浅析分布式系统之体系结构 - 事务与隔离级别(多对象、多操作)上篇
事务的本质
数千年前两河流域的楔形文字书写关于贸易、法律、账户等内容的大量文献中就已经提到事务。为了保证整个交易过程中的信息处理(例如:某笔交易)的完整、正确以及可追述,人们需要将各种信息完整正确的记录下来作为凭证,由此苏美尔人的交易方式包括两个组成部分:
数据记录集:保存整个系统的真实状态的抽象记录的集合,表示为粘土片上的标记。
事务:抄写员在数据记录集中增加新的记录(粘土片)来记录状态变化。今天,我们将每一次处理这些状态更改的过程称为事务。
描述:
将系统的真实状态的每一次变化映射为一个对于数据记录集中的记录的进行改变的程序执行过程,当这个过程是一个无法分割的处理过程,并且由一个或多个状态更改相关的多个操作的组合而成,则将其称为事务。
图1
事务描述相关概念
事务描述模型:
事务处理的对象是抽象记录的集合,这些抽象记录的集合由一个个数据对象组成。抽象记录的集合的由于规模以及需要满足的需求等不同而有各种分类例如:数据库,数据仓库,数据湖等等。数据库是其中最常见最典型的抽象记录的集合也是人们最常使用的数据存储处理系统,人们通过事务读取或写入的数据库种的多个对象进行相应的数据处理。在经典的关系型数据库系统中,每个行、表等是一个对象,每个事务读取和写入这些对象并明确这些操作发生的全序( total order)。在NoSQL数据库中,尽管使用与关系型数据库不同技术体系,当这些系统需要保证数据信息的完整、正确以及可追述时,这些新型的数据库仍旧需要满足相应的事务相关的要求。
1)事务的操作种类
事务的操作抽象为读(read)、写(write)(插入以及删除等更新操作都简化为写操作) 、提交(commit)或取消((abort)等同于回滚(rollback ))。事务的最后一次操作分为提交(commit)或取消(abort),表示它的执行是否成功;每个事务最多有一个 commit 或 abort 操作。
读(read):从记录数据集合得到需要的信息
写(write):将插入以及删除等更新操作都简化为写操作,表示改变数据集的状态
提交(commit):提交commit状态反应了事务修改已经提交成功。
取消(abort or rollback):为了保证数据记录集记录的状态变化时的完整性与正确性,可以通过在执行修改记录的过程时增加中间状态的记录来实现。当出现无法提交事务情况时,使用这些记录将数据记录集合恢复到之前的一致、已知状态。例如,在数据库系统中,在某个事务进行任何修改之前,系统会将数据库当前上的信息进行复制并创建副本(这有时称为前映像)。如果这个事务执行时任何步骤在最后的提交之前失败,则这些副本用于将数据库恢复到事务开始之前的状态。
2)数据对象与记录对象版本
数据对象可以是一个元组(关系数据库)或一个数据对象(非关系数据库)。数据对象有多个数据项item组成。(数据项可以是列column或对象的属性(attirbute))理论上数据记录集会有一个最初的抽象事务,给所有数据记录对象一个不可见的虚拟的初始版本(例如:xi.init), 当这个初始事务后续的事务执行时,当某一个数据记录被第一次写入后(例如,插入行,写入数据对象),则数据对象的虚拟的初始版本x.init就给改变成xi.1。假设事务Ti多次修改了一个对象;它对对象 x 的第一次修改可以表示为xi.1,第二次是 xi.2,依此类推(xi为事务Ti在commit 或 abort之前最后一次修改的版本,如果事务Ti最终选择abort操作,那么 xi 不会被视作 committed 的一部分),当这个 对象 被删除的时候,被标记成最终版本 (例如:x.dead),而这个对象被删除后又被插入了,那么视为两个不同的对象。不同颗粒度的对象都有一个以上的版本,不同的版本可能由不同的操作或原因造成,所以多个事务在并发执行的时候,有的事务可能会读取到由已提交、未提交甚至已经中止的事务创建的版本;所以需要,施加某些协调的约束从而阻止某些类型的读取,例如,读取由中止事务创建的版本。
3)可见性 (visibility) :可见性一般指由事务a产生的状态变化可以被事务b观察到这样的场景。两个事务之间也会相互不可见。
4)事务处理过程(Transition processing)
一个完整的信息处理的过程往往有多个无法分割的步骤组合合成的, 同样的一个完整的事务处理过程就是由多个事务组合而成的。
5)事务历史记录(Transaction History)
事务历史记录由两部分组成:事件历史记录与版本顺序记录
事件历史记录:事务处理过程的事件历史记录通过事件(Event)来记录各个事务的所有操作(读写),例如:某一个事务Ti中的一个写操作可以记录为wi (xi)或者wi(xi.m),其中xi或xi.m为某一个版本。如果需要记录写操作的值(假设为v)则可以记录为wi (xi , v),同样的如果在其他事务中例如Tj的读操作来读取这个由Ti写入的值v,可用 rj (xi, v)表示。历史记录需要保存一个事务中所有事件包含提交和撤销的顺序。这个顺序需要符合一定的操作发生前后规则,以前面的事务Ti,Tj为例
- 如果Tj的一个读操作rj到底了一个版本为m的数据对象xi,而这个版本为m的数据对象xi是由Ti事务的wi (xi.m , v)写入的,则这个读操作rj不能在写操作wi之前发生。这里读操作rj所读取的值和Ti事务的提交commit操作无关,读操作rj(xj)可以读取写操作wi(xi.m)的值v,即使Ti事务没有提交。
- 如果这个rj操作和wi之间没有任何其他的操作,则读操作rj得到值必定为wi (xi)或wi (xi.m)写入的值v。
- 事务的事件历史记录必须完整的,即记录必须包含事务的结束事件即提交commit或取消(abort)。即使事务因为各种原因而中断,也需要补上取消(abort)。这是为了应对当Tj正常提交后而Ti出现中断,而Tj的rj操作已经读取了wi操作写入的数据对象xi的值v的情况。
- 事务的事件历史记录为一个偏序(partial order)记录。
版本顺序记录:事务涉及的各个信息对象的提交(commit)以后的版本顺序记录为全序(total order)记录。由于未提交或中止的事务,没有版本排序,历史记录中由于已提交事务而导致的版本称为已提交版本(committed versions)。
这个记录包含的数据对象的版本集合包含初始xiinit以及最后的版本xdead,所有其他被其他事务可见(visibility)已经提交版本在这两者之间。对于读操作只能读取记录队的可见版本,因此对于不是由提交操作产生的版本例如xi.m,只要其为历史记录中的rj (xi)事件表示的读操作读到,则也是可见版本。
记录对象的版本的顺序可以与事件历史记录中的写入或提交操作的事件顺序不同。例如:
w1(x1) w2(x2) w2(y2) c1 c2 r3(x1) w3(x3) w4(y4) a4 【x2<这里 x2 在 x1 后写入,但是因为 commit 的 order,数据记录系统如数据库可以选择在版本全序记录中将数据对象的版本顺序调整为:数据对象x2的版本在数据对象x1的版本之前,即x2版本的顺序记录可以相反或不同,即在版本全序记录中T2按照序列应该在T1之前)。这种定义带来了足够的灵活性来允许某些优化和多版本设计的实现。
6)补偿性事务(Compensating transaction):
在某些需求当中提交和回滚机制是不允许的或在某些系统当中在提交和回滚机制不可用的,补偿事务通常用于撤消失败的事务并将系统恢复到以前的状态。
7)死锁(Deadlocks):
当多余一个事务同时对于同一个记录进行信息处理就会因为某种间接制约关系----竞争而出现死锁,从而使这些事务都无法进行下去。
8)谓词(Predicates):
一般来说各个数据对象(及其所有版本)相互之间可能会有关系。在关系型数据库中每个数据对象(及其所有版本)更是以某种关系存在。这样就可以基于这些关系使用某些谓词进行某些数据处理。谓词P(这里引入额外的记号 P)是布尔表达式。(例如,在 SQL 语句的 WHERE 子句),可以在 P 中指定一个或多个关系。在数据记录对象(含版本)集合上使用这个谓词P(即这个布尔表达式)后得到的满足这个要求的版本集合被称为Vset(P) 。这个集合只包含存在的版本记录,前面描述过的虚拟的 init 版本记录等是无法包含的,因为它只包含对应的 visible 对象。
- 基于谓词的读操作
一个事务Ti中基于这个谓词P的读操作在事务历史记录中可表示为 ri(P: Vset(P)) ri(xj) ri(yk),其中xj, yk表示在这个事务中读到的符合这个谓词P的版本。下面以关系型数据库为例,假设有如下查询要求: SELECT * FROM EMPLOYEE WHERE DEPT = SALES; 则可以将某个事务Ti中的读操作表示为 ri(Dept=Sales: x1; y2) 其中x1符合要求而y2不符合,因此 后面附加一个ri(x1)操作; 由此可以完整的表示为ri(Dept=Sales: x1; y2)ri(x1);如果是 SELECT count 则无需附加 ri(x1)。
- 基于谓词的修正操作
一个事务Ti中基于这个谓词P的修改操作,可以分解为对于所有符合这个谓词布尔表达式的数据对象进行一个读操作跟随一个写操作。例如:假设在事务Ti中有如下修正语句
UPDATE EMPLOYEE SAL = SAL + 10 WHERE DEPT=SALES;
在事务历史记录中可以表示为 ri(Dept=Sales: x1; y2) wi(xi),
对于插入以及删除等操作采取的也是类似策略。
事务的基本性质----ACID
1983年,Andreas Reuter 和 Theo Härder 基于 Jim Gray的早期工作提出了实现事务必须的四个特性:
原子性(Atomicity)
事务是真实状态变化过程的映射,当现实生活中需要状态的变化过程无法分割为更小的步骤(例如:某次转账过程,磁盘的某次数据存入)则称为事务,这无法分割为更小的特性便称为原子性。原子性的颗粒度大小由系统需要实现的实际需求决定。单一事务可以由一个或多个状态更改相关的多个单独操作的组合,当系统实现了原子性便能保证每个一个达到原子粒度的事务过程要么执行成功没有错误要么执行失败,永远不会允许部分成功的情况出现。如果某些操作已完成,但在尝试其他操作时发生错误(例如:系统崩溃,执行停止等非拜占庭错误),则这个系统将"回滚"事务的所有操作(包括成功的操作),从而擦除前面操作造成的所有痕迹,并将系统还原到事务开始处理之前所处的一致、已知状态。如果组成事务的所有单独操作都成功完成没有错误,则称为完成事务提交,此时对数据记录集的所有更改都将永久生效;完成此操作后,事务将无法回滚。因此,当没有并发发生时,客户端无法观察到正在进行中的该事务。对于客户端来说在某个时刻,某个事务还没有发生,而在下一个时刻,这个事务已经全部发生了(或者如果交易在进行中被取消,则什么也没有发生)。
一致性(Consistency):
ACID 中的「一致性」,是对于整个数据库的「一致」状态的维持。抽象来看,对数据库每进行一次事务操作,它的状态就发生一次变化。这相当于把数据库看成了状态机,只要数据库的起始状态是「一致」的,并且每次事务操作都能保持「一致性」,那么数据库就能始终保持在「一致」的状态上 (Consistency Preservation),而且事务的一致性和单一操作的一致性不同,涉及多对象,多个操作以及其他业务约束。多对象多操作一致性通过保证多个单一操作的程序执行过程不违反状态相关的完整性约束来保证。通俗地说,它指的是任何一个数据库事务的多个单一操作执行后,都应该让整个数据库保持在某种「一致」的状态。那怎样的状态才算「一致」呢?以在银行账户之间进行转账为例。「转账」这个操作依据相应的财务规则应确保在转账前后相关账户相加总额保持不变。现在假设要从账户 A 向账户 B 转账 100 元,银行系统依据用户的操作启动了一个数据库事务。在这个事务中,系统先从账号 A 中减去 100 元,再往账户 B 中增加 100 元。这样的一个事务操作,满足了 “转账前后相关账户相加总额保持不变” 的财务规则,因此说:这个事务多个单一操作的执行后保持了系统的数据记录仍处于一种「一致」的状态。另外,也可以看到一个事务的执行也保证多个数据对象的状态更改的一致性(或正确性),这里就涉及两个账户。系统状态一致性相关的完整性约束有一部分由数据系统本身提供相应的约束(例如:关系数据库中的两个主要规则:实体完整性---唯一标识和参照完整性---主、外键),而另一部分约束则和满足业务需求相关(例如:如果需要满足一个会计业务的约束----所有账户的收支必须平衡)。这些约束无法通过数据系统本身的约束保证,需要应用程序程序员通过编写程序级代码的方式来实现。比如前面这个转账的例子,“转账前后账户总额保持不变”,这个规定只对于「转账」这个特定的业务场景有效。如果换一个业务场景,「一致」的概念就不是这样规定了。因此,ACID 中的「一致性」,其实是体现了业务逻辑上的合理性,并不是完全由数据库本身的技术特性所决定的。
隔离性(Isolation):
为了提升信息处理过程的执行效率,一个完整的事务处理过程中的多个事务通常同时执行(例如,多个事务同时同一个记录进行信息处理)。为了保证在这种情况下信息处理的正确性、一致性,就需要确保多个事务的并发执行后数据记录集中的状态,与这些事务按顺序执行后的状态一致。为达成这个目的可以将并发执行的事务彼此隔离,即通过控制某个事务造成变化对于其他事务的可见性来设置各个事务之间不同的隔离程度。基于较高的隔离级别,一个不完整的事务对于状态的影响可能对其他事务是没有可见性的,这减少了在并发情况下保证信息处理的正确性实现难度,从而也减少了客户端遇到的各种并发问题的几率,但这些会需要更多的系统资源并增加一个事务阻塞另一个事务的机会从而影响信息处理的整体执行效率,反之较低的隔离级别会增加系统处理信息的能力,从而增加了客户端访问相同数据的能力,但会增加客户端可能遇到的并发处理而带来的各种问题(例如脏读或丢失更新)的几率。
持久性(Durability):
持久性是一种承诺或保证,一旦事务成功执行,它所做的状态改变将永久存在,如同真实世界发生的事件是无法回溯和改变的一般。在单个计算机范围内,持久性通常意味着信息已写入非易失性存储(如硬盘驱动器或SSD)内,并有了日志备份。而在分布式系统中,持久性可能意味着数据数据 已成功复制到各个副本上,各个数据副本已经协调完毕并达成共识,数据也已经确认提交完毕。
ACID之间的关系
ACID之间不是相互正交的关系。原子性的主要依靠持久性来保证事务成功提交后,即使有各类系统错误数据记录集的所有更改也将都将永久生效。而隔离性与一致性又部分依赖于原子性实现,当隔离性设置不当则会出现死锁,这时需要通过原子性的回滚操作来解除,当出现一致性被违反的时候需要保证原子性的回滚操作来保证系统从错误的事务执行后的状态回到正确的初始状态。一致性又有一部分依赖于隔离性,多个事务并发执行情况下的数据记录信息处理过程的一致性通过隔离性保证。
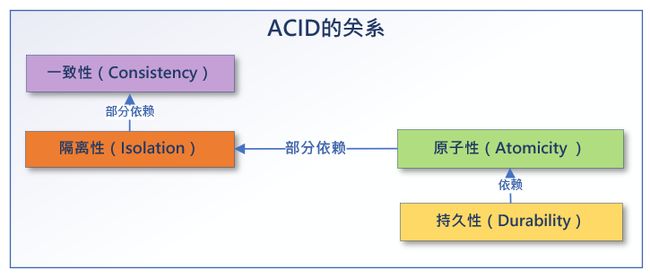
图2
事务调度相关概念
在数据系统中会有多个事务执行,当这些事务执行结束就会形成一个事务历史记录,并得到一个由这些事务交织而成的顺序。为了提高事务的执行效率,希望人们总是将各个事务尽量的并发执行以期提高执行效率。然而,多个会相互影响的事务的并发操作非常容易破坏数据记录的完整性和一致性并产生一些意想不到的结果,因此就需要基于事务相互的影响程度(可见性)找一个事务执行的可串行化调度,从而得到一个合适的事务执行顺序序列来确保多个事务的并发执行后数据记录集中的状态与这些事务单个按某种先后顺序执行后的状态保持一致,使系统符合所需的一致性与正确性。
调度(schedule)
一组事务的基本步(读、写、其他控制操作如加锁、解锁等)的一种执行顺序。
串行调度
最直观的保证一致性的对于各个事务的协调方式是串行调度(serial schedule),即不允许多个事务并发执行,所有事务组成单一队列,一个接着一个执行。很明显,事务串行执行的效率是最低的。
可串行化(Serializability)
可串行化是一种对于事务或者说一组操作对于一个或多个对象执行的保证。它保证基于可串行调度(serializable schedule)方式P执行事务的系统,其每个事务的执行结果完全等价于将这些事务完全基于一个串行(全序)调度P’执行的结果。
可串行化需要保证如下一致性:
内部一致性:在同一个事务之内,读取操作必须观察到该事务的最近写入操作写入的信息(如果有)
外部一致性:在事务 T1 中如果某一个读取操作之前在同一个事务之中没有任何写入操作,且当这个读取操作观察到在事务T1之前的另外一个事务 T0 的写入操作的写入的信息,并且T0和T1之间没有任何其他最近的事务写入该数据对象,则可以认为T0 对 T1可见,。
全可见性:可见性关系必须是全顺。
可串行化与线性一致性
如果对于事务的操作基于时间进行约束,即所有事务的多对象操作的顺序只能严格按照唯一的时间进行排序,事务的事件历史记录的顺序和线性一致性的记录一样是一个全序,则可以认为是严格串行化。因此,线性化可以看作是严格串行化的一个特例,其中事务被限制为由应用于单个对象的单个操作组成。可串行化(序列化)和线性一致性不同之处是可串行化是不可组合的,因为可串行化不能保证全序,顺序也不唯一。
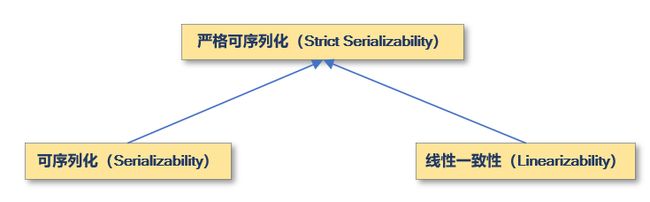
图3
相关属性
1) 串行:即不允许多个事务的操作并发执行,所有事务的操作成单一队列,一个接着一个执行。
2) 原子性:序列化意味系统保证事务的操作以原子方式进行,即一个事务的子操作会表现为不会与其他事务的操作相互交错。
3)多对象: 事务的操作可以涉及对多个对象进行操作,序列化不仅会对于一个事务中涉及的一部分特定数据对象产生影响,也会通过谓词等形式对整个系统中的所有对象产生影响。
4)约束:可串行化没有包含任何类型的确定性顺序(没有仲裁),可以存在一些等效的串行执行。尽管有时十分需要事务顺序是一个全序序列,但仍然允许某些有瑕疵的顺序(依据系统应满足的正确性需求)。可串行化没有与时间相关约束,也没有对于各个进程之间可见性方面进行约束(如果进程 A 完成写入 w,则进程 B 开始读取 r,r 不能够保证一定能观察到 w)。
可串行化的识别
不是所有的用户事务的调度(执行顺序)都是可以序列化的(即 等效于单个事务按照某些顺序执行),而且由于通过简单的事务模型来识别事务历史记录中是否可串行化顺序是一个 NP 完备问题(NP-complete)[papa79],所以找一个识别事务历史记录中可串行化顺序的高效方式并不容易,同时可串行化的一般定义很难应用。因此,我们定义了更实用的不同类型的可串行化。:视图可串行化与冲突可串行化,两者都是可串行化的子集。其中,最常用的且容易实践的是冲突可串行化形式。实践中一般都基于事务之间的依赖关系以及由此产生的操作序列冲突产生相应的有向序列化图也称为优先图或冲突图,参考系统所需满足一致性要求调整相应的可见性、选择不同的隔离级别,从而识别到合适的可串行化调度。
事务之间的依赖关系:
两个或多个事务之间的依赖关系是确认事务相互的影响程度(可见性)的关键也是确定给予事务合适的隔离级别的基础。
读依赖(Read Dependencies):
1)改变谓词读操作的匹配(Change the Matches of a Predicate-BasedRead)
指由于某个事务 Ti的执行而改变了另一个事务Tj基于某个谓词P布尔表达式的读取操作 rj (P: Vset (P)) 的匹配得到结果集的情况。当 Ti 的写操作写入了版本为xi的数据记录,xi在版本顺序记录中的位置紧接已经存在的xh的版本之后(即xh的版本顺序在xi之前一位),且xi与xh两个版本中有一个符合谓词读操作的匹配,则认为对象版本 xi 改变了谓词读操作的匹配。因为对于 rj (P: Vset (P)) 的匹配得到结果集来说,如果数据对象xi匹配而数据对象xh不匹配则应该保证xi的值是可见的,反之数据对象xi不匹配而xh匹配则两者的值都不应该在匹配结果集中可见。
2)直接读依赖(Directly Read-Depends)
直接数据项读依赖(Directly item-read-depends): Tj的读操作读取了Ti的写操作写入的数据对象版本xi,则事务Tj对于事务Ti在数据项item上有直接读依赖。
直接谓词读依赖(Directly predicate-read-depends):当事务Tj 进行了一次基于谓词布尔表达式读操作而得到了数据对象的xk版本, 而事务Ti的写操作产生了同一个对象的xi版本,而当i=k或者 xi< 例如:当某个事务 Ti 执行了 后紧接着事务Tj当中执行了 则前述的写入的符合 Dept=Sales的变化要在事务Tj当中反应出来。基于谓词的读取的版本集中的所有数据对象的各个版本都被视为可以访问,包括与谓词不匹配的数据对象。那些在事务中(例如前述事务Tj中匹配到的数据对象的读操作)作为一般的读操作事件被记录,其他版本则被记录为幽灵读(ghost reads)。这些的版本的值在基于谓词匹配的读操作中不可见,但是其仍具有读依赖。这样的规则可以使开发者发现基于谓词的读操作会发生的可能的最小的冲突。 假设事务T0插入数据对象,对象的版本为x0其中Dept对应的值是Sales,然后事务T1将Dept对应的值改为Legal同时数据对象版本变为x1,而事务T2只更新了数据对象中其他数据项的信息(例如:电话号码)而没有改变Dept对应的值,此时数据对象版本变为x2。尽管对于事务T3来说,其读取的版本集包含版本x2,但是由于事务T2对于数据对象x的变更和事务T3中的谓词匹配无关,其对于匹配的y2进行写入操作(w2(y2) ),所以这里认为T1和T3之间有直接谓词读依赖而不是T2。(因为T1改变了Dept对应的值。) 由于T2和T3之间没有依赖关系所以,这几个事务的序列化顺序可以为T0, T1, T3, T2. 当一个事务将其他事务已经观察到的数据版本给覆盖掉的时候则产生了反向依赖。与读依赖的操作排列顺序相反,读依赖中写操作执行发生在读操作之前,而反向依赖写操作在读操作之后。 1)覆盖基于谓词的读操作(Overwriting a predicate-based read) 当事务Tj写入了一个新的数据对象版本xj并且xj的版本在版本顺序记录中位于xk顺序之后,而且xk版本符合另外一个事务Ti已经执行的一个谓词匹配读取操作,则可以认为版本xj改变了Ti事务中符合该谓词匹配表达式的读操作得到的结果集。(如果Ti执行谓词读操作得到的结果集和Tj事务写操作执行后立即再次执行和Ti事务相同的谓词读操作后得到结果集和前一次执行谓词读操作得到的不一样。) 2)直接反向依赖(Directly Anti-Depends) 直接数据项反依赖(Directly item-anti-depends): 事务Ti的读操作读了数据对象版本xi,事务Tj 写入了对象的在版本顺序记录中的紧接xi之后的版本xj, 则可以认为事务Tj 对于事务Ti有直接数据项反向依赖(即执行写入操作且数据对象版本顺序在后的事务反向依赖于读得到同一个数据对象且版本顺序在前的事务)。 例如:当某个事务 Ti 执行了 后紧接着事务Tj当中执行了 则事务Tj反向依赖于事务Ti。 3)直接谓词反向依赖 Directly predicate-anti-depends 当事务Tj执行的写操作例如写入某个数据对象的新的版本覆盖了另外一个事务Ti执行基于谓词的读操作得到包含这个数据对象的以前的版本的结果集合,则可以认为Tj对于Ti有直接谓词反向依赖。 例如:当某个事务 Ti 执行了 后紧接着事务Tj当中执行了 当一个事务将其他事务已经写入的数据版本给覆盖掉的时候则产生了写依赖。 1)直接写依赖(Directly Write-Depends) 当事务Ti写入了数据对象的版本xi而事务Tj写入了依据版本顺序在xi之后的下一个版本例如xj,则认为事务Tj对事务Ti有直接写依赖。 例如:当某个事务 Ti 执行了 后紧接着事务Tj当中执行了 冲突操作指的是使调度中的一对操作满足:如果它们的顺序交换,则涉及到的事务中至少有一个的操作会改变。同一个事务的两个操作总是冲突的,而对于多个事务来说的由于事务之间的依赖关系产生了一些操作顺序上的冲突,如果调度S通过交换调度中的非冲突操作可以变换为串行调度,这样的调度S称为冲突可串行化调度(conflict serializable schedule)。按照两个不同的事务对数据库中的同一元素(需要特别注意,这里的元素不等同于一行数据,可能为一个条件范围,也可能是一张表)的读写操作(至少有一个写操作)组合,定义出三种有方向的冲突(conflict): 基于依赖以及相对应的冲突的定义可以从事务的历史记录(H)中定义出与从[BHG87]中给出的条件定义的视图可串行化类似的冲突序列化图(Direct Serialization Graph History,DSG(H))。DSG (H) 中的每个节点对应于事务的历史记录中的一个已提交事务,有向边对应于不同类型的直接冲突。DSG 不会记录事务历史记录中的所有信息,例如,DSG 仅记录有关已提交事务的信息,因此它不能代替事务的历史记录。在DSG中每一个节点代表一个已提交的事务,每一个有向的边代表不同类型的直接冲突。 当一对操作有写读冲突(Write-Read conflict):当事务Tj直接读依赖于事务Ti,则在图中画一条从 Ti 到 Tj 的实线有向边, Ti——wr——>Tj 当一对操作有读写冲突(Read-Write conflict):当事务Tj直接反向依赖于事务Ti,则在图中画一条从 Ti 到 Tj 的虚线有向边, Ti- - rw- - >Tj 当一对操作有写写冲突(Write-Write conflict):当事务Tj直接写依赖于事务Ti,则在图中画一条从 Ti 到 Tj 的实线有向边 Ti——ww——>Tj DSG 的示例: 图4 这个DSG图中没有成环,可以进行冲突可串行化转换,等效于序列化事务的顺序: T1< 由于数据版本顺序为 [x1< 图5 这个DSG图中也没有成环,可以进行冲突可串行化转换,等效于序列化事务的顺序为:T1<< 当有向序列化图出现了循环,则表明出现了相互依赖的情况,这样说明这个数据记录历史是无法序列化的,因为无法判断顺序。 图6 由于不是所有的用户事务的执行顺序都是可以序列化,而且事务执行顺序的序列化对于性能的影响十分严重,也不是所有的系统的一致性需求都需要通过序列化保证,由此人们基于数据系统所需满足的在系统层面的各级正确性需求,对于可见性程度和冲突造成错误的容忍度进行了规范,从而提出了隔离级别(Isolation Levels)。 隔离级别有多种规范,例如:ANSI的规范在历次版本都对于隔离级别做了相应的修订 (ANSI-86,ANSI-92,ANSI-99等),Adya从事务的关系角度并基于底层的事务历史记录提出了一个更具一般意义的隔离级别定义。此外,Cerone, Bernardi, & Gotsman等人提出了一个合理直观的基于抽象操作的形式化定义。由于Adya的定义与系统的具体实现解耦,只是要求这些有冲突的并发事务按照依赖关系不组成循环依赖即可,从而允许冲突的事务并发发生,因而更具一般意义,所以这里采用Adya的隔离级别定义为基线进行介绍。 Crooks,Pu,Alvisi以及 Clement则基于系统状态模型定义了相应的隔离级别并提出了客户端应用程序为中心的隔离模型(Client-Centric Specification of Database Isolation)。 1 状态模型 在状态模型中,隔离级别与候选状态集合(即读状态(read states)相关联而不是通过底层的事务历史记录。应用程序的事务可能从这些状态集合(例如:snapshot)中检索这个事务对应的底层操作执行时已经读取的值,且通过读取状态获得与数据存储系统的事务在运行时观察到的信息相一致的可能的状态集合的。 从系统状态的角度,若一个存储系统保证相应的隔离级别则必须要实现创建一个符合以下两个条件的执行(由于是基于状态的模型,所以在这个模型当中事务的执行(execution)是一系列系统的原子状态转换也是一组符合约束的事务集合T的一个全序集合,其涉及的状态集是通过从系统的初始状态开始执行,基于事务集合T中所有事务的排序而生成的状态集。) 1)执行必须与每一个事务的观察到的结果一致,这可以通过关联每个事务与读状态集合,用这些状态表示在应用程序执行相应的事务的操作时存储系统能够已经所处于的状态来实现。 2)执行必须是正确的且符合需要实现的隔离级别的约束,这些约束有效的减少了用来给应用程序构建一个可接受的执行对应的读状态的数量。如果无法得到一个符合某些事务的读状态,则认为无法保持对应的隔离级别。 2 隔离级别 对于应用程序来说,最终还是要通过在程序执行时观察到的状态来明确它依赖的数据存储系统是否能够给它的客户端提供相应的隔离级别保证,所以事物的历史记录对于保证应用程序的隔离级别来说并不是必须的。 基于一个以系统状态为基础的模型,对于应用程序来说,隔离级别标识了一个给定的事务集合以及与之对应的正确执行(一系列状态转变)的集合。隔离级别通过两个条件约束了了每个事务的执行: 1)对于事务T读状态集合的父状态进行限制。 2)将某一个事务T与一个有限的读状态集合相关联,这些状态表示在应用程序执行事务T的操作时,数据存储系统可能处于的正确的(业务约束所允许的)状态。 图7 从这里我们看出,此类模型对于应用程序的事务处理比较有意义,因此这里也会对各个隔离级别对应的客户端为中心的隔离级别做一定的介绍。 如同ANSI的规范,Adya也会基于每个级别避免的场景定义每一个隔离级别,Adya的对于场景以“G”为前缀进行说明,以表明它们具有足够的一般性允许锁或其他不同优化方式进行具体实现。(场景的命名G0,G1类似ANSI-92规范的P0,P1)。隔离的级别采用 PL (portable level)进行定义。 排斥场景:PL-1级别仅不允许场景G0。所谓G0场景指的是基于事务历史记录生成的DSG(H)图中具有由直接写依赖造成的循环依赖的场景。PL-1 对读是没有限制的,所以出现所谓的“脏读”就太正常了。例如: 图8 数据版本历史记录顺序:[x1< 由于PL-1的定义仅排斥循环覆盖的场景,因此PL-1允许多个事务并发修正同一个数据对象,这与ANSI的P0定义相比放宽了限制,P0 是不允许多个事务并发修正同一个数据对象的。因此,在实现PL-1的隔离级别的系统中未提交的事务的多个写入操作的(非序列化交错)并发执行是可能的,只要在已提交的事务中不允许并发即可(例如,通过中止某些事务来保证已提交事务的顺序)。由于锁的互斥性,两个事务无法同时并发修正同一个数据对象,故而使用锁机制(长写锁(Long duration Write locks))可以确保场景G0无法发生。 由于基于谓词的写入操作由谓词读操作加上一个紧跟的一般写入操作组合而成,PL-1对这类操作提供一个弱保证。例如:假设两个事务T1和T2并发执行,事务T1增加了两份数据记录x和y,T2则将所有“cond=A”的值进行了更新,两者的操作在事务历史记录中是相互交错的,其事务历史记录如下: 这里事务历史记录中两个事务的操作的交错的造成数据对象x由T1的写操作写入的更新值被T2事务的r2读操作读到,但数据对象y的由T1的写操作写入的更新值则没有。这种并发执行情况在 PL-1 是允许的,因为在 DSG(H)中没有写依赖循环,仅含有 T1到T2的写入依赖(这里假设最终的数据版本顺序为 [xinit11])。 客户端角度: 对于客户端应用程序来说,在隔离级别PL-1意味着客户端要允许并能够处理脏读,即客户端的事务可以看到任意(包含并发)事务无论是否提交所产生的变化。 由于PL-1只对于G0即写依赖造成的循环依赖的场景做出限制,因此事务的读操作完全没有限制(事务可以读到已经提交、未提交、甚至中止的事务的造成的修正值)。这样的系统应对某些需要对于某些读依赖场景进行限制的需求就显得不足,由此提出了隔离级别PL-2。隔离级别PL-2除了保证隔离级别PL-1以外还针对读依赖提出不允许场景G1。 排斥场景:G1;G1分为3类场景G1a,G1b,G1c G1a: 中止读( Aborted Reads.) 当事务历史记录中的包含这样的交错:已经提交的T2事务中的读操作读到某个数据对象的值是被中止的事务T1写入的数据对象的值。 H:w1(x1) ... r2(x1) C2 A1 (C2与A1次序任意) 谓词读的情况 H:w1(x1) ... r2(cond="A": x1,...) C2 A1 (C2与A1次序任意) 通过排除场景G1a 保证了当事务T1给中止后事务T2也必须被中止。即级联中止。在工程领域,通过保证直到事务T1提交成功后才进行事务T2提交来实现。 G1b:中间读( Intermediate Reads.) 当事务历史记录中的包含这样的交错:已经提交的T2事务中的读操作读到了由于事务T1多次写入的数据对象的某一个中间版本的值,无论事务T1是否已经提交。 事务T1的第一次写操作写入的值为1,这个中间值为事务T2的读操作所得到,而后事务T1的第二次写操作发生,写入的值为3。此时,事务T2进行提交则为不符合隔离级别PL-2。 谓词读的情况 通过排除G1b 保证了事务只有在读取操作所取得的结果是其他事务创建或者修正数据对象的最终版本之后才能提交。系统排除场景G1a以及G1b便能够保证一个已经提交的事务的读取操作得到的数据对象状态只能是在某些时刻已经是已提交后的数据状态或是在将来某一个时刻提交后的状态是这个数据对象版本的状态。 G1c: 循环信息流(Circular Information Flow) 当基于事务历史记录中产生的 DSG(H)图中包含一个完全由依赖关系(不包含反向依赖)组成有向环则这个事务历史记录包含场景G1c。 G1c包含场景G0,G1c代表了一类更一般的情况即一个事务能够影响另外一个事务,但这个影响必须是单向的而不能是双向的.例如:G0就是双向的写依赖的场景。由 G1a、G1b 和 G1c 组成的G1情景蕴含了脏读的本质,当系统实现了隔离级别PL-2则剔除了G1情景,也就消除了发生脏读的可能。 G1与传统的基于ANSI-92的P1级别相比限制更弱一些,因为排除G1的情景的系统仍允许事务读取其他未提交的事务中的写操作写入的数据版本(只要保证将来某一个时刻提交后的状态是这个数据对象版本的状态)。 同时,对于谓词读的情况由于涉及多个数据对象及其版本,对于事务包含的单个操作的所能保证一致性也需要进行相应的规定(从弱到强如下) 1、和一般的读取操作的一致性一致(谓词读操作不保证是原子操作) 2、保证谓词读取操作是原子操作 3、一个事务中的所有写操作是原子操作 例如:当谓词读取操作不是原子操作会发生如下情景: 上面事务历史记录中,事务T2的谓语读操作r2(cond=“A”.....) 由于不是原子的,因此事务T1的写操作对于相应数据对象的修改没有全部反映在T2的谓语读操作之中。 另外,当使用传统的锁进行实现排除G1情景时,长写锁(写锁维持时间较长可能需要等待多个操作结束)与短读锁的组合使用会保证如果事务Ti提交的时候其读操作得到另外一个事务Tj写入的数据版本必然是事务Tj已经提交时的数据版本,这就保证了G1a与G1b已经被排除了,同时也保证事务Tj不可能反过来得到Ti写入的版本(因为长写锁的存在),这保证了场景G1c也被排除。 客户端角度: 对于客户端应用程序来说,在隔离级别PL-2意味客户端要允许并能处理它的事务T看到任何其他已经提交事务(无论是否并发)的结果,事务T的所有操作不必从同一个状态s读取信息,仅需要保证从事务T的执行是从事务T之前已经提交的任意事务产生状态中读取。 仅排除G1的场景对于维护系统数据版本的准确性并不足够,因为G1针对的是依赖关系相关的需要排除的情况。 如下面的场景之中程序的 在这个事务历史记录当中可以看到事务T1和事务T2都读取了相同的系统已存在的一个数据对象的版本,然后事务T2对于这个数据进行了更新操作(x0+6=x2,26),并进行了提交。在T2提交之后,事务T1也对于这个数据进行了更新并进行了提交(x0+5=x1,25)。数据对象的版本x2的顺序在x1之前,如果客户在T2提交后并没有任何读取操作,这样的顺序会容易造成T2事务所做的变化(x0+6=x2,26)可能并没有会被客户端察觉到,即对客户端来说T2事务的数据操作的结果发生了“丢失”,客户端会得到数据对象x1的版本的值25作为最后的结果。有的时候这种丢失是业务规则所不能容忍的。例如:往购物车里面添加物品的操作,从业务规则来说两次增加货品数量是一个累计的过程。为了提高系统的并发性,有的系统会将两次物品的添加进行并发操作,如果出现上述“丢失”的情景则,购物车最后得到货物数量不是一个叠加的总数33(x0+6+5)而是数据对象x1的版本的值25,则会造成系统不能依从业务规则的情况出现,从而出现系统错误,而且这类错误并不是那么容易暴露的。 防止上述场景有多种设计方式,一类与单个对象以及单个操作的并发控制类似将操作数据对象设置为临界区的资源,通过互斥(如锁)进行相应的并发控制,这类设计典型的有ANSI-92规范等。因为是采用单个对象的并发控制方式对多个数据对象的并发访问进行约束,使用这一类方式的副作用是需要限制的场景会多于实际必须限制的场景。下面的例子当中,假设系统业务规则为需要维持x+y=35,如果数据存储系统生成的事务历史记录为H1则事务顺序为T1,当事务T1与T2提交以后T2得出的x2(x2的值为20)+y2(y2的值为9)=29违反了x+y=35的业务约束条件。 图9 基于事务历史记录H1生成DSG图中含有有向环 如果将两个事务中的commit的操作顺序进行调整,生成的数据存储系统的事务历史记录为下面H2这样的顺序。 图10 基于事务历史记录H1生成DSG图中不含有有向环 这个事务历史记录下的事务T2早于事务T1提交即事务顺序为T2T1,则事务T2与T1提交后T1与T2都能遵守x+y=35的业务约束条件,只要提交顺序是正确的也能保证两个事务执行正确性,那么即使T2和T1有对同一个数据对象并发执行情况且没有进行互斥保护(如ANSI-92中的P2)也是没有问题的。使用前面描述的方式会将这些正确的事务历史记录H2也一并排除掉,从而造成许多多事务并发控制优化方法以及多版本等调度都将无法使用,使数据存储系统设计的系统灵活性和执行效率受到较大的影响。 那么如何减少这样的情况呢,通过对于上述这类正确的事务历史记录进行分析可以发现,系统真正需要的是防止因为事务执行提交而导致不一致读取或写入结果,由此提出了不允许场景G2。 排斥场景:G2 G2:反向依赖循序(Anti-dependency Cycles) 当基于事务历史记录中产生的 DSG(H)图中包含一个含有反向依赖关系(可以多于一个反向依赖)的有向环,则这个事务历史记录包含场景G2。 隔离级别PL-3除了排斥场景G1也排斥场景G2,即隔离级别PL-3产生的 DSG(H)图不能包含任何有向环。 图11 假设数据历史记录H0中的事务T1和T2之前存在事务T0,事务T1和T2都对于事务T0存在直接读依赖即写读冲突(没有形成有向环)。然而,事务T1对于T2存在直接写依赖即写写冲突,同时T2对于T1存在直接反向依赖即读写冲突从而形成了有向环。 通过加入了对于场景G2排除,一样实现了防止因事务执行提交而导致不一致读取或写入结果,而且与ANSI-92中的P2等通过互斥预防的方式相比由于允许事务T2对于已经被未提交的事务T1的读取操作读取了的数据对象x以及y进行修正而大大提高了系统设计的灵活性。由于隔离级别PL-3是基于依赖关系以及与之相对于的冲突操作的进行规定的,而冲突可串行化(conflict-serializability)是几乎所有实际工程实践(主要的数据库系统)都会提供的,因此在一般意思上可以认为隔离级别PL-3等同于可串行化。 客户端角度:对于客户端应用程序来说,隔离级别PL-3意味着客户端应用程序的每一个(并发执行)事务的操作所观察到的值应与这些事务按照顺序执行时操作观察到的值一致等,同于上面所说的排除G1和G2。 1)事务T所有的操作必须从相同的状态s读取到信息 2)事务T在执行后的得到一个状态t的父状态(即t状态的前一个状态)应该是状态s。 隔离级别PL-3对于事务的各类涉及的所有数据对象进行了限制包括谓词读取操作,因此对系统的整体性能仍有较大影响,那么如何进行一定的改善呢?由于谓词读取操作可能涉及整个数据集合对于系统性能的影响最严重,因此可以通过放松谓词读取操作方式在系统需要提供的事务正确性和性能之间取得一定的平衡。由此,通过对于隔离级别PL-3进行些微的调整,从而定义出了隔离级别PL-2.99。 在隔离级别PL-2.99中,排除场景G1以及仅针对数据对象的包含的数据项(item)的场景G2也称为G2-item(数据项反向依赖循环)。 排斥场景:G2-item(数据项反向依赖循环) 当一个事务历史记录形成的 DSG(H) 包含一个或多个数据项反向依赖循环的有向环,则这个事务历史记录包含场景G2-item。 图12 假设有一个库存系统中有两个品种的货物分别为x,y,事务T1和事务T2进行并发执行。事务T1对于库存进行了基于谓词A的查询并得到了相应的当前符合条件A的品种x,y的库存所占仓位数量为5。而后事务T1和事务2分别通过各自的一般读操作读取了单个品种x和y的所占仓位数量为5的业务操作。事务T2在后面的操作中加入了一个新的商品z,z的所占仓位数量为10且符合谓词A的查询条件,从而系统中的商品x,y,z所占仓位总数量为实际为20。如果事务1在得到货物的总数之后依据业务需求会在库存系统层面将货物总数与仓库中的剩余空白仓位进行所占的比例的计算,并且在做这个比例计算操作,由并发执行的事务T2加入了一个新的商品z,并在事务T1提交之前进行了提交。由此,当事务T1做z重新读取货物所占仓位的总数的时候会发现与前面读取的内容有不一致的情况即所谓的幻读(phantom read)的情况。 Adya的等级 排除的场景 描述 ANSI-92 (基于锁实现) 排除的场景 客户端为中心 隔离级别PL-1 G0 排斥循环写覆盖的场景,一个事务的写操作与其他事务的写操作完全隔离。 WRITED UNCOMMITTED(ANSI 未定义) Long write locks N/A(P0 ANSI 未定义) 客户端要允许并能够脏读,即客户端的事务可以看到任意(包含并发)事务无论是否提交所产生的变化。 隔离级别PL-2 G1 涉及事务之间直接依赖关系相关的需要排除的场景。一个事务在提交时要保证其读操作读取的数据是其他已经提交的事务更新或写入的。 READ COMMITTED Short read locks Long write locks P1(Dirty Read) 事务T的所有操作不必从同一个状态s读取信息,仅需要保证从事务T的执行是从事务T之前已经提交的任意事务产生状态中读取。 隔离级别PL-2.99 G1,G2-item 涉及事务之间直接依赖关系与反向直接依赖相关的需要排除的场景。一个事务在数据对象的单个数据项层面完全与其他事务隔离,并保证对于基于谓词的读操作(涉及符合谓词的多个数据对象)保证隔离级别PL-2。 REPEATABLE READ Long data-item read locks, Short phantom read locks Long write locks P1, P2(Non-repeatable or Fuzzy Read) 没有单独的定义,缩小到单个数据项与隔离级别PL-3一致,扩大到所有数据集合则与隔离级别PL-2一致 隔离级别PL-3 G1,G2 涉及事务之间直接依赖关系与反向直接依赖相关的需要排除的场景。 一个事务的所有操作完全与其他事务隔离,这个事务的所有操作与其他事务的所有操作没有交错,所有操作要么都在另外一个事务的所有操作之前或之后。 SERIALIZABLE Long read locks Long write locks P1, P2,P3(Phantom) 并发执行事务的操作所观察到的值应与这些事务按照顺序执行时操作观察到的值一致,等同于排除G1,G2 对于数据存储系统程序来说给予只包含一个简单读操作事务T1,与另外一个包含了一系列写操作事务T2使用同样的事务隔离级别对于性能是有极大的影响的。一般来说,实际系统可能不能保证所有的事务总是同一个隔离级别上进行执行,往往是不同的隔离级别的事务混合在一起执行的。 使用混合使用隔离等级的系统当中,其会对每个事务指定相应的隔离级别。当每一个事务开始执行并产生相应的事务的历史记录,隔离级别信息也被记录在事务的历史记录之中。基于这些信息,可以在DSG图的基础上演化出相应的混合序列图MSG(mixed serialization graph)。 MSG是比DSG更特化的有向图形,MSG图中的节点以及边和DSG类似,不相同的地方在于MSG图中的有向边只包含与事务隔离等级相关依赖(冲突)或者强制冲突。 1)强制冲突(obligatory conflicts) 事务Ti与事务Tj之间有强制冲突需要满足以下的条件: 1)事务Tj直接依赖(冲突)于事务Ti,例如:Ti——wr——>Tj 。 2)系统运行事务Tj的隔离级别高于运行事务Ti的隔离级别。 3)Ti之间Tj依赖(冲突)与Tj的隔离级别有关。 例如:当一个系统给予事务T1隔离级别为PL-3,而与之有直接反向依赖关系的事务T2系统给予的是PL-1级隔离级别(即T1--rw-->T2),由于事务T2的写操作需要覆盖的是运行在隔离级别PL-3的事务T1的读取操作所读取的值,必须要等待T1提交以后才能覆盖,所以符合强制冲突的定义,在MSG上面用实线有向边表示。 2)与事务隔离等级相关依赖(冲突) 所以在MSG添加有向边规则如下:从隔离级别的定义可以看出写依赖对于所有的隔离级别相关依赖(冲突)都有影响,因此所有的写依赖都会在MSG中作为有向边予以保留。而对于对于隔离级别为PL-2或者PL-3的事务T1来说由于要保证排除G1场景,保证其读操作读取的数据是其他已经提交的事务更新或写入的,因此标识出读依赖显得十分重要的即所有从其他事务到隔离级别为PL-2或者PL-3的事务Ti的读依赖都要通过有向边标识出来。相同的道理,在反向依赖关系中所有的从隔离级别为PL-3的事务到其他事务的有向边都要标识出来。 混合使用不同隔离等级的正确性 对于一个事务历史记录来说,当里面所有的有向边没有成环,并且对于隔离级别为PL-2 和 PL-3 事务没有出现 G1a(中止读)和 G1b(中间读)场景,则可以认为这个事务历史记录所包含的混合不同隔离等级的记录是正确的,即每个事务各自提供与其隔离级别相关的保证。一般来说任何通过锁实现的系统的历史记录都是可以保证混合使用不同隔离等级的正确性的。 图13 对于事务T3来说其操作r3(x1,60),r3(y1,15),r3(z2,35)执行后,数据存储不符合系统的业务需求x+y小等于z的业务规则从而出现了数据一致性的错误。由于事务T1是对于T2有RW反向依赖,这个反向依赖在MSG中没有体现因为这个有向边的方向是从PL-2隔离级别的事务T2到PL-3的事务T3.由于事务T2的操作中涉及的业务需要基于T2的读操作得到的数据,因此仅基于MSG的有向边则会使事务T2只能得到基于事务T1的一部分的更新信息做出的判断,从而使事务T2更新后,数据存储系统的数据出现不一致的情况。所以,即使事务T3提供了PL-3级别的隔离,仍旧不能保证系统的一致性。T2使用读锁可以排除此类情况,否则使用较低隔离等级的事务则必须识别出对于相应的不一致情况并做出合适的应对从而保证其更新的一致性。 浅析分布式系统之体系结构 - 事务与隔离级别(多对象、多操作)下篇_snefsnef的博客-CSDN博客INSERT INTO SAL SELECT NAME, SAL, DEPT FROM EMP WHERE DEPT=SALESL;SELECT * FROM EMPLOYEE WHERE DEPT = SALES;H:w0(x0) w0(y0) C0 w1(x1) C1 w2(x2) r3(Dept=Sales: x2, y0) w2(y2) C2 C3 [x0 <反向依赖 (Anti Dependency)
SELECT * FROM EMPLOYEE ;UPDATE EMPLOYEE SAL = SAL + $10 ;SELECT * FROM EMPLOYEE WHERE DEPT = SALES;INSERT INTO SAL SELECT NAME, SAL, DEPT FROM EMP WHERE DEPT=SALESL;写依赖 (Write Dependencies):
INSERT INTO SAL SELECT NAME, SAL, DEPT FROM EMP;UPDATE EMPLOYEE SAL = SAL + $10 ;冲突操作
有向序列化图
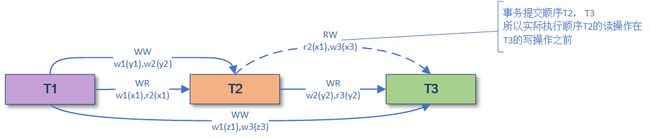
H:w1(z1) w1(x1) w1(y1) w3(x3) C1 r2(x1) w2(y2) C2 r3(y2) w3(z3) C3
H: r1(x0) r3(y0) w1(x1) w2(y2) r3(x1) w2(x2) C1 C3 C2H:r1(x1) r1(y1) w2(x2) w1(x1) r2(y1) C1 C2
隔离级别
隔离级别分类
数据存储为中心的隔离级别定义:
客户端为中心的隔离级别定义:

已提交事务的隔离级别
隔离级别PL-1 (Isolation Level PL-1)

H:w1(x1,2) w2(x2,6) w2(y2,7) C2 w1(y1,9) C1H: w1(x1) r2(cond=“A”: x1, yinit) w1(y1)w2(x2) C1 C2隔离级别PL-2(Isolation Level PL-2)
H:w1(x1,1) ... r2(x1,1) ... w1(x1,3) ... C2 ... (C1) (C2 在符合隔离级别PL-2的系统中无法提交)H:w1(x1,1) ... r2(cond="A": (x1,1),...) ... w1(x1,3) ... C2 ... (C1)H:w1(cond=“A”: (x1,1); (y1,1)) w1(x1,2) w1(y1,2) r2(cond=“A”: (x1,2); (y1,1)) r2(x1,2) C1 C2 [x1,1 <隔离级别PL-3(Isolation Level PL-3)
H0:r1(x0, 20) r2(x0, 20) w2(x2, 26) C2 w1(x1, 25) C1 [x0<H1: r2(x0, 20) r1(x0, 20) w1(x1, 26) r1(y0, 15) w1(y1, 9) C1 r2(y1, 9) C2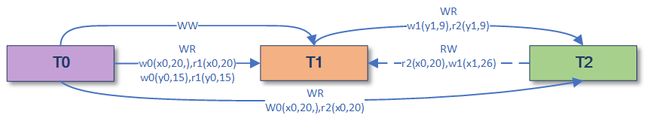
H2:r2(x0, 20) r1(x0, 20) w1(x1, 26) r1(y0, 15) r2(y0, 15) w1(y1, 9) C2 C1
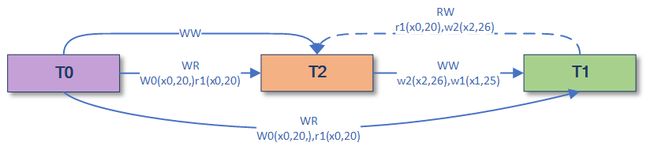
隔离级别PL-2.99(Isolation Level PL-2.99)

Hp: r1(cond=“A”: x0, 5; y0, 5) r1(x0, 5) r2(y0, 5) r2(total0, 10) w2(z2, 10) w2(total2, 20) C2 r1(total2, 20) C1 [Sum0<已提交事务的隔离级别汇总
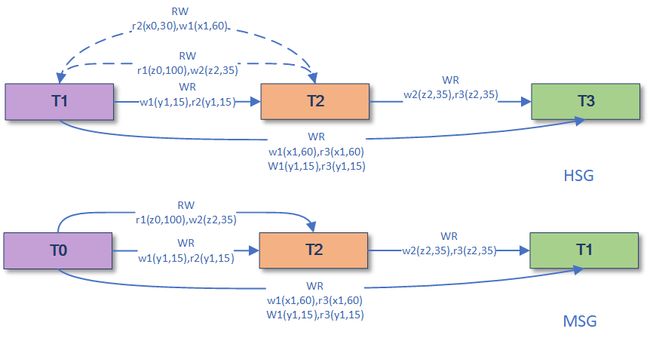
隔离等级的混合使用
Hm: r1(x0,30),r1(y0,35),r1(z0,100),r2(x0,30),w1(x1,60),w1(y1,15),C1,r2(y1,15),w2(z2,35),C2,r3(x1,60),r3(y1,15),r3(z2,35),C3 [x0<