ES(elasticsearch)集群的那些事
es集群的那些事
- 前言
- 一、ES简单介绍?
- 二、ES集群节点角色
-
- 1.主节点(Master node)
- 2.数据节点(Data node)
- 3.协调节点(Coordinating node)
- 4.配置es集群所需内存
- 三、cat命令查询ES状态
-
- 1.数据节点机器存储信息
- 2.节点信息
- 3.索引信息
- 4.分片信息
- 四、ES简单实用DSL查询
- 总结
前言
相信在平常的项目中,我们经常会用到es去查询高频出现的数据,通常每个业务线会申请自己独立的es集群,那么就需要对自己要存储的数据的量级做一个大致的了解,比如只存储近一年的数据,大概需要占用的内存是多少,以及es集群的节点分片怎么设置,本期就简单介绍一下es集群的那些事。
一、ES简单介绍?
ES是一个基于RESTful web接口并且构建在Apache Lucene之上的开源分布式搜索引擎。同时ES还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,能够横向扩展至数以百计的服务器存储以及处理PB级的数据。
可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机。
二、ES集群节点角色
一般搭建一个es集群需要三个角色的节点,分别是主节点(Master node)、数据节点(Data node)、协调节点(Coordinating node)。接下来就简单的介绍一下以上几个节点:
1.主节点(Master node)
- 主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。主节点也可以作为数据节点,但稳定的主节点对集群的健康是非常重要的,默认情况下任何一个集群中的节点都有可能被选为主节点,索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。
2.数据节点(Data node)
- 数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
3.协调节点(Coordinating node)
- 客户端请求可以发送到集群的任何节点,每个节点都知道任意文档所处的位置,然后转发这些请求,数据并返回给客户端,处理客户端请求的节点称为协调节点。协调节点将请求转发给保存数据的数据节点。每个数据节点在本地执行请求,并将结果返回给协调节点。协调节点收集完数据合,将每个数据节点的结果合并为单个全局结果。对结果收集和排序的过程可能需要很多CPU和内存资源。
4.配置es集群所需内存
- 一般先需要预估自己业务线存储数据的量级大小,比如需要在es存储近一年的数据,一个月的数据大概是一个亿,每条数据假设大小为1k,那么存储一年的大小大概就是1亿×12×1k=1,200,000,000k≈1200G的大小。所以我们需要大概1.2T左右的内存,假如配置了3个data node,那么每个node大概就是400G左右的大小,当然现实中,我们配置的的内存大小肯定是大于预估的,因为随着业务的增加量级也会增长,所以配置的内存大小都会比预估的要大一些。
三、cat命令查询ES状态
1.数据节点机器存储信息
命令:GET _cat/allocation/?v

shards 节点所承载的分片数
disk.indices 索引占用的空间大小
disk.used 节点所在机器已使用磁盘空间
disk.avail 节点所在机器剩余磁盘空间
disk.total 节点所在机器磁盘空间
host和ip 节点所属机器IP地址
node 节点名
2.节点信息
命令:GET _cat/nodes?v
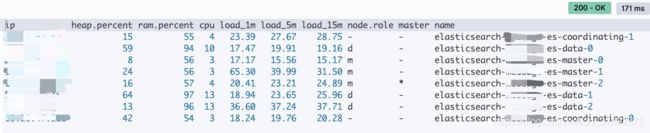
ip 节点的IP地址
heap.percent 堆内存占用百分比
ram.percent 内存占用百分比
cpu CPU占用百分比
master *表示节点是集群中的主节点
name 节点名
3.索引信息
命令:GET _cat/indices/?v

health 索引的健康状态
index 索引名
pri 索引主分片数量
rep 副本数量
store.size 索引主分片 复制分片 总占用存储空间
pri.store.size 索引总占用空间, 不计算复制分片 占用空间
4.分片信息
命令:GET _cat/shards/?v

index 索引名称
shard 分片序号
prirep p表示该分片是主分片, r 表示该分片是复制分片
store 该分片占用存储空间
node 所属节点节点名
docs 分片存放的文档数
以上就是es简单的一些查询状态信息,当然还有一些其他的命令,有需要的可以在网上搜索进行查看。
四、ES简单实用DSL查询
查询语句:
GET /index_name _*/_search
对索引名称前缀为index_name的进行查询,以下是查询param=1,且按time倒序输出,es默认最大返回数据10000条,from和size是分页的数据:
GET /index_name _*/_search
{
"from":0,
"size":1000,
"query":{
"bool":{
"must":[
{
"term":{
"param":{
"value":"1",
"boost":1
}
}
}
],
"adjust_pure_negative":true,
"boost":1
}
},
"sort":[
{
"time":{
"order":"desc"
}
}
]
}
查询结果:
{
"took" : 591,
"timed_out" : false,
"_shards" : {
"total" : 48,
"successful" : 48,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
hits里的value值是查出来的数量,hits数组是查询的数据,我们可以看到查出来的数据为空。
总结
ES搜索在项目中会经常用到,但是有时候需要自己申请一套es集群,那么以上的基本信息就需要了解,在尽可能满足功能要求的基础上节约成本,那么es集群就需要结合具体的业务场景去合理的配置。希望以上内容能够对你有所帮助!!!