锁Hi系列----跟Java锁Say声Hi(公平锁和非公平锁、互斥锁和读写锁、可重入锁和不可重入锁、自旋锁、独占锁和共享锁、悲观锁和乐观锁、JUC下5种锁代码应用)
目录
- 1. 由 ReentrantLock 和 synchronized 实现的一系列锁
-
- 1.1 从其它等待中的线程是否按顺序获取锁的角度划分 – 公平锁与非公平锁
-
- 1.1.1 锁的公平性
- 1.1.2 锁的非公平性
- 1.1.3 ReentrantLock源码来讲解公平锁和非公平锁
- 1.1.4 公平锁与非公平锁的总结
- 1.2 从能否有多个线程持有同一把锁的角度划分 – 独占锁(互斥锁)与共享锁(读写锁)
-
- 1.2.1 独占锁的实现-互斥锁
- 1.2.2 共享锁的实现-读写锁
- 1.2.3 ReentrantLock和ReentrantReadWriteLock代码分析
- 1.3 从一个线程能否递归获取自己的锁的角度划分 – 可重入锁(递归锁)与不可重入锁
-
- 1.3.1 可重入锁(递归锁)
- 1.3.2 不可重入锁
- 1.3.3 为什么可重入锁就可以在嵌套调用时可以自动获得锁?
- 1.4 从线程获取不到锁后的表现划分-自旋锁与互斥锁
-
- 1.4.1 明确java线程阻塞的代价
- 1.4.2 互斥锁
- 1.4.3 自旋锁
-
- 1.4.3.1 自旋锁的优缺点
- 1.4.3.2 自旋锁时间阈值
- 1.4.3.3 自旋锁的开启
- 1.4.3.4 自旋锁的实现原理
- 1.4.3.5 多种排队自旋锁的实现
-
- 1.4.3.5.1 TicketLock
- 1.4.3.5.2 CLHLock
- 1.4.3.5.3 MCSLock
- 1.5 从多个线程竞争同步资源的流程细节有没有区别来划分-锁升级(无锁|偏向锁|轻量级锁|重量级锁)
-
- 1.5.1 为什么Synchronized能实现线程同步?
-
- 1.5.1.1 Java对象头
- 1.5.1.2 Monitor
- 1.5.1.3 Synchronized核心组件概念
- 1.5.1.4 Synchronized的一些总结
- 1.5.2 无锁
- 1.5.3 偏向锁
- 1.5.4 轻量级锁
- 1.5.5 重量级锁
- 1.6 从编译器优化的角度划分 – 锁消除和锁粗化
- 1.7 在不同的位置使用 synchronized-- 类锁和对象锁
- 2. 从锁的设计理念来分类 – 悲观锁、乐观锁
-
- 2.1 悲观锁
- 2.2 乐观锁
-
- 2.2.1 乐观锁的实现思想 --CAS(Compare and Swap)
-
- 2.2.1.1 版本号机制
- 2.2.1.2 CAS 算法
- 3. 数据库中常用到的锁 – 共享锁、排它锁
- 4. 由于并发问题产生的锁 – 死锁、活锁
-
- 4.1 死锁
- 4.2 活锁
- 5. 问与答
-
- 5.1 什么是读优先锁、写优先锁、公平读写锁?
- 6. java.util.concurrent.locks(JUC)下常用的几种锁(以下代码都能直接运行)
-
- 6.1 ReentrantLock
-
- 6.1.1 简单使用
- 6.1.2 高级功能-中断响应
- 6.1.3 高级功能-锁申请等待限时
- 6.1.4 高级功能-Condition条件
- 6.2 信号量(Semaphore)
- 6.3 读写锁ReentrantReadWriteLock
- 6.4 倒计时器:CountDownLatch
- 6.5 循环栅栏CyclicBarrier


1. 由 ReentrantLock 和 synchronized 实现的一系列锁
jdk1.5 的 java.util.concurrent 并发包中的 Lock 接口和 1.5 之前的 synchronized 或许是我们最常用的同步方式,这两种同步方式特别是 Lock 的 ReentrantLock 实现,经常拿来进行比较,其实他们有很多相似之处,它们在实现同步的思想上大致相同,只不过在一些细节的策略上(诸如抛出异常,是否自动释放锁)有所不同。前边说过了,本文着重讲锁的实现思想和不同锁的概念与分类,不对实现原理的细节深究,因此我在下面介绍第一类锁的时候经常讲他们放在一起来说。我们先来说一下 Lock 接口的实现之一 ReentrantLock。当我们想要创建 ReentrantLock 实例的时候,jdk 为我们提供两种重载的构造函数,如图:
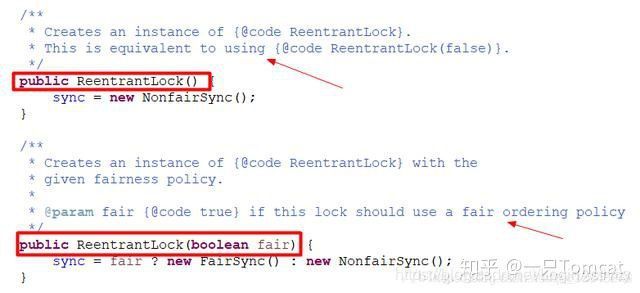
fair 是什么意思?公平的意思,没错,这就是我们要说的第一种锁。
1.1 从其它等待中的线程是否按顺序获取锁的角度划分 – 公平锁与非公平锁
我们知道,在并发环境中,多个线程需要对同一资源进行访问,同一时刻只能有一个线程能够获取到锁并进行资源访问,那么剩下的这些线程怎么办呢?这就好比食堂排队打饭的模型,最先到达食堂的人拥有最先买饭的权利,那么剩下的人就需要在第一个人后面排队,这是理想的情况,即每个人都能够买上饭。那么现实情况是,在你排队的过程中,就有个别不老实的人想走捷径,插队打饭,如果插队的这个人后面没有人制止他这种行为,他就能够顺利买上饭,如果有人制止,他就也得去队伍后面排队。
对于正常排队的人来说,没有人插队,每个人都在等待排队打饭的机会,那么这种方式对每个人来说都是公平的,先来后到嘛。这种锁也叫做公平锁。

那么假如插队的这个人成功买上饭并且在买饭的过程不管有没有人制止他,他的这种行为对正常排队的人来说都是不公平的,这在锁的世界中也叫做非公平锁。


那么我们根据上面的描述可以得出下面的结论
公平锁表示线程获取锁的顺序是按照线程加锁的顺序来分配的,即先来先得的FIFO先进先出顺序。而非公平锁就是一种获取锁的抢占机制,是随机获得锁的,和公平锁不一样的就是先来的不一定先得到锁,这个方式可能造成某些线程一直拿不到锁,结果也就是不公平的了。
在 Java 中,我们一般通过 ReetrantLock 来实现锁的公平性
我们分别通过两个例子来讲解一下锁的公平性和非公平性
1.1.1 锁的公平性
public class MyFairLock extends Thread{
private ReentrantLock lock = new ReentrantLock(true);
public void fairLock(){
try {
lock.lock();
System.out.println(Thread.currentThread().getName() + "正在持有锁");
}finally {
System.out.println(Thread.currentThread().getName() + "释放了锁");
lock.unlock();
}
}
public static void main(String[] args) {
MyFairLock myFairLock = new MyFairLock();
Runnable runnable = () -> {
System.out.println(Thread.currentThread().getName() + "启动");
myFairLock.fairLock();
};
Thread[] thread = new Thread[10];
for(int i = 0;i < 10;i++){
thread[i] = new Thread(runnable);
}
for(int i = 0;i < 10;i++){
thread[i].start();
}
}
}
我们创建了一个 ReetrantLock,并给构造函数传了一个 true,我们可以查看 ReetrantLock 的构造函数
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
根据 JavaDoc 的注释可知,如果是 true 的话,那么就会创建一个 ReentrantLock 的公平锁,然后并创建一个 FairSync ,FairSync 其实是一个 Sync 的内部类,它的主要作用是同步对象以获取公平锁。

而 Sync 是 ReentrantLock 中的内部类,Sync 继承 AbstractQueuedSynchronizer 类,AbstractQueuedSynchronizer 就是我们常说的 AQS ,它是 JUC(java.util.concurrent) 中最重要的一个类,通过它来实现独占锁和共享锁。
abstract static class Sync extends AbstractQueuedSynchronizer {...}
也就是说,我们把 fair 参数设置为 true 之后,就可以实现一个公平锁了,是这样吗?我们回到示例代码,我们可以执行一下这段代码,它的输出是顺序获取的(碍于篇幅的原因,这里就暂不贴出了),也就是说我们创建了一个公平锁
1.1.2 锁的非公平性
与公平性相对的就是非公平性,我们通过设置 fair 参数为 true,便实现了一个公平锁,与之相对的,我们把 fair 参数设置为 false,是不是就是非公平锁了?用事实证明一下
private ReentrantLock lock = new ReentrantLock(false);
其他代码不变,我们执行一下看看输出(部分输出)

可以看到,线程的启动并没有按顺序获取,可以看出非公平锁对锁的获取是乱序的,即有一个抢占锁的过程。也就是说,我们把 fair 参数设置为 false 便实现了一个非公平锁。
1.1.3 ReentrantLock源码来讲解公平锁和非公平锁
ReentrantLock 是一把可重入锁,也是一把互斥锁,它具有与 synchronized 相同的方法和监视器锁的语义,但是它比 synchronized 有更多可扩展的功能。
ReentrantLock 的可重入性是指它可以由上次成功锁定但还未解锁的线程拥有。当只有一个线程尝试加锁时,该线程调用 lock() 方法会立刻返回成功并直接获取锁。如果当前线程已经拥有这把锁,这个方法会立刻返回。可以使用 isHeldByCurrentThread 和 getHoldCount 进行检查。
这个类的构造函数接受可选择的 fairness 参数,当 fairness 设置为 true 时,在多线程争夺尝试加锁时,锁倾向于对等待时间最长的线程访问,这也是公平性的一种体现。否则,锁不能保证每个线程的访问顺序,也就是非公平锁。与使用默认设置的程序相比,使用许多线程访问的公平锁的程序可能会显示较低的总体吞吐量(即较慢;通常要慢得多)。但是获取锁并保证线程不会饥饿的次数比较小。无论如何请注意:锁的公平性不能保证线程调度的公平性。因此,使用公平锁的多线程之一可能会连续多次获得它,而其他活动线程没有进行且当前未持有该锁。这也是互斥性 的一种体现。
也要注意的 tryLock() 方法不支持公平性。如果锁是可以获取的,那么即使其他线程等待,它仍然能够返回成功。
推荐使用下面的代码来进行加锁和解锁
class MyFairLock {
private final ReentrantLock lock = new ReentrantLock();
public void m() {
lock.lock();
try {
// ...
} finally {
lock.unlock()
}
}
}
ReentrantLock 锁通过同一线程最多支持2147483647个递归锁。 尝试超过此限制会导致锁定方法引发错误。
我们在上面的简述中提到,ReentrantLock 是可以实现锁的公平性的,那么原理是什么呢?下面我们通过其源码来了解一下 ReentrantLock 是如何实现锁的公平性的

根据代码可知,ReentrantLock里面有一个内部类Sync,Sync继承AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在Sync中实现的。它有公平锁FairSync和非公平锁NonfairSync两个子类。ReentrantLock默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
跟踪其源码发现,调用 Lock.lock() 方法其实是调用了 sync 的内部的方法
abstract void lock();
而 sync 是最基础的同步控制 Lock 的类,它有公平锁和非公平锁的实现。它继承 AbstractQueuedSynchronizer 即 使用 AQS 状态代表锁持有的数量。
lock 是抽象方法是需要被子类实现的,而继承了 AQS 的类主要有

我们可以看到,所有实现了 AQS 的类都位于 JUC 包下,主要有五类:ReentrantLock、ReentrantReadWriteLock、Semaphore、CountDownLatch 和 ThreadPoolExecutor,其中 ReentrantLock、ReentrantReadWriteLock、Semaphore 都可以实现公平锁和非公平锁。
下面是公平锁 FairSync 的继承关系

非公平锁的NonFairSync 的继承关系

由继承图可以看到,两个类的继承关系都是相同的,我们从源码发现,公平锁和非公平锁的实现就是下面这段代码的区别

通过上图中的源代码对比,我们可以明显的看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()。

hasQueuedPredecessors() 也是 AQS 中的方法,它主要是用来 查询是否有任何线程在等待获取锁的时间比当前线程长,也就是说每个等待线程都是在一个队列中,此方法就是判断队列中在当前线程获取锁时,是否有等待锁时间比自己还长的队列,如果当前线程之前有排队的线程,返回 true,如果当前线程位于队列的开头或队列为空,返回 false。
综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。
1.1.4 公平锁与非公平锁的总结
- 公平锁的好处是等待锁的线程不会饿死,但是整体效率相对低一些;非公平锁的好处是整体效率相对高一些,但是有些线程可能会饿死或者说很早就在等待锁,但要等很久才会获得锁。其中的原因是公平锁是严格按照请求所的顺序来排队获得锁的,而非公平锁时可以抢占的,即如果在某个时刻有线程需要获取锁,而这个时候刚好锁可用,那么这个线程会直接抢占,而这时阻塞在等待队列的线程则不会被唤醒。
- 在 java 中,公平锁可以通过 new ReentrantLock (true) 来实现;非公平锁可以通过 new ReentrantLock (false) 或者默认构造函数 new ReentrantLock () 实现。
- synchronized 是非公平锁,并且它无法实现公平锁。
1.2 从能否有多个线程持有同一把锁的角度划分 – 独占锁(互斥锁)与共享锁(读写锁)
独占锁是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。JDK中的synchronized和java.util.concurrent(JUC)包中Lock的实现类就是独占锁。
共享锁是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。在 JDK 中 ReentrantReadWriteLock 就是一种共享锁。
1.2.1 独占锁的实现-互斥锁
互斥锁是独占锁的一种常规实现,是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。互斥锁一次只能一个线程拥有互斥锁,其他线程只有等待。
1.2.2 共享锁的实现-读写锁
读写锁是共享锁的一种具体实现。读写锁管理一组锁,一个是只读的锁,一个是写锁。
读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。读写锁相比于互斥锁并发程度更高,每次只有一个写线程,但是同时可以有多个线程并发读。在 JDK 中定义了一个读写锁的接口:ReadWriteLock,ReentrantReadWriteLock 实现了ReadWriteLock接口,在 mysql 的事务中大量使用
1.2.3 ReentrantLock和ReentrantReadWriteLock代码分析
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
下图为ReentrantReadWriteLock的部分源码:

我们看到ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,由词知意,一个读锁一个写锁,合称“读写锁”。再进一步观察可以发现ReadLock和WriteLock是靠内部类Sync实现的锁。Sync是AQS的一个子类,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在ReentrantReadWriteLock里面,读锁和写锁的锁主体都是Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
那读锁和写锁的具体加锁方式有什么区别呢?在了解源码之前我们需要回顾一下其他知识。 在最开始提及AQS的时候我们也提到了state字段(int类型,32位),该字段用来描述有多少线程获持有锁。
在独享锁中这个值通常是0或者1(如果是重入锁的话state值就是重入的次数),在共享锁中state就是持有锁的数量。但是在ReentrantReadWriteLock中有读、写两把锁,所以需要在一个整型变量state上分别描述读锁和写锁的数量(或者也可以叫状态)。于是将state变量“按位切割”切分成了两个部分,高16位表示读锁状态(读锁个数),低16位表示写锁状态(写锁个数)。如下图所示:

了解了概念之后我们再来看代码,先看写锁的加锁源码:
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState(); // 取到当前锁的个数
int w = exclusiveCount(c); // 取写锁的个数w
if (c != 0) { // 如果已经有线程持有了锁(c!=0)
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread()) // 如果写线程数(w)为0(换言之存在读锁) 或者持有锁的线程不是当前线程就返回失败
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT) // 如果写入锁的数量大于最大数(65535,2的16次方-1)就抛出一个Error。
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) // 如果当且写线程数为0,并且当前线程需要阻塞那么就返回失败;或者如果通过CAS增加写线程数失败也返回失败。
return false;
setExclusiveOwnerThread(current); // 如果c=0,w=0或者c>0,w>0(重入),则设置当前线程或锁的拥有者
return true;
}
- 这段代码首先取到当前锁的个数c,然后再通过c来获取写锁的个数w。因为写锁是低16位,所以取低16位的最大值与当前的c做与运算( int w = exclusiveCount©; ),高16位和0与运算后是0,剩下的就是低位运算的值,同时也是持有写锁的线程数目。
- 在取到写锁线程的数目后,首先判断是否已经有线程持有了锁。如果已经有线程持有了锁(c!=0),则查看当前写锁线程的数目,如果写线程数为0(即此时存在读锁)或者持有锁的线程不是当前线程就返回失败(涉及到公平锁和非公平锁的实现)。
- 如果写入锁的数量大于最大数(65535,2的16次方-1)就抛出一个Error。
- 如果当且写线程数为0(那么读线程也应该为0,因为上面已经处理c!=0的情况),并且当前线程需要阻塞那么就返回失败;如果通过CAS增加写线程数失败也返回失败。
- 如果c=0,w=0或者c>0,w>0(重入),则设置当前线程或锁的拥有者,返回成功!
tryAcquire()除了重入条件(当前线程为获取了写锁的线程)之外,增加了一个读锁是否存在的判断。如果存在读锁,则写锁不能被获取,原因在于:必须确保写锁的操作对读锁可见,如果允许读锁在已被获取的情况下对写锁的获取,那么正在运行的其他读线程就无法感知到当前写线程的操作。
因此,只有等待其他读线程都释放了读锁,写锁才能被当前线程获取,而写锁一旦被获取,则其他读写线程的后续访问均被阻塞。写锁的释放与ReentrantLock的释放过程基本类似,每次释放均减少写状态,当写状态为0时表示写锁已被释放,然后等待的读写线程才能够继续访问读写锁,同时前次写线程的修改对后续的读写线程可见。
接着是读锁的代码:
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1; // 如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
可以看到在tryAcquireShared(int unused)方法中,如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠CAS保证)增加读状态,成功获取读锁。读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是“1<<16”。所以读写锁才能实现读读的过程共享,而读写、写读、写写的过程互斥。
此时,我们再回头看一下互斥锁ReentrantLock中公平锁和非公平锁的加锁源码:

我们发现在ReentrantLock虽然有公平锁和非公平锁两种,但是它们添加的都是独享锁。根据源码所示,当某一个线程调用lock方法获取锁时,如果同步资源没有被其他线程锁住,那么当前线程在使用CAS更新state成功后就会成功抢占该资源。而如果公共资源被占用且不是被当前线程占用,那么就会加锁失败。所以可以确定ReentrantLock无论读操作还是写操作,添加的锁都是都是独享锁。
1.3 从一个线程能否递归获取自己的锁的角度划分 – 可重入锁(递归锁)与不可重入锁
1.3.1 可重入锁(递归锁)
我们知道,一条线程若想进入一个被上锁的区域,首先要判断这个区域的锁是否已经被某条线程所持有。如果锁正在被持有那么线程将等待锁的释放,但是这就引发了一个问题,我们来看这样一段简单的代码:
public class ReentrantDemo {
private Lock mLock;
public ReentrantDemo(Lock mLock) {
this.mLock = mLock;
}
public void outer() {
mLock.lock();
inner();
mLock.unlock();
}
public void inner() {
mLock.lock();
// do something
mLock.unlock();
}
}
当线程 A 调用 outer () 方法的时候,会进入使用传进来 mlock 实例来进行 mlock.lock () 加锁,此时 outer () 方法中的这片区域的锁 mlock 就被线程 A 持有了,当线程 B 想要调用 outer () 方法时会先判断,发现这个 mlock 这把锁被其它线程持有了,因此进入等待状态。我们现在不考虑线程 B,单说线程 A,线程 A 进入 outer () 方法后,它还要调用 inner () 方法,并且 inner () 方法中使用的也是 mlock () 这把锁,于是接下来有趣的事情就来了。按正常步骤来说,线程 A 先判断 mlock 这把锁是否已经被持有了,判断后发现这把锁确实被持有了,但是可笑的是,是 A 自己持有的。那你说 A 能否在加了 mlock 锁的 outer () 方法中调用加了 mlock 锁的 inner 方法呢?答案是如果我们使用的是可重入锁,那么递归调用自己持有的那把锁的时候,是允许进入的。
对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁。对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。
以 synchronized 为例,看一下下面的代码:

上面的代码中 methodA 调用 methodB,如果一个线程调用methodA 已经获取了锁再去调用 methodB 就不需要再次获取锁了,这就是可重入锁的特性。如果不是可重入锁的话,mehtodB 可能不会被当前线程执行,可能造成死锁。
1.3.2 不可重入锁
下面这段代码演示了不可重入锁:
public class Lock{
private boolean isLocked = false;
public synchronized void lock() throws InterruptedException{
while(isLocked){
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}
可以看到,当 isLocked 被设置为 true 后,在线程调用 unlock () 解锁之前不管线程是否已经获得锁,都只能 wait ()。
1.3.3 为什么可重入锁就可以在嵌套调用时可以自动获得锁?
通过重入锁ReentrantLock以及非可重入锁NonReentrantLock的源码来对比分析一下为什么非可重入锁在重复调用同步资源时会出现死锁。
首先ReentrantLock和NonReentrantLock都继承父类AQS,其父类AQS中维护了一个同步状态status来计数重入次数,status初始值为0。
当线程尝试获取锁时,可重入锁先尝试获取并更新status值,如果status == 0表示没有其他线程在执行同步代码,则把status置为1,当前线程开始执行。如果status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁。而非可重入锁是直接去获取并尝试更新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞。
释放锁时,可重入锁同样先获取当前status的值,在当前线程是持有锁的线程的前提下。如果status-1 == 0,则表示当前线程所有重复获取锁的操作都已经执行完毕,然后该线程才会真正释放锁。而非可重入锁则是在确定当前线程是持有锁的线程之后,直接将status置为0,将锁释放。

同样的道理,synchronized的可重入靠的是monitor的+1-1。
1.4 从线程获取不到锁后的表现划分-自旋锁与互斥锁
互斥锁和自旋锁是最底层的两种锁,其他的很多锁都是基于他们的实现。当线程 A 获取到锁后,线程 B 再去获取锁,有两种处理方式,第一种是线程 B 循环的去尝试获取锁,直到获取成功为止即自旋锁,另一种是线程 B 放弃获取锁,在锁空闲时,等待被唤醒,即互斥锁。
1.4.1 明确java线程阻塞的代价
java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在户态与核心态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
- 如果线程状态切换是一个高频操作时,这将会消耗很多CPU处理时间;
- 如果对于那些需要同步的简单的代码块,获取锁挂起操作消耗的时间比用户代码执行的时间还要长,这种同步策略显然非常糟糕的。
1.4.2 互斥锁
互斥锁会释放当前线程的 cpu,导致加锁的代码阻塞,直到线程再次被唤醒。互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,存在一定的性能开销。
(1) 当线程加锁失败,内核会把线程的状态由“运行”设置为“睡眠”,让出 cpu;
(2) 当锁空闲时,内核唤醒线程,状态设置为“就绪”,获取 cpu 执行;
1.4.3 自旋锁
在介绍自旋锁前,我们需要介绍一些前提知识来帮助大家明白自旋锁的概念。
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
1.4.3.1 自旋锁的优缺点
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用cpu做无用功,占着XX不XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要cup的线程又不能获取到cpu,造成cpu的浪费。所以这种情况下我们要关闭自旋锁;
1.4.3.2 自旋锁时间阈值
自旋锁的目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。但是如何去选择自旋的执行时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用CPU资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!
JVM对于自旋周期的选择,jdk1.5这个限度是一定的写死的,在1.6引入了适应性自旋锁,适应性自旋锁意味着自旋的时间不在是固定的了,而是由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间,同时JVM还针对当前CPU的负荷情况做了较多的优化
- 如果平均负载小于CPUs则一直自旋
- 如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞
- 如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞
- 如果CPU处于节电模式则停止自旋
- 自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差)
- 自旋时会适当放弃线程优先级之间的差异
1.4.3.3 自旋锁的开启
JDK1.6中-XX:+UseSpinning开启;
-XX:PreBlockSpin=10 为自旋次数;
JDK1.7后,去掉此参数,由jvm控制;
1.4.3.4 自旋锁的实现原理
自旋锁的实现原理同样也是CAS,AtomicInteger中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
自旋锁会自用户态由应用程序完成,不涉及用户态到内核态的转化,没有线程上下文切换,性能相对较好。自旋锁加锁过程:
(1) 查看锁的状态;
(2) 锁空闲,获取锁,否则执行(1);
自旋锁会利用 cpu 一直工作直到获取到锁,中间不会释放 cpu,但如果被锁住的代码执行时间较长,导致 cpu 空转,浪费资源。
自旋锁是指线程在没有获得锁时不是被直接挂起,而是执行一个忙循环,这个忙循环就是所谓的自旋。
自旋锁的目的是为了减少线程被挂起的几率,因为线程的挂起和唤醒也都是耗资源的操作。
如果锁被另一个线程占用的时间比较长,即使自旋了之后当前线程还是会被挂起,忙循环就会变成浪费系统资源的操作,反而降低了整体性能。因此自旋锁是不适应锁占用时间长的并发情况的。
在 Java 中,AtomicInteger 类有自旋的操作,我们看一下代码:

CAS 操作如果失败就会一直循环获取当前 value 值然后重试。
自旋锁在JDK1.4.2中引入,使用-XX:+UseSpinning来开启。JDK 6中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
下面我们用Java 代码来实现一个简单的自旋锁
public class SpinLockTest {
private AtomicBoolean available = new AtomicBoolean(false);
public void lock(){
// 循环检测尝试获取锁
while (!tryLock()){
// doSomething...
}
}
public boolean tryLock(){
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false,true);
}
public void unLock(){
if(!available.compareAndSet(true,false)){
throw new RuntimeException("释放锁失败");
}
}
}
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的 SpinlockTest,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成线程饥饿。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们分别对这几种锁做个大致的介绍。
1.4.3.5 多种排队自旋锁的实现
1.4.3.5.1 TicketLock
在计算机科学领域中,TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,而不用每次都进行排队。通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),先到的人需要在这个机器上取出自己现在排队的号码,这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。它增加了锁的公平性,其设计原则如下:TicketLock 中有两个 int 类型的数值,开始都是0,第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。可能有点模糊不清,简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。现在应该明白一些了吧。
当叫号叫到你的时候,不能有相同的号码同时办业务,必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,那么就轮到你去办业务,否则只能继续等待。上面这个流程的关键点在于,每个办业务的人在办完业务之后,他必须丢弃自己的号码,叫号机才能继续叫到下面的人,如果这个人没有丢弃这个号码,那么其他人只能继续等待。下面来实现一下这个票据排队方案
public class TicketLock {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
// 获取锁:如果获取成功,返回当前线程的排队号
public int lock(){
int currentTicketNum = dueueNum.incrementAndGet();
while (currentTicketNum != queueNum.get()){
// doSomething...
}
return currentTicketNum;
}
// 释放锁:传入当前排队的号码
public void unLock(int ticketNum){
queueNum.compareAndSet(ticketNum,ticketNum + 1);
}
}
每次叫号机在叫号的时候,都会判断自己是不是被叫的号,并且每个人在办完业务的时候,叫号机根据在当前号码的基础上 + 1,让队列继续往前走。
但是上面这个设计是有问题的,因为获得自己的号码之后,是可以对号码进行更改的,这就造成系统紊乱,锁不能及时释放。这时候就需要有一个能确保每个人按会着自己号码排队办业务的角色,在得知这一点之后,我们重新设计一下这个逻辑
public class TicketLock2 {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger();
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger();
private ThreadLocal<Integer> ticketLocal = new ThreadLocal<>();
public void lock(){
int currentTicketNum = dueueNum.incrementAndGet();
// 获取锁的时候,将当前线程的排队号保存起来
ticketLocal.set(currentTicketNum);
while (currentTicketNum != queueNum.get()){
// doSomething...
}
}
// 释放锁:从排队缓冲池中取
public void unLock(){
Integer currentTicket = ticketLocal.get();
queueNum.compareAndSet(currentTicket,currentTicket + 1);
}
}
这次就不再需要返回值,办业务的时候,要将当前的这一个号码缓存起来,在办完业务后,需要释放缓存的这条票据。
缺点
TicketLock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量queueNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
为了解决这个问题,MCSLock 和 CLHLock 应运而生。
1.4.3.5.2 CLHLock
上面说到TicketLock 是基于队列的,那么 CLHLock 就是基于链表设计的,CLH的发明人是:Craig,Landin and Hagersten,用它们各自的字母开头命名。CLH 是一种基于链表的可扩展,高性能,公平的自旋锁,申请线程只能在本地变量上自旋,它会不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
public class CLHLock {
public static class CLHNode{
private volatile boolean isLocked = true;
}
// 尾部节点
private volatile CLHNode tail;
private static final ThreadLocal<CLHNode> LOCAL = new ThreadLocal<>();
private static final AtomicReferenceFieldUpdater<CLHLock,CLHNode> UPDATER =
AtomicReferenceFieldUpdater.newUpdater(CLHLock.class,CLHNode.class,"tail");
public void lock(){
// 新建节点并将节点与当前线程保存起来
CLHNode node = new CLHNode();
LOCAL.set(node);
// 将新建的节点设置为尾部节点,并返回旧的节点(原子操作),这里旧的节点实际上就是当前节点的前驱节点
CLHNode preNode = UPDATER.getAndSet(this,node);
if(preNode != null){
// 前驱节点不为null表示当锁被其他线程占用,通过不断轮询判断前驱节点的锁标志位等待前驱节点释放锁
while (preNode.isLocked){
}
preNode = null;
LOCAL.set(node);
}
// 如果不存在前驱节点,表示该锁没有被其他线程占用,则当前线程获得锁
}
public void unlock() {
// 获取当前线程对应的节点
CLHNode node = LOCAL.get();
// 如果tail节点等于node,则将tail节点更新为null,同时将node的lock状态职位false,表示当前线程释放了锁
if (!UPDATER.compareAndSet(this, node, null)) {
node.isLocked = false;
}
node = null;
}
}
1.4.3.5.3 MCSLock
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。MCS 来自于其发明人名字的首字母: John Mellor-Crummey 和 Michael Scott。
public class MCSLock {
public static class MCSNode {
volatile MCSNode next;
volatile boolean isLocked = true;
}
private static final ThreadLocal<MCSNode> NODE = new ThreadLocal<>();
// 队列
@SuppressWarnings("unused")
private volatile MCSNode queue;
private static final AtomicReferenceFieldUpdater<MCSLock,MCSNode> UPDATE =
AtomicReferenceFieldUpdater.newUpdater(MCSLock.class,MCSNode.class,"queue");
public void lock(){
// 创建节点并保存到ThreadLocal中
MCSNode currentNode = new MCSNode();
NODE.set(currentNode);
// 将queue设置为当前节点,并且返回之前的节点
MCSNode preNode = UPDATE.getAndSet(this, currentNode);
if (preNode != null) {
// 如果之前节点不为null,表示锁已经被其他线程持有
preNode.next = currentNode;
// 循环判断,直到当前节点的锁标志位为false
while (currentNode.isLocked) {
}
}
}
public void unlock() {
MCSNode currentNode = NODE.get();
// next为null表示没有正在等待获取锁的线程
if (currentNode.next == null) {
// 更新状态并设置queue为null
if (UPDATE.compareAndSet(this, currentNode, null)) {
// 如果成功了,表示queue==currentNode,即当前节点后面没有节点了
return;
} else {
// 如果不成功,表示queue!=currentNode,即当前节点后面多了一个节点,表示有线程在等待
// 如果当前节点的后续节点为null,则需要等待其不为null(参考加锁方法)
while (currentNode.next == null) {
}
}
} else {
// 如果不为null,表示有线程在等待获取锁,此时将等待线程对应的节点锁状态更新为false,同时将当前线程的后继节点设为null
currentNode.next.isLocked = false;
currentNode.next = null;
}
}
}
CLHLock 和 MCSLock
- 都是基于链表,不同的是CLHLock是基于隐式链表,没有真正的后续节点属性,MCSLock是显示链表,有一个指向后续节点的属性。
- 将获取锁的线程状态借助节点(node)保存,每个线程都有一份独立的节点,这样就解决了TicketLock多处理器缓存同步的问题。
1.5 从多个线程竞争同步资源的流程细节有没有区别来划分-锁升级(无锁|偏向锁|轻量级锁|重量级锁)
JDK1.6 为了提升性能减少获得锁和释放锁所带来的消耗,引入了4种锁的状态:无锁、偏向锁、轻量级锁和重量级锁,它会随着多线程的竞争情况逐渐升级,但不能降级。这四种锁是指锁的状态,专门针对synchronized的。
在介绍这四种锁状态之前还需要介绍一些额外的知识。
1.5.1 为什么Synchronized能实现线程同步?
在回答这个问题之前我们需要了解两个重要的概念:“Java对象头”、“Monitor”。
1.5.1.1 Java对象头
synchronized是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在Java对象头里的,而Java对象头又是什么呢?
我们以Hotspot虚拟机为例,Hotspot的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
-
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
-
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
在32位虚拟机和64位虚拟机的 Mark Word 所占用的字节大小不一样,32位虚拟机的 Mark Word 和 class Pointer 分别占用 32bits 的字节,而 64位虚拟机的 Mark Word 和 class Pointer 占用了64bits 的字节,下面我们以 32位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的


用中文翻译过来就是

- 无状态也就是无锁的时候,对象头开辟 25bit 的空间用来存储对象的 hashcode ,4bit 用于存放分代年龄,1bit 用来存放是否偏向锁的标识位,2bit 用来存放锁标识位为01
- 偏向锁 中划分更细,还是开辟25bit 的空间,其中23bit 用来存放线程ID,2bit 用来存放 epoch,4bit 存放分代年龄,1bit 存放是否偏向锁标识, 0表示无锁,1表示偏向锁,锁的标识位还是01
- 轻量级锁中直接开辟 30bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为00
- 重量级锁中和轻量级锁一样,30bit 的空间用来存放指向重量级锁的指针,2bit 存放锁的标识位,为11
- GC标记开辟30bit 的内存空间却没有占用,2bit 空间存放锁标志位为11。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
关于为什么这么分配的内存,我们可以从 OpenJDK 中的markOop.hpp类中的枚举窥出端倪

来解释一下
- age_bits 就是我们说的分代回收的标识,占用4字节
- lock_bits 是锁的标志位,占用2个字节
- biased_lock_bits 是是否偏向锁的标识,占用1个字节
- max_hash_bits 是针对无锁计算的hashcode 占用字节数量,如果是32位虚拟机,就是 32 - 4 - 2 -1 = 25 byte,如果是64 位虚拟机,64 - 4 - 2 - 1 = 57 byte,但是会有 25 字节未使用,所以64位的 hashcode 占用 31 byte
- hash_bits 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取31,否则取真实的字节数
- cms_bits 我觉得应该是不是64位虚拟机就占用 0 byte,是64位就占用 1byte
- epoch_bits 就是 epoch 所占用的字节大小,2字节。
synchronized用的锁记录是存在Java对象头里的。
JVM基于进入和退出 Monitor 对象来实现方法同步和代码块同步。代码块同步是使用 monitorenter 和 monitorexit 指令实现的,monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处。任何对象都有一个 monitor 与之关联,当且一个 monitor 被持有后,它将处于锁定状态。
根据虚拟机规范的要求,在执行 monitorenter 指令时,首先要去尝试获取对象的锁,如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1,相应地,在执行 monitorexit 指令时会将锁计数器减1,当计数器被减到0时,锁就释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
1.5.1.2 Monitor
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。
Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁:锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。锁可以升级但不能降级。
所以锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking=false来禁用偏向锁。
所以目前锁一共有4种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
通过上面的介绍,我们对synchronized的加锁机制以及相关知识有了一个了解,那么下面我们给出四种锁状态对应的的Mark Word内容,然后再分别讲解四种锁状态的思路以及特点:

先来个大体的流程图来感受一下这个过程,然后下面我们再分开来说

1.5.1.3 Synchronized核心组件概念

- Wait Set:那些调用 wait 方法被阻塞的线程被放置在这里;
- Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中;
- Entry List:Contention List 中那些有资格成为候选资源的线程被移动到 Entry List 中;
- OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为 OnDeck;
- Owner:当前已经获取到所资源的线程被称为 Owner;
- !Owner:当前释放锁的线程。
1.5.1.4 Synchronized的一些总结
-
JVM 每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,ContentionList 会被大量的并发线程进行 CAS 访问,为了降低对尾部元素的竞争,JVM 会将一部分线程移动到 EntryList 中作为候选竞争线程。
-
Owner 线程会在 unlock 时,将 ContentionList 中的部分线程迁移到 EntryList 中,并指定EntryList 中的某个线程为 OnDeck 线程(一般是最先进去的那个线程)。
-
Owner 线程并不直接把锁传递给 OnDeck 线程,而是把锁竞争的权利交给 OnDeck,OnDeck需要重新竞争锁。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在JVM 中,也把这种选择行为称之为“竞争切换”。
-
OnDeck 线程获取到锁资源后会变为 Owner 线程,而没有得到锁资源的仍然停留在 EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者 notifyAll 唤醒,会重新进去EntryList 中。
-
处于 ContentionList、EntryList、WaitSet 中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux 内核下采用 pthread_mutex_lock 内核函数实现的)。
-
Synchronized 是非公平锁。 Synchronized 在线程进入 ContentionList 时,等待的线程会先尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占 OnDeck 线程的锁资源。
-
每个对象都有个 monitor 对象,加锁就是在竞争 monitor 对象,代码块加锁是在前后分别加上 monitorenter 和 monitorexit 指令来实现的,方法加锁是通过一个标记位来判断的
-
synchronized 是一个重量级操作,需要调用操作系统相关接口,性能是低效的,有可能给线程加锁消耗的时间比有用操作消耗的时间更多。
-
Java1.6,synchronized 进行了很多的优化,有适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,效率有了本质上的提高。在之后推出的 Java1.7 与 1.8 中,均对该关键字的实现机理做了优化。引入了偏向锁和轻量级锁。都是在对象头中有标记位,不需要经过操作系统加锁。
-
锁可以从偏向锁升级到轻量级锁,再升级到重量级锁。这种升级过程叫做锁膨胀;
-
JDK 1.6 中默认是开启偏向锁和轻量级锁,可以通过
-XX:-UseBiasedLocking来禁用偏向锁。
1.5.2 无锁
无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。

无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。上面我们介绍的CAS原理及应用即是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
1.5.3 偏向锁
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,还存在锁由同一线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。
-
偏向锁在Java 6 和Java 7 里是默认启用的。由于偏向锁是为了在只有一个线程执行同步块时提高性能,如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
-
偏向锁的对象头中有一个被称为 epoch 的值,它作为偏差有效性的时间戳。

可以从对象头的分配中看到,偏向锁要比无锁多了线程ID 和 epoch,下面我们就来描述一下偏向锁的获取过程
-
首先线程访问同步代码块,会通过检查对象头 Mark Word 的锁标志位判断目前锁的状态,如果是 01,说明就是无锁或者偏向锁,然后再根据是否偏向锁 的标示判断是无锁还是偏向锁,如果是无锁情况下,执行下一步
-
线程使用 CAS 操作来尝试对对象加锁,如果使用 CAS 替换 ThreadID 成功,就说明是第一次上锁,那么当前线程就会获得对象的偏向锁,此时会在对象头的 Mark Word 中记录当前线程 ID 和获取锁的时间 epoch 等信息,然后执行同步代码块。
-
等到下一次线程在进入和退出同步代码块时就不需要进行 CAS 操作进行加锁和解锁,只需要简单判断一下对象头的 Mark Word 中是否存储着指向当前线程的线程ID,判断的标志当然是根据锁的标志位来判断的。
如果用流程图来表示的话就是下面这样

1.5.4 轻量级锁
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。

- 紧接着上一步,如果 CAS 操作替换 ThreadID 没有获取成功,执行下一步
- 如果使用 CAS 操作替换 ThreadID 失败(这时候就切换到另外一个线程的角度)说明该资源已被同步访问过,这时候就会执行锁的撤销操作,撤销偏向锁,然后等原持有偏向锁的线程到达全局安全点(SafePoint)时,会暂停原持有偏向锁的线程,然后会检查原持有偏向锁的状态,如果已经退出同步,就会唤醒持有偏向锁的线程,执行下一步
全局安全点(Safe Point):全局安全点的理解会涉及到 C 语言底层的一些知识,这里简单理解 SafePoint 是 Java
代码中的一个线程可能暂停执行的位置。
- 检查对象头中的 Mark Word 记录的是否是当前线程 ID,如果是,执行同步代码,如果不是,执行偏向锁获取流程 的第2步。
如果用流程表示的话就是下面这样(已经包含偏向锁的获取)

1.5.5 重量级锁
如果线程并发进一步加剧,线程的自旋超过了一定次数,或者一个线程持有锁,一个线程在自旋,又来了第三个线程访问时(反正就是竞争继续加大了),轻量级锁就会膨胀为重量级锁,重量级锁会使除了此时拥有锁的线程以外的线程都阻塞。
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。

升级到重量级锁其实就是互斥锁了,一个线程拿到锁,其余线程都会处于阻塞等待状态。
接着上面由偏向锁升级为轻量级锁,执行下一步
-
会在原持有偏向锁的线程的栈中分配锁记录,将对象头中的 Mark Word 拷贝到原持有偏向锁线程的记录中,然后原持有偏向锁的线程获得轻量级锁,然后唤醒原持有偏向锁的线程,从安全点处继续执行,执行完毕后,执行下一步,当前线程执行第4步
-
执行完毕后,开始轻量级解锁操作,解锁需要判断两个条件
- 判断对象头中的 Mark Word 中锁记录指针是否指向当前栈中记录的指针
- 拷贝在当前线程锁记录的 Mark Word 信息是否与对象头中的 Mark Word 一致。
-
如果上面两个判断条件都符合的话,就进行锁释放,如果其中一个条件不符合,就会释放锁,并唤起等待的线程,进行新一轮的锁竞争。
-
在当前线程的栈中分配锁记录,拷贝对象头中的 MarkWord 到当前线程的锁记录中,执行 CAS 加锁操作,会把对象头 Mark Word 中锁记录指针指向当前线程锁记录,如果成功,获取轻量级锁,执行同步代码,然后执行第3步,如果不成功,执行下一步
-
当前线程没有使用 CAS 成功获取锁,就会自旋一会儿,再次尝试获取,如果在多次自旋到达上限后还没有获取到锁,那么轻量级锁就会升级为 重量级锁
如果用流程图表示是这样的

在 Java 中,synchronized 关键字内部实现原理就是锁升级的过程:无锁 --> 偏向锁 --> 轻量级锁 --> 重量级锁。
这四种状态都不是Java语言中的锁,而是JVM为了提高锁的获取与释放效率而做的优化
综上,偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。而轻量级锁是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。重量级锁是将除了拥有锁的线程以外的线程都阻塞。
1.6 从编译器优化的角度划分 – 锁消除和锁粗化
锁消除和锁粗化,是编译器在编译代码阶段,对一些没有必要的、不会引起安全问题的同步代码取消同步(锁消除) 或者 对那些多次执行同步的代码且它们可以合并到一次同步的代码(锁粗化) 进行的优化手段,从而提高程序的执行效率。
(1)锁消除
对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判断依据是来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而能被其他线程访问到,那就可以把他们当做栈上数据对待,认为他们是线程私有的,同步加锁自然就无需进行。
来看这样一个方法:
public String concatString(String s1, String s2, String s3)
{
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
源码中 StringBuffer 的 append 方法定义如下:
public synchronized StringBuffer append(StringBuffer sb) {
super.append(sb);
return this;
}
可见 append 的方法使用 synchronized 进行同步,我们知道对象的实例总是存在于堆中被多线程共享,即使在局部方法中创建的实例依然存在于堆中,但是对该实例的引用是线程私有的,对其他线程不可见。即上边代码中虽然 StringBuffer 的实例是共享数据,但是对该实例的引用确是每条线程内部私有的。不同的线程引用的是堆中存在的不同的 StringBuffer 实例,它们互不影响互不可见。也就是说在 concatString () 方法中涉及了同步操作。但是可以观察到 sb 对象它的作用域被限制在方法的内部,也就是 sb 对象不会 “逃逸” 出去,其他线程无法访问。因此,虽然这里有锁,但是可以被安全的消除,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。
(2)锁粗化
原则上,我们在编写代码的时候,总是要将同步块的作用范围限制的尽量小 —— 只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁禁止,那等待的线程也能尽快拿到锁。大部分情况下,这些都是正确的。但是,如果一系列的联系操作都是同一个对象反复加上和解锁,甚至加锁操作是出现在循环体中的,那么即使没有线程竞争,频繁地进行互斥同步操作也导致不必要的性能损耗。
举个案例,类似上面锁消除的 concatString () 方法。如果 StringBuffer sb = new StringBuffer (); 定义在方法体之外,那么就会有线程竞争,但是每个 append () 操作都对同一个对象反复加锁解锁,那么虚拟机探测到有这样的情况的话,会把加锁同步的范围扩展到整个操作序列的外部,即扩展到第一个 append () 操作之前和最后一个 append () 操作之后,这样的一个锁范围扩展的操作就称之为锁粗化。
1.7 在不同的位置使用 synchronized-- 类锁和对象锁
这是最常见的锁了,synchronized 作为锁来使用的时候,无非就只能出现在两个地方(其实还能修饰变量,但作用是保证可见性,这里讨论锁,故不阐述):代码块、方法(一般方法、静态方法)。由于可以使用不同的类型来作为锁,因此分成了类锁和对象锁。
类锁:使用字节码文件(即.class)作为锁。如静态同步函数(使用本类的.class),同步代码块中使用.class。
对象锁:使用对象作为锁。如同步函数(使用本类实例,即 this),同步代码块中是用引用的对象。
它可以把任意一个非NULL的对象当作锁。
- 作用于方法时,锁住的是对象的实例(this);
- 当作用于静态方法时,锁住的是Class实例,又因为Class的相关数据存储在永久代PermGen(jdk1.8则是metaspace),永久带是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程;
- synchronized作用于一个对象实例时,锁住的是所有以该对象为锁的代码块。
下面代码涵盖了所有 synchronized 的使用方式:
public class Demo {
public Object obj = new Object();
// 静态同步函数,使用本类字节码做类锁(即Demo.class)
public static synchronized void method1() {
}
public void method2() {
// 同步代码块,使用字节码做类锁
synchronized (Demo.class) {
}
}
// 同步函数,使用本类对象实例即this做对象锁
public synchronized void method3() {
}
// 同步代码块,使用本类对象实例即this做对象锁
public void method4() {
synchronized (this) {
}
}
public void method5() {
//同步代码块,使用共享数据obj实例做对象锁。
synchronized (obj) {
}
}
}
2. 从锁的设计理念来分类 – 悲观锁、乐观锁
如果将锁在宏观上进行大的分类,那么只有两类,即悲观锁和乐观锁。

2.1 悲观锁
悲观锁是就是悲观思想,即认为读少写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会 block 直到拿到锁。java 中的悲观锁就是 Synchronized,AQS 框架下的锁则是先尝试 cas 乐观锁去获取锁,获取不到,才会转换为悲观锁,如 RetreenLock。 有一些使用了 synchronized 关键字的容器类如 HashTable 等也是悲观锁的应用。
2.2 乐观锁
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读 - 比较 - 写的操作。 在 Java 语言中 java.util.concurrent.atomic包下的原子类就是使用CAS 乐观锁实现的。
2.2.1 乐观锁的实现思想 --CAS(Compare and Swap)
CAS 并不是一种实际的锁,它仅仅是实现乐观锁的一种思想,java 中的乐观锁(如自旋锁)基本都是通过 CAS 操作实现的,CAS 是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。
乐观锁常见的两种实现方式
乐观锁一般会使用版本号机制或 CAS 算法实现
2.2.1.1 版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数,当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
2.2.1.2 CAS 算法
即 compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。
CAS 算法涉及到三个操作数
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A 时,CAS 通过原子方式用新值 B 来更新 V 的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
java.util.concurrent包中的原子类,就是通过CAS来实现了乐观锁,那么我们进入原子类AtomicInteger的源码,看一下AtomicInteger的定义:

根据定义我们可以看出各属性的作用:
- unsafe: 获取并操作内存的数据。
- valueOffset: 存储value在AtomicInteger中的偏移量。
- value: 存储AtomicInteger的int值,该属性需要借助volatile关键字保证其在线程间是可见的。
接下来,我们查看AtomicInteger的自增函数incrementAndGet()的源码时,发现自增函数底层调用的是unsafe.getAndAddInt()。但是由于JDK本身只有Unsafe.class,只通过class文件中的参数名,并不能很好的了解方法的作用,所以我们通过OpenJDK 8 来查看Unsafe的源码:
// ------------------------- JDK 8 -------------------------
// AtomicInteger 自增方法
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
// Unsafe.class
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
// ------------------------- OpenJDK 8 -------------------------
// Unsafe.java
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
根据OpenJDK 8的源码我们可以看出,getAndAddInt()循环获取给定对象o中的偏移量处的值v,然后判断内存值是否等于v。如果相等则将内存值设置为 v + delta,否则返回false,继续循环进行重试,直到设置成功才能退出循环,并且将旧值返回。整个“比较+更新”操作封装在compareAndSwapInt()中,在JNI里是借助于一个CPU指令完成的,属于原子操作,可以保证多个线程都能够看到同一个变量的修改值。
后续JDK通过CPU的cmpxchg指令,去比较寄存器中的 A 和 内存中的值 V。如果相等,就把要写入的新值 B 存入内存中。如果不相等,就将内存值 V 赋值给寄存器中的值 A。然后通过Java代码中的while循环再次调用cmpxchg指令进行重试,直到设置成功为止。
CAS虽然很高效,但是它也存在三大问题,这里也简单说一下:
- ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。 - 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
- 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。
3. 数据库中常用到的锁 – 共享锁、排它锁
共享锁和排它锁多用于数据库中的事务操作,主要针对读和写的操作。而在 Java 中,对这组概念通过 ReentrantReadWriteLock 进行了实现,它的理念和数据库中共享锁与排它锁的理念几乎一致,即一条线程进行读的时候,允许其他线程进入上锁的区域中进行读操作;当一条线程进行写操作的时候,不允许其他线程进入进行任何操作。 即读 + 读可以存在,读 + 写、写 + 写均不允许存在
共享锁:也称读锁或 S 锁。如果事务 T 对数据 A 加上共享锁后,则其他事务只能对 A 再加共享锁,不能加排它锁。获准共享锁的事务只能读数据,不能修改数据。
排它锁:也称独占锁、写锁或 X 锁。如果事务 T 对数据 A 加上排它锁后,则其他事务不能再对 A 加任何类型的锁。获得排它锁的事务即能读数据又能修改数据。
4. 由于并发问题产生的锁 – 死锁、活锁
4.1 死锁
(1)什么是死锁
所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。下面我通过一些实例来说明死锁现象。
先看生活中的一个实例,2 个人一起吃饭但是只有一双筷子,2 人轮流吃(同时拥有 2 只筷子才能吃)。某一个时候,一个拿了左筷子,一人拿了右筷子,2 个人都同时占用一个资源,等待另一个资源,这个时候甲在等待乙吃完并释放它占有的筷子,同理,乙也在等待甲吃完并释放它占有的筷子,这样就陷入了一个死循环,谁也无法继续吃饭。
在计算机系统中也存在类似的情况。例如,某计算机系统中只有一台打印机和一台输入 设备,进程 P1 正占用输入设备,同时又提出使用打印机的请求,但此时打印机正被进程 P2 所占用,而 P2 在未释放打印机之前,又提出请求使用正被 P1 占用着的输入设备。这样两个进程相互无休止地等待下去,均无法继续执行,此时两个进程陷入死锁状态。
(2)死锁形成的必要条件
产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生:
互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合 {Pl, P2, …, pn},其中 Pi 等 待的资源被 P (i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0 占有
4.2 活锁
活锁和死锁在表现上是一样的两个线程都没有任何进展,但是区别在于:死锁,两个线程都处于阻塞状态,说白了就是它不会再做任何动作,我们通过查看线程状态是可以分辨出来的。而活锁呢,并不会阻塞,而是一直尝试去获取需要的锁,不断的 try,这种情况下线程并没有阻塞所以是活的状态,我们查看线程的状态也会发现线程是正常的,但重要的是整个程序却不能继续执行了,一直在做无用功。举个生动的例子的话,两个人都没有停下来等对方让路,而是都有很有礼貌的给对方让路,但是两个人都在不断朝路的同一个方向移动,这样只是在做无用功,还是不能让对方通过。
5. 问与答
5.1 什么是读优先锁、写优先锁、公平读写锁?
读优先锁希望的是读锁能够被更多的线程获取,可以提高读线程的并发性。线程 A 获取了读锁,线程 B 想获取写锁,此时会被阻塞,线程 c 可以继续获取读锁,直到 A 和 c 释放锁,线程 B 才可以获取写锁。如果有很多线程获取读锁,且加锁的代码执行时间很长,就到导致线程 B 永远获取不到写锁。
写优先锁希望的是写锁能够被优先获取。线程 A 获取了读锁,线程 B 想获取写锁,此时会被阻塞,后面获取读锁都会失败,线程 A 释放锁,线程 B 可以获取写锁,其他获取读锁的线程阻塞。如果有很多写线程获取写锁,且加锁的代码执行时间很长,就到导致读线程永远获取不到读锁。
上面两种锁都会造成【饥饿】现象,为解决这种问题,可以增加一个队列,把获取锁的线程(不管是写线程还是读线程)按照先进先出的方式排队,每次从队列中取出一个线程获取锁,这种获取锁的方式是公平的。
6. java.util.concurrent.locks(JUC)下常用的几种锁(以下代码都能直接运行)
6.1 ReentrantLock
ReentrantLock,可重入锁,是一种递归无阻塞的同步机制。它可以等同于synchronized的使用,但是ReentrantLock提供了比synchronized更强大、灵活的锁机制,可以减少死锁发生的概率。
ReentrantLock还提供了公平锁和非公平锁的选择,构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁。
6.1.1 简单使用
一般使用如下方式获取锁
ReentrantLock lock = new ReentrantLock();
lock.lock();
lock方法:
public void lock() {
sync.lock();
}
Sync为Sync为ReentrantLock里面的一个内部类,它继承AQS。关于AQS的相关知识可以自行补充一下。Sync有两个子类分别是FairSync(公平锁)和 NofairSync(非公平锁)。默认使用NofairSync,下面是ReentrantLock的构造类
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
下边是一个简单的重入锁使用案例
1 public class ReentrantLockDemo implements Runnable {
2 public static final Lock lock = new ReentrantLock();
3 public static int i = 0;
4
5 @Override
6 public void run() {
7 for (int j = 0; j < 1000000; j++) {
8 lock.lock();
9 try {
10 i++;
11 } finally {
12 lock.unlock();
13 }
14 }
15 }
16
17 public static void main(String[] args) throws InterruptedException {
18 ReentrantLockDemo demo = new ReentrantLockDemo();
19 Thread t1 = new Thread(demo);
20 Thread t2 = new Thread(demo);
21 t1.start();
22 t2.start();
23 t1.join();
24 t2.join();
25 System.out.println(i);
26 }
27 }
上述代码的第8~12行,使用了重入锁保护了临界区资源i,确保了多线程对i的操作。输出结果为2000000。可以看到与synchronized相比,重入锁必选手动指定在什么地方加锁,什么地方释放锁,所以更加灵活。
要注意是,再退出临界区的时候,需要释放锁,否则其他线程就无法访问临界区了。这里为啥叫可重入锁是因为这种锁是可以被同一个线程反复进入的。比如上述代码的使用锁部分可以写成这样
lock.lock();
lock.lock();
try {
i++;
} finally {
lock.unlock();
lock.unlock();
}
在这种情况下,一个线程联连续两次获取同一把锁,这是允许的。但是需要注意的是,如果同一个线程多次获的锁,那么在释放是也要释放相同次数的锁。如果释放的锁少了,相当于该线程依然持有这个锁,那么其他线程就无法访问临界区了。释放的次数多了也会抛出java.lang.IllegalMonitorStateException异常。
6.1.2 高级功能-中断响应
对用synchrozide来说,如果一个线程在等待,那么结果只有两种情况,要么获得这把锁继续执行下去要么一直等待下去。而使用重入锁,提供了另外一种可能,那就是线程可以被中断。也就是说在这里可以取消对锁的请求。这种情况对解决死锁是有一定帮组的。
下面代码产生了一个死锁,但是我们可以通过锁的中断,解决这个死锁。
public class ReentrantLockDemo implements Runnable {
//重入锁ReentrantLock
public static ReentrantLock lock1 = new ReentrantLock();
public static ReentrantLock lock2 = new ReentrantLock();
int lock;
public ReentrantLockDemo(int lock) {
this.lock = lock;
}
@Override
public void run() {
try {
if (lock == 1) {
lock1.lockInterruptibly();
Thread.sleep(500);
lock2.lockInterruptibly();
System.out.println("this is thread 1");
} else {
lock2.lockInterruptibly();
Thread.sleep(500);
lock1.lockInterruptibly();
System.out.println("this is thread 2");
}
} catch (Exception e) {
//e.printStackTrace();
} finally {
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();//释放锁
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getId() + ":线程退出");
}
}
public static void main(String[] args) throws InterruptedException {
ReentrantLockDemo r1 = new ReentrantLockDemo(1);
ReentrantLockDemo r2 = new ReentrantLockDemo(2);
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
t1.start();
t2.start();
Thread.sleep(1000);
//t2线程被中断,放弃锁申请,释放已获得的lock2,这个操作使得t1线程顺利获得lock2继续执行下去;
//若没有此段代码,t2线程没有中断,那么会出现t1获取lock1,请求lock2,而t2获取lock2,请求lock1的相互等待死锁情况
t2.interrupt();
}
}
线程t1和t2启动后,t1先占用lock1然后在请求lock2;t2先占用lock2,然后请求lock1,因此很容易形成线程之间的相互等待。着这里使用的是ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。
最后由于t2线程被中断,t2会放弃对lock1的1请求,同时释放lock2。这样可以使t1继续执行下去,结果如下图

6.1.3 高级功能-锁申请等待限时
除了等待通知以外,避免死锁还有另外一种方式,那就是限时等待。通过给定一个等待时间,让线程自动放弃
public class TimeLockDemo implements Runnable {
private static ReentrantLock reentrantLock = new ReentrantLock();
@Override
public void run() {
try {
if (reentrantLock.tryLock(5, TimeUnit.SECONDS)) {
Thread.sleep(6000);
} else {
System.out.println("Gets lock failed");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (reentrantLock.isHeldByCurrentThread()){
reentrantLock.unlock();
}
}
}
public static void main(String[] args) {
TimeLockDemo demo1 = new TimeLockDemo();
TimeLockDemo demo2 = new TimeLockDemo();
Thread t1 = new Thread(demo1);
Thread t2 = new Thread(demo2);
t1.start();
t2.start();
}
}
tryLock有两个参数,一个表示等待时长,另一个表示计时单位。在这里就是通过lock.tryLock(5,TimeUnit.SECONDS)来设置锁申请等待限时,此例就是限时等待5秒获取锁。在这里的锁请求最多为5秒,如果超过5秒未获得锁请求,则会返回fasle,如果成功获得锁就会返回true。此案例中第一个线程会持有锁长达6秒,所以另外一个线程无法在5秒内获得锁 故案例输出结果为Gets lock failed
另外tryLock方法也可以不带参数之直接运行,在这种情况下,当前线程会尝试获得锁,如果锁并未被其他线程占用,则申请锁直接成功,立即返回true,否则当前线程不会进行等待,而是立即返回false。这种模式不会引起线程等待,因此也不会产生死锁。
下边展示了这种使用方式
public class ReentrantLockDemo implements Runnable {
//重入锁ReentrantLock
public static ReentrantLock lock1 = new ReentrantLock();
public static ReentrantLock lock2 = new ReentrantLock();
int lock;
public ReentrantLockDemo(int lock) {
this.lock = lock;
}
@Override
public void run() {
try {
if (lock == 1) {
while (true) {
if (lock1.tryLock()) {
try {
Thread.sleep(1000);
} finally {
lock1.unlock();
}
}
if (lock2.tryLock()) {
try {
System.out.println("thread " + Thread.currentThread().getId() + " 执行完毕");
return;
} finally {
lock2.unlock();
}
}
}
} else {
while (true) {
if (lock2.tryLock()) {
try {
Thread.sleep(1000);
} finally {
lock2.unlock();
}
}
if (lock1.tryLock()) {
try {
System.out.println("thread " + Thread.currentThread().getId() + " 执行完毕");
return;
} finally {
lock1.unlock();
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
ReentrantLockDemo r1 = new ReentrantLockDemo(1);
ReentrantLockDemo r2 = new ReentrantLockDemo(2);
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
t1.start();
t2.start();
}
}
使用了tryLock后,线程不会傻傻的等待,而是不同的尝试获取锁,因此,只要执行足够长的时间,线程总是会获得所有需要的资源。从而正常执行。下边展示了运行结果。表示两个线程运行都正常。
![]()
在大多数情况下。锁的申请都是非公平的。也就是说系统只是会从等待锁的队列里随机挑选一个,所以不能保证其公平性。但是公平锁的实现成本很高,性能也相对低下。因此如果没有特别要求,也不需要使用公平锁。
对上边ReentrantLock几个重要的方法整理如下。
- lock():获得锁,如果锁已经被占用,则等待。
- lockInterruptibly(): 获得锁,但优先响应中断。
- tryLock():尝试获得锁,如果成功,返回true,失败返回false。该方法不等待,立即返回
- tryLock(long time,TimeUnit unit),在给定时间内尝试获得锁
- unlock(): 释放锁。注:ReentrantLock的锁释放一定要在finally中处理,否则可能会产生严重的后果。
6.1.4 高级功能-Condition条件
Conditon和ReentrantLock的组合可以让线程在合适的时间等待,或者在某一个特定的时间得到通知,继续执行。在Condition中,用await()替换wait(),用signal()替换notify(),用signalAll()替换notifyAll(),传统线程的通信方式,Condition都可以实现,这里注意,Condition是被绑定到Lock上的,要创建一个Lock的Condition必须用newCondition()方法。
- await:当前线程进入等待状态,直到被通知(signal OR signalAll)或者被中断时,当前线程进入运行状态,从await()返回;
- awaitUninterruptibly:当前线程进入等待状态,直到被通知,对中断不做响应;
- awaitNanos(long nanosTimeout):在await()的返回条件基础上增加了超时响应,返回值表示当前剩余的时间,如果在nanosTimeout之前被唤醒,返回值 = nanosTimeout - 实际消耗的时间,返回值 <= 0表示超时;
- boolean await(long time, TimeUnit unit):同样是在await()的返回条件基础上增加了超时响应,与上一接口不同的是可以自定义超时时间单位; 返回值返回true/false,在time之前被唤醒,返回true,超时返回false。
- boolean awaitUntil(Date deadline):当前线程进入等待状态直到将来的指定时间被通知,如果没有到指定时间被通知返回true,否则,到达指定时间,返回false;
- signal():唤醒一个等待在Condition上的线程
- signalAll():唤醒等待在Condition上所有的线程。
使用案例如下
public class ConditionDemo {
static class NumberWrapper {
public int value = 1;
}
public static void main(String[] args) {
//初始化可重入锁
final Lock lock = new ReentrantLock();
//第一个条件当屏幕上输出到3
final Condition reachThreeCondition = lock.newCondition();
//第二个条件当屏幕上输出到6
final Condition reachSixCondition = lock.newCondition();
//NumberWrapper只是为了封装一个数字,一边可以将数字对象共享,并可以设置为final
//注意这里不要用Integer, Integer 是不可变对象
final NumberWrapper num = new NumberWrapper();
//初始化A线程
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
//需要先获得锁
lock.lock();
try {
System.out.println("threadA start write");
//A线程先输出前3个数
while (num.value <= 3) {
System.out.println(num.value);
num.value++;
}
//输出到3时要signal,告诉B线程可以开始了
reachThreeCondition.signal();
} finally {
lock.unlock();
}
lock.lock();
try {
//等待输出6的条件
while(num.value <= 6) {
reachSixCondition.await();
}
System.out.println("threadA start write");
//输出剩余数字
while (num.value <= 9) {
System.out.println(num.value);
num.value++;
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
try {
lock.lock();
while (num.value <= 3) {
//等待3输出完毕的信号
reachThreeCondition.await();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
try {
lock.lock();
//已经收到信号,开始输出4,5,6
System.out.println("threadB start write");
while (num.value <= 6) {
System.out.println(num.value);
num.value++;
}
//4,5,6输出完毕,告诉A线程6输出完了
reachSixCondition.signal();
} finally {
lock.unlock();
}
}
});
//启动两个线程
threadB.start();
threadA.start();
}
}
结果如下

这样看来,Condition和传统的线程通信没什么区别,Condition的强大之处在于它可以为多个线程间建立不同的Condition,下面引入API中的一段代码,加以说明。
class BoundedBuffer {
final Lock lock = new ReentrantLock();//锁对象
final Condition notFull = lock.newCondition();//写线程条件
final Condition notEmpty = lock.newCondition();//读线程条件
final Object[] items = new Object[100];//缓存队列
int putptr/*写索引*/, takeptr/*读索引*/, count/*队列中存在的数据个数*/;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)//如果队列满了
notFull.await();//阻塞写线程
items[putptr] = x;//赋值
if (++putptr == items.length) putptr = 0;//如果写索引写到队列的最后一个位置了,那么置为0
++count;//个数++
notEmpty.signal();//唤醒读线程
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)//如果队列为空
notEmpty.await();//阻塞读线程
Object x = items[takeptr];//取值
if (++takeptr == items.length) takeptr = 0;//如果读索引读到队列的最后一个位置了,那么置为0
--count;//个数--
notFull.signal();//唤醒写线程
return x;
} finally {
lock.unlock();
}
}
}
这个示例中BoundedBuffer是一个固定长度的集合,这个在其put操作时,如果发现长度已经达到最大长度,那么要等待notFull信号才能继续put,如果得到notFull信号会像集合中添加元素,并且put操作会发出notEmpty的信号,而在其take方法中如果发现集合长度为空,那么会等待notEmpty的信号,接受到notEmpty信号才能继续take,同时如果拿到一个元素,那么会发出notFull的信号。
6.2 信号量(Semaphore)
信号量(Semaphore)为多线程协作提供了更为强大的控制用法。无论是内部锁Synchronized还是ReentrantLock,一次都只允许一个线程访问资源,而信号量可以多个线程访问同一资源。Semaphore是用来保护一个或者多个共享资源的访问,Semaphore内部维护了一个计数器,其值为可以访问的共享资源的个数。一个线程要访问共享资源,先获得信号量,如果信号量的计数器值大于1,意味着有共享资源可以访问,则使其计数器值减去1,再访问共享资源。如果计数器值为0,线程进入休眠。当某个线程使用完共享资源后,释放信号量,并将信号量内部的计数器加1,之前进入休眠的线程将被唤醒并再次试图获得信号量。
信号量的UML的类图如下,可以看出和ReentrantLock一样,Semaphore也包含了sync对象,sync是Sync类型;而且,Sync是一个继承于AQS的抽象类。Sync包括两个子类:“公平信号量"FairSync 和 “非公平信号量"NonfairSync。sync是"FairSync的实例”,或者"NonfairSync的实例”;默认情况下,sync是NonfairSync(即,默认是非公平信号量)

信号量主要提供了以下构造函数
Semaphore(int num)
Semaphore(int num,boolean how)
这里,num指定初始许可计数。因此,它指定了一次可以访问共享资源的线程数。如果是1,则任何时候只有一个线程可以访问该资源。默认情况下,所有等待的线程都以未定义的顺序被授予许可。通过设置how为true,可以确保等待线程按其请求访问的顺序被授予许可。信号量的主要逻辑方法如下
// 从此信号量获取一个许可,在提供一个许可前一直将线程阻塞,否则线程被中断。
void acquire()
// 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞,或者线程已被中断。
void acquire(int permits)
// 从此信号量中获取许可,在有可用的许可前将其阻塞。
void acquireUninterruptibly()
// 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞。
void acquireUninterruptibly(int permits)
// 返回此信号量中当前可用的许可数。
// 释放一个许可,将其返回给信号量。
void release()
// 释放给定数目的许可,将其返回到信号量。
// 仅在调用时此信号量存在一个可用许可,才从信号量获取许可。
boolean tryAcquire()
// 仅在调用时此信号量中有给定数目的许可时,才从此信号量中获取这些许可。
boolean tryAcquire(int permits)
// 如果在给定的等待时间内此信号量有可用的所有许可,并且当前线程未被中断,则从此信号量获取给定数目的许可。
boolean tryAcquire(int permits, long timeout, TimeUnit unit)
// 如果在给定的等待时间内,此信号量有可用的许可并且当前线程未被中断,则从此信号量获取一个许可。
实例如下:这里我们模拟10个人去银行存款,但是该银行只有两个办公柜台,有空位则上去存钱,没有空位则只能去排队等待。最后输出银行总额
public class SemaphoreThread {
private int customer;
public SemaphoreThread() {
customer = 0;
}
/**
* 银行存钱类
*/
class Bank {
private int account = 100;
public int getAccount() {
return account;
}
public void save(int money) {
account += money;
}
}
/**
* 线程执行类,每次存10块钱
*/
class NewThread implements Runnable {
private Bank bank;
private Semaphore semaphore;
public NewThread(Bank bank, Semaphore semaphore) {
this.bank = bank;
this.semaphore = semaphore;
}
@Override
public void run() {
int tempCustomer = customer++;
if (semaphore.availablePermits() > 0) {
System.out.println("客户" + tempCustomer + "启动,进入银行,有位置立即去存钱");
} else {
System.out.println("客户" + tempCustomer + "启动,进入银行,无位置,去排队等待等待");
}
try {
semaphore.acquire();
bank.save(10);
System.out.println(tempCustomer + "银行余额为:" + bank.getAccount());
Thread.sleep(1000);
System.out.println("客户" + tempCustomer + "存钱完毕,离开银行");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 建立线程,调用内部类,开始存钱
*/
public void useThread() {
Bank bank = new Bank();
// 定义2个新号量
Semaphore semaphore = new Semaphore(2);
// 建立一个缓存线程池
ExecutorService es = Executors.newCachedThreadPool();
// 建立10个线程
for (int i = 0; i < 10; i++) {
// 执行一个线程
es.submit(new Thread(new NewThread(bank, semaphore)));
}
// 关闭线程池
es.shutdown();
// 从信号量中获取两个许可,并且在获得许可之前,一直将线程阻塞
semaphore.acquireUninterruptibly(2);
System.out.println("到点了,工作人员要吃饭了");
// 释放两个许可,并将其返回给信号量
semaphore.release(2);
}
public static void main(String[] args) {
SemaphoreThread test = new SemaphoreThread();
test.useThread();
}
}
6.3 读写锁ReentrantReadWriteLock
ReentrantReadWriteLock是Lock的另一种实现方式,我们已经知道了ReentrantLock是一个排他锁,同一时间只允许一个线程访问,而ReentrantReadWriteLock允许多个读线程同时访问(也就是读操作),但不允许写线程和读线程、写线程和写线程同时访问。约束如下
- 读—读不互斥:读与读之间不阻塞
- 读—写:读阻塞写,写也会阻塞读
- 写—写:写写阻塞
相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量。
看一下官方案例
class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public void processCachedData() {
rwl.readLock().lock();//1
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();//2
rwl.writeLock().lock();//3
try {
// Recheck state because another thread might have,acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 在释放写锁之前通过获取读锁降级写锁(注意此时还没有释放写锁)
rwl.readLock().lock();//4
} finally {
// 释放写锁而此时已经持有读锁
rwl.writeLock().unlock();//5
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();//6
}
}
}
- 多个线程同时访问该缓存对象时,都加上当前对象的读锁,之后其中某个线程优先查看data数据是否为空。【加锁顺序序号:1 】
- 当前查看的线程,如果发现没有值则释放读锁,然后立即加上写锁,准备写入缓存数据。(进入写锁的前提是当前没有其他线程的读锁或者写锁)【加锁顺序序号:2和3 】
- 为什么还会再次判断是否为空值(!cacheValid)是因为第二个、第三个线程获得读的权利时也是需要判断是否为空,否则会重复写入数据。
- 写入数据后先进行读锁的降级后再释放写锁。【加锁顺序序号:4和5】
- 最后数据数据返回前释放最终的读锁。【加锁顺序序号:6 】
如果不使用锁降级功能,如先释放写锁,然后获得读锁,在这个get过程中,可能会有其他线程竞争到写锁 或者是更新数据 则获得的数据是其他线程更新的数据,可能会造成数据的污染,即产生脏读的问题
public class ReadAndWriteLock {
private static ReentrantLock lock = new ReentrantLock();
private static ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private static Lock readLock = readWriteLock.readLock();
private static Lock writeLock = readWriteLock.writeLock();
public ReadAndWriteLock setValue(int value) {
this.value = value;
return this;
}
private int value;
public Object handleRead(Lock lock) throws InterruptedException {
try {
//模拟读操作
lock.lock();
System.out.println("thread:" + Thread.currentThread().getId() + " value:" + value);
Thread.sleep(1000);
return value;
} finally {
lock.unlock();
}
}
public Object handleWrite(Lock lock, int index) throws InterruptedException {
try {
//模拟写操作
lock.lock();
value = index;
Thread.sleep(1000);
System.out.println("thread:" + Thread.currentThread().getId() + " value:" + value);
return value;
} finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
final ReadAndWriteLock demo = new ReadAndWriteLock();
demo.setValue(0);
Runnable readRunnable = new Runnable() {
@Override
public void run() {
try {
//读锁
demo.handleRead(readLock);
//可重入锁
//demo.handleRead(lock);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable writeRunnable = new Runnable() {
@Override
public void run() {
try {
//写锁
demo.handleWrite(readLock, (int) (Math.random() * 1000));
//可重入锁
//demo.handleWrite(lock, (int) (Math.random() * 1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
ExecutorService exec = new ThreadPoolExecutor(0, 200,
0, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
;
long startTime = System.currentTimeMillis();
for (int i = 0; i < 18; i++) {
exec.execute(readRunnable);
}
for (int i = 0; i < 18; i++) {
exec.execute(writeRunnable);
}
exec.shutdown();
exec.awaitTermination(60, TimeUnit.MINUTES);
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "ms");
}
}
在这里读线程完全并行,而写会阻塞读。程序执行时间如下
![]()
将上述案例中的读写锁改成可重入锁,即把标注//可重入锁注释下的那行代码打开(有2行),那么所有的读和写线程都必须相互等待,程序执行时间如下所示
![]()
6.4 倒计时器:CountDownLatch
CountDownLatch是java1.5版本之后util.concurrent提供的工具类。这里简单介绍一下CountDownLatch,可以将其看成是一个计数器,await()方法可以阻塞至超时或者计数器减至0,其他线程当完成自己目标的时候可以减少1,利用这个机制我们可以将其用来做并发。 比如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。
CountDownLatch类只提供了一个构造器,该构造器接受一个整数作为参数,即当前这个计数器的计数个数 。
public CountDownLatch(int count) { }; //参数count为计数值
使用场景:比如对于马拉松比赛,进行排名计算,参赛者的排名,肯定是跑完比赛之后,进行计算得出的,翻译成Java识别的语法,就是N个线程执行操作,主线程等到N个子线程执行完毕之后,再继续往下执行。
public class CountDownLatchTest {
public static void main(String[] args){
int threadCount = 10;
final CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("线程" + Thread.currentThread().getId() + "开始出发");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程" + Thread.currentThread().getId() + "已到达终点");
latch.countDown();
}
}).start();
}
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10个线程已经执行完毕!开始计算排名");
}
}
结果如下
线程12开始出发
线程14开始出发
线程15开始出发
线程17开始出发
线程13开始出发
线程16开始出发
线程18开始出发
线程19开始出发
线程20开始出发
线程21开始出发
线程16已到达终点
线程13已到达终点
线程19已到达终点
线程18已到达终点
线程17已到达终点
线程14已到达终点
线程15已到达终点
线程12已到达终点
线程21已到达终点
线程20已到达终点
10个线程已经执行完毕!开始计算排名
CountDownLatch在并行化应用中也是比较常用。常用的并行化框架OpenMP中也是借鉴了这种思想。比如有这样的一个需求,在你淘宝订单的时候,这笔订单可能还需要查,用户信息,折扣信息,商家信息,商品信息等,用同步的方式(也就是串行的方式)流程如下。

设想一下这5个查询服务,平均每次消耗100ms,那么本次调用至少是500ms,我们这里假设,在这个这五个服务其实并没有任何数据依赖,谁先获取谁后获取都可以,那么我们可以想办法并行化这五个服务。

这里可以使用CountDownLatch来实现这个效果。
public class CountDownLatchTest {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 8;
private static final long KEEP_ALIVE_TIME = 5L;
private final static int QUEUE_SIZE = 1600;
protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
public static void main(String[] args) throws InterruptedException {
// 新建一个为5的计数器
CountDownLatch countDownLatch = new CountDownLatch(5);
OrderInfo orderInfo = new OrderInfo();
THREAD_POOL.execute(() -> {
System.out.println("当前任务Customer,线程名字为:" + Thread.currentThread()
.getName());
orderInfo.setCustomerInfo(new CustomerInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Discount,线程名字为:" + Thread.currentThread()
.getName());
orderInfo.setDiscountInfo(new DiscountInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Food,线程名字为:" + Thread.currentThread()
.getName());
orderInfo.setFoodListInfo(new FoodListInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务Tenant,线程名字为:" + Thread.currentThread()
.getName());
orderInfo.setTenantInfo(new TenantInfo());
countDownLatch.countDown();
});
THREAD_POOL.execute(() -> {
System.out.println("当前任务OtherInfo,线程名字为:" + Thread.currentThread()
.getName());
orderInfo.setOtherInfo(new OtherInfo());
countDownLatch.countDown();
});
countDownLatch.await(1, TimeUnit.SECONDS);
System.out.println("主线程:" + Thread.currentThread()
.getName());
}
}
class OrderInfo {
private CustomerInfo customerInfo;
private DiscountInfo discountInfo;
private FoodListInfo foodListInfo;
private OtherInfo otherInfo;
private TenantInfo tenantInfo;
public CustomerInfo getCustomerInfo() {
return customerInfo;
}
public void setCustomerInfo(CustomerInfo customerInfo) {
this.customerInfo = customerInfo;
}
public DiscountInfo getDiscountInfo() {
return discountInfo;
}
public void setDiscountInfo(DiscountInfo discountInfo) {
this.discountInfo = discountInfo;
}
public FoodListInfo getFoodListInfo() {
return foodListInfo;
}
public void setFoodListInfo(FoodListInfo foodListInfo) {
this.foodListInfo = foodListInfo;
}
public OtherInfo getOtherInfo() {
return otherInfo;
}
public void setOtherInfo(OtherInfo otherInfo) {
this.otherInfo = otherInfo;
}
public TenantInfo getTenantInfo() {
return tenantInfo;
}
public void setTenantInfo(TenantInfo tenantInfo) {
this.tenantInfo = tenantInfo;
}
}
class CustomerInfo {
}
class DiscountInfo {
}
class FoodListInfo {
}
class TenantInfo {
}
class OtherInfo {
}
建立一个线程池(具体配置根据具体业务,具体机器配置),进行并发的执行我们的任务(生成用户信息,菜品信息等),最后利用await方法阻塞等待结果成功返回。
6.5 循环栅栏CyclicBarrier
字面意思循环栅栏,栅栏就是一种障碍物。这里就是内存屏障。通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。CyclicBarrier比CountDownLatch 功能更强大一些,CyclicBarrier可以接受一个参数作为barrierAction。所谓barrierAction就是当计算器一次计数完成后,系统会执行的动作。CyclicBarrier强调的是n个线程,大家相互等待,只要有一个没完成,所有人都得等着。(这种思想在高性能计算最为常见,GPU计算中关于也有类似内存屏障的用法)。构造函数如下,其中parties表示计数总数,也就是参与的线程总数。
public CyclicBarrier(int parties, Runnable barrierAction) {}
public CyclicBarrier(int parties) {}
案例:10个人去旅行,规定达到一个地点后才能继续前行.代码如下
class CyclicBarrierWorker implements Runnable {
private int id;
private CyclicBarrier barrier;
public CyclicBarrierWorker(int id, final CyclicBarrier barrier) {
this.id = id;
this.barrier = barrier;
}
@Override
public void run() {
try {
Thread.sleep(Math.abs(new Random().nextInt()%10000));
System.out.println(id + " th people wait");
barrier.await(); // 大家等待最后一个线程到达
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
public class TestCyclicBarrier {
public static void main(String[] args) {
int num = 10;
CyclicBarrier barrier = new CyclicBarrier(num, new Runnable() {
@Override
public void run() {
System.out.println("go on together!");
}
});
for (int i = 1; i <= num; i++) {
new Thread(new CyclicBarrierWorker(i, barrier)).start();
}
}
}
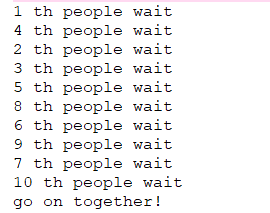
从上面输出结果可以看出,每个线程执行自己的操作之后,就在等待其他线程执行操作完毕。当所有线程线程执行操作完毕之后,所有线程就继续进行后续的操作了。
参考资料
不可不说的Java“锁”事
一文彻底理解ReentrantLock可重入锁的使用
看完你就知道的乐观锁和悲观锁
看完你就明白的锁系列之自旋锁
不懂什么是锁?看看这篇你就明白了
java并发之锁的使用以及原理浅析