HDFS主从架构
NameNode SecondaryNameNode DataNode
一、NameNode(简写为NN,名称节点)
主要功能,存储的内容包括:
1.文件的名称
2.文件的目录结构
3.文件的属性(权限,副本数,创建时间等)
也就是可以用hdfs -dfs ls看的信息
*4.一个文件被对应切割哪些数据块(包括副本数的块) ==> 对应分布在哪些DataNode
管理文件系统的命名空间,维护文件系统树的文件和文件夹
主要文件:
镜像文件:fsimage
编辑日志文件:edits
存储目录:/home/
二、SecondaryNameNode(简写为SNN,第二名称节点)
存储目录:/home/
edits_inprogress_0000000000000000408
例如edits_0000000000000000396-0000000000000000407 和 fsimage_0000000000000000409
发现两个数字对不上,镜像比在跑的节点大
发现是查看的时候正好SNN中的备份了一次,
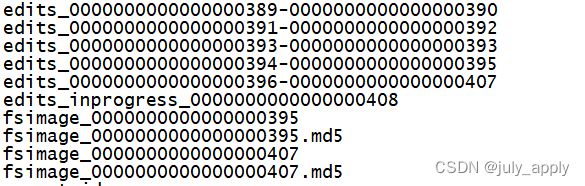
备份之前的NN

已经更新了的SNN

再查看现在的NN
现在应该是
edits_inprogress_0000000000000000410正在跑的
edits_0000000000000000408-0000000000000000409 和 fsimage_0000000000000000407
通过检查点(checkpoint)合并 fsimage_0000000000000000409 推给NN
edits_inprogress_0000000000000000410 正在记录的
写满或者一定时间会放入 edits_0000000000000000408-0000000000000000409
再新建edits_inprogress
循环往复
就是SNN中的编辑日志过一段时间会和上次的镜像merge到一起,然后回推给NNshi'wu
一些设置的参数
| dfs.namenode.checkpoint.period |
checkpoint间隔的时间,默认3600s,一小时
| dfs.namenode.checkpoint.txns |
checkpoint文件的最大事务数,默认1000000
SNN是早期为了解决NN是单点的,可能会发生单点故障,增加一个SNN,一个小时做一次checkpoint,但是现在生产上不用了
比如:
21:00 checkpoint NN和SNN是一样的
21:49 突然NN挂了,且无法恢复
即使拿SNN上的fsimage,也只能恢复到21:00
现在使用的是HA (Highly Available, 高可靠)
通过配置另一个实时的备份NN节点,随时等待active的NN挂掉,然后成为NN
active NN,backup NN
往两个NN写,但是只读一个NN
三、DataNode(DD,数据节点)
1.存储数据块 和 数据块的元文件
主要文件:
块:一个块默认最大值128M
块的元数据
2.每隔一段时间会发送blockreport(块报告)给到NN
一些设置的参数
dfs.blockreport.intervalMsec
默认 21600000 毫秒
在给NN发送blockreport(块报告)检查自己
dfs.datanode.directoryscan.interval
默认 21600 秒
这两个参数的时间间隔要设置为一样的,默认均为6H
HDFS的优缺点
优点:
1.处理海量数据
2.适合批处理
移动计算而不是移动数据
会把数据位置暴露给计算框架
3.高容错
数据自动保存N个副本,增加副本数,提高容错
某一个副本丢失,HDFS内部机制可以自动恢复
4.可以构建在廉价机器上
缺点:
1.小文件问题,需要工程师去合并小文件
2.不适合毫秒级(实时)