C++初阶---string类的模拟实现
string类的模拟实现
- 1)浅拷贝
- 2)深拷贝
- 3)string类的模拟实现
-
-
- 1. 构造,拷贝构造,赋值操作符重载,析构
- 2. iterator迭代器
- 3. 涉及到容量的操作
-
-
- ① reserve
- ② reszie
-
- 4. 访问
-
-
- ① insert和insert的重载
- ② erase
- ③find及其重载
- ④push_back append += []
-
- 5.relational operator
-
-
- 6. << >>重载和getline c_str
-
-
- 4)写时拷贝
- 5)VS下string的一种实现方案
- 6)更多大佬的文章:
1)浅拷贝
看如下代码(构造):class string { public: string(char* str) :_str(str) {} char& operator[](size_t pos) { return _str[pos]; } private: char* _str; }; int main() { string s("sdada"); s[2]='A'; return 0; }报错 常量字符串不可修改,参见:const,static总结
看如下代码(拷贝构造):class string { public: string(char* str) :_str(new char[strlen(str)]) { strcpy(_str,str); } char& operator[](size_t pos) { return _str[pos]; } ~string() { delete[] _str; _str=nullptr; } private: char* _str; }; int main() { string s1("diasdiua"); string s2(s1); return 0; }调用拷贝构造后出错,在没有拷贝构造函数的时候,会进行浅拷贝,当析构的时候会delete[]两次,
出错
浅拷贝: 也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以 当继续对资源进行操作时,就会发生发生了访问违规。要解决浅拷贝问题,C++中引入了深拷贝
2)深拷贝
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供
string类模拟实现会详细讨论
3)string类的模拟实现
string定义在我们自己的test1命名空间里
类有四个默认成员变量分别是:private: //注意这里先后顺序 初始化列表初始化时按照这个顺序进行 char* _str;//字符串 size_t _size;//大小 size_t _capacity;//容量 static const size_t npos; }; const size_t string::npos = -1;
1. 构造,拷贝构造,赋值操作符重载,析构
//默认构造“” string(const char* str = "") : _size(strlen(str)) ,_capacity(strlen(str)) { cout << _size << endl; cout << _capacity << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } //利用全局swap库函数自定义swap函数 void swap(string& s) { ::swap(_str,s._str); ::swap(_size,s._size); ::swap(_capacity,s._capacity); } //拷贝构造 string(const string& s) :_str(nullptr) { string tmp(s._str); this->swap(tmp); } //赋值操作 string& operator=(string s) { if (this != &s) { this->swap(s); } return *this; } //析构函数 ~string() { delete[] _str; _size = 0; _capacity = 0; _str = nullptr; }以上写的是现代常用方法
分析解释:
构造函数:
- 给了一个缺省值“”空字符串用来存储’\0’
- 以下缺省给法错误:
//string(const char* str = "\0")错误示范
//string(const char* str = nullptr)错误示范- 初始化列表初始化是按照私有成员变量声明的顺序进行初始化的,初始化列表要按照私有成员变量声明的顺序写(
写的时候踩过这坑)
拷贝构造:
- 对于string s1(s)的写法我们参数传的是引用,进行深拷贝,我们先用s的_str构造深拷贝一个tmp string类,再让_str和tmp._str交换
赋值操作:
- 传值是进行深拷贝,接收参数的时候就
拷贝构造了一个string s对象,再用自定义的swap函数对成员三个成员变量进行交换
2. iterator迭代器
// iterator begin/end typedef char* iterator; const typedef char* const_iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } // iterator cbegin/cend iterator cbegin()const { return _str; } iterator cend()const { return _str + _size; }分为普通迭代器和const迭代器
分析省略
注意:
- 在使用自己实现的迭代器要
保持begin end函数名和库里一致,因为底层iterator实现是按照特定函数命来实现的范围for循环,其实本质就是将其替换为迭代器


3. 涉及到容量的操作
① reserve
void reserve(size_t n) { if (n > _capacity) { char* tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } }分析:
char* tmp = new char[n + 1];写在delete[]前面是防止new失败后程序终止不会释放原空间
② reszie
void resize(size_t n, char c = '\0') { if (n < _size) { _size = n; } else { if (_capacity < n) { reserve(n); } int i = _size; while (i < n - 1) { _str[i--] = c; } _size = n; } _str[_size] = '\0'; }分析:(两种情况)
- 传入的n小于原来的_size,直接把_size赋为n再把’\0’加在末尾
- n大于_size 在后面多的部分填充字符c,c给了缺省值为‘\0’(
注意:n>_capacity时要扩容)
4. 访问
① insert和insert的重载
string& insert(size_t pos, char c) { assert(pos <= _size + 1); //这里实现的是用户输入3,实际在下标2处修改 //针对push_back的复用_size+1 if (_size + 1 > _capacity) { reserve(_size + 1); } _size++; int end = _size; while (end>=pos) //注意end是int和无符号size_t比较时要进行 //整形提升当减到-1时会当成一个很大的正数 { _str[end] = _str[end - 1]; end--; } _str[pos - 1] = c; return *this; } string& insert(size_t pos, const char* str) //这里实现的是用户输入3,实际在下标2处修改 { //针对append的复用_size+1 assert(pos <= _size+1); int len = strlen(str); if (_size + len > _capacity) { reserve(_size + len); } int end = _size + len;//注意这里不要-1 '\0'也要移 while (end >= pos + len)//后移 { _str[end] = _str[end - len]; end--; } for (int i = 0; i < len; i++)//写入 { _str[pos + i - 1] = str[i]; } _size += len; return *this; }分析:
- 插入一个字符
库里的insert有防止pos超过_size的机制,要加上assert断言 (思路读代码)
注意: 在while循环后移时要防止int型的end减到-1,因为和无符号数比较整形提升时会当成一个很大的正数- 插入一个字符串
思路读代码
② erase
string& erase(size_t pos, size_t len = npos) { assert(pos < _size); // 1、pos后面删完 // 2、pos后面删除一部分 if (len == npos || pos + len >= _size) { _str[pos] = '\0'; _size = pos; } else { strcpy(_str + pos, _str + pos + len); _size -= len; } return *this; }分析:
- 传入了参数len,且pos+len>=_size,全删除,没有传参数,全删除
- 其他情况按照传入的len来
③find及其重载
在这里插入代码片
这里是引用
④push_back append += []
void push_back(char ch) { insert(_size, ch); } void append(const char* str) { insert(_size, str); } string& operator+=(char ch) { //this->push_back(ch); push_back(ch); return *this; } string& operator+=(const char* str) { append(str); return *this; } string& operator+=(const string& s) { *this += s._str; return *this; } char& operator[](size_t index)//写 { return _str[index]; } const char& operator[](size_t index)const//读 { return _str[index]; }都是进行一些已实现的函数复用
5.relational operator
bool operator<(const string& s1, const string& s2)
{
int i1 = 0, i2 = 0;
while (i1 < s1.size() && i2 < s2.size())
{
if (s1[i1] > s2[i2])
{
return false;
}
else if (s1[i1] > s2[i2])
{
return true;
}
i1++;
++i2;
}
if (i1 == s1.size())//注意条件控制不是(i1
{
return true;
}
else
{
return false;
}
}
bool operator==(const string& s1, const string& s2)
{
int i1 = 0, i2 = 0;
while (i1 < s1.size() && i2 < s2.size())
{
if ((s1[i1] > s2[i2]) || (s1[i1] > s2[i2]))
{
return false;
}
}
if (i1 < s1.size() || i2 < s2.size())
{
return false;
}
return true;
}
inline bool operator<=(const string& s1, const string& s2)//复用大于和等于
{
return (s1 < s2) || (s1 == s2);
}
inline bool operator>(const string& s1, const string& s2)//复用
{
return !(s1 <= s2);
}
inline bool operator>=(const string& s1, const string& s2)//复用
{
return (s1 > s2) || (s1 == s2);
}
inline bool operator!=(const string& s1, const string& s2)//复用
{
return !(s1 == s2);
}
一些较为简单的复用,注意是按照strcmp函数的比较方式
6. << >>重载和getline c_str
注意是定义在类外面定义,由于有this指针强制占了第一个参数,在类里重载会让操作数的左右顺序对调void clear() { _str[0] = '\0'; _size = 0; } ostream& operator<<(ostream& out, const string& s) { for (int i = 0; i < s.size(); i++) { out << s[i]; } return out; } istream& operator>>(istream& in, string& s) { s.clear(); char ch; ch = in.get(); while (ch != ' '&& ch != '\n') { s += ch; ch=in.get();//是一个字符一个字符,所以要循环读取 } return in; } istream& getline(istream& in, string& s) { s.clear(); char ch; ch = in.get(); while (ch != '\n') { s += ch; ch = in.get();//是一个字符一个字符,所以要循环读取 } return in; }这里提一下>>重载要用到istream里的get函数
std::istream::get:从流中提取字符,作为未格式化的输入,这里利用的它可以接收空格的特性
string类里的>>是遇到空格和换行符就停止,getline是遇到换行符才停止
const char* c_str()const { return _str; } // 不管字符数组中的内容是啥,size是多少,就要输出多少个有效字符 cout << s2 << endl; // 不管实际字符串的长度,遇到\0就终止 cout << s2.c_str() << endl;c_str是按照c语言的标准来,打印时不管字符串的长度,遇到\0就终止
4)写时拷贝
写时拷贝是在浅拷贝的基础之上增加了引用计数的方式来实现的
引用计数:
用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源
linux旧版本使用了这种技术,由于有副作用,微软已取消这种技术
参考陈皓大佬的:
C++ STL STRING的COPY-ON-WRITE技术
5)VS下string的一种实现方案
观察下面代码输出什么
std::string s1("111111"); std::string s2("111111111111111111111111111111111111"); cout << sizeof(s1) << endl; cout << sizeof(s2) << endl; return 0;
一般的,我们知道size_t在32位系统上定义为 unsigned int,在64位系统上定义为 unsigned long所以这里的三个成员变量一共12字节(静态成员变量不算)
但在
vs下做了特殊优化,增加了一个_buf数组类似于变成下面这样private: //char _buf[16]; char* _str;//字符串 size_t _size;//大小 size_t _capacity;//容量 static const size_t npos;当传入字符串长度小于16个字节会直接存在_buf数组里
当传入字符串长度大于16个字节他会存在堆上,用_Ptr指针指向它
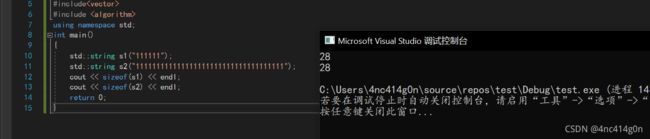

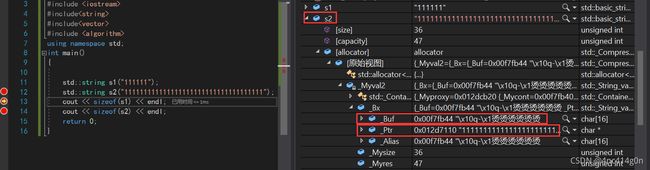
然而 在Linux下,gcc version 8.4.1执行的结果是 32
6)更多大佬的文章:
STL 的string类怎么啦?
C++面试中STRING类的一种正确写法