分布式存储技术(上):HDFS 与 Ceph的架构原理、特性、优缺点解析
面对企业级数据量,单机容量太小,无法存储海量的数据,这时候就需要用到多台机器存储,并统一管理分布在集群上的文件,这样就形成了分布式文件系统。HDFS是Hadoop下的分布式文件系统技术,Ceph是能处理海量非结构化数据存储的对象存储技术,本文将对他们的架构原理、特性和优缺点做介绍。

— 分布式文件系统HDFS —
HDFS全称为Hadoop Distributed File System,在2006年由Doug Cutting发布了第一个版本,是运行在通用硬件上的分布式文件系统。它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。HDFS的推出给当时的行业提供了一个低成本、高可扩展的数据存储方案,尤其适用于互联网行业的海量用户访问日志的存储和检索需求,因此一经推出就受到了互联网行业的欢迎,以Yahoo为代表的互联网企业快速构建了基于HDFS的企业数仓,从而加速了Hadoop在互联网行业内的快速落地(后来这个Yahoo团队独立出来创立了Hortonworks)。此后经过3~4年的快速发展,海外的大型企业都开始拥抱HDFS,各种新型应用场景开始出现并创造了较大的业务价值。从2009年开始,国内的Hadoop应用开始出现,并最早在运营商和互联网行业落地。作为Hadoop体系的最成功的项目,HDFS已经在各种大型在线服务和数据存储系统中得到广泛应用,已经成为私有化部署领域海量数据存储的实施标准。
HDFS通过一个高效的分布式算法,将数据的访问和存储分布在大量服务器之中,在可靠地多备份存储的同时还能将访问分布在集群中的各个服务器之上。在构架设计上,NameNode管理元数据,包括文件目录树,文件->块映射,块->数据服务器映射表等。DataNode负责存储数据、以及响应数据读写请求;客户端与NameNode交互进行文件创建/删除/寻址等操作,之后直接与DataNode交互进行文件I/O。
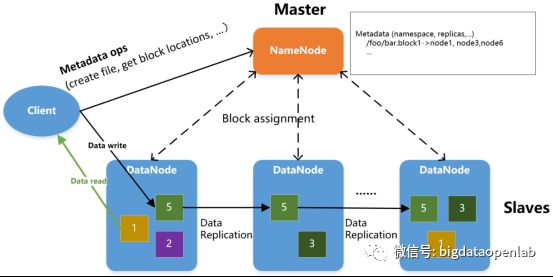
HDFS通过副本机制保证数据的存储安全与高可靠,默认如上图所示配置为3副本,每个数据块分布在不同的服务器之上。在用户访问时,HDFS将会计算使用网络最近的和访问量最小的服务器给用户提供访问。HDFS支持文件的创建、删除、读取与追加,对于一个较大的文件,HDFS将文件的不同部分存放于不同服务器之上。在访问大型文件时,系统可以并行从服务器阵列中的多个服务器并行读入,增加了大文件读入的访问带宽。通过以上实现,HDFS通过分布式计算的算法,将数据访问均摊到服务器阵列中的每个服务器的多个数据拷贝之上,单个硬盘或服务器的吞吐量限制都可以突破,提供了极高的数据吞吐量。
HDFS将文件的数据块分配信息存放在NameNode服务器之上,文件数据块的信息分布地存放在DataNode服务器上。当整个系统容量需要扩充时,只需要增加DataNode的数量,HDFS后续通过balance算法将数据块搬迁到新的DataNode实例中。通过以上实现,HDFS可以做到在不停止服务的情况下横向扩容和数据重新分布。HDFS文件系统假设系统故障(服务器、网络、存储故障等)是常态,并通过多方面措施来保证数据的可靠性。数据在写入时被复制多份,可以通过用户自定义的复制策略分布到物理位置不同的服务器上;数据在读写时将自动进行数据的校验,一旦发现数据校验错误将重新进行复制。
受限于当时的需求背景和硬件能力水平,HDFS也有一些明显的架构问题,随着技术和需求的演进而逐渐成为瓶颈。通过NameNode来管理元数据有它的架构问题,首先是服务高可用问题,在Hadoop 1.0时代这是最大的架构问题,不过在2013年Hadoop 2.0中通过Master-Slave的方式得以解决;另外每个存储的文件都必须在NameNode的内存中维护一个描述符从而占据内存空间,当文件数据量太大时就会受限于单个NameNode的内存资源从而导致性能瓶颈(一般单个集群文件数量在亿级别以上时),社区在2017年推出的Hadoop 2.9版本提供HDFS Router Federation功能,通过不同的NameService处理挂载在HDFS上不同目录下的文件的方式来缓解这个问题。
存储成本问题对于大型HDFS集群是个更大的问题,HDFS的三副本策略保证了性能和存储成本的均衡,适合于热数据和温数据的存储和处理,对于冷数据存储来说成本就偏高,尤其与对象存储类的解决方案相比。开源社区直到2019年Hadoop 3.0里才推出了Erasure Code技术(星环科技在2014年推出HDFS EC技术),但由于推出时间较晚和技术成熟度等原因,目前并没有大规模落地。与云计算的存储技术融合是另外一个重要的架构问题,公有云有成熟的云存储方案,相对HDFS成本更低,与云平台的调度系统协调的更好,而HDFS只能定位作为云上的企业存储的一个细分方案之一。如各个云平台都推出EMR(Elastic MapReduce)类产品,如Google Dataproc,阿里云EMR等,但总体受欢迎度比较一般,缺少与云上其他数据分析与处理系统的全方位的打通和互联。
从2012年开始,国内重点行业的中大型企业都已经开始了大数据的布局,到2019年像金融、运营商、能源、政府公安等重要行业大部分企业都已经构建了基于HDFS的数据存储系统,推动了一批重点的数字化应用的推广。如金融行业的ODS、历史数据存储、数据湖、科技监管类应用,运营商的经分系统、电子围栏、数字营销系统等,都已经是广泛使用的业务系统。由于国内外行业需求的差异性以及对公有云的接受程度不同,HDFS在国内仍然是一个非常重要的数据存储技术,也拥有更好的技术和应用生态,因此有着更为完善的技术生命力。
— 对象存储Ceph —
对象存储的设计目标是为了处理海量非结构化数据的存储问题,如邮件、图谱、视频、音频以及其他多媒体文件,并在社交、移动等应用中大量被使用,此外也大量被用于数据备份和灾备场景。
在业务开发层一般提供基于S3协议的开发接口,这套API提供了一整套的RESTful API,可以让应用可以通过HTTP PUT或GET命令来操作数据对象,每个对象有个自己的访问地址。与HDFS等文件类存储采用目录结构或多层级树形结构不同,对象存储在物理存储上一般采用一个扁平的数据存储结构,每个对象都是一个包括元数据、数据和唯一标识ID的完备数据描述,这样应用可以非常方便的去找到并访问这个数据对象,在存储的管理上也相对比较简单,尤其是大部分应用场景下数据对象都存储在远端的云服务器上。对象存储管理软件会将所有的硬盘资源抽象为一个存储池,用于数据的物理化存储。相对于文件类存储,对象存储相对来说成本更低,但相对数据分析的性能不佳,需要配套各种分析的缓存技术来能提供比较好的数据分析性能。
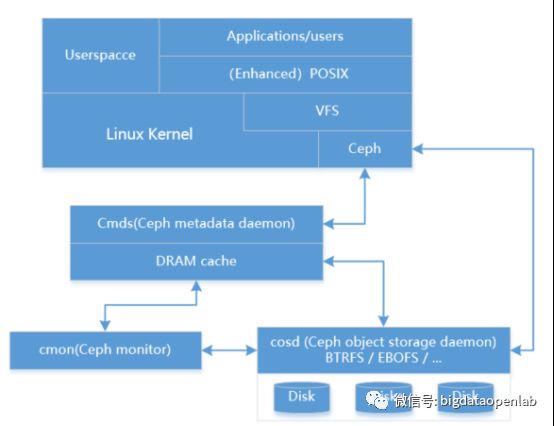
Ceph是一个开源的对象存储项目,诞生于2004年,提供对象、块和文件存储,其中对象存储功能在业内非常受欢迎,在国内已经有很多私有化云平台的对象存储生产落地案例。一个Ceph的存储集群一般包括三个部分:
-
Ceph存储集群服务端:在Ceph存储集群服务端架构中核心组件有Monitor服务、OSD(Object Storage Daemons)服务和Manager服务等。其中Mon服务用于维护存储系统的硬件逻辑关系,主要是服务器和硬盘等在线信息。Mon服务通过集群的方式保证其服务的可用性。OSD服务用于实现对磁盘的管理并实现真正的数据读写,通常一个磁盘对应一个OSD服务。
-
Ceph Clients:以library方式提供的客户端,可以用于访问Ceph服务端,它提供了3种协议来访问,包括对象存储的RADOSGW、块存储端的RBD以及文件存储的CephFS。
-
Ceph 协议:用于服务端和Client的通信协议。
由于一个分布式存储集群管理的对象数量非常多,可能是百万级甚至是千万级以上,因此OSD的数量也会比较多,为了有好的管理效率,Ceph引入了Pool、Place Groups(PGs)、对象这三级逻辑。PG是一个资源池的子集,负责数据对象的组织和位置映射,一个PG负责组织一批对象(数据在千级以上)。同时一个PG会被映射到多个OSD,也就是由多个OSD来负责其组织的对象的存储和查询,而每个OSD都会承载大量的PG,因此PG和OSD之间是多对多的映射关系。
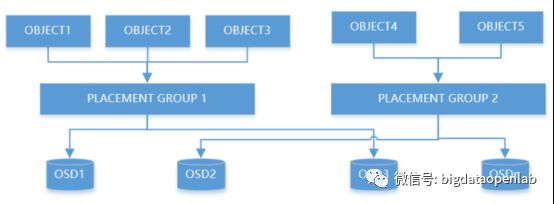
当用户要将数据存储到Ceph集群时,存储数据会被分割成多个对象(Ceph的最小存储单元),每个对象都有一个唯一的id,每个对象的大小是可以配置的,默认为4MB。Ceph通过自创的CRUSH哈希算法,将若干个对象映射到PG上,形成一个对象与PG的逻辑组合,并根据PG所在的Pool的副本数,将数据复制到多个OSD上,保证数据的高可用。

图片来源于:https://www.wenjiangun.com/blog/952/
在集群的可扩展性上,Ceph可以做到几乎线性扩展。CRUSH 通过一种伪随机的方式将数据进行分布,因此 OSD 的利用就能够准确地通过二项式建模或者常规方式分配。无论哪一个都可以取得完美的随机过程。随着 PG 的增加,差异就下降:对于每个 OSD 100 个 PG的情况下,标准差是 10%;对于1000 个的情况下为 3%。线性的分布策略极好地将负载在集群中平衡。CRUSH 通过卸载所有的分配碎片到一个特定的 OSD 上从而来修正这样的问题。与哈希以及线性策略不同,CRUSH 同时也最小化了数据在集群扩展产生的迁移,同时又保证了负载的平衡。CRUSH 的计算复杂度为 O(log(n))(对于有 n 个 OSD 的集群),因此只需要 10 几个微秒就可以使集群增长到好几千个 OSDs。
值得关注的是,Ceph客户端所有的读写操作都需要经过代理节点,一旦集群并发量较大,代理节点就容易成为单点瓶颈。在数据的一致性方面,Ceph只能支持数据的最终一致性。
— 小结—
本文从架构和原理介绍了高度容错性、高吞吐量的分布式文件系统HDFS,和处理海量非结构化数据存储的对象存储技术Ceph(现在各项技术发展比较快,可能存在技术描述跟最新技术发展情况不太一致的情况)。那么在特定场景下,数据的快速查询、快速写入和可扩展性也是必不可少的,下一篇我们将介绍搜索引擎技术和宽表存储技术。