pytorch--在本地搭建chatGpt简化版,实现聊天,写代码功能
文章目录
-
- 前言
- 效果
- 搭建环境
- 安装编译环境
- 安装anaconda,python3.8.8环境
- 安装vs2019
- vs2019安装完毕后开始安装cuda
- 安装cudnn
- 安装pytorch
前言
体验了一下new bing,很不错,但是最近觉得这种模型还是搭建在自己电脑上最好,看了下github上的chatGLM项目,这个项目在致力于将一个大语言模型搭建在个人机上,我对此惊叹不已,就按照其流程下载下来搭建在自己电脑上了,这种模型运行在自己电脑上的感觉不会有那种隐私被偷窥的感觉,同时自己可以对其进行自定义优化,很好
首先感谢ChatGPT,终于不用在搜索引擎的各种垃圾信息堆里找食吃了,不用再看各种妖魔鬼怪装逼了
效果
随意交谈,同时也可以让其归纳语言和写代码,很不错

搭建环境
电脑配置环境:
- 系统:win10
- 编程环境:pytorch2.0
- cuda:cuda11.7
- python:python3.8.0
- 显卡:七彩虹战斧3060ti
- annaconda:Anaconda3-2021.05-Windows-x86_64.exe
- VS2019
流程:
如果你安装过cuda和cudnn,搭建过程会很简单,
想要运行模型,就先从基础的编译环境搭建开始吧
安装编译环境
可是怎么事先知道那个版本的windows系统,显卡型号,pytorch版本,python版本,cuda,cudnn是相互配合的呢?
先看显卡,看看显卡支持到哪里?
找到nvidia控制面板,看一下支持的cuda版本信息,要小于显卡所标识的最大版本号
cmd输入nvidia-smi,查询驱动器版本号,

心中已经对显卡支持的版本有了大致了解,然后去pytorch官网,他们给的有版本配置单,按着来就行了
https://pytorch.org/get-started/locally/

哦吼,完美支持,我cuda12.0的,向下兼容,去英伟达官网安装cuda11.7的加速计算包完全可行
有的人电脑配置不行,就去看历史版本,如果不支持cuda11.7,就去看历史版本,看相关配置
https://pytorch.org/get-started/previous-versions/


既然支持cuda11.7,那就去英伟达官网去下载cuda11.7安装包
https://developer.nvidia.com/cuda-downloads
选择历史版本

然后下载所需版本即可,比如我这里的cuda11.7
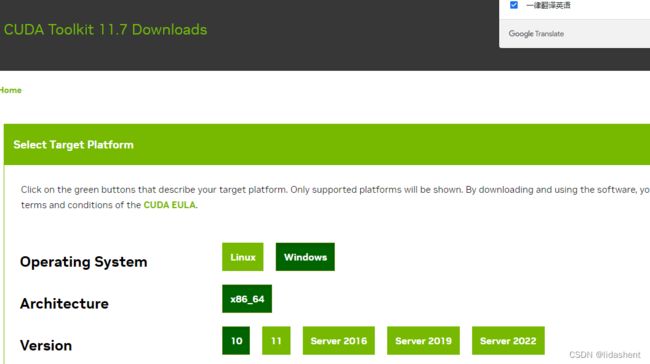
然后再下载cudnn,找到和cuda11.7配套的
https://developer.nvidia.com/rdp/cudnn-download
需要注意的是下载cudnn需要登陆

然后cuda和cudnn就下载好了,但是先别急着安装,还需要安装vs2019和anaconda,
不安装vs2019 cuda无法安装成功,不安装anaconda不容易安装pytorch
先把这两个重要文件安装下
安装anaconda,python3.8.8环境

安装vs2019
cuda安装需要vs环境,适配的组件在vs2019中都具备了,因此要先安装vs2019
需要注意的是在安装时勾选以下组件,否则还是没有cuda运行环境
从网上下载个vs2019安装器,然后勾选如下即可,等待安装完成
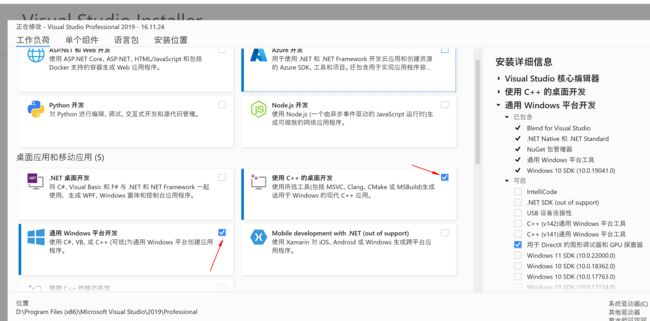
vs2019安装完毕后开始安装cuda
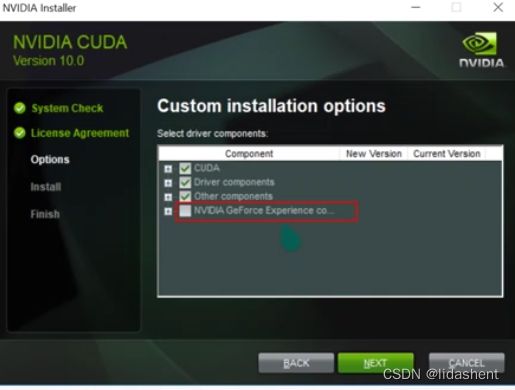
cuda第一开始显示的文件路径框是自解压,选择一个空白文件夹即可,安装完毕后其会将解压的文件自动删除
然后没什么可说的,要注意选择自定义,全部勾选,下一步下一步
安装后看一下如下路径是否有此驱动(这是以前的老图,大差不差,路径类似,无非是11.0换成11.7,cupti64后换个日期)

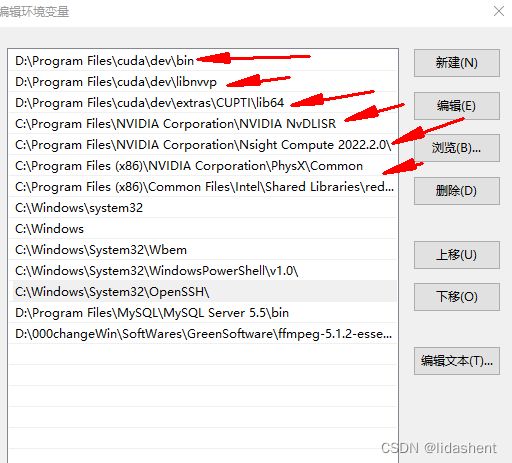
然后配置系统变量,需要注意的是path的搜索有先后顺序,如果搜索到前面的,后面的就会被忽略
如果有多个cuda版本,应该把最需要的cuda版本放在上面,比如安装了cuda11.7和cuda11.0的,就有扫描顺序先后之分,如果想要执行cuda11.7就需要把配置路径放在前面
我自定义了路径,安装到d盘了,可能大家看着dev,doc不是很懂,其实就是development和document文件夹,我自定义文件夹了
安装cudnn
其实就是解压的文件夹,将cudnn中的三个文件复制放入cuda的安装目录如下
cudnn解压后的文件夹,全选复制一下

粘贴到cuda安装目录(以前的老图,方便理解)

然后cmd输入nvcc看看战绩

至此,cudnn和cuda,python就安装好了,版本之间的对应关系要注意对应,否则互相不兼容
安装pytorch
还记得去pytorch官网查配置时底下的命令行吗?输入anaconda就能从他们官网自动下载配置了


等待自动配置安装即可
然后进入pycharm找个命令测试下是否可以运行
import torch
print(torch.__version__):查看torch版本
print(torch.cuda.is_available()):看安装好的torch和cuda能不能用,也就是看GPU能不能用
提示
配置成功
然后进入github官网,下载ChatGlm工程
https://github.com/THUDM/ChatGLM-6B
downloadZip即可
下载然后解压,执行
pip install -r requirements.txt
等待其自动结束配置,
然后运行示例代码等待自动配置即可见到效果
如果需要网页版交流,就使用web_demo.py
以后会更新如何训练此类似模型,仿写以及调优
使用过程中实际会发现,运行话语多句之后内存溢出就会崩,实际上,可以单次提问,相当于浏览器的一问一答模式
聊天会丧失记忆,但是用于代写代码很不错
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
def toChat(speechWords):
response, history = model.chat(tokenizer, speechWords, history=[])
print(response)
while(1):
speechWords=input("用户:\n")
print("AI思考中...")
toChat(speechWords)