KAFKA 海量吞吐低延迟技术解密:KafkaProducer
1、导读
笔者在生产交付的项目中使用了 KAFKA,为了更好地掌握 KAFKA,业余时间阅读了部分源码。KAFKA 生产者的代码中有很多的精妙绝伦的设计,非常值得借鉴学习。本文将探讨 KafkaProducer 的消息发送流程、高并发场景下消息的缓冲机制、缓冲机制是如何通过分段加锁和读写分离巧妙提升吞吐和并发的、为减少频繁 FGC 设计的内存池、消息重复发送和消息丢失的场景。笔者水平有限,若有不当之处,请不吝指正。
2、消息发送的流程
KAFKA 生产者客户端分别由主线程和 Sender 线程协调运行,主线程负责由 KafkaProducer 创建消息,经过拦截器、序列化和分区选择后缓存追加至 RecordAccumulator(消息累加器)中,Sender 线程负责从 RecordAccumulator 中批量取出消息并发送至 KAFKA 服务端。
RecordAccumulator(消息累加器)负责缓存生产者客户端产生的消息,按消息的目标分区进行攒批,攒批的大小可以通过生产者客户端参数batch.size配置(默认为 16KB),整个缓存的大小可以通过生产者客户端参数buffer.memory配置(默认为 32 MB)。RecordAccumulator(消息累加器)在内部设计上为每个分区都维护了一个 Deque(双端队列),队列中存放了每个分区的 ProducerBatch(消息攒批),消息是追加到 ProducerBatch 的尾部,因此消息是分区有序的;
消息发送的流程见下图:

※ 消息发送的各关键阶段:
① 用户使用生产者客户端发送消息;
② KafkaProducer 主线程唤醒 Sender 线程(Sender 线程在客户端初始化过程中启动并阻塞),Sender 线程向 KAFKA 服务端请求获取集群元数据并维护在客户端内存 Metadata 对象中;
③ 消息经过拦截器、序列化和分区后,追加至 RecordAccumulator(消息累加器) 中;
④ Sender 线程轮询 RecordAccumulator,待缓冲区数据批次就绪后,取出消息块;
⑤ Sender 线程构造消息发送的请求,并封装为 ClientRequest 后提交给 NetworkClient,准备发送;
⑥ NetworkClient 将请求放入 KafkaChannel 缓存中,执行网络 IO,发送至 KAFKA 服务端;
⑦ NIO Selector 收到请求响应,进行 TCP 拆包后解析成 NetworkReceive 对象放入 Deque 队列中,由 NetworkClient 经过一连串的请求响应处理器后,封装成 ClientResponse;
2.1、消息拦截器
消息拦截器可以在消息发送前对其进行拦截或修改,也可对ACK响应进行预处理,通常可用于监控埋点、消息审计等用途。用户如果自定义消息拦截器,需要实现接口org.apache.kafka.clients.producer.ProducerInterceptor,生产者会按照一个或多个自定义的拦截器的顺序,有序地作用于同一条消息从而形成一条拦截链。
public interface ProducerInterceptor extends Configurable {
// 消息在发送前拦截,此拦截器返回的结果将传递至下一个消息拦截器
public ProducerRecord onSend(ProducerRecord record);
// 消息在发送至KAFKA服务端结束后(成功或失败),在调用用户的Callback前进行拦截
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
// 消息拦截器的关闭
public void close();
} 2.2、消息序列化
客户端和服务端的网络通信是基于 Java NIO 实现的,传输的数据类型是 Byte 数组。KAFKA 生产者在初始化时通过反射方式分别指定了 Key、Value 序列化器,KAFKA 客户端提供了针对各种数据类型的序列化器,包路径位于:org.apache.kafka.common.serialization.*,用户也可通过实现接口org.apache.kafka.common.serialization.Serializer和org.apache.kafka.common.serialization.Deserializer来自定义序列化器和反序列化器。
2.3、元数据加载
用户在使用客户端发送消息时,仅指定了 Topic、部分 Broker IP,而生产者最终是要将消息发送到指定 Topic 下某个分区的 Leader 副本所在的服务节点上的,因此需要知道 KAFKA 集群的元数据信息,包括 Topic 有多少分区、各分区的 Leader 副本分配在哪个服务节点上、Follower 副本分配在哪些服务节点上、哪些副本在ISR集合中、服务节点的地址和端口等信息,这些元数据会在某个合适的时机加载到客户端的 Metadata 对象中,主要成员如下:
public final class Metadata {
// 两次元数据过期刷新之间的时间间隔
private final long refreshBackoffMs;
// 元数据的保留时长
private final long metadataExpireMs;
// 客户端内存中 KAFKA 集群元数据的版本号,每次过期刷新都自增
private int version;
// 上次刷新的时间戳(包括刷新失败的场景)
private long lastRefreshMs;
// 上次成功刷新的时间戳
private long lastSuccessfulRefreshMs;
// KAFKA 集群的元数据
// 1、Broker 节点的ID、Host、IP地址、端口
// 2、KafkaController 的节点信息
// 3、Topic 下各个分区的ID、Leader副本所在的服务节点信息、所有副本所在的节点信息、ISR集合中所有副本所在的节点信息、OSR集合中所有副本所在的节点信息
private Cluster cluster;
// 是否需要强制刷新元数据
private boolean needUpdate;
// Topic 的元数据过期时间,默认5分钟
private final Map topics;
// 是否允许自动创建Topic(Broker配置了auto.create.topics.enable=true,且KAFKA集群不存在指定的Topic时自动创建同名Topic)
private final boolean allowAutoTopicCreation;
...
} 2.3.1、懒加载
KAFKA 生产者客户端在初始化时并不会加载元数据,这是懒加载的编程思想,元数据是由 Sender 线程异步加载的。下图展示了生产者客户端发送消息时加载元数据的时序:
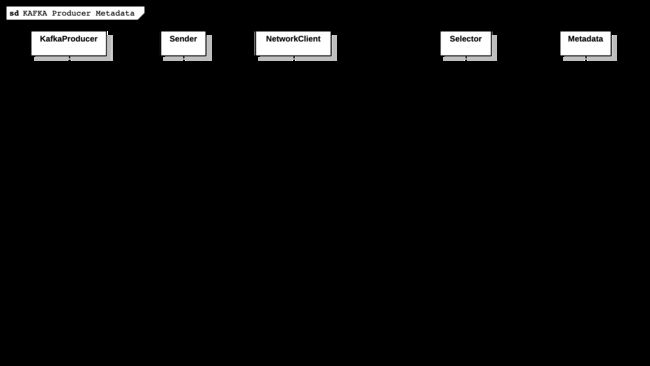
生产者客户端在初始化过程中,Sender 线程首先与 Broker 建立 TCP 连接,随后进入阻塞。加载元数据的关键步骤如下:
1) 【主线程】生产者客户端发送消息时,主线程会唤醒 Sender 线程,随后主线程阻塞,直到 Sender 线程完成元数据的加载。主线程和 Sender 线程的通信是基于 wait/notify 机制;
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
...
do {
// 唤醒Sender线程
sender.wakeup();
try {
// 内部调用wait(),主线程阻塞
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
}
...
}2) 【Sender线程】构造获取元数据的请求,并发送到负载最小的服务端节点;
private long maybeUpdate(long now, Node node) {
// 1、Broker是否可连接
String nodeConnectionId = node.idString();
if (canSendRequest(nodeConnectionId)) {
...
MetadataRequest.Builder metadataRequest;
if (metadata.needMetadataForAllTopics())
metadataRequest = MetadataRequest.Builder.allTopics();
else
metadataRequest = new MetadataRequest.Builder(new ArrayList<>(metadata.topics()), metadata.allowAutoTopicCreation());
log.debug("Sending metadata request {} to node {}", metadataRequest, node);
// 3、构建获取元数据的请求,发送至负载最小的Broker节点
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
return requestTimeoutMs;
}
...
}3) 【Sender线程】NetworkClient 通过NioSelector.select(timeout)获取到请求的响应,进行 TCP 拆包后解析成 NetworkReceive 对象,放入 Deque 尾部;
public void poll(long timeout) throws IOException {
...
// 1、调用NioSelector.select(timeout)取得请求响应
int numReadyKeys = select(timeout);
...
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {
...
if (dataInBuffers) {
...
// 2、TCP拆包(消息定长方式)
// 3、请求响应解析为NetworkReceive对象,塞到Deque尾部
pollSelectionKeys(toPoll, false, endSelect);
}
...
}4) 【Sender线程】NetworkClient 从 Deque 头部取出 NetworkReceive,通过handleCompletedReceives方法更新客户端的元数据,维护在 Metadata 对象中,最后通过notifyAll()唤醒主线程
public List poll(long timeout, long now) {
...
List responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
// 1、Deque头部取出NetworkReceive对象
// 2、更新Metadata对象中的元数据信息
// 3、通过notifyAll()唤醒所有线程
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
} 2.4、分区分配
分区器的作用是为消息分配分区,至于为何要分区,其核心的目的在于水平扩展,KAFKA 的性能瓶颈在于磁盘文件的读写,如果同一个Topic的消息都写到一台Broker,吞吐率就会降低,也没办法水平扩展。KAFKA 生产者是按分区发送消息的,消息最终按分区分片切成多个数据文件+索引文件后顺序写磁盘,因此每台 Broker 都会持有不同的分区分片文件,可以让分区的读写尽可能均匀分发到多个节点上,感兴趣的同学可以了解下KAFKA的日志存储。如果生产者客户端没有指定分区器,则会用默认的分区器对消息进行分区,默认的分区器是在生产者客户端初始化时通过反射方式实例化的。默认的分区器逻辑如下:
-
如果消息指定了分区编号,则直接使用;
-
如果消息未指定分区编号,且Key不为空,则先使用高性能、低碰撞率的 MurmurHash2 算法计算 Key 的哈希值,与 Topic 的总分区数取模得出分区编号;
-
如果消息未指定分区编号,且Key为空,则按照Round-Robin 分区分配策略,使得消息能够最大限度地被均匀分配到 Topic 的各分区;
2.4.1、Round-Robin 分区策略
KAFKA 生产者默认的分区分配策略是 Round-Robin,有如下要点:
-
相比旧版本客户端,新版生产者客户端用 ThreadLocalRandom 取代了 Random,与 Random 相比,ThreadLocalRandom 号称能在高并发下大幅度减少性能开销和资源抢夺;
-
nextValue 函数中为什么要用 AtomicInteger 而不是 Integer,原因是生产者客户端必定有很多业务使用它来发送消息,需要保证消息最终能发到对的分区,因此 partition 方法必须是线程安全;
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 消息无Key:分区编号 = (随机数 % Topic的分区数)
int nextValue = nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 消息有Key:分区编号 = (MurmurHash2算法计算Key的哈希值 % Topic的分区数)
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
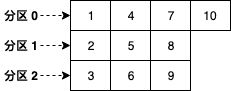
} 分析上述代码不难发现,在同一个生产者客户端线程中,会随着发送消息的数量增加而均匀地分配到 Topic 的各个分区。假设 Topic 有 3 个分区,发送 10 条消息,最终消息的分区分布如下:
2.5、消息缓存
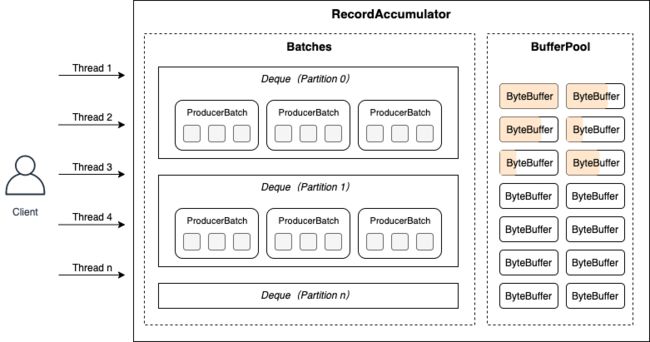
KAFKA 生产者的消息并非直接发送到服务端的,而是先进行攒批,当攒批量达到一定条件后才一次性发送,这样有利于网络IO,提升吞吐量。为此,KAFKA 生产者设计了一个缓存结构,设计思想是一方面客户端作为主线程源源不断地把消息发送到缓存中就直接返回,另一方面 Sender 线程负责当缓存中的消息达到一定数量后进行网络IO发送到服务端。
前文提到,RecordAccumulator(消息累加器)负责缓存生产者客户端产生的消息。生产者客户端发送消息时,会为消息的目标分区创建一个用于存放 ProducerBatch 的双端队列,其中 ProducerBatch 用于消息攒批,包含一条或多条 MemoryRecord(客户端生产的消息),攒批的大小可通过生产者客户端参数batch.size配置(默认为 16KB),而整个缓存池(BufferPool)的大小可以通过生产者客户端参数buffer.memory配置(默认为 32 MB)
2.5.1、内存复用
ProducerBatch 负责缓冲消息,底层存储容器是 ByteBuffer,其创建和销毁是比较消耗资源的,试想如果每个缓冲区都创建新的 ByteBuffer,用完后再由GC回收的话,在海量高吞吐的场景下势必会造成频繁的FGC,性能大打折扣,为了实现内存的高效利用,基本上每个成熟的框架都有一套内存管理机制,KAFKA 客户端设计了 BufferPool 来实现对 ByteBuffer 的复用,对象创建时是从内存池取出空闲内存块,用完后归还内存池。
※ 1、内存池的布局
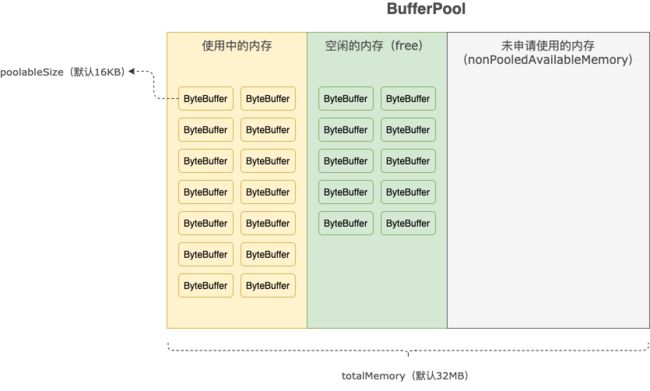
public class BufferPool {
// 内存池的总大小,默认32MB,可根据客户端参数 buffer.memory 调整
private final long totalMemory;
// 内存块的大小(ByteBuffer的大小),默认16KB,可根据客户端参数 batch.size 调整
private final int poolableSize;
// 申请、归还内存操作的同步锁
private final ReentrantLock lock;
// 空闲的内存块
private final Deque free;
// 正在等待空闲内存块的事件
private final Deque waiters;
// 未申请使用的内存
private long nonPooledAvailableMemory; ※ 2、申请内存块
- 内存充足的场景:
-
申请内存块的大小 <= batch.size:直接分配内存块;
-
申请内存块的大小 > batch.size:从已分配的空闲的内存(free)中回收内存,直到 nonPooledAvailableMemory 内存的大小大于等于申请内存块的大小,最后从 nonPooledAvailableMemory 分配内存块;
-
-
内存紧缺的场景:阻塞当前线程等待空闲内存块,循环收集空闲的内存,直到累计收集的内存足够分配内存块为止;
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
// 1、所申请的内存大小超过buffer.memory配置值,即超出整个内存池的大小
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
// 控制线程申请或归还内存块操作的可重入
this.lock.lock();
try {
// 2、所申请的内存大小是否等于batch.size配置的大小,且是否已有空闲未使用的内存块
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
int freeListSize = freeSize() * this.poolableSize;
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// 3、当前空闲的总内存充足,调整可用内存的值,此时尚未分配内存块
freeUp(size);
this.nonPooledAvailableMemory -= size;
} else {
// 4、当前空闲的总内存紧缺,阻塞等待空闲的内存块
int accumulated = 0;
Condition moreMemory = this.lock.newCondition();
try {
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);
// 4.1、持续等待空闲内存块,一点一点分配,只要累计分配到的内存块仍不足申请的内存就会一直循环下去
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
// 4.2、线程阻塞,唤醒的时机有两种,要么等待超时,要么内存池回收了内存块
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
this.waitTime.record(timeNs, time.milliseconds());
}
if (waitingTimeElapsed) {
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// 4.3、所申请的内存大小等于batch.size,且刚有空闲内存块,则直接分配
buffer = this.free.pollFirst();
accumulated = size;
} else {
// 4.4、从已有空闲的内存中一点一点分配
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
accumulated += got;
}
}
// Don't reclaim memory on throwable since nothing was thrown
accumulated = 0;
} finally {
// When this loop was not able to successfully terminate don't loose available memory
this.nonPooledAvailableMemory += accumulated;
this.waiters.remove(moreMemory);
}
}
} finally {
// signal any additional waiters if there is more memory left
// over for them
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
// Another finally... otherwise find bugs complains
lock.unlock();
}
}
if (buffer == null)
return safeAllocateByteBuffer(size);
else
return buffer;
}
private ByteBuffer safeAllocateByteBuffer(int size) {
boolean error = true;
try {
ByteBuffer buffer = allocateByteBuffer(size);
error = false;
return buffer;
} finally {
if (error) {
this.lock.lock();
try {
this.nonPooledAvailableMemory += size;
if (!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
this.lock.unlock();
}
}
}
}※ 3、归还内存块
Sender 线程成功发送一批消息到KAFKA服务端后,会触发归还内存块的操作,内存块归还后会唤醒正在等待空闲内存块的线程;
public void deallocate(ByteBuffer buffer, int size) {
// 控制线程申请或归还内存块操作的可重入
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
// 归还的内存块大小等于batch.size,则清空内容后放置到「空闲内存区(free)」
buffer.clear();
this.free.add(buffer);
} else {
// 归还的内存块至「未申请使用的内存区(nonPooledAvailableMemory)」
this.nonPooledAvailableMemory += size;
}
// 唤醒正在等待空闲内存块的线程
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}由此可见,生产者发送消息时无论是同步还是异步发送,可能都会因为等待空闲内存块而被阻塞
2.5.2、分段加锁
生产者客户端每发送一条消息,都会调用org.apache.kafka.clients.producer.internals.RecordAccumulator#append,因此它是高并发方法,需要保证线程安全。在高并发海量吞吐的场景下,如何才能保证消息有序、高吞吐地发送是值得思考的问题。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
...
ByteBuffer buffer = null;
try {
// 1、获取分区的ProducerBatch队列,若不存在则创建
Deque dq = getOrCreateDeque(tp);
// 2、向队列中最后一个ProducerBatch追加消息
synchronized (dq) {
...
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
// 3、追加失败,向内存池申请内存块,内存块大小是取消息长度和batch.size配置值的较大者
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
...
// 4、再次向队列中最后一个ProducerBatch追加消息
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 5、创建新的ProducerBatch,追加消息
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
// 6、将新创建的ProducerBatch放入队列尾部,添加到batches集合中
dq.addLast(batch);
// 7、将新创建的ProducerBatch添加到incomplete集合中
incomplete.add(batch);
// 8、避免代码走到finally就把刚申请的内存块回收掉
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
// 9、上述步骤执行异常时需要归还刚申请的内存块,避免内存泄漏
if (buffer != null)
free.deallocate(buffer);
}
} 代码看起来可能有点奇怪,写了一堆synchronize,为啥不直接在完整的synchronize块中完成?这恰恰正是设计者的高明之处,其意义在于尽可能将锁的粒度更加精细化进一步提高并发,从上一节 2.5.1 得知,向BufferPool申请内存时可能会导致阻塞,假设一种场景:线程1发送的消息比较大,需要向BufferPool申请新的内存块,而此时因为BufferPool空间不足,随后进入阻塞,但此时它仍然持有Deque的锁;线程2发送的消息很小,Deque最后一个ProducerBatch的剩余空间足够,但由于线程1持有了Deque的锁导致阻塞,若类似线程2情况的线程较多时,势必会造成大量不必要的线程阻塞,降低吞吐量和并发。
2.5.3、读多写少
再来看看这段代码,作用是取出分区对应的 ProducerBatch 队列
Deque dq = getOrCreateDeque(tp);
private Deque getOrCreateDeque(TopicPartition tp) {
Deque d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
} 其中this.batches采用了CopyOnWriteMap数据结构来存放
private final ConcurrentMap> batches;
this.batches = new CopyOnWriteMap<>(); 上一节讲到,客户端每发送一条消息都会调用一次append方法,假设Topic有3个分区,总共发送1000万条消息就需要调用1000万次getOrCreateDeque(tp),其中get调用了1000万次,putIfAbsent仅调用了3次,可见这是一个高并发读多写少的场景。针对此场景,KAFKA精心设计了CopyOnWriteMap,CopyOnWriteMap允许线程并发访问,读操作没有加锁限制,性能较高,而写操作需要先在堆内存创建新对象,再将原对象的内容拷贝至新对象,写操作需要上锁。这种数据结构的优点和缺点都非常明显,优点是:
-
采用读写分离的思想,读操作性能很高,几乎无需额外开销,十分适用于读多写少的场景;
-
map采用volatile关键字修饰,保证了写操作对map的修改对其它线程可见;
缺点是:
-
每次写操作都要内存复制一份,数据量大时对内存开销较大,容易导致频繁GC;
-
无法保证数据的强一致性,毕竟读写是作用于新老对象;
public class CopyOnWriteMap implements ConcurrentMap {
// 可见性
private volatile Map map;
public CopyOnWriteMap() {
this.map = Collections.emptyMap();
}
// 不加锁读
@Override
public boolean containsKey(Object k) {
return map.containsKey(k);
}
// 不加锁读
@Override
public V get(Object k) {
return map.get(k);
}
// 加锁写,内容拷贝到新对象
@Override
public synchronized V put(K k, V v) {
Map copy = new HashMap(this.map);
V prev = copy.put(k, v);
this.map = Collections.unmodifiableMap(copy);
return prev;
}
@Override
public synchronized V putIfAbsent(K k, V v) {
if (!containsKey(k))
return put(k, v);
else
return get(k);
}
} 2.6、消息发送
生产者客户端发送消息到RecordAccumulator缓冲区后,如果缓冲区中当前的ProducerBatch已满或者有新创建的ProducerBatch,就会唤醒Sender线程,随后Sender线程异步地做一系列的校验确认是否可以向服务端发送消息,核心过程如下:
-
RecordAccumulator.ready() 方法获取KAFKA集群中符合发送消息条件的节点集合,必须满足如下所有条件:
-
Deque中有多个或第一个ProducerBatch已满;
-
BufferPool的内存空间耗尽,此时有其它线程等待空闲内存块;
-
ProducerBatch攒批超时(等待消息攒批的过期时间);
-
Sender 线程是否准备关闭;
-
-
RecordAccumulator.drain() 方法是将
private long sendProducerData(long now) {
// 1、获取KAFKA集群的元数据
Cluster cluster = metadata.fetch();
// 2、获取KAFKA集群中符合发送消息条件的节点集合。需满足如下条件:
// (1) Deque中有多个或第一个ProducerBatch已满
// (2) BufferPool的内存空间耗尽,此时有其它线程等待空闲内存块
// (3) ProducerBatch攒批超时(等待消息攒批的过期时间)
// (4) Sender 线程是否准备关闭
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 3、获取不到Leader副本的分区集合,其原因可能是由于元数据获取超时导致的,因此强制再次刷新元数据
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 4、在准备发送消息的节点集合中剔除网络连接失败的节点
Iterator iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// 5、将 结构转换成 ,
// 并将发送至同一个节点所有分区的ProducerBatch都归并到一起(大小不超过 max.request.size 的配置值)
Map> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
if (guaranteeMessageOrder) {
for (List batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
...
// 6、构造消息发送请求,发送到服务端
sendProduceRequests(batches, now);
return pollTimeout;
} 2.6.1、重复发送
问题原因:如果生产者客户端启用了重试机制(retries配置重试次数,默认不重试),可能会出现这种情况,客户端向服务端发送消息过程由于网络抖动让客户端误以为发送失败,并在一段时间后触发重试,导致消息重复发送。另外由于重试的缘故,可能会导致消息的乱序(A、B两条消息先后发送,A发送失败,B发送成功,A重试后成功,故导致A顺序在B之后)
解决方案:生产者客户端开启幂等机制(enable.idempotence配置是否开启,默认关闭),开启的条件同时要求max.in.flight.requests.per.connection<=5 且retries> 1 且acks= all,此配置是客户端会话级别,作用范围是Topic的消息;实现原理是客户端为每条消息生成自增ID,服务端Broker根据消息ID做幂等;值得注意的是,如果业务上要求保证消息分区内有序,则需要设置max.in.flight.requests.per.connection= 1,意思是限制客户端在单个连接上能够发送的未获得响应请求的个数,设置为1表示Broker在响应请求前客户端不能再向同一个Broker发送请求,因此此举将直接导致吞吐量大幅度下降。
2.6.2、消息丢失
背景描述:生产者客户端向服务端发送消息时,针对服务端是否收到消息的答复,有三种ACK机制:
-
acks = 0:无需等待任何Broker确认收到消息的答复,直接继续下一条消息的发送,因此吞吐性能最高,也最容易导致数据丢失;
-
acks = 1:至少需要等待分区Leader副本确认将消息成功落盘,但无需等待其它Follower副本是否同步成功,因此如果当Follower尚未同步完而Leader宕机,Follower又选举为新的Leader时,就会导致数据丢失;
-
acks = all:需要等待ISR集合中所有Leader、Follower副本都将消息成功落盘,是最高的写入保证,但意味着性能会随着副本数增加而下降,另外如果是单副本的话,就退化成acks=1,会存在丢数据的风险;
问题原因:有如下几种
-
acks=0 或 acks=1;
-
acks = all 且 单副本(min.insync.replicas= 1)则退化成 acks = 1;
-
unclean.leader.election.enable = true,意思是允许OSR中的副本选举为Leader,Leader宕机而OSR中的副本当选为新Leader,会导致很严重的丢数据现象,一般此开关极少打开;
解决方案:最直接的 acks = all 且 min.insync.replicas > 1
感谢阅读!文章篇幅比较大,写作周期较长。最后安利下 KAFKA 3.0,KRaft 干掉了 ZooKeeper,另外对于生产者默认启用了最强的交付保证:What's New in Apache Kafka 3.0.0 : Kafka