【Python课程作业】食物数据的爬取及分析(详细介绍及分析)
食物数据爬取及分析
-
- 项目概述
- 网页爬取
-
- 食物类别
- 表头设置
- 食物数据爬取保存
- 运行结果
- 数据分析
-
- CSV文件读取
- 总体描述
- 分类分析
- 特定食物分析
- 运行结果
- 项目资源
项目概述
日常生活中我们食用的各种食物具有很多营养属性,比如卡路里、蛋白质与脂肪含量和各种微量元素,通过分析不同食物的营养含量对我们日常生活的饮食健康有很大好处,同时网页中有很多开放的食物数据库,我们可以爬取网页数据保存到本地文件供我们分析。该项目即通过爬取网页食物数据,并进行分析与可视化,也便于后续进行个人饮食健康评估与健康饮食推荐的研究。
网页爬取
- 程序路径:
foodData\GetData.py
通过对目标网页的观察,网页结构整齐,所以这里使用XPath的方法,同时为了实现访问一次就可以得到不同层次的数据,用下面的函数实现:
url:网页域名xpathlist:数据类型为list,可包括不同层次的xpath路径
# 爬取数据
def getData(url, xpathList):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.109 Safari/537.36'}
try:
response = requests.get(url, headers=headers)
response = lxml.etree.HTML(response.text)
# print(response)
except:
print('打开网址失败!!!请检查!')
return
dataList = []
for i in range(len(xpathList)):
data = response.xpath(xpathList[i])
if len(data) == 0:
print(f"爬取数据为空!请检查xpath路径xpathList[{i}]!")
# print(data)
dataList.append(data)
# 返回数据列表
return dataList
食物类别
爬取数据网页的域名为:http://db.foodmate.net/yingyang/type_%s.html ,其中%s 为**‘1’~‘21’**表示不同食物种类,如下图所示,该页面为%s='1'时谷类食物页面。
通过观察,食物种类数据在xpath='//*[@id="top"]/a'中,值得注意的是页面缺失type_12、type_13、type_14的数据,通过手动输入域名我们可以发现这三个食物类别分别为:['鱼类', '婴儿食品类', '小吃类'],函数实现如下:
- 得到结果:
['谷类', '薯类淀粉', ' 干豆类', '蔬菜类', '菌藻类', '水果类', '坚果种子', '畜肉类', '禽肉类', '乳类', '蛋类', '鱼类', '婴儿食品类', '小吃类', '速食食品', '软饮料', '酒精饮料', '糖蜜饯类', '油脂类', '调味品类', '药食及其它', 'xlfcnkvf']
# 爬取食物种类类别
def getFoodKind():
url3 = f'http://db.foodmate.net/yingyang/type_1.html'
xpathList3 = ['//*[@id="top"]/a']
dataElem3 = getData(url3, xpathList3)
kindfood_temp = ['鱼类', '婴儿食品类', '小吃类']
kindFood = []
i = 0
sign = 0
signList = [11, 12, 13]
while i < len(dataElem3[0]):
if sign in signList:
kindFood.append(kindfood_temp[sign - 11])
sign += 1
else:
kindFood.append(dataElem3[0][i].text)
i += 1
sign += 1
return kindFood
表头设置
在食物种类页面,我们可以得到食物的名称,同时名称中包含食物的别名和特性,比如甘薯(红心)[山芋,红薯],后面在数据爬取中我们将其分离,至此我们的表头可以手动设置为 headers = ['食物', '别名', '特征', '分类', 'Wiki百科'],每种食物的营养物质名称可以在特定食物页面中获得,这里爬取的为小麦网页页面,域名为: http://db.foodmate.net/yingyang/type_0%3A1%3A0_1.html。
xpath路径:'//*[@id="rightlist"]/div[@class="list"]//text()'
函数实现:
- 得到结果:
['食物', '别名', '特征', '分类', 'Wiki百科', '热量(千卡)', '硫胺素(毫克)', '钙(毫克)', '蛋白质(克)', '核黄素(毫克)', '镁(毫克)', '脂肪(克)', '烟酸(毫克)', '铁(毫克)', '碳水化合物(克)', '维生素C(毫克)', '锰(毫克)', '膳食纤维(克)', '维生素E(毫克)', '锌(毫克)', '维生素A(微克)', '胆固醇(毫克)', '铜(毫克)', '胡罗卜素(微克)', '钾(毫克)', '磷(毫克)', '视黄醇当量(微克)', '钠(毫克)', '硒(微克)', '备注']
# 爬取表头
def getCsvHeaders():
headers = ['食物', '别名', '特征', '分类', 'Wiki百科']
ur = 'http://db.foodmate.net/yingyang/type_0%3A1%3A0_1.html'
xp = ['//*[@id="rightlist"]/div[@class="list"]//text()']
da = getData(ur, xp)
for i in range(len(da[0]) // 2):
headers.append(da[0][2 * i])
headers.append('备注')
return headers
食物数据爬取保存
食物名称及详细页面链接
一类食物页面其中的每一个食物名称及其数据页面链接都在 xpath=//*[@id="dibu"]/li[@class="lie"]/a路径中,如下图
li[i]/a.text:食物名称li[i]/a.attrib['href']:食物数据页面链接
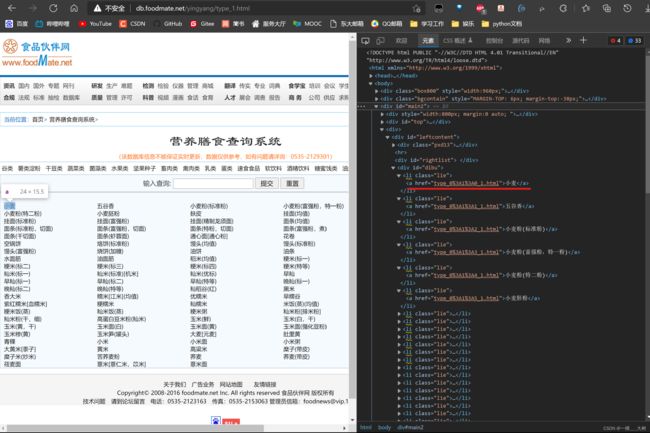
上面我们提到食物名称中可能含有食物的别名('[ ]‘内容)和特征描述(’( )'内容),这里我们用re正则匹配将食物名称中的别名与特征提取出来,如果没有别名或者特征描述,就设置为 'Empty'。
食物的详细数据获取
在上面爬取食物名称时,我们得到了一种食物数据页面的部分链接,所以一种食物数据页面的域名为 'http://db.foodmate.net/yingyang/' + li[i]/a.attrib['href']
如图进入数据页面我们发现我们所需数据的路径有两个:
-
//*[@id="rightlist"]/center/a.attrib['href']:Wiki食物百科链接 -
//*[@id="rightlist"]/div[i]//text():食物营养物质含量数据
数据写入csv文件
filename:文件保存路径data:数据列表(二维)headers:表头列表isHeaders:是否写入表头(第一次写入数据)
# 数据写入csv文件
def dataWriteToCsv(filename, data, headers=None, isHeaders=False):
if headers is None:
headers = []
try:
with open(filename, 'a', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
# 是否写入标题头
if isHeaders:
writer.writerow(headers)
for i in range(len(data)):
writer.writerow(data[i])
print(f'数据写入成功{filename}中!')
except:
print('写入文件失败!!!')
函数实现
foodKindId:食物种类编号1~21foodKind:食物种类列表headers:表头设置列表
# 读取食物营养库一类食物数据并保存到csv文件中
def getFoodDataToCsv(foodKindId, foodKind, headers):
# 食物名称及详细页面
url0 = f'http://db.foodmate.net/yingyang/type_{foodKindId}.html'
xpathList1 = ['/html/body/div[@id="main2"]/div/div[@id="leftcontent"]/div[@id="dibu"]/li[@class="lie"]/a']
dataElem = getData(url0, xpathList1)
# re正则匹配将食物名称中的别名与特征提取出来
pattan1 = re.compile('\[.*?\]')
pattan2 = re.compile('\(.*?\)')
dataList = []
for i in range(len(dataElem[0])):
string_temp = dataElem[0][i].text
# 提取名称中‘【】’的别名
other_name = pattan1.search(string_temp)
# 提取名称中‘()’的特性
features = pattan2.search(string_temp)
if other_name is None:
other_name = 'Empty'
else:
other_name = other_name.group()
other_name = other_name.replace('[', '')
other_name = other_name.replace(']', '')
if features is None:
features = 'Empty'
else:
features = features.group()
features = features.replace('(', '')
features = features.replace(')', '')
# 将名称中的别名与特征去除
f_Name = pattan1.sub('', string_temp)
f_Name = pattan2.sub('', f_Name)
# 写入data列表
data = [f_Name, other_name, features, foodKind[foodKindId - 1]]
# 一种食物的数据页面
url1 = 'http://db.foodmate.net/yingyang/' + dataElem[0][i].attrib['href']
xpathList2 = ['//*[@id="rightlist"]/div[@class="list"]//text()', '//*[@id="rightlist"]/center/a']
data2Elem = getData(url1, xpathList2)
try:
data.append(data2Elem[1][0].attrib['href'])
except:
# Wiki食物百科不存在
data.append('Empty')
for j in range(len(headers) - 6):
try:
data.append(float(data2Elem[0][2 * j + 1]))
# 数据为空设置为nan
except:
data.append(np.nan)
# 备注设置为空
data.append('Empty')
dataList.append(data)
# print(dataList)
# 将数据写进csv文件
dataWriteToCsv('Data\\food.csv', dataList, headers=headers, isHeaders=(foodKindId == 1))
运行结果
主函数
# 主函数
if __name__ == '__main__':
# 爬取食物种类
fK = getFoodKind()
# print(fK)
# 爬取表头
header = getCsvHeaders()
# print(header)
# 爬取食物数据
for num in range(20):
getFoodDataToCsv(num + 1, fK, header)
csv文件部分数据如下
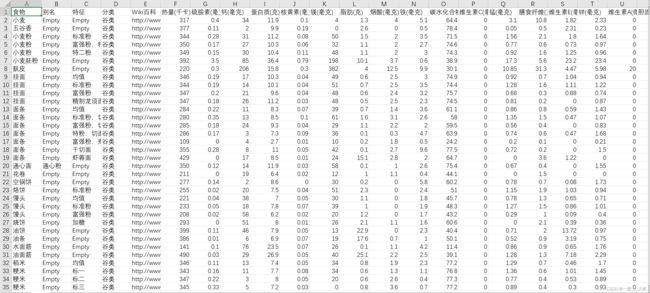
数据分析
-
程序路径:
foodData\DataAnalysis.py -
调用
import pandas as pd和import numpy as np两个库进行数据分析; -
调用
import matplotlib.pyplot as plt进行数据可视化; -
平时我们饮食重点关注食物的热量,所以我们主要对食物热量进行分析;
CSV文件读取
- 调用
import pandas as pd读取:data = pd.read_csv('data\\food.csv') - 调用
import csv读取,函数实现如下:filename:文件路径isDic=False:是否只读取某一列,默认为FalsedicName='':若只读取某一列,该列列名,默认为空
# 读取csv文件
def dataReadFromCsv(filename, isDic=False, dicName=''):
dataList = []
try:
with open(filename, 'r', encoding='utf-8') as f:
# 全部读取
if not isDic:
reader = csv.reader(f)
# 跳过标题
next(reader)
for data in reader:
dataList.append(data)
# 按照标题查询
else:
reader = csv.DictReader(f)
for data in reader:
try:
dataList.append(data[dicName])
except:
print('列名不存在!!')
return
print(f'文件{filename}读取成功!')
return dataList
except:
print('读取csv文件失败!!!')
return
总体描述
RangeIndex: 1404 entries, 0 to 1403:共1404种食物数据;Data columns (total 30 columns):每种食物拥有30种属性;dtypes: float64(24), object(6):30个属性中24种数据类型为浮点型,剩下六种为字符串;memory usage: 329.2+ KB:占用内存;
分类分析
首先得到文件中食物种类的起始索引等相关信息,函数实现如下:
- 得到结果:
[(0, 87, 87, '谷类'), (87, 105, 18, '薯类淀粉'), (105, 177, 72, ' 干豆类'), (177, 377, 200, '蔬菜类'), (377, 412, 35, '菌藻类'), (412, 574, 162, '水果类'), (574, 618, 44, '坚果种子'), (618, 756, 138, '畜肉类'), (756, 815, 59, '禽肉类'), (815, 853, 38, '乳类'), (853, 874, 21, '蛋类'), (874, 1011, 137, '鱼类'), (1011, 1021, 10, '婴儿食品类'), (1021, 1104, 83, '小吃类'), (1104, 1140, 36, '速食食品'), (1140, 1194, 54, '软饮料'), (1194, 1250, 56, '酒精饮料'), (1250, 1283, 33, '糖蜜饯类'), (1283, 1309, 26, '油脂类'), (1309, 1404, 95, '调味品类')]
# 食物类别索引
def foodKindIndex():
# 分类数据
dataKind = dataReadFromCsv('data\\food.csv', dicName='分类', isDic=True)
kindIndex = []
temp = 0
start = 0
tempStr = dataKind[0]
while temp < len(dataKind):
temp += 1
if temp == len(dataKind):
kindIndex.append((start, temp, temp - start, tempStr))
break
if tempStr != dataKind[temp]:
# 四元组(start,end,num,foodName)
kindIndex.append((start, temp, temp - start, tempStr))
tempStr = dataKind[temp]
start = temp
del dataKind
return kindIndex
数量分析
foodKindNum: 20:共20种食物,柱状图如下:
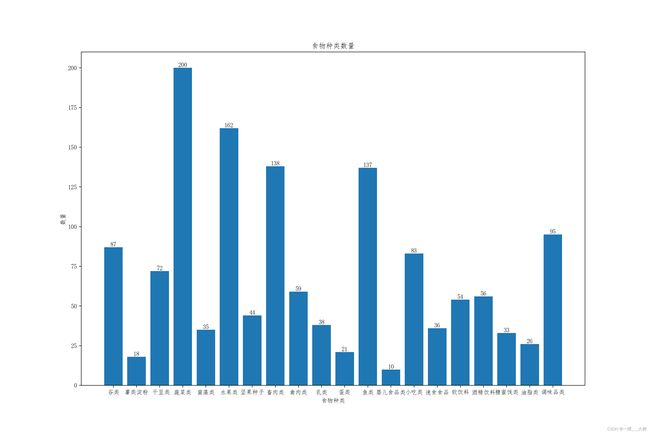
热量分析
-
不同食物种类的平均热量
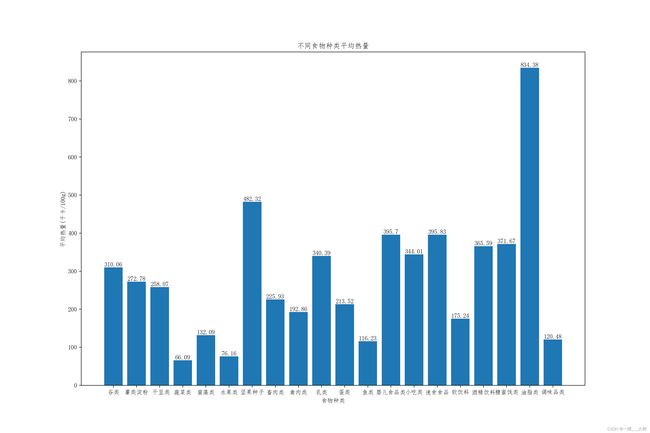
-
不同食物种类最高与最低热量

特定食物分析
查找目标食物
函数实现如下:
foodName:查找名称dataA:食物数据
# 搜索特定食物
def searchFood(foodName, dataA):
reIndex = []
for i in range(len(dataA)):
# 查找名称
if re.search(foodName, dataA[i][0]) is not None:
reIndex.append(i)
# 查找别名
elif re.search(foodName, dataA[i][1]) is not None:
reIndex.append(i)
# 返回查找结果索引
return reIndex
生成热量柱状图
当结果个数为1时,输出该结果的所有数据信息;当结果大于25个时,只绘制前25个热量柱状图。函数实现如下:
dataIndex:结果索引列表dataC:热量数据dataA:食物数据header:表头
# 特定食物生成热量柱状图
def specialDataToImage(dataIndex, dataC, dataA, header):
print(f'查找到{len(dataIndex)}个结果。。。')
if len(dataIndex) == 0:
print('数据索引为空!!')
return
elif len(dataIndex) == 1:
print('只查找到一项,信息如下:')
print(f'名称:{dataA[dataIndex[0]][0]}\t别名:{dataA[dataIndex[0]][1]}\t特征:{dataA[dataIndex[0]][2]}')
print('详细信息:')
for i in range(3, len(header)):
print(f'{header[i]}:{dataA[dataIndex[0]][i]}')
return
elif len(dataIndex) >= 25:
print('查找结果大于25个,结果如下,只给出前10个结果热量柱状图:')
print([f'{dataA[i][0]}({dataA[i][2]})' for i in dataIndex])
dataIndex = dataIndex[0:25]
# 指定默认字体
mpl.rcParams['font.sans-serif'] = ['FangSong']
# 解决保存图像是负号'-'显示为方块的问题
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(25, 10))
name_list = []
for i in dataIndex:
name = dataA[i][0]
if dataA[i][1] != 'Empty':
name += f'\n[{dataA[i][1]}]'
if dataA[i][2] != 'Empty':
name += f'\n({dataA[i][2]})'
name_list.append(name)
num_list = [dataC[i] for i in dataIndex]
plt.bar(range(len(num_list)), num_list, tick_label=name_list)
for x, y in enumerate(num_list):
plt.text(x, y, '%s' % y, ha='center', va='bottom')
plt.title('食物热量比较')
plt.xlabel('食物名称')
plt.ylabel('热量(千卡/100g)')
plt.show()
运行结果
主函数
# 主函数
if __name__ == '__main__':
# data1 = pd.read_csv('data\\food.csv')
data2, headers = dataReadFromCsv('data\\food.csv')
# 数据概览
# print(data1.info())
# 热量数据
dataCalorie = dataReadFromCsv('data\\food.csv', dicName='热量(千卡)', isDic=True)
dataCalorie = [float(i) for i in dataCalorie]
kindI = foodKindIndex()
# 不同食物种类的数目柱状图
# dataToImage2(kindI)
# 不同食物种类的平均热量柱状图
# dataToImage3(kindI, dataCalorie)
# 不同食物种类最高与最低热量柱状图
# dataToImage4(kindI, dataCalorie, data2)
# 查找食物
while 1:
foodN = input('输入要查找食物的名称(退出请输入0):')
if foodN == '0':
break
reList = searchFood(foodN, data2)
specialDataToImage(reList, dataCalorie, data2, headers)
查找:苹果
查找到22个结果。。。
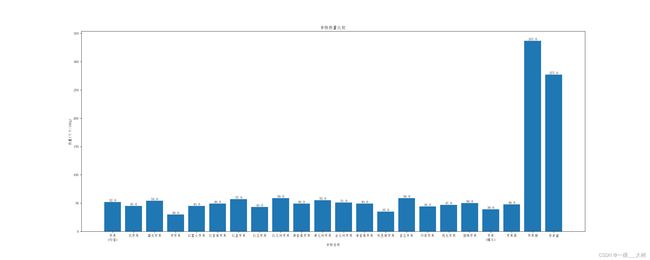
查找:玉米
查找到11个结果。。。

查找:边鱼
查找到1个结果。。。
只查找到一项,信息如下:
名称:参鱼 别名:蓝圆参,边鱼 特征:Empty
详细信息:
['分类:鱼类', 'Wiki百科:http://www.foodbk.com/wiki/%E5%8F%82%E9%B1%BC', '热量(千卡):124.0', '硫胺素(毫克):0.06', '钙(毫克):55.0', '蛋白质(克):18.5', '核黄素(毫克):0.11', '镁(毫克):30.0', '脂肪(克):3.4', '烟酸(毫克):3.6', '铁(毫克):1.8', '碳水化合物(克):4.8', '维生素C(毫克):0.0', '锰(毫克):0.05', '膳食纤维(克):0.0', '维生素E(毫克):0.49', '锌(毫克):0.85', '维生素A(微克):1.0', '胆固醇(毫克):78.0', '铜(毫克):0.11', '胡罗卜素(微克):1.3', '钾(毫克):215.0', '磷(毫克):191.0', '视黄醇当量(微克):72.0', '钠(毫克):81.6', '硒(微克):24.89', '备注:Empty']
查找:鱼
查找到77个结果。。。
查找结果大于25个,结果如下,只给出前25个结果热量柱状图:
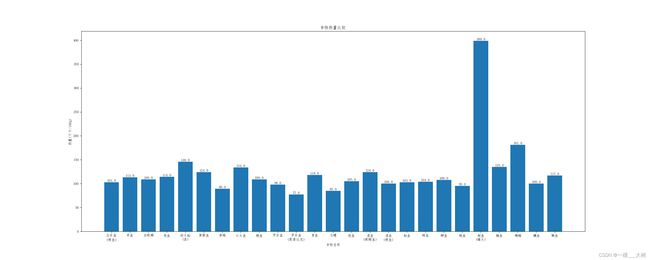
项目资源
- 已在CSDN发布资源
python食物数据爬取及分析(源码、爬取数据、数据可视化图表、报告) - GitHub项目传送门
https://github.com/A-BigTree/college_assignment