深入理解Android进程间通信机制
通信是Android开发必不可少的一部分,不管是我们做应用App开发,还是Android系统,都使用了大量的通信。通信又分为进程间通信和进程内通信,在这篇文章,我主要深入讲解Android系统所涉及到的所有进程间通信方式。
Android系统中有大量IPC(进程间通信)的场景,比如我们想要创建一个新的进程,需要通过Socket这种IPC方式去让Zygote Fork新进程;如果我们要杀掉一个进程,需要通过信号这种IPC方式去将SIGNAL_KILL信号传递到系统内核;如果我们想要唤醒主线程处于休眠中的Looper,需要管道这种IPC方式来唤醒;我们想要在应用开发中使用AIDL,广播或者Messager等方式来进行跨进程通信,其实底层都是使用了Binder这种IPC方式。
那么,Android到底有多少种进程间通信的方式呢?什么样的场景要选择什么样的通信方式呢?这些IPC通信方式怎么使用呢?这些IPC通信的底层原理又是什么呢?看完这篇文章,你就能回答这几个问题了。
我们先通过下面一览Android系统所具有的IPC通信方式

可以看到,Android所拥有的IPC总共有这些:
- 基于Unix系统的IPC的管道,FIFO,信号
- 基于SystemV和Posix系统的IPC的消息队列,信号量,共享内存
- 基于Socket的IPC
- Linux的内存映射函数mmap()
- Linux 2.6.22版本后才有的eventfd
- Android系统独有的Binder和匿名共享内存Ashmen
下面,我会详细介绍这些IPC的通信机制。
管道
PIPE和FIFO的使用及原理
PIPE和FIFO都是指管道,只是PIPE独指匿名管道,FIFO独指有名管道,我们先看一下管道的数据结构以及他们的使用方式:
//匿名管道(PIPE)
#include 可以看到,匿名管道通过pipe函数创建,pipe函数通过在内核的虚拟文件系统中创建两个pipefs虚拟文件(不清楚虚拟文件的可以去了解下Linux的虚拟文件系统VFS),并返回这两个虚拟文件描述符,有了这两个文件描述,我们就能进行跨进程通信了。
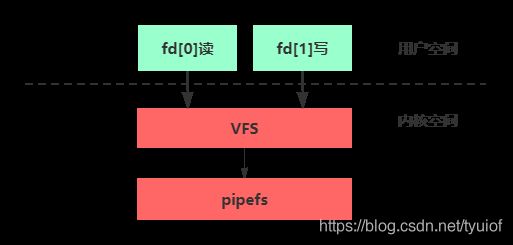
匿名管道是单向半双工的通信方式,单向即意味着只能一端读另一端写,半双工意味着不能同时读和写,其中文件描述符fd[1]只能用来写,文件描述符f[0]只能用来读,pipe创建好后,我们就可以用Linux标准的文件读取函数read和写入函数write来对pipe进行读写了。
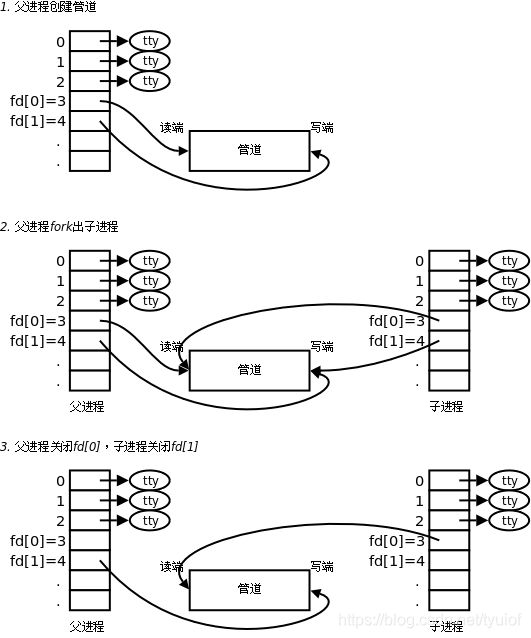
为什么pipe是匿名管道呢?因为pipefs文件是特殊的虚拟文件系统,并不会显示在VFS的目录中,所以用户不可见,既然用户不可见,那么又怎么能进行进程间通信呢?因为pipe是匿名的,所以它只支持父子和兄弟进程之间的通信。通过fork创建父子进程或者通过clone创建兄弟进程的时候,会共享内存拷贝,这时,子进程或兄弟进程就能在共享拷贝中拿到pipe的文件描述符进行通信了。我们通过下图看一下通信的流程。
接着说有名管道FIFO,FIFO是半双工双向通信,所以通过FIFO创建的管道既能读也能写,但是不能同时读和写,FIFO本质上是一个先进先出的队列数据结构,最早放入的数据被最先读出来,这样的数据结构能保证信息交流的顺序。
FIFO使用也很简单,通过mkfifo函数创建管道,它同样会在内核的虚拟文件系统中创建一个FIFO虚拟文件,FIFO文件在在VFS目录中可见,所以他是有名管道,FIFO创建后,我们需要调用open函数打开这个fifo文件,然后才能通过write和read函数进行读写
我们来总结一下pipe和fifo的异同点
相同点
- IPC的本质都是通过在内核创建虚拟文件,并且调用文件读写函数来进行数据通信
- 都只能接收字节流数据
- 都是半双工通信
不同点
- pipe是单向通信,fifo可以双向通信
- pipe只能在父子,兄弟进程间通信,fifo没有这个限制
那么管道的使用场景是什么呢?匿名管道只能用在亲属进程之间通信,而且传输的数量小,一般只支持4K,不适合大数据的交换数据和不同进程间的通信,但是使用简单方便,因为是单向通信,所以不存在并发问题。虽然FIFO能在任意两个进程间进行通信,但是因为FIFO是可以双向通信的,这样也不可避免的带来了并发的问题,我们需要花费比较大的精力用来控制并发问题。
管道在Android系统中的使用场景
下面说一下Android系统中具体使用到管道的场景:Looper。Looper不就是一个消息队列吗?怎么还使用到了管道呢?其实在Android 6.0 以下版本中,主线程Looper的唤醒就使用到了管道。
//文件-->/system/core/libutils/Looper.cpp
Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
int wakeFds[2];
int result = pipe(wakeFds); //创建pipe
mWakeReadPipeFd = wakeFds[0];
mWakeWritePipeFd = wakeFds[1];
result = fcntl(mWakeReadPipeFd, F_SETFL, O_NONBLOCK);
LOG_ALWAYS_FATAL_IF(result != 0, "Could not make wake read pipe non-blocking. errno=%d",
errno);
result = fcntl(mWakeWritePipeFd, F_SETFL, O_NONBLOCK);
LOG_ALWAYS_FATAL_IF(result != 0, "Could not make wake write pipe non-blocking. errno=%d",
errno);
mIdling = false;
// Allocate the epoll instance and register the wake pipe.
mEpollFd = epoll_create(EPOLL_SIZE_HINT);
LOG_ALWAYS_FATAL_IF(mEpollFd < 0, "Could not create epoll instance. errno=%d", errno);
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event)); // zero out unused members of data field union
eventItem.events = EPOLLIN;
eventItem.data.fd = mWakeReadPipeFd;
result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeReadPipeFd, & eventItem);
LOG_ALWAYS_FATAL_IF(result != 0, "Could not add wake read pipe to epoll instance. errno=%d",
errno);
}
从第上面代码可以看到,native层的Looper的构造函数就使用了pipe来创建管道,通过mWakeReadPipeFd,mWakeWritePipeFd这两个文件描述符的命名也看出,它是用来做唤醒的,我们就来看一下具体的唤醒的实现吧。
//文件-->/system/core/libutils/Looper.cpp
void Looper::wake() {
ssize_t nWrite;
do {
nWrite = write(mWakeWritePipeFd, "W", 1);
} while (nWrite == -1 && errno == EINTR);
if (nWrite != 1) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}
可以看到,唤醒函数其实就是往管道mWakeWritePipeFd里写入一个字母“W”,mWakeReadPipeFd接收到数据后,就会唤醒Looper。
信号
信号的使用及原理
信号实质上是一种软中断,既然是一种中断,就说明信号是异步的,信号接收函数不需要一直阻塞等待信号的到达。当信号发出后,如果有地方注册了这个信号,就会执行响应函数,如果没有地方注册这个信号,该信号就会被忽略。我们来看一下信号的使用方法。
#include 注册信号有两个方法
- **signal()**函数:signal不支持传递信息,signum入参为信号量,handler入参为信号处理函数
- **sigaction()**函数:sigaction支持传递信息,信息放在sigaction数据结构中
信号发送函数比较多,这里我列举一下。
- kill():用于向进程或进程组发送信号;
- sigqueue():只能向一个进程发送信号,不能向进程组发送信号;
- alarm():用于调用进程指定时间后发出SIGALARM信号;
- setitimer():设置定时器,计时达到后给进程发送SIGALRM信号,功能比alarm更强大;
- abort():向进程发送SIGABORT信号,默认进程会异常退出。
- raise():用于向进程自身发送信号;
通过kill -l指令可以查看Android手机支持的信号,从下图可以看到,总共有64个,前31个信号是普通信号,后33个信号是实时信号,实时信号支持队列,可以保证信号不会丢失。

我列举一下前几个信号的作用,其他的就不讲解了
| 1 | SIGHUP | 挂起 |
|---|---|---|
| 2 | SIGINT | 中断 |
| 3 | SIGQUIT | 中断 |
| 3 | SIGQUIT | 退出 |
| 4 | SIGILL | 非法指令 |
| 5 | SIGTRAP | 断点或陷阱指令 |
| 6 | SIGABRT | abort发出的信号 |
| 7 | SIGBUS | 非法内存访问 |
| 8 | SIGFPE | 浮点异常 |
| 9 | SIGKILL | 杀进程信息 |
当我们调用信号发送函数后,信号是怎么传到注册的方法调用中去的呢?这里以kill()这个信号发送函数讲解一下这个流程。
kill()函数会经过系统调用方法sys_tkill()进入内核,sys_tkill是SYSCALL_DEFINE2这个方法来实现,这个方法的实现是一个宏定义。我会从这个方法一路往底追踪,这里我会忽略细节实现,只看关键部分的代码。
//文件-->syscalls.h
asmlinkage long sys_kill(int pid, int sig);
//文件-->kernel/signal.c
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct kernel_siginfo info;
clear_siginfo(&info);
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = task_tgid_vnr(current);
info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
return kill_something_info(sig, &info, pid);
}
static int kill_something_info(int sig, struct kernel_siginfo *info, pid_t pid)
{
int ret;
if (pid > 0) {
ret = kill_pid_info(sig, info, find_vpid(pid));
return ret;
}
……
}
int kill_pid_info(int sig, struct kernel_siginfo *info, struct pid *pid)
{
……
for (;;) {
error = group_send_sig_info(sig, info, p, PIDTYPE_TGID);
……
}
}
int group_send_sig_info(int sig, struct kernel_siginfo *info,
struct task_struct *p, enum pid_type type)
{
……
ret = do_send_sig_info(sig, info, p, type);
return ret;
}
int do_send_sig_info(int sig, struct kernel_siginfo *info, struct task_struct *p,
enum pid_type type)
{
……
ret = send_signal(sig, info, p, type);
return ret;
}
static int send_signal(int sig, struct kernel_siginfo *info, struct task_struct *t,
enum pid_type type)
{
return __send_signal(sig, info, t, type, from_ancestor_ns);
}
我们从sys_kill函数一路追踪,最终调用了__send_signal函数,我们接着看这个函数的实现。
//文件-->kernel/signal.c
static int __send_signal(int sig, struct kernel_siginfo *info, struct task_struct *t,
enum pid_type type, int from_ancestor_ns)
{
……
out_set:
signalfd_notify(t, sig); //将信号发送给监听的fd
sigaddset(&pending->signal, sig);
complete_signal(sig, t, type); //完成信号发送
ret:
trace_signal_generate(sig, info, t, type != PIDTYPE_PID, result);
return ret;
}
static void complete_signal(int sig, struct task_struct *p, enum pid_type type)
{
struct signal_struct *signal = p->signal;
struct task_struct *t;
//寻找处理信号的线程
if (wants_signal(sig, p))
t = p;
else if ((type == PIDTYPE_PID) || thread_group_empty(p))
return;
else {
t = signal->curr_target;
while (!wants_signal(sig, t)) {
t = next_thread(t);
if (t == signal->curr_target)
return;
}
signal->curr_target = t;
}
//如果是SIGKILL信号,则杀掉线程组
if (sig_fatal(p, sig) &&
!(signal->flags & SIGNAL_GROUP_EXIT) &&
!sigismember(&t->real_blocked, sig) &&
(sig == SIGKILL || !p->ptrace)) {
/*
* This signal will be fatal to the whole group.
*/
if (!sig_kernel_coredump(sig)) {
/*
* Start a group exit and wake everybody up.
* This way we don't have other threads
* running and doing things after a slower
* thread has the fatal signal pending.
*/
signal->flags = SIGNAL_GROUP_EXIT;
signal->group_exit_code = sig;
signal->group_stop_count = 0;
t = p;
do {
task_clear_jobctl_pending(t, JOBCTL_PENDING_MASK);
sigaddset(&t->pending.signal, SIGKILL);
signal_wake_up(t, 1);
} while_each_thread(p, t);
return;
}
}
/*
* The signal is already in the shared-pending queue.
* Tell the chosen thread to wake up and dequeue it.
*/
signal_wake_up(t, sig == SIGKILL);
return;
}
可以看到,信号最终被分发到了监听的fd中,交给了我们注册的函数处理,从最后部分也可以看到,如果是SIGKILL信号,内核会专门处理去杀进程。这里我详细讲了发送信号的底层实现,关于注册信号的底层实现,就不再这里详细讲了,有兴趣的可以自己去研究。
信号在Android中的使用场景
我们已经知道如何使用信号以及它的原理,那么我们在来看一个Android系统中使用信号的场景:杀进程。从上面部分可以看到,SIGKILL信号是由内核捕获并处理的,我们看一下Android是怎么调用杀进程的信号的吧。
//文件-->Process.java
public static final void killProcess(int pid) {
sendSignal(pid, SIGNAL_KILL);
}
//文件-->android_util_Process.cpp
void android_os_Process_sendSignal(JNIEnv* env, jobject clazz, jint pid, jint sig) {
if (pid > 0) {
//打印Signal信息
ALOGI("Sending signal. PID: %" PRId32 " SIG: %" PRId32, pid, sig);
kill(pid, sig);
}
}
可以看到,当我们调用Process的killProcess函数杀掉某个进程时,最终会调用到native方法kill(),入参sig信号量就是SIGKILL,这个kill()方法,就是我在上面讲的信号量发送函数,最终内核会响应我们的SIGKILL,杀掉进程。
我们已经了解了基于Unix的三种通信方式以及他们在Android系统上的应用,我们接着来看看另外三种IPC通信方式,消息队列,信号量和共享内存。这三种IPC方式有基于SystemV和基于Posix的两个版本,由于有些Linux系统并没有实现基于POSIX的IPC,所以这儿就只说SystemV的IPC了,他们在本质上其实都是相似的。
消息队列
消息队列的使用和原理
我们首先看看消息队列的创建及其如何使用
#include 我们可以通过**msgget()**函数来创建消息队列,它会在内核空间创建一个消息链表,**msgsend()**函数往消息队列发送消息,msgrcv()函数获取消息队列里的数据。
通过消息发送和接收函数可以看到,消息队列的每个消息消息都有msgid,msgtype,msgflg字段,msgid是消息的队列标识符,msgtype是消息的类型,发送函数中放在msg_ptr这个结构体里,msgflg用来控制读取消息时队列已满或者队列为空时的操作。
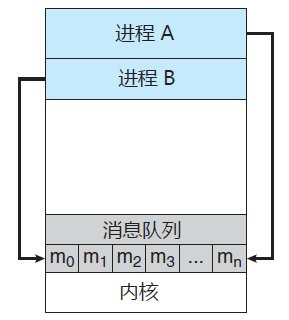
我在这里介绍一下消息队列的数据结构,它是一个消息的链表,存放在内核中并由消息队列标识符标识,也就是上面提到的msgid,标识符标识用大于0的整数表示,并且每中标识符的消息队列都有自己的链表。它的表现结构如下图:
消息队列有哪些优点呢?它克服了Linux早期IPC机制的很多缺点,比如消息队列具有异步能力,又克服了具有同样能力的信号承载信息量少的问题;具有数据传输能力,又克服了管道只能承载无格式字节流以及缓冲区大小受限的问题。但是缺点是消息队列比信号和管道都要更加重量,在内核中会使用更多内存,并且消息队列能传输的数据也有限制,一般上限都是16kb。
消息队列在Android中的使用场景
受限于性能,数据量等问题的限制,Android系统没有直接使用Linux消息队列来进行IPC的场景,但是有大量的场景都利用了消息队列的特性来设计通信方案,比如我们最频繁使用的Handler,就是一个消息队列,由于Handler只是进程内的通信方式,所以它的实现不在这儿讨论,消息队列的架构模型被非常多的场景使用,主要有下面几个有点原因。
- 解耦:消息队列可以实现两个模块之间的解耦,两个需要通信的模块不需要之间对接,发送方只需要将消息丢到队列,接收方只需要从队列里面取消息。
- 异步:我们可以将多条消息并行的发送给消息队列,然后不同的模块去并行的处理,在这种方案下,我们不需要串行的处理任务。
- 缓冲:消息队列的数据结构就是一个缓冲池,可以帮助我们减轻流量过大的压力。
关于消息队列的介绍就讲到这儿了,它并不是一个常用的Linux IPC通信方式,我们接着信号量。
信号量
信号量的使用和原理
信号量和信号是不同的IPC通信机制,信号量是在进程之间传递是一个整数值,信号量只有三种操作可以进行:初始化,P操作,V操作,我们看一下具体的使用函数和数据结构。
#include我们通过semget()函数获取或者创建一个信号量,并返回一个信号量id,有了这个id,我们就可以通过semop()函数进行V和P的操作。V就是将这个信号量加1,P就是将信号量减1。这三种操作都是原子操作,我们通常用信号量来进行并发和同步的控制。
讲到了信号量,不免要提一下互斥锁Mutex,信号量可以是非负整数,互斥锁只能是0和1两个值,我们可以将Mutex理解为特殊的信号量。在大部分情况下,用互斥锁来做并发的控制会比信号量更方便。关于Android或者Java的线程并发,我会专门写一篇文章来讲,也就不在这儿再继续深入讲了。
共享内存
共享内存的使用和原理
还是先看共享内存的使用方法,我主要介绍两个函数:
#include 通过**shmget()**函数申请共享内存,它的入参如下
- key:用来唯一确定这片内存的标识,。
- size:就是我们申请内存的大小
- shmflg:读写权限
- 返回值:这个操作会返回一个id, 我们一般称为 shmid
通过**shmat()**函数将我们申请到的共享内存映射到自己的用户空间,映射成功会返回地址,有了这个地址,我们就可以随意的读写数据了,我们继续看一下这个函数的入参
- shmid :我们申请内存时, 返回的shmid
- shmaddr:共享内存在进程的内存地址,传NULL让内核自己决定一个合适的地址位置.
- shmflg:读写权限
- 返回值:映射后进程内的地址指针, 代表内存的头部地址
共享内存的原理是在内存中单独开辟的一段内存空间,这段内存空间其实就是一个tempfs(临时虚拟文件),tempfs是VFS的一种文件系统,挂载在/dev/shm上,前面提到的管道pipefs也是VFS的一种文件系统。
由于共享的内存空间对使用和接收进程来讲,完全无感知,就像是在自己的内存上读写数据一样,所以也是效率最高的一种IPC方式,上面提到的IPC的方式都是在内核空间中开辟内存来存储数据,写数据时,需要将数据从用户空间拷贝到内核空间,读数据时,需要从内核空间拷贝到自己的用户空间,而共享内存就只需要一次拷贝,而且共享内存不是在内核开辟空间,所以可以传输的数据量大。
但是共享内存最大的缺点就是没有并发的控制,我们一般通过信号量配合共享内存使用,进行同步和并发的控制。
Android中共享内存的使用场景
共享内存在Android系统中主要的使用场景是用来传输大数据,并且Android并没有直接使用Linux原生的共享内存方式,而是设计了Ashmem匿名共享内存。之前说到有名管道和匿名管道的区别在于有名管道可以在vfs目录树中查看到这个管道的文件,但是匿名管道不行,所以匿名共享内存同样也是无法在vfs目录中查看到的,Android之所以要设计匿名共享内存,我觉得主要是为了安全性的考虑吧。
我们来看看共享内存的一个使用场景,在Android中,如果我们想要将当前的界面显示出来,需要将当前界面的图元数据传递Surfaceflinger去做图层混合,图层混合之后的数据会直接送入帧缓存,送入帧缓存后,显卡就会直接取出帧缓存里的图元数据显示了。那么我们如何将应用的Activity的图元数据传递给SurfaceFlinger呢?想要将图像数据这样比较大的数据跨进程传输,靠binder是不行的,所以这儿便用到匿名共享内存。
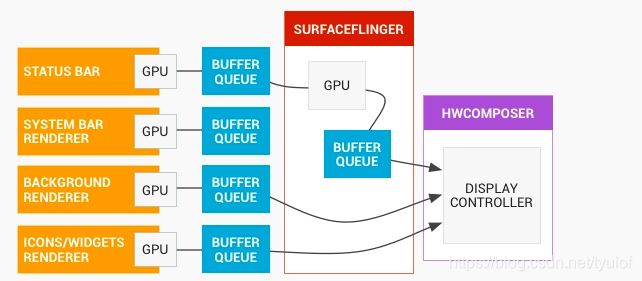
从谷歌官方提供的架构图可以看到,图元数据是通过BufferQueue传递到SurfaceFlinger去的,当我们想要绘制图像的时候,需要从BufferQueue中申请一个Buffer,Buffer会调用Gralloc模块来分配共享内存当作图元缓冲区存放我们的图元数据。我们看一下代码的实现。
//文件-->hardware/libhardware/modules/gralloc/gralloc.cpp
static int gralloc_alloc_buffer(alloc_device_t* dev,
size_t size, int usage, buffer_handle_t* pHandle)
{
int err = 0;
int fd = -1;
size = roundUpToPageSize(size);
// 创建共享内存,并且设定名字跟size
fd = ashmem_create_region("gralloc-buffer", size);
if (err == 0) {
private_handle_t* hnd = new private_handle_t(fd, size, 0);
gralloc_module_t* module = reinterpret_cast<gralloc_module_t*>(
dev->common.module);
// 执行mmap,将内存映射到自己的进程
err = mapBuffer(module, hnd);
if (err == 0) {
*pHandle = hnd;
}
}
return err;
}
int mapBuffer(gralloc_module_t const* module,
private_handle_t* hnd)
{
void* vaddr;
return gralloc_map(module, hnd, &vaddr);
}
static int gralloc_map(gralloc_module_t const* module,
buffer_handle_t handle,
void** vaddr)
{
private_handle_t* hnd = (private_handle_t*)handle;
if (!(hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER)) {
size_t size = hnd->size;
//映射创建的匿名共享内存
void* mappedAddress = mmap(0, size,
PROT_READ|PROT_WRITE, MAP_SHARED, hnd->fd, 0);
if (mappedAddress == MAP_FAILED) {
return -errno;
}
hnd->base = intptr_t(mappedAddress) + hnd->offset;
}
*vaddr = (void*)hnd->base;
return 0;
}
可以看到Android的匿名共享内存是通过ashmem_create_region() 函数来申请共享内存的,它会在/dev/ashmem下创建一个虚拟文件,Linux原生共享内存是通过shmget()函数,并会在/dev/shm下创建虚拟文件。
匿名共享内存是通过**mmap()**函数将申请到的内存映射到自己的进程空间,而Linux是通过*shmat()函数。虽然函数不一样,但是Android的匿名共享内存和Linux的共享内存在本质上是大同小异的。
Socket
Socket的使用和原理
socket套接字本来是设计给基于TCP/IP协议的网络通信使用的,但由于它是一种C/S架构模型,即客户端服务器端架构,这种模型能带来很大的安全性以及快速的响应能力,所以也常常用在进程之间的通信上。Socket的使用方式比上面前面提到的其他IPC都要复杂很多,我们先通过下图了解它的使用流程。
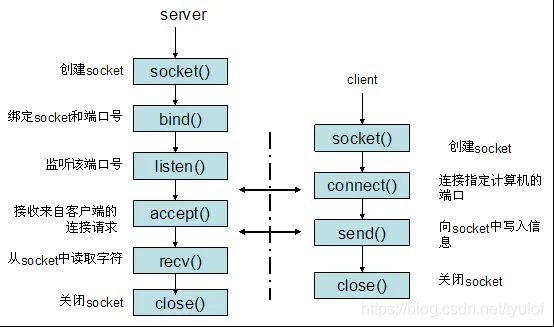
我们在看看具体的函数
#include Linux系统中万物皆文件,所以Socket也是一个虚拟文件,socket文件的数据结构中包含了当前主机的ip地址,当前主机进程的端口号,发送端主机的ip地址等信息,通过这些信息,我们可以在虚拟文件系统中唯一定位到一个Socket文件,通过对这个文件的读写达到通信的目的。
Socket在Android系统中的使用场景
当我们使用socket来进行进程间的通信时,实际是通过将IP设置为127.0.0.1这个本地IP来实现的,Android系统为我们提供了LocalSocket来进行进程间的通信,LocalSocket的实质也是对Socket的封装,通过直接使用LocalSocket,我们省掉了设置本机IP等一系列繁琐的操作。
我们看一个LocalSocket的使用场景:当我们启动一个App应用时,如果当前的应用的进程不存在,AMS会通过Socket通知Zygote去Fork新进程。它的代码实现如下。
//文件-->frameworks/base/core/java/com/android/internal/os/ZygoteInit.java
// 服务端
public static void main(String argv[]) {
ZygoteServer zygoteServer = new ZygoteServer();
……
zygoteServer.registerServerSocket(socketName);
……
Log.i(TAG, "Accepting command socket connections");
zygoteServer.runSelectLoop(abiList);
zygoteServer.closeServerSocket();
……
}
ZygoteInit启动时,会创建一个ZygoteServer,然后fork生成System Server进程,接着启动整个Framwork的Server,最终执行zygoteServer的runSelectLoop函数,始终等待其他进程发送过来的fork进程的消息。在上面的代码中,我只展示了ZygoteServer相关的代码,启动System Server等其他流程的代码我全部省略了,有兴趣的可以去看看这一块的源码。我们接着看registerServerSocket函数和runSelectLoop函数的实现
//文件-->/frameworks/base/core/java/com/android/internal/os/ZygoteServer.java
void registerServerSocket(String socketName) {
if (mServerSocket == null) {
int fileDesc;
final String fullSocketName = ANDROID_SOCKET_PREFIX + socketName;
try {
String env = System.getenv(fullSocketName);
fileDesc = Integer.parseInt(env);
} catch (RuntimeException ex) {
throw new RuntimeException(fullSocketName + " unset or invalid", ex);
}
try {
FileDescriptor fd = new FileDescriptor();
fd.setInt$(fileDesc);
mServerSocket = new LocalServerSocket(fd);
} catch (IOException ex) {
throw new RuntimeException(
"Error binding to local socket '" + fileDesc + "'", ex);
}
}
}
void runSelectLoop(String abiList) throws Zygote.MethodAndArgsCaller {
ArrayList<FileDescriptor> fds = new ArrayList<FileDescriptor>();
ArrayList<ZygoteConnection> peers = new ArrayList<ZygoteConnection>();
fds.add(mServerSocket.getFileDescriptor());
peers.add(null);
while (true) {
StructPollfd[] pollFds = new StructPollfd[fds.size()];
for (int i = 0; i < pollFds.length; ++i) {
pollFds[i] = new StructPollfd();
pollFds[i].fd = fds.get(i);
pollFds[i].events = (short) POLLIN;
}
try {
Os.poll(pollFds, -1);
} catch (ErrnoException ex) {
throw new RuntimeException("poll failed", ex);
}
for (int i = pollFds.length - 1; i >= 0; --i) {
if ((pollFds[i].revents & POLLIN) == 0) {
continue;
}
if (i == 0) {
ZygoteConnection newPeer = acceptCommandPeer(abiList);
peers.add(newPeer);
fds.add(newPeer.getFileDesciptor());
} else {
boolean done = peers.get(i).runOnce(this);
if (done) {
peers.remove(i);
fds.remove(i);
}
}
}
}
}
可以看到registerServerSocket函数实际是创建了LocalServerSocket,这个LocalServerSocket的名字就叫“zygote”,runSelectLoop函数将ServerSocket加入多路复用模型里,当收到消息时便调用runOnce方法去fork进程。
我们已经了解了Server端了,我们接着看一下Client端
//文件-->/frameworks/base/core/java/android/os/Process.java
//客户端
public static final ProcessStartResult start(final String processClass,
final String niceName,
int uid, int gid, int[] gids,
int debugFlags, int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String invokeWith,
String[] zygoteArgs) {
return zygoteProcess.start(processClass, niceName, uid, gid, gids,
debugFlags, mountExternal, targetSdkVersion, seInfo,
abi, instructionSet, appDataDir, invokeWith, zygoteArgs);
}
//文件-->/frameworks/base/core/java/android/os/ZygoteProcess.jav
public final Process.ProcessStartResult start(final String processClass,
final String niceName,
int uid, int gid, int[] gids,
int debugFlags, int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String invokeWith,
String[] zygoteArgs) {
try {
return startViaZygote(processClass, niceName, uid, gid, gids,
debugFlags, mountExternal, targetSdkVersion, seInfo,
abi, instructionSet, appDataDir, invokeWith, zygoteArgs);
} catch (ZygoteStartFailedEx ex) {
Log.e(LOG_TAG,
"Starting VM process through Zygote failed");
throw new RuntimeException(
"Starting VM process through Zygote failed", ex);
}
}
private Process.ProcessStartResult startViaZygote(final String processClass,
final String niceName,
final int uid, final int gid,
final int[] gids,
int debugFlags, int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String invokeWith,
String[] extraArgs)
throws ZygoteStartFailedEx {
……
synchronized(mLock) {
//连接服务端socket,并发送数据
return zygoteSendArgsAndGetResult(openZygoteSocketIfNeeded(abi), argsForZygote);
}
}
private ZygoteState openZygoteSocketIfNeeded(String abi) throws ZygoteStartFailedEx {
if (primaryZygoteState == null || primaryZygoteState.isClosed()) {
try {
primaryZygoteState = ZygoteState.connect(mSocket);
} catch (IOException ioe) {
throw new ZygoteStartFailedEx("Error connecting to primary zygote", ioe);
}
}
……
}
public static ZygoteState connect(String socketAddress) throws IOException {
DataInputStream zygoteInputStream = null;
BufferedWriter zygoteWriter = null;
final LocalSocket zygoteSocket = new LocalSocket();
zygoteSocket.connect(new LocalSocketAddress(socketAddress,
LocalSocketAddress.Namespace.RESERVED));
zygoteInputStream = new DataInputStream(zygoteSocket.getInputStream());
zygoteWriter = new BufferedWriter(new OutputStreamWriter(
zygoteSocket.getOutputStream()), 256);
return new ZygoteState(zygoteSocket, zygoteInputStream, zygoteWriter,
Arrays.asList(abiListString.split(",")));
}
private static Process.ProcessStartResult zygoteSendArgsAndGetResult(
ZygoteState zygoteState, ArrayList<String> args)
throws ZygoteStartFailedEx {
int sz = args.size();
for (int i = 0; i < sz; i++) {
if (args.get(i).indexOf('\n') >= 0) {
throw new ZygoteStartFailedEx("embedded newlines not allowed");
}
}
final BufferedWriter writer = zygoteState.writer;
final DataInputStream inputStream = zygoteState.inputStream;
writer.write(Integer.toString(args.size()));
writer.newLine();
for (int i = 0; i < sz; i++) {
String arg = args.get(i);
writer.write(arg);
writer.newLine();
}
writer.flush();
Process.ProcessStartResult result = new Process.ProcessStartResult();
result.pid = inputStream.readInt();
result.usingWrapper = inputStream.readBoolean();
if (result.pid < 0) {
throw new ZygoteStartFailedEx("fork() failed");
}
return result;
}
从上面的代码实现可以看到,当AMS调用Process的start()函数时,最终执行到了ZygoteProcess类中的openZygoteSocketIfNeeded() 函数,连接socket,然后调用zygoteSendArgsAndGetResult() 函数通过LocalSocket 往LocalServerSocket发送消息 。
为什么Android fork进程要用Socket,而不用Binder呢?这个问题留给大家去思考。
mmap函数
mmap是一个很重要的函数,它可以实现共享内存,但并不像SystemV和Posix的共享内存存粹的只用于共享内存,mmap()的设计,主要是用来做文件的映射的,它提供了我们一种新的访问文件的方案。
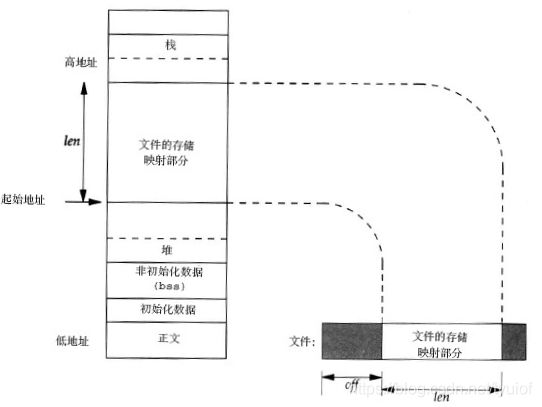
mmap函数的使用非常简单,我们来看一下
#include - addr:用于指定映射到进程空间的起始地址,为了应用程序的可移植性,一般设置为NULL,让内核来选择一个合适的地址
- length:表示映射到进程地址空间的大小
- prot:用于设置内核映射区域的读写属性等。
- flags:用于设置内存映射的属性,例如共享映射、私有映射等。
- fd:表示这个是一个文件映射,fd是打开文件的句柄。
- offset:在文件映射时,表示文件的偏移量。
常规文件操作为了提高读写效率和保护磁盘,使用了页缓存机制,这种机制会造成读文件时需要先将文件页从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中。这样,通过了两次数据拷贝过程,才能完成进程对文件内容的获取任务。写操作也是一样,待写入的buffer在内核空间不能直接访问,必须要先拷贝至内核空间对应的主存,再写回磁盘中(延迟写回),也是需要两次数据拷贝。
而使用mmap操作文件中,由于不需要经过内核空间的数据缓存,只使用一次数据拷贝,就从磁盘中将数据传入内存的用户空间中,供进程使用。
mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程,因此mmap效率很高。
Android中mmap()的使用场景
mmap()使用非常频繁,看过Android系统源码的人,肯定看到过大量的地方使用mmap()函数,比如上面提到的匿名共享内存的使用就使用到了mmap来映射/dev/ashmem里的文件。
这里我再介绍一种mmap()在Android系统上的使用场景,mmap的设计目的就是为了让文件的访问更有效率,所以当APK进行安装时,为了更高效的读取APK包里面的文件,同样也用到了mmap函数。Dalvik在安装应用时,需要加载dex文件,然后进行odex优化处理,优化函数为dvmContinueOptimization,我们看一下他的大致实现。
bool dvmContinueOptimization(int fd, off_t dexOffset, long dexLength,
const char* fileName, u4 modWhen, u4 crc, bool isBootstrap)
{
……
//通过mmap映射dex文件
mapAddr = mmap(NULL, dexOffset + dexLength, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if (mapAddr == MAP_FAILED) {
ALOGE("unable to mmap DEX cache: %s", strerror(errno));
goto bail;
}
……
//验证和优化dex文件
success = rewriteDex(((u1*) mapAddr) + dexOffset, dexLength,
doVerify, doOpt, &pClassLookup, NULL);
……
//取消文件映射
if (munmap(mapAddr, dexOffset + dexLength) != 0) {
ALOGE("munmap failed: %s", strerror(errno));
goto bail;
}
……
bail:
dvmFreeRegisterMapBuilder(pRegMapBuilder);
free(pClassLookup);
return result;
}
可以看到,dvmContinueOptimization函数中对dex文件的加载便用了mmap内存映射函数。
eventfd
eventfd 是 Linux 2.6.22后才开始支持的一种IPC通信方式,它的作用主要时用来做事件通知,并且完全可以替代pipe,对于内核来说,eventfd的开销更低,eventfd只需要创建一个虚拟文件,而pipe需要创建两个,并且可用于select或epoll等多路复用模型中,来实现异步的信号通知功能。所以eventfd 是很好用的一种IPC方式,而且它的使用也简单。
#includeeventfd在内核里的核心是一个计数器counter,它是一个uint64_t的整形变量counter,初始值为initval。
当调用read() 函数读取eventfd时,会根据counter值执行下列操作:
- 如果当前counter > 0,那么read返回counter值,并重置counter为0;
- 如果当前counter等于0,那么read 函数阻塞直到counter大于0,如果设置了NONBLOCK,那么返回-1。
当调用write() 往eventfd写数据时,我们只能写入一个64bit的整数value
Eventfd在Android中的使用场景
正是因为eventfd比管道更简单高效,所以在Android6.0之后,Looper的唤醒就换成了eventfd。
Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mPolling(false), mEpollFd(-1), mEpollRebuildRequired(false),
mNextRequestSeq(0), mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
mWakeEventFd = eventfd(0, EFD_NONBLOCK);
LOG_ALWAYS_FATAL_IF(mWakeEventFd < 0, "Could not make wake event fd. errno=%d", errno);
AutoMutex _l(mLock);
rebuildEpollLocked();
}
void Looper::wake() {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ wake", this);
#endif
uint64_t inc = 1;
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
if (nWrite != sizeof(uint64_t)) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}
可以看到,Looper的构造函数中mWakeEventFd已经由之前提到的pipe换成了evnentfd,wake()函数也不是之前的写入一个“w”字符,而是写入了一个64位整数1。
Binder
终于讲到Android的最后一种IPC的通信机制Binder了,有人会疑问,为什么AIDL,BroadCast,Content Provider这些不是Android的IPC机制呢?这些方式其实也是Android的IPC方式,但是他们的底层都是基于Binder实现的。
Binder的机制比较复杂,由于这篇文章只是为了横向介绍Android的IPC机制,所以不会对Binder有太过深入的讲解,也不会在这儿介绍基于binder实现的BroadCast,Content Provider等IPC方式,这些我之后会写文专门讲解。我们主要了解一下Binder的架构及其设计思想。
Linux已经有了前面提到的这么多的IPC方式了,为什么还要设计Binder呢?我觉得主要有三个原因的考虑。
- 通信效率
- 安全问题
- 并发问题
在上面提到的所有的IPC中,只有共享内存效率是最高,但是直接使用共享内存会有并发问题和安全问题
我们先来解决安全问题。如果想要解决安全问题,我们可以采用C/S架构或者匿名的IPC通信机制,匿名的IPC通信机制无疑会影响进程间通信的方便性,比如匿名管道,就只能在亲属进程间通信。所以我们需要采用C/S的架构,在C/S架构下,Server端可以对Client端的请求做校验来保证安全性。
接着我们需要解决并发问题,解决并发问题我们可以采用消息队列,或者通过锁来控制并发情况,或者采用C/S架构。
在这三者的考虑下,我们发现只有采用C/S架构的共享内存才是最高效的。所以我们的Binder本质上就是C/S架构的共享内存的IPC机制。
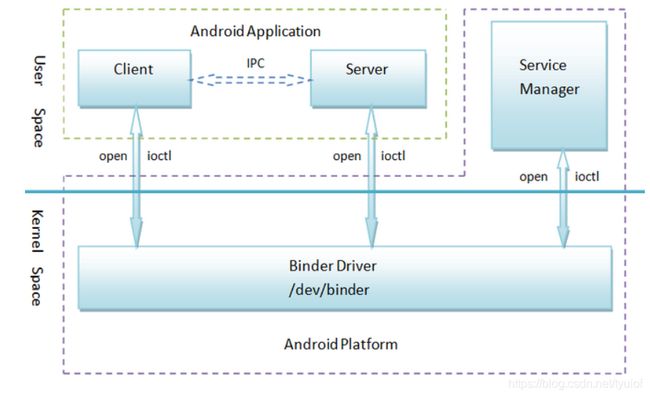
从架构图可以看到,Binder其实是挂载在/dev/binder下的一个虚拟文件。我们可能猜测,Clinet端和Server端通过前面提到的mmap()文件映射函数,将/dev/binder下的文件映射到自己的用户空间中,这样Client端直接往这块内容写数据,Server也能同时读取文件了。
但实际不是这样的。Binder的机制其实是通过将/dev/binder下的文件同时映射到Server端的用户空间和内核空间,在这种情况下,Server端想要读写这一块内容时,就不需要执行将数据从用户空间拷贝内核空间,或者将数据从内核空间拷贝到用户空间的操作了。我们的Client端只需要通过将数据写入内核空间,Server端的用户空间便能直接读取这块数据了。
为什么binder的设计不采用上面这种方案,而采用下面的方案呢?因为上面的方案其实就是和共享内存的方案是一模一样了。采用下面的方案,Client写数据时,依然会陷入内核,内核函数此时可以充当Server的角色。
总结
自此,Android的IPC通信机制全部讲完了,受限于篇幅问题,有很多地方没有深入展开,比如Binder,如果深入展开又需要写非常长了。写这篇文章的目的,主要是想通过对Android IPC机制广度的认识,来达到更加深入思考的目的。比如为什么Android要设计Binder,Binder的优缺点是什么,如果让我们自己设计IPC,需要怎么设计?在我看来,我觉得Binder还是有一些缺点的,比如相比于Linux自身的IPC通信,它的内存占用过多,使用太过复杂,而且数据传输量有限制。又比如,Linux系统自带的IPC机制优缺点又是什么?它会往什么样的方向发展?2.6.22内核中为什么要新出eventfd这种IPC,接下来的内核中,又可能出现哪些IPC机制呢?Linux的图形操作系统中,如Ubuntu等系统的应用程序进行IPC时是采用的哪种IPC呢?
有很多问题,我自己也不清楚。只能说技术这条路,路漫漫其修远兮,吾将上下而求索。
欢迎关注个人技术公众号,坚持更新,坚持只写高质量文章,坚持探索技术的本质。
