数据分析学习项目:东京奥运会跳水评论分析
“中国跳水梦之队”
————有关东京奥运会跳水评论分析
导语
第32届夏季奥林匹克运动会于2021年07月23日-2021年08月08日在日本东京举办。 四年一届的奥运会可以说是世界瞩目的盛会,奥运健儿们在赛场上的精神风貌不只是代表了他们自身的运动精神,更昭示这整个民族的精神风貌。
一、概述
对此次奥运会之旅,网友们的讨论也十分激烈,单单微博就有超过290亿的讨论度,大家都期待中国队能在世界舞台上一展雄姿。

同时,中国队也不负众望,在此次奥运会中取得了令人瞩目的成绩。

如上图所示,截止8月8日奥运会结束,中国在奖牌榜上依旧是遥遥领先。
从中国奥运奖牌分布,我们可以看出,跳水这一项目获得的金牌位于各个项目前列,那么对于这项取得优异成绩的比赛,网友们又是怎么看的呢?于是,我们就关于跳水这一项目的讨论的内容和相关人员做了一次数据分析
相信大家前几天一定被这个小女孩刷过屏

没错!她就是我们中国年仅14岁的跳水冠军,而且我国的“跳水梦之队”也在今年的比赛中收获颇丰
年轻、活力、未来,这就是朝气蓬勃的中国跳水运动员!
中国队的跳水无论是奖牌数,还是金牌数,都是独占鳌头的存在,在公众中也是引发了强烈的反响。
从奥运官网上爬取下来的奖牌数据,简单的进行处理一下,运用pandas和matplotlib进行画图 (稍后介绍这个这两个工具)
matplotlib可以用各种方式清晰地展示数据,方便得出结论,就拿上面奖牌榜举例

通过读取各国奖牌数据,我们可以轻松实现数据可视化它可以用各种方式清晰地展示数据,方便得出结论。
静态分析已经不能满足我们的眼球了,掌握一定技巧后,动态图表更直观
同时也可以将它们分布到世界地图上,实现区域和奖牌的一一对应。
下面的数据分析环节我们将着重于对数据可视化的获取,这样可以很大程度上帮助我们实现数据分析
我想说,每一块金牌并不只是代表一个数字,而是运动健儿们无数个日夜努力训练的汗水,在赛场上宠辱不惊的冷静发挥,这远比数字值得骄傲值得自豪的
二、准备数据
2.1 收集数据
条件
- 跳水运动于7月25日开始比赛,全部8月7日结束。选择评论时,应该注意评论的发布时间,当在25日之后。
- 尽量选择 “热门” 评论,特别是一些权威机构发布的微博下,进行数据的取样,让数据更具普适性。
- 由于我们进行数据分析的时间在奥运会结束之后,还应当考虑的一点是,这几天的新闻、微博,更多的偏向于奥运会后期,特别是8月5日~7日这几天的报道。所以,也不应该全部将评论的获取集中在后期的报道上,前期也要选取少许评论。
这里主要是通过爬虫技术爬取微博手机端上的用户评论来获取数据
(爬取难度: 网页端>手机端>移动端 )
2.1.1 爬虫简介
开始之前,先简单介绍爬虫流程:
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据

-
发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等 -
获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等 -
解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件 -
保存数据
数据库
一些实用的库和包:
请求库:requests,selenium
request库是根据你提供的网站url,获取网页html信息的库,很多发布在网络上的信息都可以通过相应的html来获取。selenium库是通过代码模拟加载网页的工具,有些网页有相应的反爬虫设置,可能会阻碍我们对html的获取,这时就要用到selenium库来实现自动获取网页的效果。
request:
- URL:
即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。 - 常用的请求方式:GET,POST
- post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
-User-agent:
中文名用户代理,服务器从此处知道客户端的 操作系统类型和版本,电脑CPU类型,浏览器种类版本,浏览器渲染引擎,等等。这是爬虫当中最最重要的一个请求头参数,所以一定要伪造,甚至多个。如果不进行伪造,而直接使用各种爬虫框架中自定义的user-agent,很容易被封禁。
请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息
这里直接上代码
import requests
import json
import re
import time
import random
# 爬取微博评论写入weibo_comment.txt
def get_comment(url, headers, number, params_1, weibo_id):
count = 0
while count < number:
# 判断是否是第一组,第一组不加max_id
if count == 0:
print('是第一组')
try:
urls = url + '&max_id_type=0'
web_data_1 = requests.get(urls, headers=headers, params=params_1)
data_1 = web_data_1.json()
# 获取连接下一页评论的max_id
max_id = data_1['data']['max_id']
comments_list = data_1['data']['data']
for commment_item in comments_list:
user = commment_item['user']['screen_name']
gender = commment_item['user']['gender']
comment = commment_item["text"]
# 删除表情符号
label_filter = re.compile(r']*>', re.S)
comment = re.sub(label_filter, '', comment)
with open(r'weibo_comment.txt', 'a', encoding='utf-8') as f:
f.write(f'{user}\t{gender}\t{comment}\n')
count += 1
print("已获取" + str(count) + "条评论。")
except Exception as e:
print(str(count) + "遇到异常")
continue
else:
print('不是第一组')
try:
urls = url + '&max_id='+str(max_id) + '&max_id_type=0'
params_2 = (
('id', str(weibo_id)),
('mid', str(weibo_id)),
('max_id', str(max_id)),
('max_id_type', '0'),
)
web_data_2 = requests.get(urls, headers=headers, params=params_2)
data_2 = web_data_2.json()
# 获取连接下一页评论的max_id
max_id = data_2['data']['max_id']
comments_list = data_2['data']['data']
for commment_item in comments_list:
user = commment_item['user']['screen_name']
gender = commment_item['user']['gender']
comment = commment_item["text"]
# 删除表情符号
label_filter = re.compile(r']*>', re.S)
comment = re.sub(label_filter, '', comment)
with open(r'weibo_comment.txt', 'a', encoding='utf-8') as f:
f.write(f'{user}\t{gender}\t{comment}\n')
count += 1
print("已获取" + str(count) + "条评论。")
except Exception as e:
print(str(count) + "遇到异常")
continue
t = random.randint(2, 6)
time.sleep(t) # 随机停顿时间
if __name__ == "__main__":
weibo_id = '' # 这里的信息要添加你登录后的cookie,以及所要爬取用户的id
headers = {
'authority': 'm.weibo.cn',
'method': 'GET',
'path':'/comments/hotflow?id=' + str(weibo_id) + '&mid=' + str(weibo_id) + '&max_id_type=0',
'scheme':'https',
'accept':'application/json,text/plain,*/*',
'accept - encoding': 'gzip, deflate, br',
'accept - language': 'zh - CN, zh;q = 0.9',
'cookie':'登录后的cookie',
'mweibo - pwa':'1',
'referer': 'https://m.weibo.cn/detail/' + str(weibo_id),
'user - agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Mobile Safari/537.36',
'x - requested -with': 'XMLHttpRequest',
'x - xsrf - token': 'becd86',
}
# 后面的数据如有不同,也请适时更改。着重强调上述‘:’后的内容里,字符串开头不能有空格,referer中也无空格
url = 'https://m.weibo.cn/comments/hotflow?id=' + str(weibo_id) + '&mid=' + str(weibo_id)
params_1 = (
('id', str(weibo_id)),
('mid', str(weibo_id)),
('max_id_type', ' 0'),
)
number = 200 # 爬取评论量,由于手机版一页是19条,故可能会多爬取
get_comment(url, headers, number, params_1, weibo_id)
pandas:
pandas 是基于numpy 的一种工具,该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pandas读取的到

pandas:
pandas 是基于numpy 的一种工具,该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
2.2 数据处理
2.2.1 去除图片和表情包
这里可以使用正则表达式,替换掉
# 删除表情符号
label_filter = re.compile(r']*>', re.S)
comment = re.sub(label_filter, '', comment)
- 正则表达式:正则表达式是由一些具有特殊含义的字符组成的字符串,多用于查找、替换符合规则的字符串。在表单验证、Url映射等处都会经常用到。
详解和示例:
(1). 匹配任何任意字符 例如 . 可以匹配 1,n,*,+,- ,等
(2)\d\w\s 匹配第一个字符为数字,第二个字符为字母或数字、或下划线或汉字,第三字符为空格的字符串 例如:11 ,2a , 1_
(3)^\d\d\d$ 匹配三个全部都为数字的字符串 例如: 123,456,789
还可以用于验证输入的字符串是否符合qq(身份证号)的验证 :
例如:^\d{8}$ 匹配8位数字的qq号,^\d{15}&匹配15位均为数字的身份证号
2.2.2 去除语气词/空评论
在统计词频的时候,可以将一些,无用的语气词,等删去
import jieba # 引用中文分词库
# 为了读取方便,我将评论一栏单独保存到一个文件里
txt = open("xinxi.txt", "r", encoding="utf-8").read() # 读取文件,注意编码
words = jieba.lcut(txt) # 中文分词
excludes = {"真的", "可以", "恭喜"} # 通过不断优化排除结果中的无用词,此处只列举几个
for word in excludes: # 排除无用词
del counts[word]
三、数据分析和信息挖掘
想要进行使数据分析的结果直观有效的呈现出来,对现有数据的可视化分析处理是必不可少的一步
可视化绘图工具:
Matplotlib
matplotlib作为python最流行的可视化模块之一, 功能强大,用法简便。对于新手而言,其上手难度低,仅需要几行代码就可以创建一个发表质量的图片,而且同时支持静态和动态图片。对于开发者而言,其丰富的子模块提供了对图片中各个细节的精确控制,可以实现高度定制的可视化效果。
使用matplotlib库绘图,原理很简单,就是下面这5步:
-
创建一个图纸 (figure)
-
在图纸上创建一个或多个绘图(plotting)区域(也叫子图,坐标系/轴,axes)
-
在plotting区域上描绘点、线等各种marker
-
为plotting添加修饰标签(绘图线上的或坐标轴上的)
-
其他各种DIY
pyechart
但下方的数据可视化则主要用到的则是pyecharts,(为啥呢?因为真的更美观)
而要想了解pyechart,首先就要知道Echart。Echarts 是一个由百度开源的数据可视化javascript库,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts诞生了。简单地说,pyecharts就是百度开源的一个强大的javascript数据可视化库Echarts的python接口。
3.1 微博评论分析
3.1.1 词频统计(生成词云图)
收集到的评论如果逐条去看的话,一定会让人眼花缭乱,所以我们何不去找一些出现频率较高的关键词,看看大家的评论都有哪些异曲同工之妙。
得到

当然,如果这还看的不够直观的话,我们可以制作词云图。
得到:

简析
- 侧重点:中国、来日可期、恭喜中国跳水梦之队、郭晶晶、全红婵,加油吧,YYDS。。。。。。
- 分析与结论:
-
中国跳水队在本次东京奥运会总共获得7金5银的优异成绩!中国跳水“梦之队”圆满收官 ,让微博上的网友们,更加肯定和认可中国跳水队的实力,中国跳水队YYDS!!!(金牌?拿来吧你!)
-
还有就是在本届奥运会上大放异彩的14岁小将全红婵,更是得到了网友们的一致追捧,同时也让我看到了00后的我们光明的未来,都要能为祖国争光,为中华民族的伟大复兴梦添砖加瓦。
-
还有就是曾经的跳水女王郭晶晶,在奥运会上担任裁判,远渡重洋,随代表队一起,她是一个辉煌,如今也看到了我们的辉煌。
-
3.1.2 评论用户男女比例分析
在提取数据的同时,还有评论用户的性别
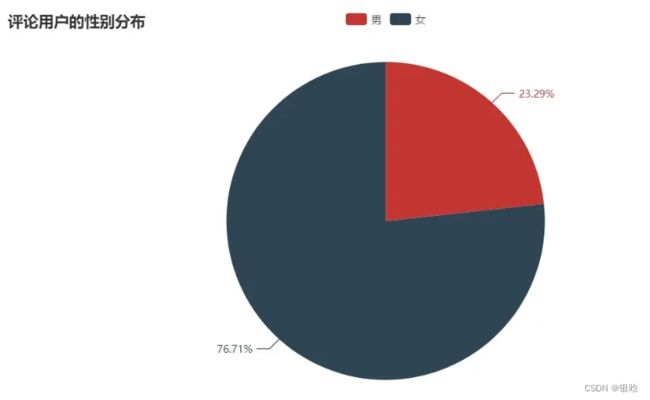
我们可以看到,女性用户的评论占比很高,有76.71%,而男性为23.29%
女性用户可能对东京奥运会跳水项目的关注度较高,
当然,也有可能是女性用户更愿意在微博发表自己的评论,为奥运健儿加油打气
3.1.3 评论的情感分析
评论者们高涨的情绪,我们也是能通过数据统计获悉哦!

(为了能够让读者直观的看到,我将微博上的评论,从消极到积极,分成1~10分,分数越高,评论的内容越积极正向)
我们可以清晰的看到,微博上的网友们,评论分数在10分的不在少数,获得高分的评论更是不在少数,可见大家都对我们的运动员抱有极大的信心和鼓励!
3.1.4 呼声较高的运动员
在东京奥运会开幕仪式中,最为瞩目的中国跳水的梦之队,一共十名奥运健儿参加比赛。
男子选手:谢思埸、王宗源、杨 健、曹 缘、陈艾森
女子选手:施廷懋、王 涵、陈芋汐、全红婵、张家齐
而我们想知道讨论他们之中谁的的呼声最热烈,就做了这个直方图

我们也是可以看到全红婵、杨 健、曹 缘、陈芋汐的呼声是比较高的。
人们对于14岁“奥运冠军”全红婵的讨论也十分激烈。这就让我想到了最近网络上很火的段子“别的00后拿奥运冠军,而你正宅在家刷手机 ”。

当然,仅供娱乐,中国的00后也正在逐渐成长,成为祖国的栋梁之材。
(可能有些用户对运动员的姓名的称呼不完整,可能对结果造成细微的影响)
3.2 B站弹幕分析
3.2.1 谁的呼声最高
当代年轻人的“二刺螈”文化繁荣的Bilibili,又称“B站”,也有为运动员加油打气的呼声哦!
在这里我们可以看陈芋汐、张家齐的讨论度是比较高的。这也与实事密切相关的。
北京时间7月27日下午,东京奥运会跳水比赛决出女子双人10米跳台金牌,而在陈艾森/曹缘组合在男子10米双人跳台项目出现失误导致丢冠之后,张家齐/陈芋汐组合顶住压力,连续5跳发挥稳定,以巨大优势击败各个对手夺得冠军,捍卫跳水梦之队在这一项目的霸主地位,实现6连冠。为中国跳水队再添1枚金牌,与此同时这也是中国队本届奥运会第8枚金牌。
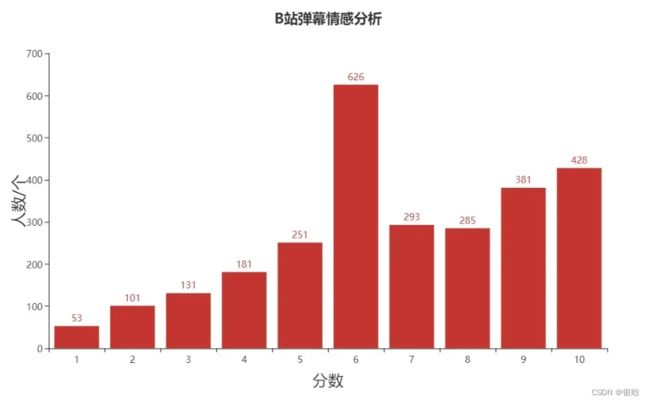
3.2.2 B站的情感得分
与微博一样,我也为弹幕文化繁荣的B站弹幕,顺便做了一下情感分析
与微博的“一枝独秀”不同的是,B站中,处于中立的6分评论数较多
但相同的是,高分分布依旧密集,且占据了绝大多数,可见大家,都是心心念念着我们祖国的奥运英雄们! ✊
3.3 B站评论分析
根据点赞数讲热门的评论进行排序,筛选出热门评论
拿到经过排序后的数据后,绘制柱状图:
根据爬取到的B站用户的个人信息,我们可以统计性别比例:

3.4 跳水梦之队的奖牌史
中国跳水队被称为梦之队,那么为什么被称为梦之队呢?是因为他们的实力超级强大,具有绝对的统治力。如图:
Tips :中国跳水队首次参加奥运会是在1984年洛杉矶奥运会。1984年至1996年亚特兰大奥运会,跳水项目只有4个单人项目,分别是男、女单人3米板,男、女单人10米台。而2000年悉尼奥运会以后,增加了4个双人项目,一共8个小项。
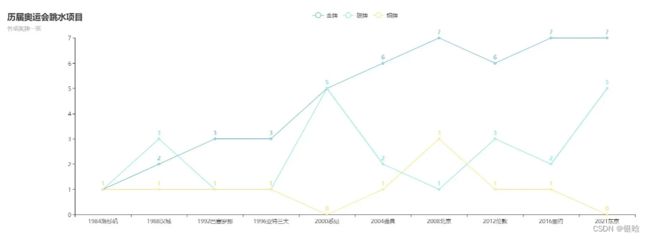
在总共的10届奥运会中,目前一共产生了64枚奥运金牌,中国跳水队一共夺得了其中的47枚,占据了其中的73.4%,非常的了不起,梦之队名称实至名归。
同时,我也希望我们的运动员能够在以后的比赛中,再创辉煌,为国争光

代码
B站弹幕爬虫代码
import requests
import json
import re
if __name__ == '__main__':
# url='https://api.bilibili.com/x/v2/dm/web/seg.so?type=1&oid=286557535&pid=458806830&segment_index=1'
url = 'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=286557535&date=2021-08-%d'
headers = {
'cookie': "your cookies"
'User-Agent': 'your UA'
}
params = {
'type': '1',
'oid': '286557535',
'date': '2021-08-09',
}
def get_response(url1):
response = requests.get(url=url1, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
data = response.text
contents = re.findall(".*?([\u4E00-\u9FA5]+).*?", data)
return contents
def save_data(content):
for i in content:
with open('./B站弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(i)
f.write('\n')
# print(i)
for i in range(10, 12):
urls = (url % i)
content = get_response(urls)
# print(content)
save_data(content)
B站评论代码
from datetime import datetime
import pandas as pd
import requests
import json
headers = {
'cookie': "cookies“,
'User-Agent': 'UA'
}
def get_comment():
url = 'https://api.bilibili.com/x/v2/reply/main?&next=%d&type=1&oid=458806830&mode=3&plat=1'
page = 1
comment_list = []
while page < 5:
urls = url % page
param = {
'callback': 'jQuery17207626243612334476_1630228955114',
'jsonp': 'jsonp',
'next': page,
'type': '1',
'oid': '458806830',
'mode': '3',
'plat': '1',
'_': '1630228982037',
}
response = requests.get(urls, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
data = response.text
data = json.loads(data)['data']['replies']
# print(data)
# try:
for dic in data:
dic_comment = {}
dic_comment['name'] = dic['member']['uname']
# print(dic['member']['uname'])
dic_comment['sex'] = dic['member']['sex']
dic_comment['comment'] = dic['content']['message']
dic_comment['like'] = dic['like']
# dic_comment['time'] = datetime.fromtimestamp(data['ctime'])
dic_comment['rpid'] = dic['rpid_str']
comment_list.append(dic_comment)
comment_list.extend(get_detail_comment(dic_comment['rpid']))
page += 1
# except Exception as page_Error:
# break
return comment_list
def get_detail_comment(rpid):
page = 1
rpid = int(rpid)
reply_list = []
while True:
url = 'https://api.bilibili.com/x/v2/reply/reply?&next=%d&type=1&oid=458806830&ps=10&root=%d'
urls = url % (page, rpid)
# print(urls)
response = requests.get(url=urls, headers=headers)
data = response.text
reply_data = json.loads(data)
reply_data=reply_data['data']['replies']
# page_count=reply_data['data']['page']['count']
# x = "复', 'sub_reply_title_text': '相关回复共0条'}},"
# reply_data = reply_data.replace(x, "")
# print(reply_data)
if reply_data is None:
break
for dic in reply_data:
dic_reply = {}
dic_reply['name'] = dic['member']['uname']
dic_reply['sex']= dic['member']['sex']
dic_reply['comment'] = dic['content']['message']
dic_reply['like'] = dic['like']
# dic_reply['time'] = datetime.fromtimestamp(reply_data['ctime'])
reply_list.append(dic_reply)
print(dic_reply['comment'])
page += 1
if page>1:
break
return reply_list
if __name__ == "__main__":
df = pd.DataFrame(get_comment())
df.to_excel('bilibili.xlsx', sheet_name='comment', index=False)
print(df.head())
print(len(df))
奥运会数据爬代码
import requests
import json
import xlwt
if __name__ =='__main__':
url = 'https://api.cntv.cn/olympic/getOlyMedals?serviceId=pcocean&itemcode=GEN-------------------------------&t=jsonp&cb=omedals1'
headers = {
'User-Agent': 'your UA'
}
response = requests.get(url=url,timeout= 30)
response.raise_for_status()
response.encoding = response.apparent_encoding
data = str.replace(response.text ,'omedals1'+ "(", "")
data = str.replace(data, ");", "")
# 解码json,转成字典
medals = json.loads(data)
medalList = medals['data']['medalsList'] #一步拿到数据
#多步详解
# dic= medals['data']
# medal_list= dic['medalsList']
# print(medalList)
wb = xlwt.Workbook(encoding='utf-8',style_compression=0)
sh = wb.add_sheet('奥运会奖牌榜',cell_overwrite_ok=True)
col=('rank','countryname','medal_count','gold',' silver','bronze')
for i in range(0,6):
sh.write(0,i,col[i])
for i in range(0,len(medalList)):
sh.write(i+1,0,medalList[i]['rank'])
sh.write(i+1,1,medalList[i]['countryname'])
sh.write(i+1,2,medalList[i]['count'])
sh.write(i+1,3,medalList[i]['gold'])
sh.write(i+1,4,medalList[i]['silver'])
sh.write(i+1,5,medalList[i]['bronze'])
sFile = 'save_dir'
wb.save(sFile)