shell脚本之函数与数组
文章目录
- 一、shell函数
-
- 1.1 函数的作用
- 1.2 函数的基本格式
- 1.3 函数的调用
- 1.4 函数的返回值
- 1.5 函数的传参
- 1.6 本地变量与全局变量
- 1.7 函数的递归
- 二、数组
-
- 2.1 shell 数组的定义
- 2.2 数组的定义方式
- 2.3.数组常见用法
- 三、冒泡排序
一、shell函数
1.1 函数的作用
1.语句块定义成函数约等于别名,定义函数,再引用函数
2.封装的可重复利用的具有特定功能的代码
1.2 函数的基本格式
格式1:
function 函数名 {
command
} ###这是一种规范写法
格式2:
函数名(){
command
} ###最常用因为最简洁
1.3 函数的调用
直接在脚本里定义函数的代码块后写函数名即可完成调用
示例:
[root@host ~]# vim sy1.sh
#!/bin/bash
function f { ###定义一个函数叫f
echo "hello world!" ###函数的功能是打印“hello world!”
}
f ###直接写函数名就会运行函数内的代码
[root@host ~]# sh sy1.sh
hello world!


注:函数名必须是唯一,如果先定义了一个,再用同样的名称定义,第二个会覆盖第一个的功能,出现了你不想要的结果,所以这里一定要注意不要重名!
[root@host ~]# vim kk.sh
#!/bin/bash
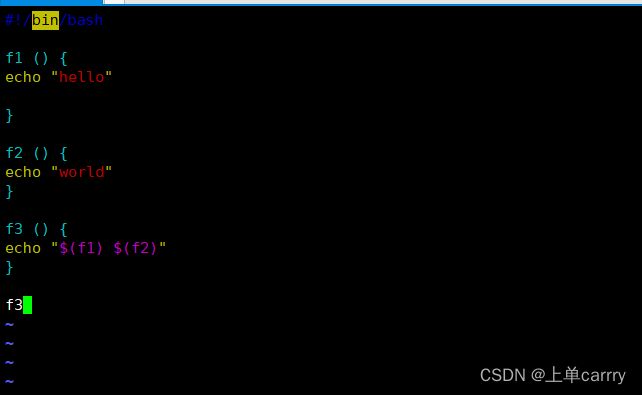
f1 () {
echo "hello"
}
f2 () {
echo "world"
}
f3 () {
echo "$(f1) $(f2)"
}
f3
[root@host ~]# sh kk.sh
hello world

1.4 函数的返回值
return表示退出函数并返回一个退出值,脚本中可以用$?变量表示该值
函数的使用原则:
1.函数一结束就取返回值,因为$?变量只返回执行的最后一条命令的退出状态码;
2.退出状态码必须是0~255,超出时值将为除以256取余。
示例:
[root@host ~]# vim kk.sh
#!/bin/bas
user () {
if [ $USER = root ]
then
echo "这是管理员用户"
else
echo "这不是管理员用户"
return 1
fi
}
user
[root@host ~]# sh kk.sh
这是管理员用户
[root@host ~]# echo $?
0
[root@host ~]# su lu
[root@host ~]$ sh kk.sh
这不是管理员用户
[lu@localhost ~]$ echo $?
1


1.5 函数的传参
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…即使用位置参数来实现参数传递。
示例:
两个数求和
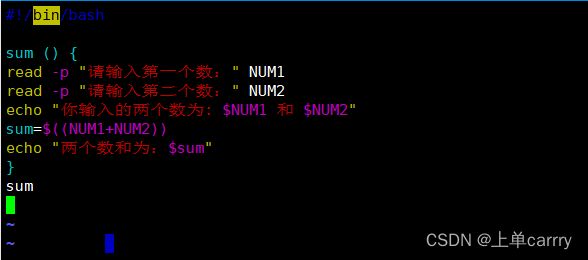
[root@host ~]# vim kkk.sh
#!/bin/bash
sum () {
read -p "请输入第一个数:" NUM1
read -p "请输入第二个数:" NUM2
echo "你输入的两个数为: $NUM1 和 $NUM2"
sum=$((NUM1+NUM2))
echo "两个数和为:$sum"
}
sum
[root@host ~]# sh kkk.sh
请输入第一个数:6
请输入第二个数:66
你输入的两个数为: 6 和 66
两个数和为:72

案例:
阶乘
[root@host ~]# vim kkk.sh
#!/bin/bash
jc () {
che=1
for i in {1..5}
do
let che=$i*$che
done
echo $che
}
jc
[root@host ~]# sh kkk.sh
120
优化版:根据需求算几阶的阶乘
[root@host ~]# vim kkk.sh
#!/bin/bash
jc () {
che=1
read -p "请输入您想算的阶乘:" num
for i in `seq $num`
do
let che=$i*$che
done
echo $che
}
jc
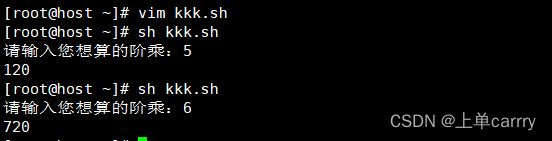
[root@host ~]# sh kkk.sh
请输入您想算的阶乘:5
120
[root@host ~]# sh kkk.sh
请输入您想算的阶乘:6
720


优化

1.6 本地变量与全局变量
在脚本里定义的变量或者在函数体没有声明为本地变量的都为全局变量,意思是在当前shell环境都识别
如果需要这个变量只在函数中使用则可以在函数中用local关键字声明,这样即使函数体外有个重名的变量也没关系,不影响在函数体的使用
如果是用source执行脚本的话就能看出差别
在外部调用命令需要先source一下。然后调用函数,再调用函数中的变量
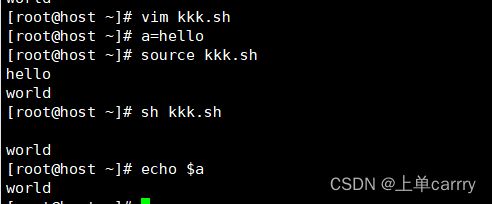
[root@host ~]# a=hello
[root@host ~]# vim kkkk.sh
#!/bin/bash
f1 () {
echo $a
a=world
echo $a
}
f1
[root@host ~]# source kkkk.sh ###用source执行脚本,会发现a的值改变了
hello
world
[root@host ~]# echo $a
world

在函数体中用local定义变量a的值
[root@localhost ~]# vim kkkk.sh
#!/bin/bash
f1 () {
echo $a
local a=world
echo $a
}
f1
[root@localhost ~]# source kkkk.sh ###执行脚本发现a的值并没有改变
world
world
1.7 函数的递归
函数自己调用自己的本身
列出目录内文件列表,目录用蓝色表示,文件显示层级关系
[root@host ~]# vim kkkk.sh
#!/bin/bash
list(){
for i in $1/*
do
if [ -d $i ];then
echo -e "\e[34m$i\e[0m"
list $i " $2"
else
echo "$2$i"
fi
done
}
list $1 $2
[root@localhost ~]# sh kkkk.sh /home
/home/kk
/home/kk/*
/home/lu
/home/lu/公共
/home/lu/公共/*
/home/lu/模板
/home/lu/模板/*
/home/lu/视频
/home/lu/视频/*
/home/lu/图片
/home/lu/图片/*
/home/lu/文档
/home/lu/文档/*
/home/lu/下载
/home/lu/下载/*
/home/lu/音乐
/home/lu/音乐/*
/home/lu/桌面
/home/lu/桌面/*

二、数组
2.1 shell 数组的定义
1.数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组)
2.数组元素的下标由 0 开始。
3.Shell 数组用括号来表示,元素用"空格"符号分割开
4.在shell语句中,使用、遍历数组的时候,数组格式要写成 ${arr[@]} 或 ${arr[*]}
数组是存放相同类型数据的集合,在内存中开辟了连续的空间,通常配合循环使用
数组的分类:
普通数组:不需要声明直接定义,下标索引只能是整数
关联数组:需要用declare -A 声明 否则系统不识别,索引可以是字符串
2.2 数组的定义方式
第一种:直接把要加入数组的元素用小括号括起来,中间用空格分开
num= ( 11 22 33 44 )
${ #num} 显示字符串长度
数组名=(value0 value1 value2)
第二种:精确的给每一个下标索引定义一个值加入数组,索引数字可以不连续
num= ( [ 0 ]=55 [ 1 ]=66 [ 2 ]=77 [ 4 ]=88)
数组名=( [ 0 ]=value [ 1 ]=value [ 2 ]=value. . . )
第三种:先把要加入数组的元素全部先赋值给一个变量,然后引用这个变量加入到数组。
list="11 12 13 14"
num=($list)
列表名="value0 value1 value2..."
数组名=($列表名)
第四种:根据下标定义
数组名[0]="11"
数组名[1]="22"
数组名[2]="33"
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"
2.3.数组常见用法
1.获取数组的长度
[root@host ~]# ar_number=(10 20 30 40 50)
[root@host ~]#ar_length=${#ar_number[*]}
[root@host ~]# echo $ar_length
5
[root@host ~]# ar_number=(10 20 30 40 50)
[root@host ~]# ar_length=${#ar_number[@]}
[root@host ~]# echo $ar_length
5
2.数组元素遍历
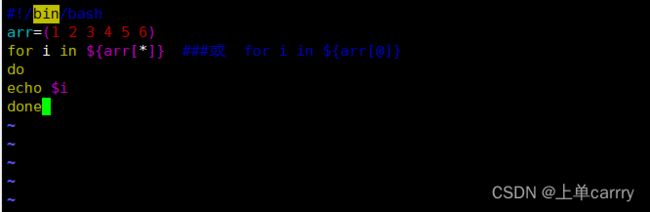
[root@host ~]# vim kkkk.sh
#!/bin/bash
arr=(1 2 3 4 5 6)
for i in ${arr[*]} ###或 for i in ${arr[@]}
do
echo $i
done
[root@host ~]## sh kkkk.sh
1
2
3
4
5

3.元素切片
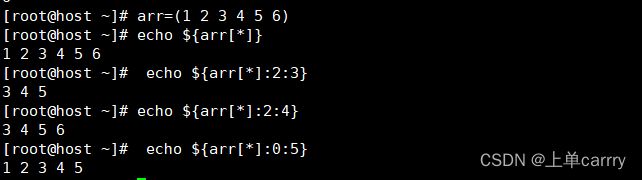
[root@host ~]# arr=(1 2 3 4 5 6)
[root@host ~]# echo ${arr[*]}
1 2 3 4 5 6
[root@host ~]# echo ${arr[*]:2:3}
3 4 5
[root@host ~]# echo ${arr[*]:2:4}
3 4 5 6
[root@host ~]# echo ${arr[*]:0:5}
1 2 3 4 5
4.数组元素替换
临时替换
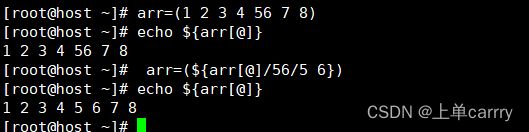
[root@host ~]# arr=(1 2 3 4 56 7 8)
[root@host ~]# echo ${arr[*]}
1 2 3 4 56 7 8
[root@host ~]# echo ${arr[*]/56/5 6}
1 2 3 4 5 6 7 8
[root@host ~]# echo ${arr[*]}
1 2 3 4 56 7 8
永久替换
[root@host ~]# arr=(1 2 3 4 56 7 8)
[root@host ~]# echo ${arr[@]}
1 2 3 4 56 7 8
[root@host ~]# arr=(${arr[@]/56/5 6})
[root@host ~]# echo ${arr[@]}
1 2 3 4 5 6 7 8
5.数组删除
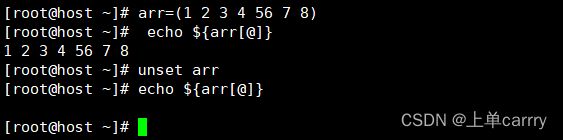
删除整个数组
[root@host ~]# arr=(1 2 3 4 56 7 8)
[root@host ~]# echo ${arr[@]}
1 2 3 4 56 7 8
[root@host ~]# unset arr
[root@host ~]# echo ${arr[@]}
[root@host ~]#
删除数组中的元素
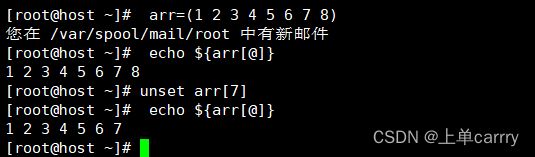
[root@host ~]# arr=(1 2 3 4 5 6 7 8)
[root@host ~]# echo ${arr[@]}
1 2 3 4 5 6 7 8
[root@host ~]# unset arr[7]
[root@host ~]# echo ${arr[@]}
1 2 3 4 5 6 7
三、冒泡排序
1.定义:
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动
2.基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部
3.算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少
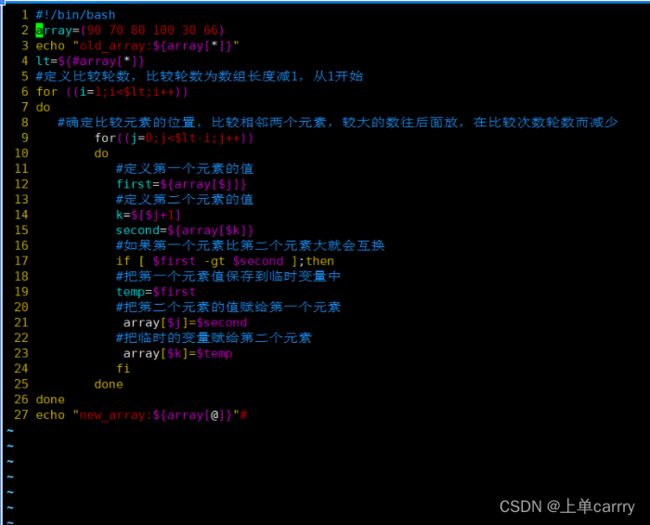
4.冒泡排序案例:
#!/bin/bash
array=(90 70 80 100 30 66)
echo "old_array:${array[*]}"
lt=${#array[*]}
#定义比较轮数,比较轮数为数组长度减1,从1开始
for ((i=1;i<$lt;i++))
do
#确定比较元素的位置,比较相邻两个元素,较大的数往后面放,在比较次数轮数而减少
for((j=0;j<$lt-i;j++))
do
#定义第一个元素的值
first=${array[$j]}
#定义第二个元素的值
k=$[$j+1]
second=${array[$k]}
#如果第一个元素比第二个元素大就会互换
if [ $first -gt $second ];then
#把第一个元素值保存到临时变量中
temp=$first
#把第二个元素的值赋给第一个元素
array[$j]=$second
#把临时的变量赋给第二个元素
array[$k]=$temp
fi
done
done
echo "new_array:${array[@]}"