shell脚本之函数、数组以及冒泡排序
目录
一、shell函数
1.1.函数的定义
(1)函数的格式
(2)函数返回值
1.2.函数的调用
1.3.return
1.4.函数的传参
1.5.函数的作用范围
1.6.函数的案例
阶乘
搭建本地yum仓库
二、数组
2.1.数组的定义
2.2.数组的表示方法
2.3.数组常见用法
(1)获取数组的长度
(2)数组元素遍历
(3)元素切片
(4)数组元素替换
(5)数组删除
三、冒泡排序
(1)定义
(2)冒泡排序案例
四、总结
一、shell函数
1.1.函数的定义
(1)函数的格式
①
function 函数名 {
command
}
②
函数名(){
command
} (2)函数返回值
return表示退出函数并返回一个退出值,脚本中可以用$?变量显示该值。
使用原则:
- 函数一结束就取返回值,因为$?变量只返回执行的最后一条命令的退出状态码。
- 退出状态码必须是0~255,超出时值将为取余256 。
1.2.函数的调用
直接在脚本里定义函数的代码块后写函数名即可完成调用。
#!/bin/bash
function fun1 { //定义了一个函数叫做fun1
echo "this is a function!" //函数体的功能是打印"this is a function!
}
fun1 //直接写函数名就会运行函数体内的代码(调用函数)

注意①:函数名必须是唯一,如果先定义了一个,再用同样的名称定义,第二个会覆盖第一个的功能,出现了你不想要的结果,所以这里一定要注意不要重名。
#!/bin/bash
f1 (){
echo hello
}
f1 (){
echo world
}
f1


注意②:调用函数之前必须先进行定义。
#!/bin/bash
f1 (){
echo hello
}
f3 (){
echo "$(f1) $(f2)"
}
f2 (){
echo world
}
f3
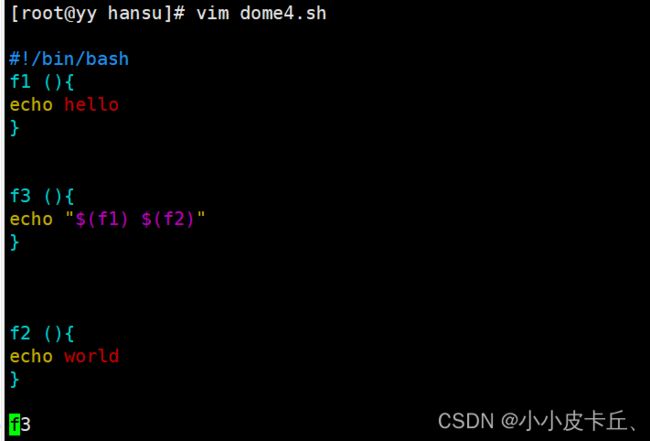

#!/bin/bash
f1 (){
echo hello
}
f3 (){
echo "$(f1) $(f2)"
}
f3
f2 (){
echo world
}
[root@root hansu]# sh dome4.sh //因为f3函数里调用了f2,调用了f3的时候并不能知道f2的定义,因为f2在f3运行之后才被定义,所以运行的脚本会报错。
f1.sh:行8: f2: 未找到命令
hello 

1.3.return
案例1:
第一种用return返回一个值:
#!/bin/bash
function test1 {
read -p "请输入一个数字" num
return $[$num*2]
}
test1
echo $?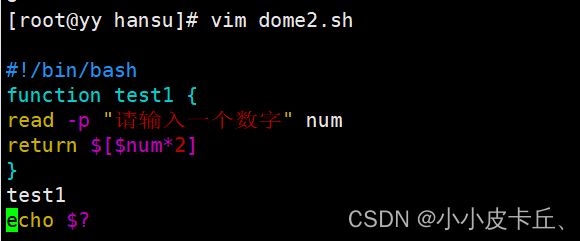

第二种echo直接输出一个值:
#!/bin/bash
test2 () {
read -p "请输入值:" NUM
echo $[$NUM*2]
}
res=$(test2)
echo $[$res *2] 

案例2:测试文件是否存在
#!/bin/bash
file=/etc/passwd
f1 (){
if [ -f $file ];then
return 100
else
return 200
fi
}
f1
echo $? //我们可以根据返回值来判断我们想要的结果,如果为100说明存在,如果为200说明不存在。 

1.4.函数的传参
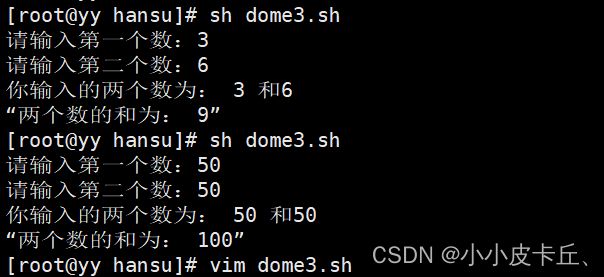
例题1:两个数求和。
#!/bin/bash
sum(){
read -p "请输入第一个数:" NUM1
read -p "请输入第二个数:" NUM2
echo "你输入的两个数为: $NUM1 和$NUM2 "
SUM=$(( NUM1+$NUM2))
echo “两个数的和为: $SUM”
}
sum
例题2:计算位置变量$1和$2的和。
函数的参数::
#!/bin/bash
add (){
let sum=$1+$2 //这里的位置变量是函数的位置变量,所以要写在调用函数的后面,如果是调用脚本时使用则不能成功。
echo $sum
}
add 4 5

脚本的参数:
#!/bin/bash
add (){
let sum=$1+$2
echo $sum
}
add $1 $2 //这里相当于调用了脚本的参数了,然后把脚本的位置变量传递给函数进行计算

1.5.函数的作用范围
在 Shell 脚本中函数的执行并不会开启一个新的子 Shell,而是仅在当前定义的 Shell 环境中有效。如果Shell脚本中的变量没有经过特殊设定,默认在整个脚本中都是有效的。在编写脚本时,有时需要将变量的值限定在函数内部,可以通过内置命令local来实现。函数内部变量的使用,可以避免函数内外同时出现同名变量对脚本结果的影响。
shell脚本中变量默认全局有效。
local命令:将变量限定在函数内部使用。
案列1:
#!/bin/bsah
myfun ()
{
local i
i=8
echo $i
}
i=9
myfun
echo $i

上述脚本中myfun 函数内部使用了local命令设置变量i,其作用是将变量i限定在函数内部。myfun 函数外部同样定义了变量i,内部变量i和全局变量i互不影响。脚本执行时先调用了函数myfun,函数内部变量i为8,所以输出结果是8。调用完函数之后,给变量i赋值为9,再打印外部变量i,所以又输出 9。
案列2:
#!/bin/bash
myfunc() {
a=8
echo $a
}
a=9
myfunc
echo $a

1.6.函数的案例
阶乘
第一种方法:
#!/bin/bash
jiecheng (){
cheng=1
for i in {1..6}
do
let cheng=$i*$cheng
done
echo $cheng
}
jiecheng 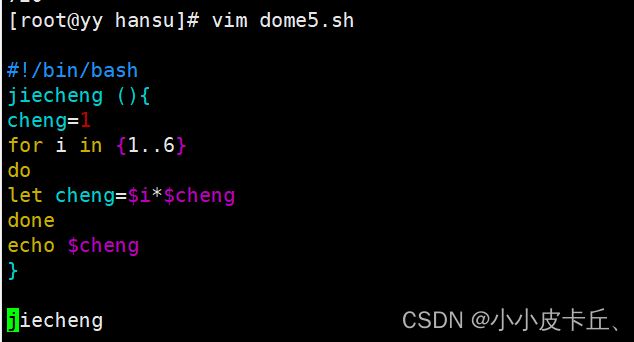
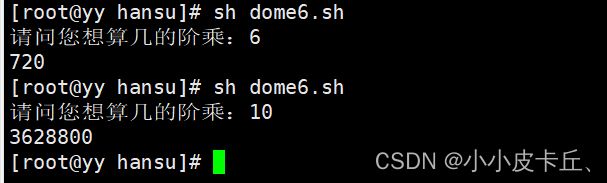
第二种方法:优化版:根据用户需求算几的阶乘。
#!/bin/bash
jiecheng (){
cheng=1
read -p "请问您想算几的阶乘:" num
for i in `seq $num`
do
let cheng=$i*$cheng
done
echo $cheng
}
jiecheng

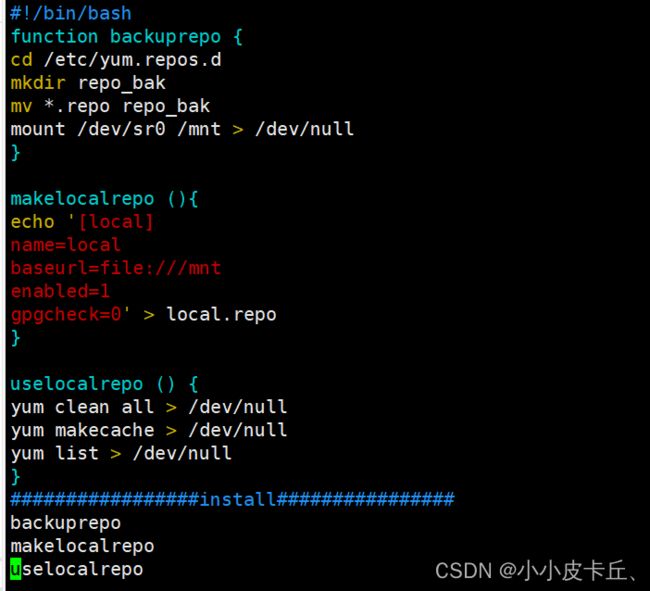
搭建本地yum仓库
#!/bin/bash
function backuprepo {
cd /etc/yum.repos.d
mkdir repo_bak
mv *.repo repo_bak
mount /dev/sr0 /mnt > /dev/null
}
makelocalrepo (){
echo '[local]
name=local
baseurl=file:///mnt
enabled=1
gpgcheck=0' > local.repo
}
uselocalrepo () {
yum clean all > /dev/null
yum makecache > /dev/null
yum list > /dev/null
}
#################install################
backuprepo
makelocalrepo
uselocalrepo
二、数组
2.1.数组的定义
数组是存放相同类型数据的集合,在内存中开辟了连续的空间,通常配合循环使用。
数组的分类
- 普通数组:不需要声明直接定义,下标索引只能是整数。
- 关联数组:需要用declare -A声明否则系统不识别,索引可以是字符串。
数组的定义方式
(30 20 10 60 50 40)
0 1 2 3 4 5
数组包括的数据类型
- 数值类型
- 字符类型
(使用 " " 或者 ' '定义 )
2.2.数组的表示方法
第一种:直接把要加入数组的元素用小括号括起来,中间用空格分开。
num=(11 22 33 44)
${#num} 显示字符串长度
数组名=(value0 value1 value2)第二种:精确的给每一个下标索引定义一个值加入数组,索引数字可以不连续。
num=([0]=55 [1]=66 [2]=77 [4]=88)
数组名=([0]=value [1]=value [2]=value)第三种:先把要加入数组的元素全部先赋值给一个变量,然后引用这个变量加入到数组。
list="11 12 13 14"
num=($list)列表名="value0 value1 value2..."
数组名=($列表名)第四种:根据下标定义
数组名[0]="11"
数组名[1]="22"
数组名[2]="33"
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"2.3.数组常见用法
(1)获取数组的长度

(2)数组元素遍历
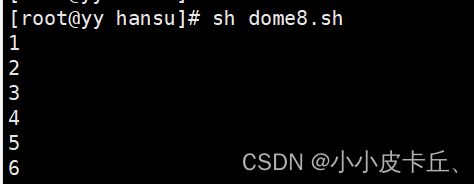
#!/bin/bash
arr=(1 2 3 4 5 6)
for i in ${arr[*]} 或者 for i in ${arr[@]}
do
echo $i
done
(3)元素切片

(4)数组元素替换
临时替换
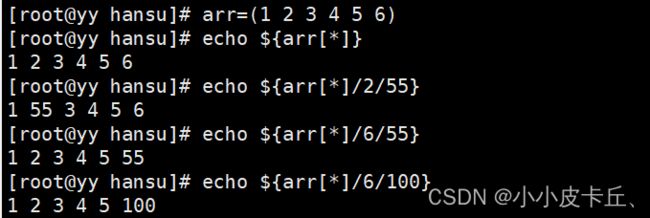
永久替换
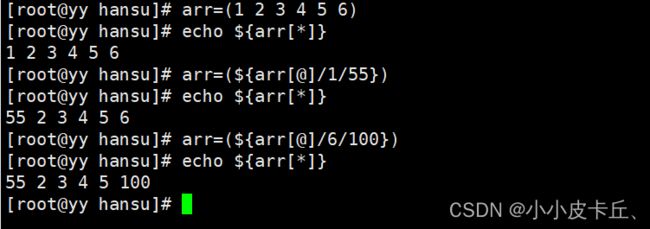
(5)数组删除
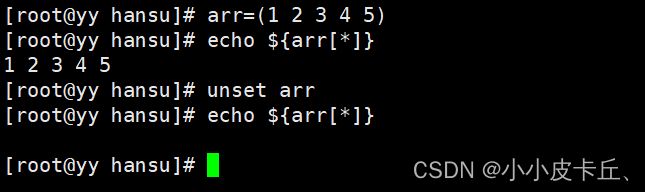
删除整个数组:
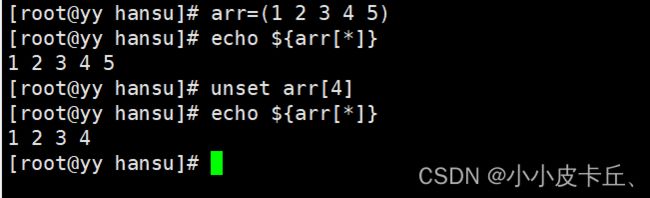
删除数组第五个元素:
三、冒泡排序
(1)定义
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路:
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
(2)冒泡排序案例
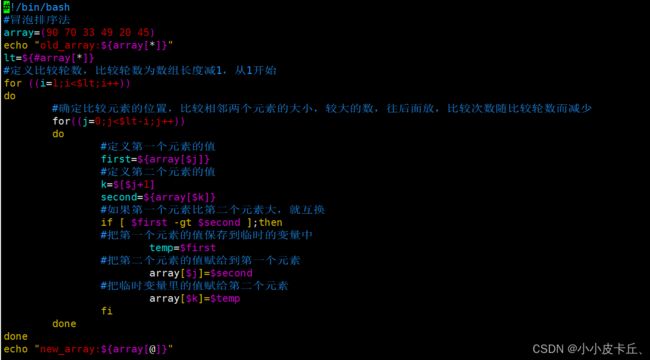
例题:将90,70,33,49,20,45用冒泡排序的方法进行排序。
#!/bin/bash
#冒泡排序法
array=(90 70 33 49 20 45)
echo "old_array:${array[*]}"
lt=${#array[*]}
#定义比较轮数,比较轮数为数组长度减1,从1开始
for ((i=1;i<$lt;i++))
do
#确定比较元素的位置,比较相邻两个元素的大小,较大的数,往后面放,比较次数随比较轮数而减少
for((j=0;j<$lt-i;j++))
do
#定义第一个元素的值
first=${array[$j]}
#定义第二个元素的值
k=$[$j+1]
second=${array[$k]}
#如果第一个元素比第二个元素大,就互换
if [ $first -gt $second ];then
#把第一个元素的值保存到临时的变量中
temp=$first
#把第二个元素的值赋给到第一个元素
array[$j]=$second
#把临时变量里的值赋给第二个元素
array[$k]=$temp
fi
done
done
echo "new_array:${array[@]}"

四、总结
1.Shell函数定义方法。
2.数组使用方法。
3.冒泡排序法。