第2.4章:StarRocks表设计--分区分桶与副本数
StarRocks采用Range-Hash的组合数据分布方式,也就是我们一直在提的分区分桶方式。
1分区
StarRocks中的分区是在建表时通过PARTITION BY RANGE()语句设置,用于分区的列也被称之为分区键,当前分区键仅支持日期类型和整数类型(支持一列或多列)。例如前文中表table01中“PARTITION BY RANGE(event_time)”,event_time即为分区键。若建表时我们不进行分区,StarRocks会将整个table作为一个分区(这个分区的名称和表名相同)。
StarRocks会将数据使用分区进行裁剪,例如按天分区时,每天的数据都会单独存储在一个分区内,当我们使用where查找某天的数据时,就会只去搜索对应分区的数据,减少数据扫描量。
分区的另一个目的是可以将分区作为单独的管理单元,我们可以直接为某个分区设置存储策略,比如副本数、冷热策略和存储介质等。
StarRocks支持在一个集群内使用多种存储介质(HDD/SSD)。我们就可以为分区设置不同的存储介质,比如将最新数据所在的分区放在SSD上,利用SSD的随机读写性能来提高查询性能。而老的数据可以放在HDD中,以节省数据存储的成本。
2分桶
对每个分区的数据,StarRocks还会再进行Hash分桶。我们在建表时通过DISTRIBUTED BY HASH()语句来设置分桶,用于分桶的列也被称之为分桶键。分桶键可以是一列或多列,例如前文中表table06的user_id就是分桶键。在聚合模型和更新模型\主键模型下,分桶键必需是排序键中的列。
分桶键Hash值对分桶数取模得到桶的序号(Bucket Seq),假设一个Table的分桶数为8,则共有[0, 1, 2, 3, 4, 5, 6, 7]共8个分桶(Bucket)。同一分区内,分桶键哈希值相同的数据形成(Tablet)子表。
分桶的目的就是将数据打散为一个个逻辑分片(Tablet),以Tablet作为数据均衡的最小单位,使数据尽量均匀的分布在集群的各个BE节点上,以便在查询时充分发挥集群多机多核的优势。
在StarRocks中,Partition是数据导入和备份恢复的最小逻辑单位,Tablet是数据复制和均衡的最小物理单位。表(Table)、分区(Partition)、逻辑分片(Tablet)的关系如下图:
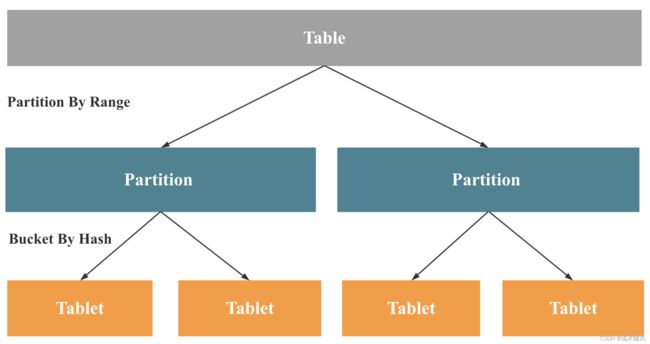
3副本数
StarRocks中的副本数就是同一个Tablet保存的份数,在建表时通过replication_num参数指定,也可以后面修改。默认不指定时,StarRocks使用三副本建表,也即每个Tablet会在不同节点存储三份(StarRocks的副本策略会将某个tablet的副本存储在与其不同IP的节点)。
为方便理解,我们假设当前有一个3BE节点的集群,有表Table A和Table B,表A和表B建表时都未设置分区(视为一个大分区),分桶数为3,副本数replication_num为2,则表A和表B在集群中数据分布的一种可能如下图:
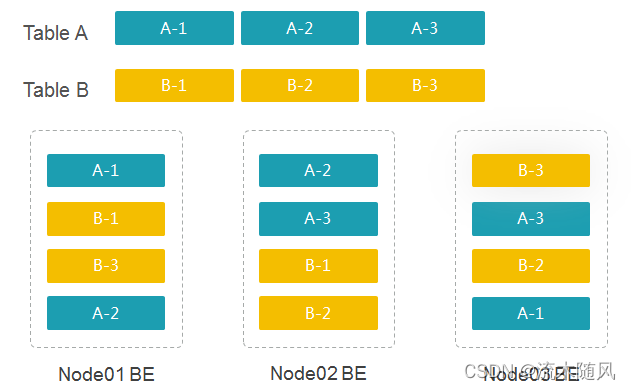
总结一下:分区是针对表的,是对表的数据取段。分桶是针对每个分区的,会将分区后的每段数据打散为逻辑分片Tablet。副本数是针对Tablet的,是指Tablet保存的份数。那么我们不难发现,对某一个数据表,若每个分区的分桶数一致,其总Tablet数:
总Tablet数=分区数*分桶数*副本数
以table01为例,我们为其设置了3个分区,为每个分区设置了20个分桶,又对分桶后的tablet设置了1副本,则table01的总tablet数=3*20*1=60个。查看table01的tablet信息,发现确实共有60个tablet:
mysql> show tablet from table01;
…………
60 rows in set (0.01 sec)
4设置规范
理清了分区分桶和副本数的概念,我们再来研究一下该如何规范的进行分区分桶。
4.1分区规范
分区键选择:当前分区键仅支持日期类型和整数类型,为了让分区能够更有效的裁剪数据,我们一般也是选取时间列作为分区键。
分区粒度选择:StarRocks的分区粒度视数据量而定,单个分区原始数据量建议维持在100G以内。
4.2分桶规范
分桶键选择:分桶的目的我们一直在说是为了将数据打散,所以分桶键就需要选择高基数的列(去重后数据量最大的列)。分桶后的数据如果出现严重的数据倾斜,就可能导致系统局部的性能瓶颈,所以我们也可以视情况使用两个或三个列作为分桶键,尽量的将数据均匀分布。我们可以show语句查看表中的数据分布情况:
mysql> show tablet from tablename;
分桶数:分桶数的设置需要适中,如果分桶过少,查询时查询并行度上不来(CPU多核优势体现不出来)。而如果分桶过多,会导致元数据压力比较大,数据导入导出时也会受到一些影响。
分桶数的设置通常也建议以数据量为参考,从经验来看,每个分桶的原始数据建议不要超过5个G,考虑到压缩比,也即每个分桶的大小建议在100M-1G之间。
若不好估算数据量,我们也可以将分桶数设为:分桶数=“BE个数*BE节点CPU核数”或者“BE个数*BE节点CPU核数/2”,这样一般也不会有什么问题。这里需要注意的是,已创建分区的分桶数不能修改(有其他方式能实现,但比较麻烦),所以前期设定合适的分桶数非常重要。
5动态分区
在StarRocks中,必须先有分区,才能将对应的数据导入进来,不然导入就会报错(提示there is a row couldn’t find a partition)。比如使用日期作为分区,那就需要先创建每天的分区,再进行数据导入。在日常业务中,除了每日会新增数据,我们还会对旧的历史数据进行清理。动态分区就是StarRocks用来实现新分区自动创建以及过期分区自动删除的方式。
动态分区由后台常驻进程调度,默认调度周期为10分钟一次,由FE配置文件中的dynamic_partition_check_interval_seconds参数控制(单位是秒,配置文件中默认没有该配置),所以并不是创建动态分区表后所有分区就立刻被创建,我们还需要等待不超过10分钟让后台调度生效。
咱们创建一个动态分区表table07:
CREATE TABLE starrocks.table07(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0'
)
DUPLICATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)(
PARTITION p20211009 VALUES LESS THAN ("2021-10-10"),
PARTITION p20211010 VALUES LESS THAN ("2021-10-11"),
PARTITION p20211011 VALUES LESS THAN ("2021-10-12")
)
DISTRIBUTED BY HASH(event_day, site_id) BUCKETS 32
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-3",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
table07的PROPERTIES中的几个参数释义如下:
dynamic_partition.enable:是否开启动态分区特性,可指定为TRUE或FALSE。如果该参数等号后不填写值,则默认代表TRUE。
dynamic_partition.time_unit:动态分区调度的粒度,可指定为DAY/WEEK/MONTH。
不同分区粒度下动态分区自动创建分区的名称后缀不同,指定为DAY时,分区名后缀为yyyyMMdd,例如table07中的20211009。指定为WEEK时,分区名后缀为yyyy_ww,例如2021_40代表2021年第40周。指定为MONTH时,动态创建的分区名后缀格式为yyyyMM,例如202110。这里注意,我们前面创建静态分区时,分区命名也建议和动态分区自动创建的规则保持一致。
dynamic_partition.start:动态分区的开始时间。以当天为基准,根据该参数向过去推算数个粒度的时间,超过该时间范围的分区将会被删除。如果不填写,则默认为Integer.MIN_VALUE即-2147483648。
dynamic_partition.end:动态分区的结束时间。以当天为基准,会根据该参数提前创建数个粒度的分区范围。
dynamic_partition.prefix:动态分区自动创建的分区名前缀。
dynamic_partition.buckets:动态创建的分区所对应的分桶数量。
以上属性在建表完成后也可以进行修改,例如关闭动态分区属性:
ALTER TABLE table07 SET("dynamic_partition.enable"="false");
其他几个属性也可以使用类似的语句进行修改。
动态分区表使用过程中会不断地自动增减分区,可以通过下列命令查看当前的分区情况:
SHOW PARTITIONS FROM table07;
分区默认是左闭右开区间,如果用户仅指定右边界,系统会自动确定左边界。比如table07的p20211010分区,其时间范围就是[2021-10-10, 2021-10-11)。
需要注意的是LESS THAN写法的首个分区,比如table07的p20211009分区,它的时间范围是[0000-01-01, 2021-10-10),在13号时,该分区会到期然后被删除,那么table07就会有一个比较大的分区空白段。
在早期版本中,历史分区的创建没有优雅的实现方式,从1.16版本开始,StarRocks也支持了批量创建分区。用户可以通过给出一个START值、一个END值以及一个定义分区增量值的EVERY子句批量产生分区。其中START值将被包括在内而END值将排除在外。
当分区键为日期类型的时候,需要指定INTERVAL关键字来表示日期间隔,目前日期仅支持day、week、month、year,分区的命名规则同动态分区一样。例如:
PARTITION BY RANGE (event_day) (
START ("2021-10-01") END ("2021-10-04") EVERY (INTERVAL 1 day)
)
等价于:
PARTITION p20211001 VALUES [('2021-10-01'), ('2021-10-02')),
PARTITION p20211002 VALUES [('2021-10-02'), ('2021-10-03')),
PARTITION p20211003 VALUES [('2021-10-03'), ('2021-10-04'))
当分区键为整数类型时,我们可以直接使用数字进行分区,这里注意分区值需要使用引号引用,而EVERY则不用引号,例如:
PARTITION BY RANGE (datekey) (
START ("1") END ("5") EVERY (1)
)
上面的语句将产生如下分区:
PARTITION p1 VALUES [("1"), ("2")),
PARTITION p2 VALUES [("2"), ("3")),
PARTITION p3 VALUES [("3"), ("4")),
PARTITION p4 VALUES [("4"), ("5"))
当然,建表时也支持批量创建不同类型的日期分区,例如:
PARTITION BY RANGE (datekey) (
START ("2019-01-01") END ("2021-01-01") EVERY (INTERVAL 1 YEAR),
START ("2021-01-01") END ("2021-05-01") EVERY (INTERVAL 1 MONTH),
START ("2021-05-01") END ("2021-05-04") EVERY (INTERVAL 1 DAY)
)
上面的语句将会产生如下分区:
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
6分区分桶修改
在建表完成后,我们也可以手动增加分区。此时,如果没有指定分桶方式,则自动使用建表时的分桶方式。如果指定分桶方式,则使用新的分桶方式创建(这里当前只能修改分桶数,不能修改分桶方式或分桶列)。另外注意,动态分区表的分区不能直接增删改,若要操作,需要先关闭其动态分区属性。例如我们先关闭table07的动态分区属性:
ALTER TABLE table07 SET("dynamic_partition.enable"="false");
使用新的分桶数新增分区p20210311:
ALTER TABLE starrocks.table07
ADD PARTITION p20210311 VALUES LESS THAN ("2021-03-12")
DISTRIBUTED BY HASH(event_day, site_id) BUCKETS 20;
再增加一个指定上下界的分区p20210312:
ALTER TABLE starrocks.table07
ADD PARTITION p20210312 VALUES [("2021-03-12"), ("2021-03-13"));
删除分区p20210311:
ALTER TABLE starrocks.table07 DROP PARTITION p20210311;
将表table07中名为p20210312的partition修改为p20210312_1:
ALTER TABLE table07 RENAME PARTITION p20210312 p20210312_1;
建表后批量创建分区(与建表时批量创建分区类似):
ALTER TABLE table07 ADD
PARTITIONS START ("2021-01-01") END ("2021-01-06") EVERY (interval 1 day);
清空分区数据:
TRUNCATE TABLE table07 PARTITION(p20211009,p20211010);
7副本数修改
前面提到过,我们可以为分区设置单独的存储策略,比如增加分区时使用新的副本数:
ALTER TABLE starrocks.table07
ADD PARTITION p20210313 VALUES LESS THAN ("2021-03-14")
("replication_num"="1");
修改分区副本数:
ALTER TABLE starrocks.table07
MODIFY PARTITION p20210313 SET("replication_num"="2");
修改表的默认副本数量,新建分区副本数量默认使用此值:
ALTER TABLE starrocks.table07
SET ("default.replication_num" = "2");
修改单分区表的实际副本数量(只限单分区表):
ALTER TABLE starrocks.table06
SET ("replication_num" = "1");
修改表所有分区的副本数:
ALTER TABLE starrocks.table01
MODIFY PARTITION(*)
SET ("replication_num" = "3");
8临时分区
StarRocks中也有临时分区的概念,通过临时分区,我们可以较为方便的调整原数据表中不合理分区的分桶数或者分区范围,也可以在StarRocks中基于lambda模式方便的进行数据导入(用T+1的数据修正实时数据)。
首先,只有显式指定的分区表才可以创建临时分区,例如前面的table01、table05和table07。临时分区的创建需要遵循以下规则:
1、临时分区的分区列和正式分区的相同,且不可修改;
2、一张表所有临时分区之间的分区范围不可重叠,但临时分区的范围和正式分区范围可以重叠;
3、临时分区的分区名称不能和正式分区或其他临时分区的重复。
4、与正式分区一样,临时分区同样可以独立指定一些属性。包括分桶数、副本数、是否是内存表、存储介质等信息。
临时分区的创建语法与正式分区的基本一致,只有关键词TEMPORARY PARTITION不同,例如为表table05新增一个临时分区tp01:
ALTER TABLE table05 ADD TEMPORARY PARTITION tp01 VALUES [("2021-12-01"), ("2021-12-02"));
查看table05中的临时分区情况:
show temporary partitions from table05;
导入数据到临时分区的语句也和普通分区的一样,只有分区关键词不同,例如:
Insert into:
INSERT INTO tbl TEMPORARY PARTITION(tp1, tp2, ...) SELECT ....
Stream Load:
curl --location-trusted -u root: -H "label:123" -H "temporary_partitions: tp1, tp2, ..." ……
Broker Load:
LOAD LABEL example_db.label1
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/data/input/file")
INTO TABLE `my_table`
TEMPORARY PARTITION (tp1, tp2, ...)
…………
Routine Load:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl
COLUMNS(k1, k2, k3, v1, v2, v3 = k1 * 100),
TEMPORARY PARTITIONS(tp1, tp2, ...)
…………
查询临时分区:
SELECT ... FROM
tbl1 TEMPORARY PARTITION(tp1, tp2, ...)
JOIN
tbl2 TEMPORARY PARTITION(tp1, tp2, ...)
ON ...
WHERE ...;
删除table05的临时分区tp01(不会影响正式分区的数据):
ALTER TABLE table05 DROP TEMPORARY PARTITION tp01;
创建临时分区主要还是为了服务正式分区,在对临时分区处理完成后,我们还可以用一个或多个临时分区来替换表中的一个或多个正式分区。
举个例子,我们创建临时分区tp02,并设置该分区为单副本,分桶数为8:
ALTER TABLE table05 ADD TEMPORARY PARTITION tp02 VALUES LESS THAN("2021-12-20")
("replication_num" = "1")
DISTRIBUTED BY HASH(`order_id`) BUCKETS 8;
因为前面已经删除了tp01,那么临时分区tp02的时间范围应为左闭右开的:[0000-01-01 , 2021-12-20),通过show temporary partitions语句确认后也确实如此。
导入数据:
insert into table05 temporary partition(tp02) values('2021-09-29',20210707001,01,100,10086,'lm',9,23,98,2);
查看临时分区数据:
SELECT * FROM table05 TEMPORARY PARTITION(tp02);
如果我们想用调整过分桶数和副本数的临时分区tp02来替换table05中的正式p20210929和p20210930,写法为:
ALTER TABLE table05 REPLACE PARTITION (p20210929,p20210930) WITH TEMPORARY PARTITION (tp02)
PROPERTIES (
"strict_range" = "false",
"use_temp_partition_name" = "true"
);
这里解释一下strict_range和use_temp_partition_name的概念。
strict_range:默认为true。对于Range分区,当该参数为true时,表示要被替换的所有正式分区的范围并集需要和替换的临时分区的范围并集完全相同。当置为 false 时,只需要保证替换后,新的正式分区间的范围不重叠即可。上面的例子中因为范围不相同,我们设为了false。
use_temp_partition_name:默认为false。当该参数为false,并且待替换的分区和替换分区的个数相同时,替换后的正式分区名称维持不变。如果为true,或待替换分区与替换分区的个数不相同,则替换后,正式分区的名称为替换分区的名称。在上面的例子中,因为待替换分区和替换分区的个数不相同,所以此时table05中的正式分区的名称变为tp02。
分区替换成功后,被替换的分区将被删除,且不可恢复。
此时查看table05表的数据,会发现已经是刚才临时分区中的数据:
SELECT * FROM table05;
查看正式分区,会发现正式分区名称为tp02:
SHOW partitions FROM table05;
临时分区和其他操作的关系:
- DROP
使用Drop操作直接删除数据库或表后,可以通过Recover命令恢复数据库或表(限定时间内),但临时分区不会被恢复。
使用Alter命令删除正式分区后,可以通过Recover命令恢复分区(限定时间内)。操作正式分区和临时分区无关。
使用Alter命令删除临时分区后,无法通过 Recover 命令恢复临时分区。
- TRUNCATE
使用Truncate命令清空表,表的临时分区会被删除,且不可恢复。
使用Truncate命令清空正式分区时,不影响临时分区。
不可以使用Truncate命令清空临时分区。
- ALTER
当表存在临时分区时,无法使用Alter命令对表进行 Schema Change、Rollup 等变更操作。
当表在进行变更操作时,无法对表添加临时分区。
9冷热分区
在很多业务场景中,较近时间段的数据通常是查询最频繁的,时间较久的历史数据查询频率可能就会低很多。StarRocks支持在一个BE中使用多种存储介质(HDD/SSD/Mem),这样我们就可以将最新数据所在的分区放在SSD上,利用SSD的随机读写性能来提高查询性能。而老的数据会自动迁移至HDD盘中,以节省数据存储的成本。此外,StarRocks也是支持内存表的,但这部分功能很久没有优化了,目前不推荐使用。
首先明确一点,若集群服务器的存储介质单一(只有机械磁盘,又或者全为固态硬盘),我们就不需要再单独设置什么。例如集群中的磁盘全为SSD,虽然StarRocks在不额外设置参数时默认展示磁盘为HDD,但由于SSD带来的性能提升是源自物理层面的,所以并不会影响实际性能。
当同一台服务器中既有SSD又有HDD时,StarRocks并不会自动识别磁盘的类型,我们需要在be.conf中为storage_root_path显式的指定存储介质类型,格式可以参考be.conf中的示例:
# storage_root_path = /data1,medium:HDD,capacity:50;/data2,medium:SSD,capacity:1;/data3,capacity:50;/data4
# /data1, capacity limit is 50GB, HDD;
# /data2, capacity limit is 1GB, SSD;
# /data3, capacity limit is 50GB, HDD(default);
# /data4, capacity limit is disk capacity, HDD(default)
StarRocks的冷热分区目前有以下几个使用方式:
1、在建表时,指定表级别的存储介质及存储到期时间;
2、建表完成后,修改分区的存储介质及存储到期时间;
3、建表完成后,新增分区时设置分区的存储介质及存储到期时间;
4、当前不支持在建表时为某个分区单独设置分区的到期时间,同样,也不支持设置动态分区自动创建的新分区的到期时间。
举个例子,在集群的be.conf中设置完SSD及HDD后,创建表table08:
CREATE TABLE table08 (
user_id INT COMMENT "id of user",
device_code INT COMMENT "code of device",
device_price DECIMAL(10,2) COMMENT "",
event_time DATETIME NOT NULL COMMENT "datetime of event",
total DECIMAL(18,2) SUM DEFAULT "0" COMMENT "total amount of equipment",
index index01 (user_id) USING BITMAP COMMENT "bitmap index"
)
AGGREGATE KEY(user_id, device_code,device_price,event_time)
PARTITION BY RANGE(event_time)
(
PARTITION p1 VALUES LESS THAN ('2022-01-01'),
PARTITION p2 VALUES LESS THAN ('2022-01-02'),
PARTITION p3 VALUES LESS THAN ('2022-01-03')
)
DISTRIBUTED BY HASH(user_id,device_code) BUCKETS 20
PROPERTIES (
"replication_num" = "1",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2023-01-01 23:59:59"
);
通过show语句,查看分区存储介质及其到期时间:
show partitions from table08;
StorageMedium为SSD;
CooldownTime为2023-01-01 23:59:59。
这里的storage_cooldown_time参数若不显式设置,默认为1个月,默认时间可以通过fe.conf中storage_cooldown_second参数调整。
修改分区p3的存储到期时间:
ALTER TABLE table08 MODIFY PARTITION p3 SET("storage_medium"="SSD", "storage_cooldown_time"="2023-03-11 10:29:01");
新增分区p4,指定存储介质及存储到期时间:
ALTER TABLE table08 ADD PARTITION p4 VALUES LESS THAN ('2022-01-04') ("storage_medium" = "SSD","storage_cooldown_time"="2023-03-11 10:29:01");
在table08中,我们虽然在PROPERTIES 中设置了"storage_medium" = "SSD"和"storage_cooldown_time",但这个属性仅会用于表创建时的三个分区,后面新建的分区若不指定,还是会使用HDD(也就没有所谓的存储到期时间了)。这里的默认存储介质类型受fe.conf中的default_storage_medium参数控制,默认为HDD,我们可以设置为:default_storage_medium=SSD
注意,只有SSD的存储到期时间有意义,在HDD中,到期时间都为9999-12-31,也即为无到期时间。当时钟到达分区存储到期时间后,会触发迁移逻辑,该分区存储在SSD中的数据会向HDD中迁移。
这里同样引出一个注意事项,当我们的存储介质全为SSD时,我们前面提到过,完全可以不单独设置参数,也即be.conf和建表语句中都不用设置。此时,若我们在建表语句中设置了"storage_medium" = "SSD",那同时就需要注意给一个较大的"storage_cooldown_time"到期时间,以避免分区到期后后台不断触发迁移逻辑。