Python中的函数
Python函数知识点
- 1. 函数的作用
- 2.创建和调用函数
- 3. 函数的参数
- 4.函数的返回值
- 5. 位置参数
- 6. 关键字参数
- 7. 默认参数
- 8.只能使用位置参数
- 9. 只能使用关键字参数
- 10. 收集参数
- 11. 解包参数
- 12. 局部作用域
- 13. 全局作用域
- 14.global 语句
- 15. 嵌套函数
- 16. nonlocal 语句
- 17.LEGB规则
- 18. 嵌套作用域的特性
- 19. 闭包
- 20. 闭包举例
- 21.修饰器
- 22.lambda表达式
- 23.lambda的优势
- 24.lambda与 map() 和 filter() 函数搭配使用
- 25. lambda总结
- 26.生成器
- 27. 生成器表达器
- 28. 函数文档
- 29. 类型注释
- 30. 内省
- 31. 高阶函数
- 32.reduce() 函数
- 33.偏函数 (partial function)
- 34.@wraps 装饰器
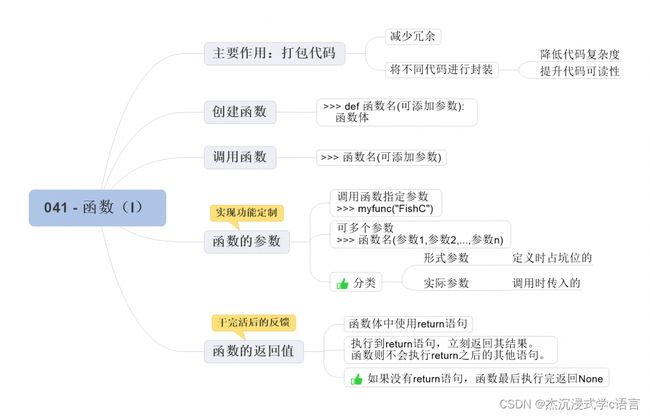
1. 函数的作用
Python 函数的主要作用就是打包代码。
有两个显著的好处:
- 可以最大程度地实现代码重用,减少冗余的代码
- 可以将不同功能的代码段进行封装、分解,从而降低结构的复杂度,提高代码的可读性
2.创建和调用函数
我们使用 def 语句来定义函数,紧跟着的是函数的名字,后面带一对小括号,冒号下面就是函数体,函数体是一个代码块,也就是每次调用函数时将被执行的内容:
>>> def myfunc():
... pass
...
>>>
注:pass 是一个空语句,表示不做任何事情,经常是被用来做一个占位符使用的。
调用这个函数,只需要在名字后面加上一对小括号:
>>> myfunc()
>>>
3. 函数的参数
从调用角度来看,参数可以细分为:形式参数(parameter)和实际参数(argument)。
其中,形式参数是函数定义的时候写的参数名字(比如下面例子中的 name 和 times);实际参数是在调用函数的时候传递进去的值(比如下面例子中的 “Python” 和 5)。
>>> def myfunc(name, times):
... for i in range(times):
... print(f"I love {name}.")
...
>>> myfunc("Python", 5)
I love Python.
I love Python.
I love Python.
I love Python.
I love Python.
4.函数的返回值
有时候,我们可能需要函数干完活之后能给一个反馈,这在 BIF 函数中也很常见,比如 sum() 函数会返回求和后的结果,len() 函数会返回一个元素的长度,而 list() 函数则会将参数转换为列表后返回……
只需要使用 return 语句,就可以让咱们自己定制的函数实现返回:
>>> def div(x, y):
... z = x / y
... return z
...
>>> div(4, 2)
2.0
最后,如果一个函数没有通过 return 语句返回,它也会自己在执行完函数体中的语句之后,悄悄地返回一个 None 值:
>>> def myfunc():
... pass
...
>>> print(myfunc())
None
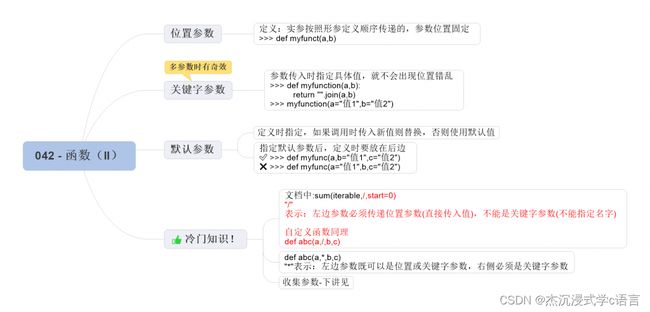
5. 位置参数
在通常的情况下,实参是按照形参定义的顺序进行传递的:
>>> def myfunc(s, vt, o):
... return "".join((o, vt, s))
...
>>> myfunc("我", "打了", "小甲鱼")
'小甲鱼打了我'
>>> myfunc("小甲鱼", "打了", "我")
'我打了小甲鱼'
由于在定义函数的时候,就已经把参数的名字和位置确定了下来,我们将 Python 中这类位置固定的参数称之为位置参数。
6. 关键字参数
使用关键字参数,我们只需要知道形参的名字就可以:
>>> myfunc(o="我", vt="打了", s="小甲鱼")
'我打了小甲鱼'
尽管使用关键字参数需要你多敲一些字符,但对于参数特别多的函数,这一招尤其管用。
如果同时使用位置参数和关键字参数,那么使用顺序是需要注意一下的:
>>> myfunc(o="我", "清蒸", "小甲鱼")
SyntaxError: positional argument follows keyword argument
比如这样就不行了,因为位置参数必须是在关键字参数之前,之间也不行哈。
7. 默认参数
Python 还允许函数的参数在定义的时候指定默认值,这样以来,在函数调用的时候,如果没有传入实参,那么将采用默认的参数值代替:
>>> def myfunc(s, vt, o="小甲鱼"):
... return "".join((o, vt, s))
...
>>> myfunc("香蕉", "吃")
'小甲鱼吃香蕉'
默认参数的意义就是当用户没有输入该参数的时候,有一个默认值可以使用,不至于造成错误。
如果用户指定了该参数值,那么默认的值就会被覆盖:
>>> myfunc("香蕉", "吃", "不二如是")
'不二如是吃香蕉'
这里也有一点是需要注意的,就是如果要使用默认参数,那么应该把它们摆在最后:
>>> def myfunc(s="苹果", vt, o="小甲鱼"):
SyntaxError: non-default argument follows default argument
>>> def myfunc(vt, s="苹果", o="小甲鱼"):
... return "".join((o, vt, s))
...
>>> myfunc("拱了")
'小甲鱼拱了苹果'
8.只能使用位置参数
咱们在使用 help() 函数查看函数文档的时候呢,经常会在函数原型的参数中发现一个斜杠(/),比如:
>>> help(abs)
Help on built-in function abs in module builtins:
abs(x, /)
Return the absolute value of the argument.
>>> help(sum)
Help on built-in function sum in module builtins:
sum(iterable, /, start=0)
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
When the iterable is empty, return the start value.
This function is intended specifically for use with numeric values and may
reject non-numeric types.
这表示斜杠左侧的参数必须传递位置参数,不能是关键字参数,举个例子:
>>> abs(-1.5)
1.5
>>> abs(x = -1.5)
Traceback (most recent call last):
File "" , line 1, in <module>
abs(x = -1.5)
TypeError: abs() takes no keyword arguments
那斜杠右侧的话呢,就随你了:
>>> sum([1, 2, 3], start=6)
12
>>> sum([1, 2, 3], 6)
12
9. 只能使用关键字参数
既然有限制 “只能使用位置参数”,那有没有那种限制 “只能使用关键字参数” 的语法呢?
那就是利用星号(*):
>>> def abc(a, *, b, c):
... print(a, b, c)
这样,参数 a 既可以是位置参数也可以是关键字参数,但参数 b 和参数 c 就必须是关键字参数,才不会报错:
>>> abc(1, 2, 3)
Traceback (most recent call last):
File "" , line 1, in <module>
abc(1, 2, 3)
TypeError: abc() takes 1 positional argument but 3 were given
>>> abc(1, b=2, c=3)
1 2 3
>>> abc(a=3, b=2, c=1)
3 2 1
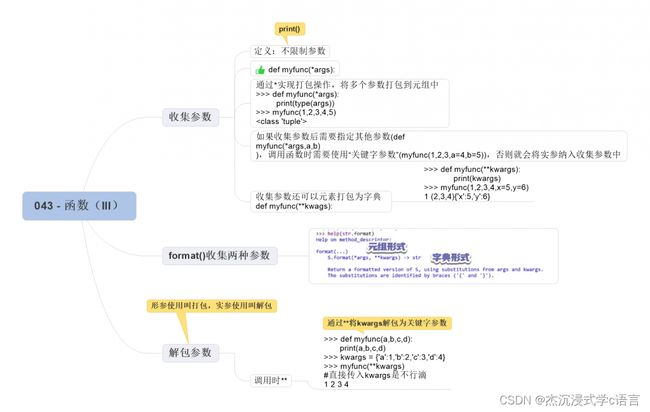
10. 收集参数
什么叫收集参数呢?
当我们在定义一个函数的时候,假如需要传入的参数的个数是不确定的,按照一般的写法可能需要定义很多个相同的函数然后指定不同的参数个数,这显然是很麻烦的,不能根本解决问题。
为解决这个问题,Python 就推出了收集参数的概念。所谓的收集参数,就是说只指定一个参数,然后允许调用函数时传入任意数量的参数。
定义收集参数其实也很简单,即使在形参的前面加上星号(*)来表示:
>>> def myfunc(*args):
... print("有%d个参数。" % len(args))
... print("第2个参数是:%s" % args[1])
...
>>> myfunc("小甲鱼", "不二如是")
有2个参数。
第2个参数是:不二如是
>>> myfunc(1, 2, 3, 4, 5)
有5个参数。
第二个参数是:2
如果在收集参数后面还需要指定其它参数,那么在调用函数的时候就应该使用关键参数来指定后面的参数:
>>> def myfunc(*args, a, b):
... print(args, a, b)
...
>>> myfunc(1, 2, 3, a=4, b=5)
(1, 2, 3) 4 5
除了可以将多个参数打包为元组,收集参数其实还可以将参数们打包为字典,做法呢,是使用连续的两个星号(**):
>>> def myfunc(**kwargs):
... print(kwargs)
...
对于这种情况,在传递参数的时候就必须要使用关键字参数了,因为字典的元素都是键值对嘛,所以等号(=)左侧是键,右侧是值:
>>> myfunc(a=1, b=2, c=3)
{'a': 1, 'b': 2, 'c': 3}
混合起来使用就更加灵活了:
>>> def myfunc(a, *b, **c):
... print(a, b, c)
...
>>> myfunc(1, 2, 3, 4, x=5, y=6)
1 (2, 3, 4) {'x': 5, 'y': 6}
11. 解包参数
这一个星号(*)和两个星号(**)不仅可以用在函数定义的时候,在函数调用的时候也有特殊效果,在形参上使用称之为参数的打包,在实参上的使用,则起到了相反的效果,即解包参数:
>>> args = (1, 2, 3, 4)
>>> def myfunc(a, b, c, d):
... print(a, b, c, d)
...
>>> myfunc(*args)
1 2 3 4
那么两个星号(**)对应的是关键字参数:
>>> args = {'a':1, 'b':2, 'c':3, 'd':4}
>>> myfunc(**args)
1 2 3 4
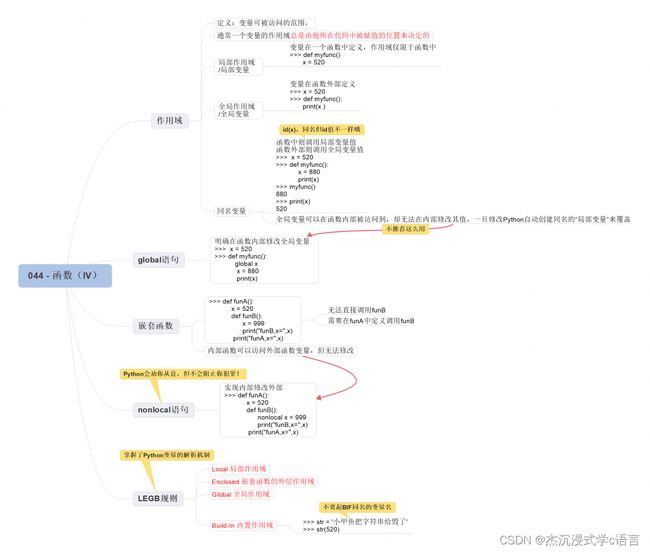
12. 局部作用域
如果一个变量定义的位置是在一个函数里面,那么它的作用域就仅限于函数中,我们将它称为局部变量。
>>> def myfunc():
... x = 520
... print(x)
...
>>> myfunc()
520
变量 x 是在函数 myfunc() 中定义的,所以它的作用域仅限于该函数,如果我们尝试在函数的外部访问这个变量,那么就会报错:
>>> print(x)
Traceback (most recent call last):
File "" , line 1, in <module>
print(x)
NameError: name 'x' is not defined
13. 全局作用域
如果是在任何函数的外部去定义一个变量,那么它的作用域就是全局的,我们也将其称为全局变量:
>>> x = 880
>>> def myfunc():
... print(x)
...
>>> myfunc()
880
如果在函数中存在一个跟全局变量同名的局部变量,会发生什么样的事情呢?
在函数中,局部变量就会覆盖同名的全局变量的值:
>>> x = 880
>>> def myfunc():
... x = 520
... print(x)
...
>>> myfunc()
520
>>> print(x)
880
注意:代码中两个 x 并非同一个变量,只是由于作用域不同,它们同名但并不同样。
14.global 语句
通常我们无法在函数内部修改全局变量的值,除非使用 global 语句破除限制:
>>> x = 880
>>> def myfunc():
... global x
... x = 520
... print(x)
...
>>> myfunc()
520
>>> print(x)
520
15. 嵌套函数
函数也是可以嵌套的:
>>> def funA():
... x = 520
... def funB():
... x = 880
... print("In funB, x =", x)
... print("In funA, x =", x)
在外部函数 funA() 里面嵌套了一个内部函数 funB(),那么这个内部函数是无法被直接调用的:
>>> funB()
Traceback (most recent call last):
File "" , line 1, in <module>
funB()
NameError: name 'funB' is not defined
想要调用 funB(),必须得通过 funA():
>>> def funA():
... x = 520
... def funB():
... x = 880
... print("In funB, x =", x)
... funB()
... print("In funA, x =", x)
...
>>> funA()
In funB, x = 880
In funA, x = 520
16. nonlocal 语句
通常我们无法在嵌套函数的内部修改外部函数变量的值,除非使用 nonlocal 语句破除限制:
>>> def funA():
... x = 520
... def funB():
... nonlocal x
... x = 880
... print("In funB, x =", x)
... funB()
... print("In funA, x =", x)
...
>>> funA()
In funB, x = 880
In funA, x = 880
17.LEGB规则
只要记住 LEGB,那么就相当于掌握了 Python 变量的解析机制。
其中:
- L 是 Local,是局部作用域
- E 是 Enclosed,是嵌套函数的外层函数作用域
- G 是 Global,是全局作用域
- B 是 Build-In,也就是内置作用域
最后一个是 B,也就是 Build-In,最没地位的那一个。
比如说 Build-In Function —— BIF,你只要起一个变量名跟它一样,那么就足以把这个内置函数给 “毁了”:
>>> str = "小甲鱼把str给毁了"
>>> str(520)
Traceback (most recent call last):
File "" , line 1, in <module>
str(520)
TypeError: 'str' object is not callable
是不是,它本来的功能是将参数转换成字符串类型,但由于我们将它作为变量名赋值了,那么 Python 就把它给覆盖了:
>>> str
'小甲鱼把str给毁了'
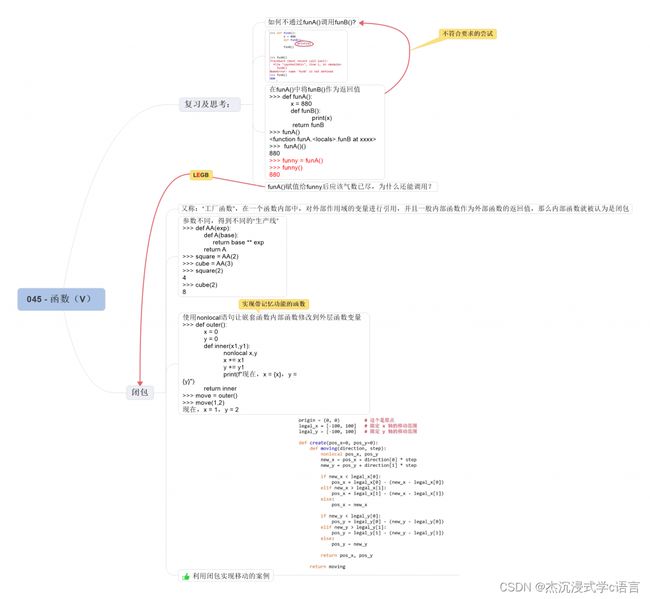
18. 嵌套作用域的特性
对于嵌套函数来说,外层函数的作用域是会通过某种形式保存下来的,它并不会跟局部作用域那样,调用完就消失。
>>> def funA():
... x = 520
... def funB():
... print(x)
... return funB
>>> funA()
<function funA.<locals>.funB at 0x0000014C02684040>
>>> funA()()
520
>>> funny = funA()
>>> funny
<function funA.<locals>.funB at 0x0000014C02684550>
>>> funny()
520
19. 闭包
所谓闭包(closure),也有人称之为工厂函数(factory function)。
举个例子:
>>> def power(exp):
... def exp_of(base):
... return base ** exp
... return exp_of
...
>>> square = power(2)
>>> cube = power(3)
>>> square
<function power.<locals>.exp_of at 0x000001CF6A1FAF70>
>>> square(2)
4
>>> square(5)
25
>>> cube(2)
8
>>> cube(5)
125
这里 power() 函数就像是一个工厂,由于参数不同,得到了两个不同的 “生产线”,一个是 square(),一个是 cube(),前者是返回参数的平方,后者是返回参数的立方。
20. 闭包举例
比如说在游戏开发中,我们需要将游戏中角色的移动位置保护起来,不希望被其他函数轻易就能够修改,所以我们就可以利用闭包:
origin = (0, 0) # 这个是原点
legal_x = [-100, 100] # 限定x轴的移动范围
legal_y = [-100, 100] # 限定y轴的移动范围
# 好,接着我们定义一个create()函数
# 初始化位置是原点
def create(pos_x=0, pos_y=0):
# 然后我们定义一个实现角色移动的函数moving()
def moving(direction, step):
# direction参数设置方向,1为向右或向上,-1为向左或向下,如果是0则不移动
# step参数是设置移动的距离
# 为了修改外层作用域的变量
nonlocal pos_x, pos_y
# 然后我们真的就去修改它们
new_x = pos_x + direction[0] * step
new_y = pos_y + direction[1] * step
# 检查移动后是否超出x轴的边界
if new_x < legal_x[0]:
# 制造一个撞墙反弹的效果
pos_x = legal_x[0] - (new_x - legal_x[0])
elif new_x > legal_x[1]:
pos_x = legal_x[1] - (new_x - legal_x[1])
else:
pos_x = new_x
# 检查移动后是否超出y轴边界
if new_y < legal_y[0]:
pos_y = legal_y[0] - (new_y - legal_y[0])
elif new_y > legal_y[1]:
pos_y = legal_y[1] - (new_y - legal_y[1])
else:
pos_y = new_y
# 将最终修改后的位置作为结果返回
return pos_x, pos_y
# 外层函数返回内层函数的引用
return moving
程序实现如下:
>>> move = create()
>>> print("向右移动20步后,位置是:", move([1, 0], 20))
向右移动20步后,位置是: (20, 0)
>>> print("向上移动120步后,位置是:", move([0, 1], 120))
向上移动120步后,位置是: (20, 80)
>>> print("向左移动66步后,位置是:", move([-1, 0], 66))
向左移动66步后,位置是: (-46, 80)
>>> print("向右下角移动88步后,位置是:", move([1, -1]), 88)
Traceback (most recent call last):
File "" , line 1, in <module>
print("向右下角移动88步后,位置是:", move([1, -1]), 88)
TypeError: moving() missing 1 required positional argument: 'step'
>>> print("向右下角移动88步后,位置是:", move([1, -1], 88))
向右下角移动88步后,位置是: (42, -8)
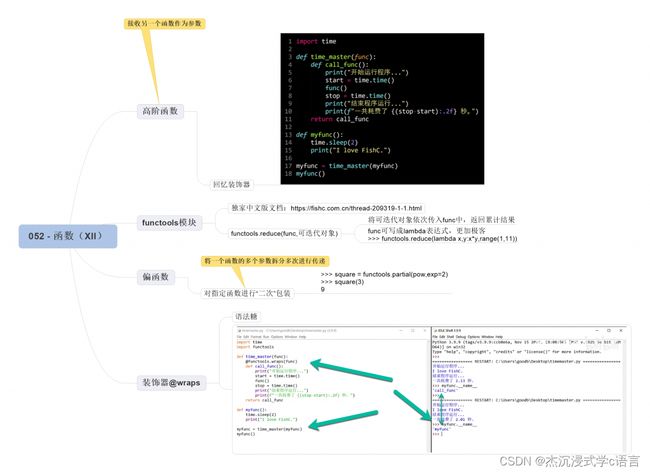
21.修饰器
装饰器本质上也是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能。
import time
def time_master(func):
def call_func():
print("开始运行程序...")
start = time.time()
func()
stop = time.time()
print("结束程序运行...")
print(f"一共耗费了 {(stop-start):.2f} 秒。")
return call_func
@time_master
def myfunc():
time.sleep(2)
print("I love FishC.")
myfunc()
程序实现如下:
开始运行程序...
I love FishC.
结束程序运行...
一共耗费了 2.01 秒
使用了装饰器,我们并不需要修改原来的代码,只需要在函数的上方加上一个 @time_master,然后函数就能够实现统计运行时间的功能了。
这个 @ 加上装饰器名字其实是个语法糖,装饰器原本的样子应该这么调用的:
我们在 f-string 里面谈到过语法糖,我们说语法糖是某种特殊的语法,对语言的功能没有影响,但对程序员来说,有更好的易用性,简洁性、可读性和方便性。
import time
def time_master(func):
def call_func():
print("开始运行程序...")
start = time.time()
func()
stop = time.time()
print("结束程序运行...")
print(f"一共耗费了 {(stop-start):.2f} 秒。")
return call_func
def myfunc():
time.sleep(2)
print("I love FishC.")
myfunc = time_master(myfunc)
myfunc()
这个就是装饰器的实现原理啦~
多个装饰器也可以用在同一个函数上:
def add(func):
def inner():
x = func()
return x + 1
return inner
def cube(func):
def inner():
x = func()
return x * x * x
return inner
def square(func):
def inner():
x = func()
return x * x
return inner
@add
@cube
@square
def test():
return 2
print(test())
程序实现如下:
65
这样的话,就是先计算平方(square 装饰器),再计算立方(cube 装饰器),最后再加 1(add 装饰器)。
如何给装饰器传递参数呢?
答案是添加多一层嵌套函数来传递参数:
import time
def logger(msg):
def time_master(func):
def call_func():
start = time.time()
func()
stop = time.time()
print(f"[{msg}]一共耗费了 {(stop-start):.2f}")
return call_func
return time_master
@logger(msg="A")
def funA():
time.sleep(1)
print("正在调用funA...")
@logger(msg="B")
def funB():
time.sleep(1)
print("正在调用funB...")
funA()
funB()
程序实现如下:
正在调用funA...
[A]一共耗费了 1.01
正在调用funB...
[B]一共耗费了 1.04
我们将语法糖去掉,拆解成原来的样子,你就知道原理了:
import time
def logger(msg):
def time_master(func):
def call_func():
start = time.time()
func()
stop = time.time()
print(f"[{msg}]一共耗费了 {(stop-start):.2f}")
return call_func
return time_master
def funA():
time.sleep(1)
print("正在调用funA...")
def funB():
time.sleep(1)
print("正在调用funB...")
funA = logger(msg="A")(funA)
funB = logger(msg="B")(funB)
funA()
funB()
程序实现如下:
正在调用funA...
[A]一共耗费了 1.02
正在调用funB...
[B]一共耗费了 1.01
这里其实就是给它裹多一层嵌套函数上去,然后通过最外层的这个函数来传递装饰器的参数。
这样,logger(msg=“A”) 得到的是 timemaster() 函数的引用,然后再调用一次,并传入 funA,也就是这个 logger(msg=“A”)(funA),得到的就是 call_func() 函数的引用,最后将它赋值回 funA()。
咱们对比一下没有参数的描述器,这里其实就是添加了一次调用,然后通过这次调用将参数给传递进去而已。

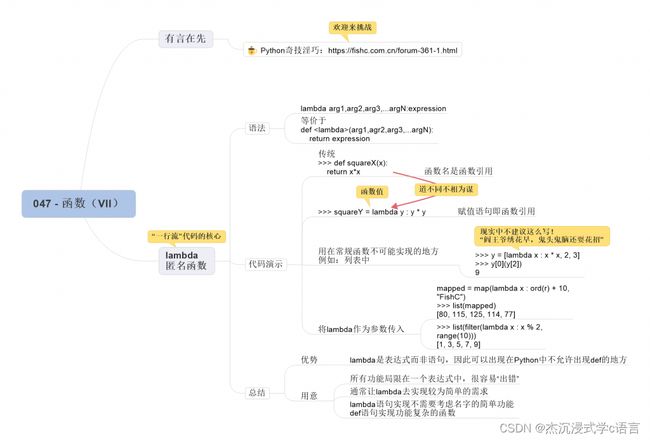
22.lambda表达式
lambda 表达式,也就是大牛们津津乐道的匿名函数。
只要掌握了 lambda 表达式,你也就掌握了一行流代码的核心 —— 仅使用一行代码,就能解决一件看起来相当复杂的事情。
它的语法是这样的:
lambda arg1, arg2, arg3, … argN : expression
ambda 是个关键字,然后是冒号,冒号左边是传入函数的参数,冒号后边是函数实现表达式以及返回值。
我们可以将 lambda 表达式的语法理解为一个极致精简之后的函数,如果使用传统的函数定义方式,应该是这样:
def <lambda>(arg1, arg2, arg3, ... argN):
... return expression
如果要求我们编写一个函数,让它求出传入参数的平方值,以前我们这么写:
>>> def squareX(x):
... return x * x
...
>>> squareX(3)
9
现在我们这么写:
>>> squareY = lambda y : y * y
>>> squareY(3)
9
传统定义的函数,函数名就是一个函数的引用:
>>> squareX
<function squareX at 0x0000015E06668F70>
而 lambda 表达式,整个表达式就是一个函数的引用:
>>> squareY
<function <lambda> at 0x0000015E06749EE0>
23.lambda的优势
lambda 是一个表达式,因此它可以用在常规函数不可能存在的地方:
>>> y = [lambda x : x * x, 2, 3]
>>> y[0](y[1])
4
>>> y[0](y[2])
9
注意:这里说的是将整个函数的定义过程都放到列表中哦~
24.lambda与 map() 和 filter() 函数搭配使用
利用 lambda 表达式与 map() 和 filter() 函数搭配使用,会使代码显得更加 Pythonic:
>>> list(mapped = map(lambda x : ord(x) + 10, "FishC"))
[80, 115, 125, 114, 77]
>>> list(filter(lambda x : x % 2, range(10)))
[1, 3, 5, 7, 9]
25. lambda总结
lambda 是一个表达式,而非语句,所以它能够出现在 Python 语法不允许 def 语句出现的地方,这是它的最大优势。
但由于所有的功能代码都局限在一个表达式中实现,因此,lambda 通常只能实现那些较为简单的需求。
当然,Python 肯定是有意这么设计的,让 lambda 去做那些简单的事情,我们就不用花心思去考虑这个函数叫什么,那个函数叫什么……
def 语句则负责用于定义功能复杂的函数,去处理那些复杂的工作。
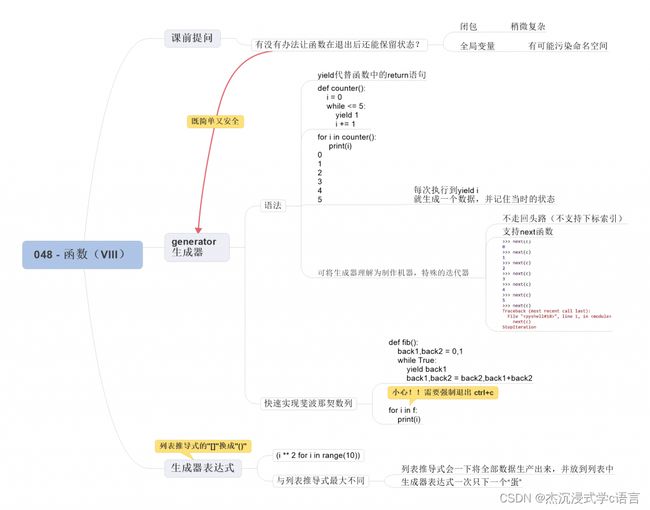
26.生成器
在 Python 中,使用了 yield 语句的函数被称为生成器(generator)。
与普通函数不同的是,生成器是一个返回生成器对象的函数,它只能用于进行迭代操作,更简单的理解是 —— 生成器就是一个特殊的迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 yield 方法时从当前位置继续运行。
定义一个生成器,很简单,就是在函数中,使用 yield 表达式代替 return 语句即可。
举个例子:
>>> def counter():
... i = 0
... while i <= 5:
... yield i
... i += 1
现在我们调用 counter() 函数,得到的不是一个返回值,而是一个生成器对象:
>>> counter()
<generator object counter at 0x0000025835D0D5F0>
我们可以把它放到一个 for 语句中:
>>> for i in counter():
... print(i)
...
0
1
2
3
4
5
注意:生成器不像列表、元组这些可迭代对象,你可以把生成器看作是一个制作机器,它的作用就是每调用一次提供一个数据,并且会记住当时的状态。而列表、元组这些可迭代对象是容器,它们里面存放着早已准备好的数据。
生成器可以看作是一种特殊的迭代器,因为它首先是 “不走回头路”,第二是支持 next() 函数:
>>> c = counter()
>>> next(c)
0
>>> next(c)
1
>>> next(c)
2
>>> next(c)
3
>>> next(c)
4
>>> next(c)
5
next(c)
Traceback (most recent call last):
File "" , line 1, in <module>
next(c)
StopIteration
当没有任何元素产出的时候,它就会抛出一个 “StopIteration” 异常。
由于生成器每调用一次获取一个结果这样的特性,导致生成器对象是无法使用下标索引这样的随机访问方式:
>>> c = counter()
>>> c[2]
Traceback (most recent call last):
File "" , line 1, in <module>
c[2]
TypeError: 'generator' object is not subscriptable
27. 生成器表达器
因为列表有推导式,元组则没有,如果非要这么写:
>>> (i ** 2 for i in range(10))
<generator object <genexpr> at 0x0000019A976CC5F0>
那么我们可以看到,它其实就是得到一个生成器嘛:
>>> t = (i ** 2 for i in range(10))
>>> next(t)
0
>>> next(t)
1
>>> next(t)
4
>>> next(t)
9
>>> next(t)
16
>>> for i in t:
... print(i)
...
25
36
49
64
81
这种利用推导的形式获取生成器的方法,我们称之为生成器表达式。
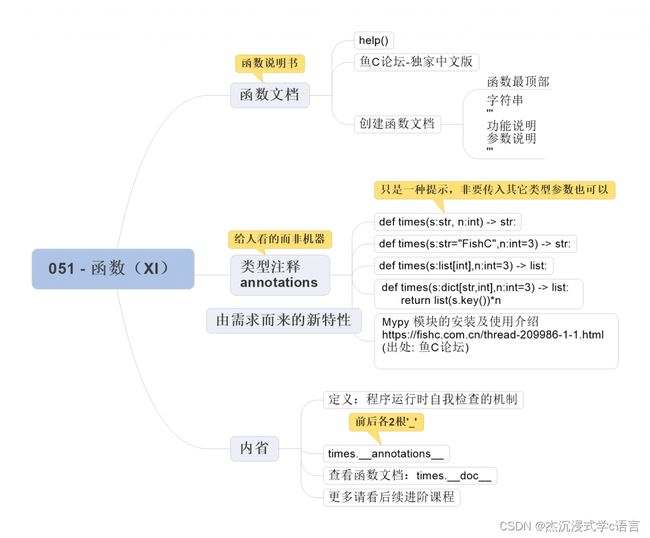
28. 函数文档
使用 help() 函数,我们可以快速查看到一个函数的使用文档:
>>> help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
创建函数文档非常简单,使用字符串就可以了,举个例子:
>>> def exchange(dollar, rate=6.32):
"""
功能:汇率转换,美元 -> 人民币
参数:
- dollar 美元数量
- rate 汇率,默认值 6.32(2022-03-08)
返回值:
- 人民币数量
"""
return dollar * rate
...
>>> exchange(20)
126.4
注意:函数文档一定是在函数的最顶部。
我们可以看到,函数开头的几行字符串并不会被打印出来,但它将作为函数的文档被保存起来。
现在通过 help() 函数,就可以查看到 exchange() 的文档了:
>>> help(exchange)
Help on function exchange in module __main__:
exchange(dollar, rate=6.32)
功能:汇率转换,美元 -> 人民币
参数:
- dollar 美元数量
- rate 汇率,默认值 6.32(2022-03-08)
返回值:
- 人民币数量
29. 类型注释
有时候,你可能会看到这样的代码:
>>> def times(s:str, n:int) -> str:
... return s * n
其实这里面多出来的东东,就是 Python 的类型注释啦~
比如上面代码表示该函数的作者,希望调用者传入到 s 参数的是字符串类型,传入到 n 参数的是整数类型,最后还告诉我们函数将会返回一个字符串类型的返回值:
>>> times("FishC", 5)
'FishCFishCFishCFishCFishC'
当然,这只不过是函数作者的寄望,如果调用者非要胡来,Python 也是不会出面阻止的:
>>> times(5, 5)
25
因为这只是类型注释,是给人看的,不是给机器看的哈。
如果需要使用默认参数,那么类型注释可以这么写:
>>> def times(s:list, n:int = 5) -> list:
... return s * n
...
>>> times([1, 2, 3], 3)
[1, 2, 3, 1, 2, 3, 1, 2, 3]
如果还想更进一步,比如期望参数类型是一个整数列表(也就是列表中所有的元素都是整数),那么代码可以这么写:
>>> def times(s:list[int], n:int = 5) -> list:
... return s * n
映射类型也可以使用这种方法,比如我们期望字典的键是字符串,值是整数,可以这么写:
>>> def times(s:dict[str, int], n:int = 5) -> list:
... return list(s.keys()) * n
...
>>> times({'A':1, 'B':2, 'C':3}, 3)
['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C']
30. 内省
内省,其实最先是心理学的基本研究方法之一,又称为自我观察法。它是发生在内部的,我们自己能够意识到的主观现象。
Python 通过一些特殊的属性来实现内省,比如我们想知道一个函数的名字,可以使用 name:
>>> times.__name__
'times'
使用 _annotations 查看函数的类型注释:
>>> times.__annotations__
{'s': dict[str, int], 'n': <class 'int'>, 'return': list[str]}
查看函数文档,可以使用 doc:
>>> exchange.__doc__
'\n\t功能:汇率转换,美元 -> 人民币\n\t参数:\n\t- dollar 美元数量\n\t- rate 汇率,默认值 6.32(2022-03-07)\n\t返回值:\n\t- 人民币数量\n\t'
阅读不友好,咱们使用 print() 函数给打印一下:
>>> print(exchange.__doc__)
功能:汇率转换,美元 -> 人民币
参数:
- dollar 美元数量
- rate 汇率,默认值 6.32(2022-03-07)
返回值:
- 人民币数量
>>>
31. 高阶函数
很多同学一听高阶,那一定是很厉害很强大的意思,其实这样描述并不全面。
在前面的学习中,我们发现,函数是可以被当作变量一样自由使用的,那么当一个函数接收另一个函数作为参数的时候,这种函数就称之为高阶函数。
高阶函数几乎就是函数式编程的灵魂所在,所以 Python 专程为此搞了一个模块 —— functools,这里面包含了非常多实用的高阶函数,以及装饰器。
32.reduce() 函数
>>> def add(x, y):
... return x + y
...
>>> functools.reduce(add, [1, 2, 3, 4, 5])
15
它的第一个参数是指定一个函数,这个函数必须接收两个参数,然后第二个参数是一个可迭代对象,reduce() 函数的作用就是将可迭代对象中的元素依次传递到第一个参数指定的函数中,最终返回累积的结果。
其实就相当于这样子:
>>> add(add(add(add(1, 2), 3), 4), 5)
15
另外,将 reduce() 函数的第一个参数写成 lambda 表达式,代码就更加极客了,比如我们要计算 10 的阶乘,那么可以这么写:
>>> functools.reduce(lambda x,y:x*y, range(1, 11))
3628800
33.偏函数 (partial function)
偏函数是对指定函数的二次包装,通常是将现有函数的部分参数预先绑定,从而得到一个新的函数,该函数就称为偏函数。
>>> square = functools.partial(pow, exp=2)
>>> square(2)
4
>>> square(3)
9
>>> cube = functools.partial(pow, exp=3)
>>> cube(2)
8
>>> cube(3)
27
偏函数的实现原理大致等价于:
def partial(func, /, *args, **keywords):
def newfunc(*fargs, **fkeywords):
newkeywords = {**keywords, **fkeywords}
return func(*args, *fargs, **newkeywords)
newfunc.func = func
newfunc.args = args
newfunc.keywords = keywords
return newfunc
其实不难发现,它的实现原理就是闭包!
只不过使用偏函数的话更简单了一些,细节实现不用我们去费脑子了,直接拿来就用。
34.@wraps 装饰器
让我们先回到讲解装饰器时候的例子:
import time
def time_master(func):
def call_func():
print("开始运行程序...")
start = time.time()
func()
stop = time.time()
print("结束程序运行...")
print(f"一共耗费了 {(stop-start):.2f} 秒。")
return call_func
@time_master
def myfunc():
time.sleep(2)
print("I love FishC.")
myfunc()
程序实现如下:
开始运行程序...
I love FishC.
结束程序运行...
一共耗费了 2.01 秒
这里的代码呢,其实是有一个 “副作用” 的:
>>> myfunc.__name__
'call_func'
竟然,myfunc 的名字它不叫 ‘my_func’,而是叫 ‘call_func’……
这个其实就是装饰器的一个副作用,虽然通常情况下用起来影响不大,但大佬的眼睛里哪能容得下沙子,对吧?
所以发明了这个 @wraps 装饰器来装饰装饰器:
import time
import functools
def time_master(func):
@functools.wraps(func)
def call_func():
print("开始运行程序...")
start = time.time()
func()
stop = time.time()
print("结束程序运行...")
print(f"一共耗费了 {(stop-start):.2f} 秒。")
return call_func
@time_master
def myfunc():
time.sleep(2)
print("I love FishC.")
myfunc()
程序实现如下:
开始运行程序...
I love FishC.
结束程序运行...
一共耗费了 2.01 秒
>>> myfunc.__name__
'myfunc'