定义。
纯虚函数:你希望子类一定会重新定义(override)它,并且你对它没有默认定义。
代码例子如下:
class Shape{
public:
virtual void draw() const = 0; // pure virtual
virtual void error(const std::string &msg); //impure virtual
int objectID() const; //non-virtual
...
};
class Rectangle: public Shape {...};
class Ellipse: public Shape {...};一个具体的虚函数的应用实例代码如下图所示:

看代码可知,CDocument为基类,其定义一个虚函数Serialize()为空函数(注意这不是纯虚函数)。CMyDoc为子类,它也定义了虚函数Serialize()并给出了Serialize()的具体实现。
C++编译器看到CDocument类有虚函数,就会给CDocument类生成一个虚函数表vtbl,并给出一个指针vptr指向vtbl。vtbl的每一项就指向一个虚函数(这里只有一项因为只有一个虚函数Serialize())。
对于CMyDoc,因为它的父类CDocument有虚函数,编译器也会给它生成一个虚函数表vtbl。这里需要注意的是:
1. 不管CMyDoc有没有override父类的虚函数,或者定义新的虚函数,它都会有一个vtbl。
2. 如果CMydoc没有定义其它虚函数,那它的vtbl的每一项都跟CDocument的vtbl的对应项指向同样的函数。但如果CMydoc类override了CDocument类的虚函数,那么CMydoc的vtbl里面的对应项就会指向override过的地址。
具体调用过程见下图:

当main()函数构造CMyDoc的对象myDoc时,它会call CDocument::OnFileOpen(),里面会call Serialize()。编译器一看这是个虚函数,就会根据vptr查找vtbl里面的对应项,
this->Serialize();
=> (*(this->vptr)[n])(this);注意这里的this指针是指向myDoc,所以会找到myDoc的vtbl里面的Serialize()函数,该函数里面会执行相应的初始化操作(因为只有应用程序本身才知道怎么读取自己的文件格式)。然后main()再调用myDoc.OnFileOpen(),该函数直接从CDocument而来,不用去查vtbl就可以执行了。
上面我们分别讨论了复合,委托和继承这三种关系。这三种关系互相组合,又形成多种错综复杂的模式。下面我们举几个例子讲解。
先看一下复合+继承这种情况。
例1是Base类有Component的情况,如下图所示。

根据C++的构造由内而外,析构由外而内的原则我们很容易看出:
Derived的构造函数先调用Component的缺省构造函数,再调用Base的缺省构造函数,然后才执行自己。
Derived的析构函数先执行自己,再调用Base的析构函数,再调用Component的析构函数。
例2是Derived类有Component的情况,如下图所示。

根据构造由内向外,由上到下的原则,Derived的构造函数先调用Base的缺省构造函数,然后再调用Component的缺省构造函数,然后再执行自己。
根据析构由外向内,由下到上的原则,Derived的析构函数先执行自己,然后再调用Component的析构函数,然后调用Base的析构函数。
我们再来看看委托+继承这种情况,其关系图表示如下:

一个具体的代码实例如下:

如图所示,Subject类的实例只有一个subj,其内部有一个指针vector m_views,其每项都指向一个Observer对象。Observer有2个子类,每个子类的构造函数都会把自己的object添加到m_views中,并初始化相应的参数。
Subject类有一个set_val()函数,其可设置m_value参数,并调用notify()通知所有的m_view指向的Observer对象进行update()操作。而update()函数在Observer类里是一个纯虚函数,Observer的各个子类对update()有各自的定义,这样,m_view里面各个Observer对象同时都得到了更新。