- ETL可视化工具 DataX -- 简介( 一)
dazhong2012
软件工具数据仓库dataxETL
引言DataX系列文章:ETL可视化工具DataX–安装部署(二)ETL可视化工具DataX–DataX-Web安装(三)1.1DataX1.1.1DataX概览DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、
- Hive简介
文章目录Hive简介Hive特点Hive和RDBMS的对比Hive的架构Hive的数据组织Hive数据类型Hive简介1、Hive由Facebook实现并开源2、是基于Hadoop的一个数据仓库工具3、可以将结构化的数据映射为一张数据库表4、并提供HQL(HiveSQL)查询功能5、底层数据是存储在HDFS上6、Hive的本质是将SQL语句转换为MapReduce任务运行7、使不熟悉MapRedu
- ftp文件服务器有连接数限制,查看ftp服务器连接数命令
赵承铭
ftp文件服务器有连接数限制
查看ftp服务器连接数命令内容精选换一换本章节适用于MRS3.x之前版本。Loader支持以下多种连接,每种连接的配置介绍可根据本章节内容了解。obs-connectorgeneric-jdbc-connectorftp-connector或sftp-connectorhbase-connector、hdfs-connector或hive-connectorOBS连接是Loa“数据导入”章节适用于
- ClickHouse高频面试题
野老杂谈
数据库
ClickHouse高频面试题1、简单介绍一下ClickHouse2、ClickHouse具有哪些特点3、ClickHouse作为一款高性能OLAP数据库,存在哪些不足4、ClickHouse有哪些表引擎5、介绍下Log系列表引擎应用场景共性特点不支持6、简单介绍下MergeTree系列引擎7、简单介绍下外部集成表引擎ODBCJDBCMySQLHDFSKafkaRabbitMQ8、ClickHou
- HDFS 伪分布模式搭建与使用全攻略(适合初学者 & 开发测试环境)
huihui450
hdfshadoop大数据
HDFS(HadoopDistributedFileSystem)作为Hadoop生态系统的核心组件,广泛应用于海量数据的分布式存储场景。对于开发者而言,伪分布模式提供了一种低成本、高还原度的学习与测试方式。本文将详细介绍如何在本地搭建并使用HDFS的伪分布模式,包括环境准备、配置过程、常用命令及常见问题排查,帮助你快速入门Hadoop分布式文件系统的实践操作。一、什么是伪分布模式?Hadoop有
- MapReduce学习笔记
1.MapReduce做什么Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。Reducer负责对map阶段的结果进行汇总。2.MapReduce工作机制实体一:客户端,用来提交MapReduce作业。实体二:JobTracker,用来协调作业的运行。实体三:TaskTracker,用来处理作业划分后的任务。实体四:HDFS,用来在其它实体间共享作业文件。3.编写MapRed
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- 数据仓库技术及应用(Hive 产生背景与架构设计,存储模型与数据类型)
娟恋无暇
数据仓库笔记hive
1.Hive产生背景传统Hadoop架构存在的一些问题:MapReduce编程必须掌握Java,门槛较高传统数据库开发、DBA、运维人员学习门槛高HDFS上没有Schema的概念,仅仅是一个纯文本文件Hive的产生:为了让用户从一个现有数据基础架构转移到Hadoop上现有数据基础架构大多基于关系型数据库和SQL查询Facebook诞生了Hive2.Hive是什么官网:https://hive.ap
- 大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop核心理论与应用场景1.1设计思想与技术定位Sqoop是Apache旗下的开源数据传输工具,核心设计基于MapReduce分布式计算框架,通过并行化的Map任务实现高效的数据批量迁移。其特点包括:批处理特性:基于MapReduce作业实现导入/导出,适合大规模离线数据迁移,不支持实时数据同步。异构数据源连接:支持关系型数据库(如MySQL、Oracle)与Hadoop生态(HDFS、H
- Hadoop之HDFS
只年
大数据HadoopHDFShadoophdfs大数据
Hadoop之HDFSHDFS的Shell操作启动Hadoop集群(方便后续测试)[atguigu@hadoop102~]$sbin/start-dfs.sh[atguigu@hadoop102~]$sbin/start-yarn.sh-help:输出这个命令参数[atguigu@hadoop102~]$hadoopfs-helprm-ls:显示目录信息[atguigu@hadoop102~]$h
- HDFS中fsimage和edits究竟是什么
清平乐的技术博客
大数据运维hdfshadoop大数据
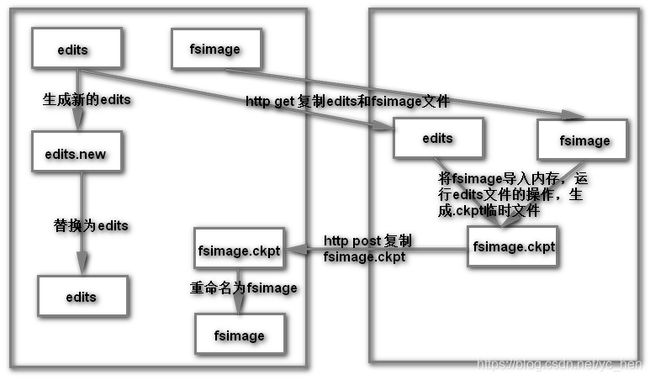
fsimage和edits是HadoopHDFS(Hadoop分布式文件系统)中的两个关键组件,用于存储文件系统的元数据,以确保文件系统的持久性和一致性。在理解它们的作用之前,我们先了解一下HDFS的基本工作原理。HDFS采用了一种分布式文件系统的架构,其中数据被划分成块并分布在不同的数据节点上,而元数据(文件和目录的信息)则由单独的组件进行管理。元数据的持久性和一致性非常重要,因为文件系统的正确
- 【Hadoop】Hadoop车辆数据存储
db_hjx_2066
javahadoop
Hadoop车辆数据存储本作业旨在实现将车辆数据按天存储到Hadoop分布式文件系统(HDFS)中,并根据数据文件大小分割成多个文件进行存储。数据格式为JSON。作业要求车辆数据按天存储,每天的数据存储在一个文件夹下。数据文件以JSON格式存储。如果数据文件大于100M,则另起一个文件存储。每天的数据总量不少于300M。实现方法1.代码说明以下是用Java编写的实现代码:1.导入类//导入必要的类
- HDFS与HBase有什么关系?
lucky_syq
hdfshbasehadoop
1、HDFS文件存储系统和HBase分布式数据库HDFS是Hadoop分布式文件系统。HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。Hbase是Hadoopdatabase,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
- Hbase和关系型数据库、HDFS、Hive的区别
别这么骄傲
hivehbase数据库
目录1.Hbase和关系型数据库的区别2.Hbase和HDFS的区别3.Hbase和Hive的区别1.Hbase和关系型数据库的区别关系型数据库Hbase存储适合结构化数据,单机存储适合结构化和半结构数据的松散数据,分布式存储功能(1)支持ACID(2)支持join(3)使用主键PK(4)数据类型:int、varchar等(1)仅支持单行事务(2)不支持join,把数据糅合到一张大表(3)行键ro
- 大数据基础知识-Hadoop、HBase、Hive一篇搞定
原来是猪猪呀
hadoop大数据分布式
HadoopHadoop是一个由Apache基金会所开发的分布式系统基础架构,其核心设计包括分布式文件系统(HDFS)和MapReduce编程模型;Hadoop是一个开源的分布式计算框架,旨在帮助用户在不了解分布式底层细节的情况下,开发分布式程序。它通过利用集群的力量,提供高速运算和存储能力,特别适合处理超大数据集的应用程序。Hadoop生态圈Hadoop生态圈是一个由多个基于Hadoop开发的相
- Hadoop、HDFS、Hive、Hbase区别及联系
静心观复
大数据hadoophdfshive
Hadoop、HDFS、Hive和HBase是大数据生态系统中的关键组件,它们都是由Apache软件基金会管理的开源项目。下面将深入解析它们之间的区别和联系。HadoopHadoop是一个开源的分布式计算框架,它允许用户在普通硬件上构建可靠、可伸缩的分布式系统。Hadoop通常指的是整个生态系统,包括HadoopCommon(共享库和工具)、HadoopDistributedFileSystem(
- 大数据(1)-hdfs&hbase
viperrrrrrr
大数据hdfshbase
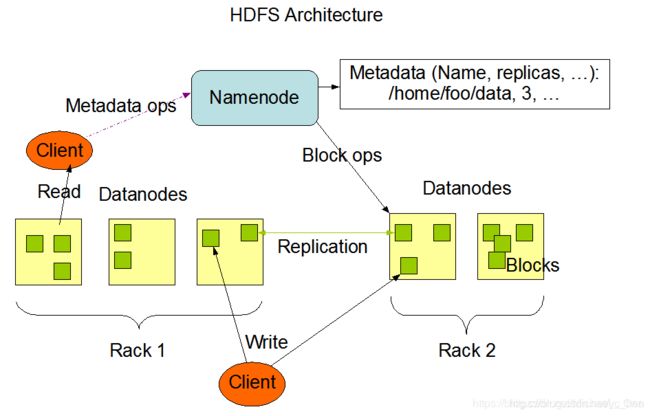
hbase&hdfs一、体系结构HDFS是一个标准的主从(Master/Slave)体系结构的分布式系统;HDFS集群包含一个或多个NameNode(NameNodeHA会有多个NameNode)和多个DataNode(根据节点情况规划),用户可以通过HDFS客户端同NameNode和DataNode进行交互以访问文件系统。HDFS公开文件系统名称空间,并允许将用户数据存储在文件中。在内部,一个文
- Hadoop入门案例
'Wu'
学习日常大数据hadoophdfs大数据
Hadoop的运行流程:客户端向HDFS请求文件存储或使用MapReduce计算。NameNode负责管理整个HDFS系统中的所有数据块和元数据信息;DataNode则实际存储和管理数据块。客户端通过NameNode查找需要访问或处理的文件所在的DataNode,并将操作请求发送到相应的DataNode上。当客户端上传一个新文件时(比如输入某些日志),它会被分成固定大小(默认64MB)并进行数据复
- Hadoop、Spark、Flink 三大大数据处理框架的能力与应用场景
一、技术能力与应用场景对比产品能力特点应用场景Hadoop-基于MapReduce的批处理框架-HDFS分布式存储-容错性强、适合离线分析-作业调度使用YARN-日志离线分析-数据仓库存储-T+1报表分析-海量数据处理Spark-基于内存计算,速度快-支持批处理、流处理(StructuredStreaming)-支持SQL、ML、图计算等-支持多语言(Scala、Java、Python)-近实时处
- 使用datax进行mysql的表恢复
是桃萌萌鸭~
mysql数据库
DataXDataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括MySQL、SQLServer、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS等各种异构数据源之间高效的数据同步功能。FeaturesDataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上Dat
- 【头歌】MapReduce基础实战 答案
Seven_Two2
头歌大数据实验答案c#开发语言
本专栏已收集大数据所有答案第1关:成绩统计编程要求使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。答案:需要先在命令行启动HDFS#命令行start-dfs.sh再在代码文件中写入以下代码#代码文件importjava.io.IOException;importjava.util.S
- HDFS(Hadoop分布式文件系统)总结
Cachel wood
大数据开发hadoophdfs大数据散列表算法哈希算法spark
文章目录一、HDFS概述1.定义与定位2.核心特点二、HDFS架构核心组件1.NameNode(名称节点)2.DataNode(数据节点)3.Client(客户端)4.SecondaryNameNode(辅助名称节点)三、数据存储机制1.数据块(Block)设计2.复制策略(默认复制因子=3)3.数据完整性校验四、文件读写流程1.写入流程2.读取流程五、高可用性(HA)机制1.单点故障解决方案2.
- Hadoop的部分用法
覃炳文20230322027
hadoophive大数据分布式
前言Hadoop是一个由Apache基金会开发的开源框架,它允许跨多个机器使用分布式处理大数据集。Hadoop的核心是HDFS(HadoopDistributedFileSystem)和MapReduce编程模型。1.Hadoop环境搭建在开始使用Hadoop之前,你需要搭建Hadoop环境。这通常包括安装Java、配置Hadoop环境变量、配置Hadoop的配置文件等步骤。1.1环境准备在开始安
- Hadoop 版本进化论:从 1.0 到 2.0,架构革命全解析
拾光师
大数据后端
Hadoop版本hadoop1.x版本由三部分组成Common(辅助工具)HDFS(数据存储)MapReduce(计算和资源调度)存在的问题JobTracker同时具备了资源管理和作业控制两个功能,成为了系统的最大瓶颈采用了master/slave结构,master存在单点问题,一旦master出现故障,会导致整个集群不可用采用了基于槽位的资源分配模型,将槽位分为了Mapslot和Reducesl
- 合并小文件汇总(Hive/Spark)
有数的编程笔记
Spark/Hivehivesparkhadoop
合并小文件的原因:过多的小文件会导致HDFS上元数据负载增加。并且小文件也会导致计算性能下降。1.使用hive时1.1.使用hive.merge参数,开启文件合并--控制在map阶段结束后合并输出的小文件,默认值为trueSEThive.merge.mapfiles=true;--控制在reduce阶段结束后合并输出小文件,默认值为falseSEThive.merge.mapredfiles=tr
- 基于pyspark的北京历史天气数据分析及可视化_离线
大数据CLUB
spark数据分析可视化数据分析数据挖掘hadoop大数据spark
基于pyspark的北京历史天气数据分析及可视化项目概况[]点这里,查看所有项目[]数据类型北京历史天气数据开发环境centos7软件版本python3.8.18、hadoop3.2.0、spark3.1.2、mysql5.7.38、scala2.12.18、jdk8开发语言python开发流程数据上传(hdfs)->数据分析(spark)->数据存储(mysql)->后端(flask)->前端(
- 探秘Flink Connector加载机制:连接外部世界的幕后引擎
Edingbrugh.南空
flink大数据flink大数据
在Flink的数据处理生态中,SourceFunction负责数据的输入源头,而真正架起Flink与各类外部存储、消息系统桥梁的,则是Connector。从Kafka消息队列到HDFS文件系统,从MySQL数据库到Elasticsearch搜索引擎,Flink通过Connector实现了与多样化外部系统的交互。而这一切交互的基础,都离不开背后强大且精巧的Connector加载机制。接下来,我们将深
- 基于pyspark的北京历史天气数据分析及可视化_实时
大数据CLUB
spark数据分析可视化数据分析数据挖掘sparkhadoop大数据
基于pyspark的北京历史天气数据分析及可视化项目概况[]点这里,查看所有项目[]数据类型北京历史天气数据开发环境centos7软件版本python3.8.18、hadoop3.2.0、spark3.1.2、mysql5.7.38、scala2.12.18、jdk8、kafka2.8.2开发语言python开发流程数据上传(hdfs)->数据分析(spark)->数据写kafka(python)
- 时序数据库IoTDB的架构、安装启动方法与数据模式总结
时序数据说
时序数据库iotdb数据库大数据物联网
一、IoTDB的架构IoTDB的架构主要分为三个部分:时序文件(Tsfile):专为时序数据设计的文件存储格式。支持高效的压缩和查询性能。可独立使用,并可通过TsFileSync工具同步至HDFS进行大数据处理。数据库引擎:负责数据的收集、写入、存储和查询等核心功能。分析引擎:可选的分析组件,用于数据处理和分析。二、IoTDB的安装启动方法1.使用环境:需要具备JDK>=1.8的运
- Hadoop等大数据处理框架的Java API
扬子鳄008
Javahadoopjava大数据
Hadoop是一个非常流行的大数据处理框架,主要用于存储和处理大规模数据集。Hadoop主要有两个核心组件:HDFS(HadoopDistributedFileSystem)和MapReduce。此外,还有许多其他组件,如YARN(YetAnotherResourceNegotiator)、HBase、Hive等。下面详细介绍Hadoop及其相关组件的JavaAPI及其使用方法。HadoopHad
- 如何用ruby来写hadoop的mapreduce并生成jar包
wudixiaotie
mapreduce
ruby来写hadoop的mapreduce,我用的方法是rubydoop。怎么配置环境呢:
1.安装rvm:
不说了 网上有
2.安装ruby:
由于我以前是做ruby的,所以习惯性的先安装了ruby,起码调试起来比jruby快多了。
3.安装jruby:
rvm install jruby然后等待安
- java编程思想 -- 访问控制权限
百合不是茶
java访问控制权限单例模式
访问权限是java中一个比较中要的知识点,它规定者什么方法可以访问,什么不可以访问
一:包访问权限;
自定义包:
package com.wj.control;
//包
public class Demo {
//定义一个无参的方法
public void DemoPackage(){
System.out.println("调用
- [生物与医学]请审慎食用小龙虾
comsci
生物
现在的餐馆里面出售的小龙虾,有一些是在野外捕捉的,这些小龙虾身体里面可能带有某些病毒和细菌,人食用以后可能会导致一些疾病,严重的甚至会死亡.....
所以,参加聚餐的时候,最好不要点小龙虾...就吃养殖的猪肉,牛肉,羊肉和鱼,等动物蛋白质
- org.apache.jasper.JasperException: Unable to compile class for JSP:
商人shang
maven2.2jdk1.8
环境: jdk1.8 maven tomcat7-maven-plugin 2.0
原因: tomcat7-maven-plugin 2.0 不知吃 jdk 1.8,换成 tomcat7-maven-plugin 2.2就行,即
<plugin>
- 你的垃圾你处理掉了吗?GC
oloz
GC
前序:本人菜鸟,此文研究学习来自网络,各位牛牛多指教
1.垃圾收集算法的核心思想
Java语言建立了垃圾收集机制,用以跟踪正在使用的对象和发现并回收不再使用(引用)的对象。该机制可以有效防范动态内存分配中可能发生的两个危险:因内存垃圾过多而引发的内存耗尽,以及不恰当的内存释放所造成的内存非法引用。
垃圾收集算法的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别
- shiro 和 SESSSION
杨白白
shiro
shiro 在web项目里默认使用的是web容器提供的session,也就是说shiro使用的session是web容器产生的,并不是自己产生的,在用于非web环境时可用其他来源代替。在web工程启动的时候它就和容器绑定在了一起,这是通过web.xml里面的shiroFilter实现的。通过session.getSession()方法会在浏览器cokkice产生JESSIONID,当关闭浏览器,此
- 移动互联网终端 淘宝客如何实现盈利
小桔子
移動客戶端淘客淘寶App
2012年淘宝联盟平台为站长和淘宝客带来的分成收入突破30亿元,同比增长100%。而来自移动端的分成达1亿元,其中美丽说、蘑菇街、果库、口袋购物等App运营商分成近5000万元。 可以看出,虽然目前阶段PC端对于淘客而言仍旧是盈利的大头,但移动端已经呈现出爆发之势。而且这个势头将随着智能终端(手机,平板)的加速普及而更加迅猛
- wordpress小工具制作
aichenglong
wordpress小工具
wordpress 使用侧边栏的小工具,很方便调整页面结构
小工具的制作过程
1 在自己的主题文件中新建一个文件夹(如widget),在文件夹中创建一个php(AWP_posts-category.php)
小工具是一个类,想侧边栏一样,还得使用代码注册,他才可以再后台使用,基本的代码一层不变
<?php
class AWP_Post_Category extends WP_Wi
- JS微信分享
AILIKES
js
// 所有功能必须包含在 WeixinApi.ready 中进行
WeixinApi.ready(function(Api) {
// 微信分享的数据
var wxData = {
&nb
- 封装探讨
百合不是茶
JAVA面向对象 封装
//封装 属性 方法 将某些东西包装在一起,通过创建对象或使用静态的方法来调用,称为封装;封装其实就是有选择性地公开或隐藏某些信息,它解决了数据的安全性问题,增加代码的可读性和可维护性
在 Aname类中申明三个属性,将其封装在一个类中:通过对象来调用
例如 1:
//属性 将其设为私有
姓名 name 可以公开
- jquery radio/checkbox change事件不能触发的问题
bijian1013
JavaScriptjquery
我想让radio来控制当前我选择的是机动车还是特种车,如下所示:
<html>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js" type="text/javascript"><
- AngularJS中安全性措施
bijian1013
JavaScriptAngularJS安全性XSRFJSON漏洞
在使用web应用中,安全性是应该首要考虑的一个问题。AngularJS提供了一些辅助机制,用来防护来自两个常见攻击方向的网络攻击。
一.JSON漏洞
当使用一个GET请求获取JSON数组信息的时候(尤其是当这一信息非常敏感,
- [Maven学习笔记九]Maven发布web项目
bit1129
maven
基于Maven的web项目的标准项目结构
user-project
user-core
user-service
user-web
src
- 【Hive七】Hive用户自定义聚合函数(UDAF)
bit1129
hive
用户自定义聚合函数,用户提供的多个入参通过聚合计算(求和、求最大值、求最小值)得到一个聚合计算结果的函数。
问题:UDF也可以提供输入多个参数然后输出一个结果的运算,比如加法运算add(3,5),add这个UDF需要实现UDF的evaluate方法,那么UDF和UDAF的实质分别究竟是什么?
Double evaluate(Double a, Double b)
- 通过 nginx-lua 给 Nginx 增加 OAuth 支持
ronin47
前言:我们使用Nginx的Lua中间件建立了OAuth2认证和授权层。如果你也有此打算,阅读下面的文档,实现自动化并获得收益。SeatGeek 在过去几年中取得了发展,我们已经积累了不少针对各种任务的不同管理接口。我们通常为新的展示需求创建新模块,比如我们自己的博客、图表等。我们还定期开发内部工具来处理诸如部署、可视化操作及事件处理等事务。在处理这些事务中,我们使用了几个不同的接口来认证:
&n
- 利用tomcat-redis-session-manager做session同步时自定义类对象属性保存不上的解决方法
bsr1983
session
在利用tomcat-redis-session-manager做session同步时,遇到了在session保存一个自定义对象时,修改该对象中的某个属性,session未进行序列化,属性没有被存储到redis中。 在 tomcat-redis-session-manager的github上有如下说明: Session Change Tracking
As noted in the &qu
- 《代码大全》表驱动法-Table Driven Approach-1
bylijinnan
java算法
关于Table Driven Approach的一篇非常好的文章:
http://www.codeproject.com/Articles/42732/Table-driven-Approach
package com.ljn.base;
import java.util.Random;
public class TableDriven {
public
- Sybase封锁原理
chicony
Sybase
昨天在操作Sybase IQ12.7时意外操作造成了数据库表锁定,不能删除被锁定表数据也不能往其中写入数据。由于着急往该表抽入数据,因此立马着手解决该表的解锁问题。 无奈此前没有接触过Sybase IQ12.7这套数据库产品,加之当时已属于下班时间无法求助于支持人员支持,因此只有借助搜索引擎强大的
- java异常处理机制
CrazyMizzz
java
java异常关键字有以下几个,分别为 try catch final throw throws
他们的定义分别为
try: Opening exception-handling statement.
catch: Captures the exception.
finally: Runs its code before terminating
- hive 数据插入DML语法汇总
daizj
hiveDML数据插入
Hive的数据插入DML语法汇总1、Loading files into tables语法:1) LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]解释:1)、上面命令执行环境为hive客户端环境下: hive>l
- 工厂设计模式
dcj3sjt126com
设计模式
使用设计模式是促进最佳实践和良好设计的好办法。设计模式可以提供针对常见的编程问题的灵活的解决方案。 工厂模式
工厂模式(Factory)允许你在代码执行时实例化对象。它之所以被称为工厂模式是因为它负责“生产”对象。工厂方法的参数是你要生成的对象对应的类名称。
Example #1 调用工厂方法(带参数)
<?phpclass Example{
- mysql字符串查找函数
dcj3sjt126com
mysql
FIND_IN_SET(str,strlist)
假如字符串str 在由N 子链组成的字符串列表strlist 中,则返回值的范围在1到 N 之间。一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串。如果第一个参数是一个常数字符串,而第二个是type SET列,则 FIND_IN_SET() 函数被优化,使用比特计算。如果str不在strlist 或st
- jvm内存管理
easterfly
jvm
一、JVM堆内存的划分
分为年轻代和年老代。年轻代又分为三部分:一个eden,两个survivor。
工作过程是这样的:e区空间满了后,执行minor gc,存活下来的对象放入s0, 对s0仍会进行minor gc,存活下来的的对象放入s1中,对s1同样执行minor gc,依旧存活的对象就放入年老代中;
年老代满了之后会执行major gc,这个是stop the word模式,执行
- CentOS-6.3安装配置JDK-8
gengzg
centos
JAVA_HOME=/usr/java/jdk1.8.0_45
JRE_HOME=/usr/java/jdk1.8.0_45/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME
- 【转】关于web路径的获取方法
huangyc1210
Web路径
假定你的web application 名称为news,你在浏览器中输入请求路径: http://localhost:8080/news/main/list.jsp 则执行下面向行代码后打印出如下结果: 1、 System.out.println(request.getContextPath()); //可返回站点的根路径。也就是项
- php里获取第一个中文首字母并排序
远去的渡口
数据结构PHP
很久没来更新博客了,还是觉得工作需要多总结的好。今天来更新一个自己认为比较有成就的问题吧。 最近在做储值结算,需求里结算首页需要按门店的首字母A-Z排序。我的数据结构原本是这样的:
Array
(
[0] => Array
(
[sid] => 2885842
[recetcstoredpay] =&g
- java内部类
hm4123660
java内部类匿名内部类成员内部类方法内部类
在Java中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号。内部类可以间接解决多继承问题,可以使用内部类继承一个类,外部类继承一个类,实现多继承。
&nb
- Caused by: java.lang.IncompatibleClassChangeError: class org.hibernate.cfg.Exten
zhb8015
maven pom.xml关于hibernate的配置和异常信息如下,查了好多资料,问题还是没有解决。只知道是包冲突,就是不知道是哪个包....遇到这个问题的分享下是怎么解决的。。
maven pom:
<dependency>
<groupId>org.hibernate</groupId>
<ar
- Spark 性能相关参数配置详解-任务调度篇
Stark_Summer
sparkcachecpu任务调度yarn
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 本文试图通过阐述这其中部分参数的工作原理和配置思路, 和大家一起探讨一下如何根据实际场合对Spark进行配置优化。
由于篇幅较长,所以在这里分篇组织,如果要看最新完整的网页版内容,可以戳这里:http://spark-config.readthedocs.org/,主要是便
- css3滤镜
wangkeheng
htmlcss
经常看到一些网站的底部有一些灰色的图标,鼠标移入的时候会变亮,开始以为是js操作src或者bg呢,搜索了一下,发现了一个更好的方法:通过css3的滤镜方法。
html代码:
<a href='' class='icon'><img src='utv.jpg' /></a>
css代码:
.icon{-webkit-filter: graysc