Hadoop大数据框架研究(6)——Hadoop环境部署问题汇总
近期对hadoop生态的大数据框架进行了实际的部署测试,并结合ArcGIS平台的矢量大数据分析产品进行空间数据挖掘分析。本系列博客将进行详细的梳理、归纳和总结,以便相互交流学习。
A.使用vim编辑文件时,保存提示:“Found a swap file by the name”
原因:之前编辑此文件时出现未知异常,产生了一个*.swp文件,需要删除此隐藏文件才能继续操作目标文件。尤其是使用不同用户编辑同一文件。
解决方案:
1.ls -a 显示目标编辑文件所在的文件夹(包括隐藏文件)
2.删除*.swp文件。
3.然后使用相应权限的用户编辑
B.Hadoop集群所有的DataNode都启动不了
原因:多次使用Hadoop namenode -format格式化hdfs造成临时目录保护
java.io.IOException: Cannot lock storage /usr/hadoop/tmp/dfs/name. The directory is already locked.
解决方案:
到每个Slave节点下面找到/hadoop/hadoop275_tmp/dfs/目录,删除下面的data文件夹
java.io.IOException: Cannot lock storage /usr/hadoop/tmp/dfs/name. The directory is already locked.
解决方案:
到每个Slave节点下面找到/hadoop/hadoop275_tmp/dfs/目录,删除下面的data文件夹
C.启动hiveserver2时jar包冲突(slf4j-log4j12-1.7.10.jar)
原因:因为hadoop环境和hive环境都包含同一个jar包,移除其中一个即可。
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop/apache-hive-2.3.2-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
解决方案:
r m –f 移除其中一个即可
D.使用正常的虚拟机重启后网络配置失效
原因:因为虚拟机开启了NetworkManager
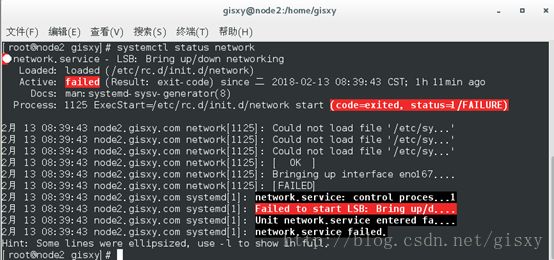
解决方案:
关闭NetworkManager重启网络或者虚拟机
关闭NetworkManager重启网络或者虚拟机
[root@node1 hadoop]$ systemctl stop NetworkManager
[root@node1 hadoop]$systemctl disable NetworkManager
[root@node1 hadoop]$systemctl restart network.service
[root@node1 hadoop]$systemctl disable NetworkManager
[root@node1 hadoop]$systemctl restart network.service
E.scp拷贝命令不可用
原因: ssh服务不正常
解决方案:
重启ssh服务
[root@node1 hadoop]$ systemctl restart sshd.service
F.启动 start-historty-server出错
原因: hadoop库位置未指定或指定错误
Unable to load native-hadoop library foryour platform... using builtin-java classes where applicable
解决方案:
环境变量增加相关配置
环境变量增加相关配置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
G.使用load data local inpath装载数据后显示NULL
原因: 创建表时未指定分隔符或分割符指定的实际数据不一致
hive> select * from test;
OK
1000 gisxy
NULL NULL
NULL NULL
NULL NULL 解决方案:
检查数据分割符的实际情况,重新创建表再装载数据
检查数据分割符的实际情况,重新创建表再装载数据
1000,gisxy
1001,zhangsan
1002,lisi
1003,wangwu hive>create table test(id int,name string)row format delimited fields terminated by ',' lines terminated by '\n';hive> select * from test;
OK
1000 gisxy
1001 zhangsan
1002 lisi
1003 wangwu
H.zookeeper启动后状态信息不正确
[root@node3 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@node3 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Error contacting service. It is probably not running. 原因:
[root@node3 bin]# cat zookeeper.out
2018-03-15 15:36:45,690 [myid:] - INFO [main:QuorumPeerConfig@134] - Reading configuration from: /home/hadoop/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
2018-03-15 15:36:45,708 [myid:] - INFO [main:QuorumPeer$QuorumServer@167] - Resolved hostname: node3.gisxy.com to address: node3.gisxy.com/192.168.0.163
2018-03-15 15:36:45,708 [myid:] - INFO [main:QuorumPeer$QuorumServer@167] - Resolved hostname: node5.gisxy.com to address: node5.gisxy.com/192.168.0.165
2018-03-15 15:36:45,709 [myid:] - INFO [main:QuorumPeer$QuorumServer@167] - Resolved hostname: node4.gisxy.com to address: node4.gisxy.com/192.168.0.164
2018-03-15 15:36:45,709 [myid:] - INFO [main:QuorumPeerConfig@396] - Defaulting to majority quorums
2018-03-15 15:36:45,723 [myid:1] - INFO [main:DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3
2018-03-15 15:36:45,724 [myid:1] - INFO [main:DatadirCleanupManager@79] - autopurge.purgeInterval set to 0
2018-03-15 15:36:45,724 [myid:1] - INFO [main:DatadirCleanupManager@101] - Purge task is not scheduled.
2018-03-15 15:36:45,742 [myid:1] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2018-03-15 15:36:45,750 [myid:1] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
2018-03-15 15:36:45,777 [myid:1] - INFO [main:QuorumPeer@1134] - minSessionTimeout set to -1
2018-03-15 15:36:45,777 [myid:1] - INFO [main:QuorumPeer@1145] - maxSessionTimeout set to -1
2018-03-15 15:36:45,777 [myid:1] - INFO [main:QuorumPeer@1419] - QuorumPeer communication is not secured!
2018-03-15 15:36:45,777 [myid:1] - INFO [main:QuorumPeer@1448] - quorum.cnxn.threads.size set to 20
2018-03-15 15:36:45,780 [myid:1] - INFO [main:FileSnap@83] - Reading snapshot /home/hadoop/hadoop/zookeeperData/version-2/snapshot.300000000
2018-03-15 15:36:45,915 [myid:1] - ERROR [main:QuorumPeer@648] - Unable to load database on disk
java.io.IOException: Unreasonable length = 8722441
at org.apache.jute.BinaryInputArchive.checkLength(BinaryInputArchive.java:127)
at org.apache.jute.BinaryInputArchive.readBuffer(BinaryInputArchive.java:92)
at org.apache.zookeeper.server.persistence.Util.readTxnBytes(Util.java:233)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:629)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:166)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:601)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:591)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:164)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2018-03-15 15:36:45,917 [myid:1] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:649)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:591)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:164)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.IOException: Unreasonable length = 8722441
at org.apache.jute.BinaryInputArchive.checkLength(BinaryInputArchive.java:127)
at org.apache.jute.BinaryInputArchive.readBuffer(BinaryInputArchive.java:92)
at org.apache.zookeeper.server.persistence.Util.readTxnBytes(Util.java:233)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:629)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:166)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:601)
... 4 morezookeeper呈现给使用某些状态的所有客户端进程一致性的状态视图。当一个客户端从zookeeper获得响应时,客户端可以非常肯定这个响应信息与其他响应信息或其他客户端所接收的响应均保持一致。有时,zookeeper客户端库与zookeeper服务的连接会丢失,而且服务提供一致性保证信息,当客户端发现自己处于这种状态时就会返回这种状态
解决方案:删除或重命名配置文件
[root@node3 hadoop]# cd zookeeperData
[root@node3 zookeeperData]# mv ./version-2 ./version-2.bakI.umount卸载失败,umount.nfs: /data: device is busy 问题
[root@ga2 data]# umount /data
umount.nfs4: /data: device is busy
[root@ga2 data]# fuser -m -v /data/
USER PID ACCESS COMMAND
/data: root kernel mount /home/data/gaserver
arcgis 5943 f.... wineserver
arcgis 21501 ..c.. bash
root 25218 ..c.. bash
ga1 30200 ..c.. bash原因:
资源占用,使用fuser -m -v 查看
-v 表示 verbose 模式。进程以 ps 的方式显示,包括 PID、USER、COMMAND、ACCESS 字段
-m 表示指定文件所在的文件系统或者块设备(处于 mount 状态)。所有访问该文件系统的进程都被列出。
解决方案:
确认后,kill -9 干掉相关进程即可