依赖条件:需要有Hadoop,hive,zookeeper,hbase环境
映射:每一个在 Hive 表中的域都存在于 HBase 中,而在 Hive 表中不需要包含所有HBase 中的列。HBase 中的 RowKey 对应到 Hive 中为选择一个域使用 :key 来对应,列族(cf:)映射到 Hive 中的其它所有域,列为(cf:cq)
配置映射环境
一:先关闭所有服务
[root@siwen ~]# stop-hbase.sh -----关闭hbase
[root@siwen ~]# zkServer.sh stop -----关闭zookeeper
[root@siwen ~]# stop-alll.sh -----关闭hadoop
二:配置文件
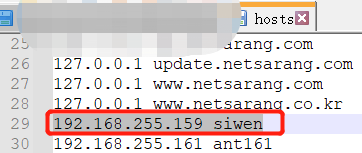
1,修改host文件:
C:\Windows\System32\drivers\etc在此目录下的hosts文件把此机器的ip和hostname加入进去
2,修改hive-site.xml
[root@siwen ~]# cd /opt/soft/hive312/conf/
[root@siwen conf]# vim ./hive-site.xml
加入下面几行
hive.zookeeper.quorum 192.168.255.159 hbase.zookeeper.quorum 192.168.255.159 hive.aux.jars.path file:///opt/soft/hive312/lib/hive-hbase-handler-3.1.2.jar,file:///opt/soft/hive312/lib/zookeeper-3.4.6.jar,file:///opt/soft/hive312/lib/hbase-client-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5-tests.jar,file:///opt/soft/hive312/lib/hbase-server-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-common-2.3.5.jar,file:///opt/soft/hive312/lib/hbase-protocol-2.3.5.jar,file:///opt/soft/hive312/lib/htrace-core-3.2.0-incubating.jar
3,拷贝jar包
①将hbase235/lib目录下所有的jar包都拷贝到hive下面
[root@siwen conf]# cp /opt/soft/hbase235/lib/* /opt/soft/hive312/lib/
是否覆盖内容的时候,可以输入n,不覆盖;或者覆盖了也没问题
②统一guava文件
[root@siwen lib]# find ../lib/guava* -------查看所有的guava文件
[root@siwen lib]# rm -rf ../lib/guava-11.0.2.jar -------删除11版本的
[root@siwen conf]# cd /opt/soft/hbase235/lib/
[root@siwen lib]# pwd
/opt/soft/hbase235/lib
[root@siwen lib]# cp /opt/soft/hive312/lib/guava-27.0-jre.jar ./ -----把hive的guava文件拷贝给hbase
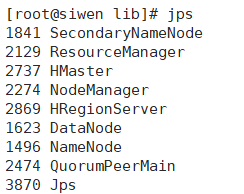
三:启动服务
#启动hadoop [root@siwen lib]# start-all.sh #启动zookeeper [root@siwen lib]# zkServer.sh start #启动hbase [root@siwen lib]# start-hbase.sh #启动hive [root@siwen lib]# nohup hive --service metastore & [root@siwen lib]# nohup hive --service hiveserver2 &
开始使用idea创建maven工程
在pom.xml 里面添加依赖
org.apache.hbase hbase-client 2.3.5 org.apache.hbase hbase-server 2.3.5
1,编写初始化方法:配置hbase信息,连接数据库
//定义一个config,用于获取配置对象
static Configuration config = null;
//获取连接
private Connection conn = null;
Admin admin = null;
@Before
public void init() throws IOException {
//配置hbase信息,连接hbase数据库
config = HBaseConfiguration.create();
config.set(HConstants.HBASE_DIR, "hdfs://192.168.255.159:9000/hbase");
config.set(HConstants.ZOOKEEPER_QUORUM, "192.168.255.159");
config.set(HConstants.CLIENT_PORT_STR, "2181");
//hbase连接工厂
conn = ConnectionFactory.createConnection(config);
//拿到admin
admin = conn.getAdmin();
}
2,编写关闭方法
@After
public void close() throws IOException {
System.out.println("执行close()方法");
if (admin!=null)
admin.close();
if (conn!=null)
conn.close();
}
3,编写创建命名空间方法
@Test
public void createNameSpace() throws IOException {
NamespaceDescriptor bigdata = NamespaceDescriptor.create("bigdata").build();
#执行创建对象
admin.createNamespace(bigdata);
}
4,编写创建表的方法
@Test
public void createTable() throws IOException {
//创建表的描述类
TableName tableName = TableName.valueOf("bigdata:student");
//获取表格描述器
HTableDescriptor desc = new HTableDescriptor(tableName);
//创建列族的描述,添加列族
HColumnDescriptor family1 = new HColumnDescriptor("info1");
HColumnDescriptor family2 = new HColumnDescriptor("info2");
desc.addFamily(family1);
desc.addFamily(family2);
admin.createTable(desc);*/
5,编写查看表结构的方法
@Test
public void getAllNamespace() throws IOException {
List tableDesc = admin.listTableDescriptorsByNamespace("bigdata".getBytes());
System.out.println(tableDesc.toString());
}
6,编写插入数据方法
@Test
public void insertData() throws IOException {
//获取表的信息
Table table = conn.getTable(TableName.valueOf("bigdata:student"));
//设置行键
Put put = new Put(Bytes.toBytes("student1"));
//设置列的标识以及列值
put.addColumn("info1".getBytes(), "name".getBytes(), "zs".getBytes());
put.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
//执行添加
table.put(put);
//使用集合添加数据
Put put2 = new Put(Bytes.toBytes("student2"));
put2.addColumn("info1".getBytes(), "name".getBytes(), "zss".getBytes());
put2.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
Put put3 = new Put(Bytes.toBytes("student3"));
put3.addColumn("info1".getBytes(), "name".getBytes(), "zsr".getBytes());
put3.addColumn("info2".getBytes(), "school".getBytes(), "xwxx".getBytes());
List list = new ArrayList<>();
list.add(put2);
list.add(put3);
table.put(list);
}
7,编写查询指定数据的方法
#查询student1的信息
@Test
public void queryData() throws IOException {
Table table = conn.getTable(TableName.valueOf("bigdata:student"));
Get get = new Get(Bytes.toBytes("student1"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名:"+Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("学校:"+Bytes.toString(value));
}

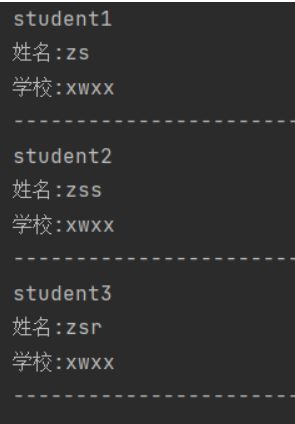
8,编写扫描数据的方法(所有数据)
@Test
public void scanData() throws IOException {
Table table = conn.getTable(TableName.valueOf("kb21:student"));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] value = result.getValue(Bytes.toBytes("info1"), Bytes.toBytes("name"));
System.out.println("姓名:"+Bytes.toString(value));
value = result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("school"));
System.out.println("学校:"+Bytes.toString(value));
System.out.println(Bytes.toString(result.getRow()));
}
}
9,编写删除表的方法
@Test
public void deleteTable() throws IOException {
//先禁用
admin.disableTable(TableName.valueOf("bigdata:student"));
//再删除
admin.deleteTable(TableName.valueOf("bigdata:student"));
}
创建外部表
---------主要外部表的字段需要和Hbase中的列形成映射
create external table student(
id string,
name string,
school string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,info1:name,info2:school")
tblproperties ("hbase.table.name"="bigdata:student");
select * from student
到此这篇关于用idea操作hbase数据库,并映射到hive的文章就介绍到这了,更多相关idea操作hbase数据库内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!