OpenStack Victoria搭建(一)简介
简介
OpenStack 项目是一个适用于所有类型云的开源云计算平台,旨在实现简单、可大规模扩展和功能丰富。来自世界各地的开发人员和云计算技术人员创建了 OpenStack 项目。
OpenStack通过一组相互关联的服务提供基础设施即服务 (IaaS)解决方案。每个服务都提供了一个 应用程序编程接口 (API)来促进这种集成。
概念架构

逻辑架构
要设计、部署和配置 OpenStack,管理员必须了解逻辑架构。
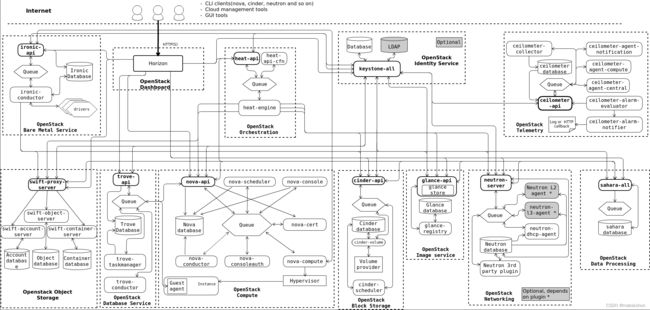
如 概念架构 中所示,OpenStack 由几个独立的部分组成,称为 OpenStack 服务。所有服务都通过公共身份服务进行身份验证。各个服务通过公共 API 相互交互,除非需要特权管理员命令。
在内部,OpenStack 服务由多个进程组成。所有服务都至少有一个 API 进程,它监听 API 请求,对它们进行预处理并将它们传递给服务的其他部分。除身份服务外,实际工作由不同的进程完成。
对于一个服务的进程之间的通信,使用了 AMQP 消息(rabbitmq)代理。服务的状态存储在数据库中。在部署和配置 OpenStack 云时,您可以在多种消息代理和数据库解决方案中进行选择,例如 RabbitMQ、MySQL、MariaDB 和 SQLite。
用户可以通过 Horizon Dashboard 实现的基于 Web 的用户界面、命令行客户端以及通过浏览器插件或curl等工具发出 API 请求来访问 OpenStack 。对于应用程序,有几个 SDK 可用。最终,所有这些访问方法都会向各种 OpenStack 服务发出 REST API 调用。
下图显示了 OpenStack 云最常见但并非唯一可能的架构:
概述
OpenStack项目是一个开源的云计算平台,支持所有类型的云环境。该项目旨在实现简单的实现、大规模的可扩展性和丰富的功能集。来自世界各地的云计算专家为该项目做出了贡献。
OpenStack通过各种互补服务提供基础架构即服务 (IaaS)解决方案。每个服务都提供了一个 应用程序编程接口 (API)来促进这种集成。
本指南使用适用于具有足够 Linux 经验的 OpenStack 新用户的功能示例架构逐步部署主要 OpenStack 服务。本指南并非旨在用于生产系统安装,而是为了解 OpenStack 的目的创建一个最低限度的概念验证。
在熟悉了这些 OpenStack 服务的基本安装、配置、操作和故障排除之后,您应该考虑使用生产架构进行部署的以下步骤:
确定并实施必要的核心和可选服务以满足性能和冗余要求。
使用防火墙、加密和服务策略等方法提高安全性。
使用 Ansible、Chef、Puppet 或 Salt 等部署工具来自动化生产环境的部署和管理。OpenStack 项目有几个部署项目,每个版本都有特定的指南:
Yoga 版本
Xena 版本
Wallaby 版本
Victoria 版本
Ussuri 版本
Train 版本
Stein 版本
Rocky 版本
Queens 版本
Pike 版本
架构设计指南
架构设计指南提供了有关规划和设计 OpenStack 云的信息。它解释了核心概念、云架构设计要求以及 OpenStack 云中关键组件和服务的设计标准。该指南还描述了五个常见的云用例。
先决条件:
- 具备云架构和原理的先验知识。
- Linux 和虚拟化经验。
- 对网络原理和协议有基本的了解。
安装指南
部署指南
OpenStack 操作指南
架构要求
企业要求
成本
财务因素是任何组织的首要关注点。成本考虑可能会影响您构建的云的类型。例如,通用云不太可能成为专门应用程序最具成本效益的环境。除非业务需求表明成本是一个关键因素,否则成本不应成为选择或设计云时的唯一考虑因素。
作为一般准则,增加云架构的复杂性会增加构建和维护它的成本。例如,涉及多个供应商和技术架构的混合或多站点云架构可能需要更高的设置和运营成本,因为需要比其他架构更复杂的编排和代理工具。但是,通过使用云代理工具将工作负载部署到最具成本效益的平台,总体运营成本可能会更低。
在设计云时考虑以下成本类别:
- 计算资源
- 网络资源
- 复制
- 贮存
- 管理
- 运营成本
考虑随着云的扩展成本将如何增加也很重要。在小型系统中影响可以忽略不计的选择可能会大大增加大型系统的成本。在这些情况下,重要的是尽量减少堆栈所有层的资本支出 (CapEx)。大规模可扩展 OpenStack 云的运营商需要使用可靠的商品硬件和免费提供的开源软件组件,以降低部署成本和运营费用。诸如开放计算(开放计算项目中提供更多信息)之类的计划提供了更多信息。
上市时间
在灵活的时间范围内交付服务或产品的能力是构建云时的常见业务因素。允许用户自行配置并按需访问计算、网络和存储资源可能会缩短新产品和应用程序的上市时间。
您必须平衡构建新云平台所需的时间与将用户从旧平台迁移出来所节省的时间。在某些情况下,现有基础架构可能会影响您的架构选择。例如,当对多个应用程序进行现有投资时,使用多个云平台可能是一个不错的选择,因为将投资捆绑在一起可能比迁移组件并将它们重构到单个平台更快。
收入机会
收入机会因云的意图和用例而异。面向客户的商业产品的要求通常与内部私有云有很大不同。您必须考虑哪些功能使您的设计对用户最有吸引力。
容量规划和可扩展性
容量和工作负载的放置是云计算的关键设计考虑因素。这些设计的长期容量计划必须包含随时间的增长,以防止永久消耗更昂贵的外部云。为避免这种情况,请考虑未来应用程序的容量需求并适当规划增长。
如果用户数量波动或应用程序的使用量意外增加,则很难预测特定应用程序可能产生的负载量。可以根据 vCPU、RAM、带宽或其他资源定义应用程序要求并进行适当规划。但是,其他云可能不会使用相同的计量器,甚至不会使用相同的超额订阅率。
超额订阅是一种模拟比实际可能存在的更多容量的方法。例如,具有 32 GB RAM 的物理管理程序节点可以托管 24 个实例,每个实例配备 2 GB RAM。只要所有 24 个实例不同时使用 2 GB,这种安排就可以很好地工作。然而,一些主机过度订阅到极端,因此,性能可能不一致。如果可能的话,确定每台主机的超额订阅率是多少,并相应地规划容量。
表现
在设计任何云时,性能是一个关键的考虑因素,并且随着规模和复杂性的增长而变得越来越重要。虽然可以严格控制单站点私有云,但多站点和混合部署需要更仔细的规划,以减少站点之间的网络延迟等问题。
例如,您应该考虑在不同的云中运行工作负载所需的时间以及减少此时间的方法。这可能需要将数据移动到更靠近应用程序或应用程序更靠近它们处理的数据,并对功能进行分组,以便需要低延迟的连接发生在单个云上而不是跨云上。
这可能还需要 CMP 来确定哪个云可以最有效地运行哪些类型的工作负载。
使用原生 OpenStack 工具有助于提高性能。例如,您可以使用遥测来衡量性能,并使用编排服务(热量)对需求变化做出反应。
注意
编排需要特殊的客户端配置才能与 Amazon Web Services 集成。对于其他类型的云,请使用 CMP 功能。
1. 云资源部署
云用户期望启动和部署云资源的过程具有可重复性、可靠性和确定性。您可以通过基于 Web 的界面或公开可用的 API 端点来提供此功能。All appropriate options for requesting cloud resources must be available through some type of user interface, a command-line interface (CLI), or API endpoints.
2. 消费模式
云用户期望完全自助和按需消费模式。当 OpenStack 云达到可大规模扩展的规模时,期望以各种方式消费即服务。
一切都必须能够自动化。例如,从计算硬件、存储硬件、网络硬件到支持软件的安装和配置。在大规模可扩展的 OpenStack 设计架构中,手动流程是不切实际的。
大规模可扩展的 OpenStack 云需要广泛的计量和监控功能,通过让操作员了解基础设施的状态和状态来最大限度地提高运营效率。这包括硬件和软件状态的全面计量。还需要相应的日志记录和警报框架来存储和启用操作以对计量和监控解决方案提供的计量表进行操作。云运营商还需要一个解决方案,使用计量和监控解决方案提供的数据来提供容量规划和容量趋势分析。
3. 地点
对于许多用例,用户与其工作负载的接近程度直接影响应用程序的性能,因此在设计中应予以考虑。某些应用程序需要零到最小的延迟,这只能通过在多个位置部署云来实现。这些位置可能位于不同的数据中心、城市、国家或地理区域,具体取决于用户需求和用户的位置。
4. 输入输出要求
输入输出性能要求需要在决定最终存储框架之前进行研究和建模。运行输入输出性能基准测试为预期的性能水平提供了基准。如果这些测试包含详细信息,则生成的数据可以帮助对不同工作负载期间的行为和结果进行建模。在架构的生命周期中运行脚本化的小型基准测试有助于记录不同时间点的系统运行状况。来自这些脚本基准的数据有助于未来确定范围并更深入地了解组织的需求。
5.规模
在以存储为中心的 OpenStack 架构设计中扩展存储解决方案是由初始需求驱动的,包括 IOPS、容量、带宽和未来需求。根据预算周期过程中的预计需求规划容量对于设计很重要。该架构应该平衡成本和容量,同时还允许灵活地实施新技术和方法,因为它们变得可用。
网络
在选择 CMP 和云提供商时,重要的是要考虑网络的功能、安全性、可扩展性、可用性和可测试性。
确定网络框架并设计最低限度的功能测试。这可确保测试和功能在升级期间和升级后持续存在。
跨多个云提供商的可扩展性可能决定您在不同的云提供商中选择哪种底层网络框架。展示网络 API 功能并验证功能是否在所选的所有云端点上持续存在是很重要的。
高可用性实现在功能和设计上有所不同。一些常见方法的示例是主动-热备、主动-被动和主动-主动。开发高可用性和测试框架对于确保理解功能和限制是必要的。
考虑客户端和端点之间数据的安全性,以及穿越多个云的流量的安全性。
例如,降级的视频流和低质量的 VoIP 会话会对用户体验产生负面影响,并可能导致生产力和经济损失。
网络配置错误
配置不正确的 IP 地址、VLAN 和路由器可能会导致网络区域中断,或者在最坏的情况下会导致整个云基础架构中断。自动化网络配置以最大限度地减少操作员错误的机会,因为它可能导致破坏性问题。
容量规划
随着时间的推移,云网络需要对容量和增长进行管理。容量规划包括购买可能具有以月或年为单位的交货时间的网络电路和硬件。
网络调优
配置云网络以最大程度地减少链路丢失、丢包、包风暴、广播风暴和环路。
单点故障 (SPOF)
考虑物理层和环境层的高可用性。如果仅由于一个上游链路或仅一个电源而导致单点故障,则中断可能变得不可避免。
复杂
过于复杂的网络设计可能难以维护和排除故障。虽然设备级配置可以缓解维护问题,自动化工具可以处理覆盖网络,但可以避免或记录功能和专用硬件之间的非传统互连,以防止中断。
非标准功能
配置云网络以利用供应商特定功能会产生额外的风险。一个示例是用于在网络的聚合器交换机级别提供冗余的多链路聚合 (MLAG)。MLAG 不是一个标准,因此每个供应商都有自己的专有功能实现。MLAG 架构在交换机供应商之间不能互操作,这会导致供应商锁定,并可能在升级组件时导致延迟或无法使用。
动态资源扩展或突发
需要额外资源的应用程序可能适合多云架构。例如,零售商在假期期间需要额外的资源,但不想增加私有云资源来满足高峰需求。用户可以通过在这些峰值负载期间突发到公共云来适应增加的负载。这些爆发可能是从每小时到每年的长周期或短周期。
合规性和地理位置
组织可能有某些法律义务和法规遵从措施,可能要求某些工作负载或数据不能位于某些区域。
合规性考虑对于多站点云尤其重要。考虑因素包括:
- 联邦法律要求
- 当地司法管辖区的法律和合规要求
- 图像一致性和可用性
- 存储复制和可用性(块和文件/对象存储)
- 身份验证、授权和审计 (AAA)
地理因素也可能影响建设或租赁数据中心的成本。考虑因素包括:
- 建筑面积
- floor weight
- 机架高度和类型
- 环境因素
- 用电量和用电效率(PUE)
- 物理安全
审计
一个经过深思熟虑的审计计划对于快速发现问题至关重要。如果更改影响生产,则跟踪对安全组和租户更改所做的更改对于回滚更改很有用。例如,如果租户的所有安全组规则都消失了,那么出于运营和法律原因,快速追踪问题的能力将很重要。有关审计的更多详细信息,请参阅OpenStack 安全指南中的合规性章节。
安全
安全性的重要性因使用云的组织类型而异。例如,政府和金融机构往往有非常高的安全要求。应根据资产、威胁和漏洞风险评估矩阵实施安全。请参阅安全要求。
服务等级协定
服务水平协议 (SLA) 必须与业务、技术和法律投入一起制定。小型私有云可能在非正式的 SLA 下运行,但混合云或公共云通常需要与其用户达成更正式的协议。
对于可大规模扩展的 OpenStack 公共云的用户,不需要对安全性、性能或可用性进行控制。用户只期望与 API 服务的正常运行时间相关的 SLA,以及所提供服务的非常基本的 SLA。用户有责任自行解决这些问题。这种期望的例外是为具有特定要求的私人或政府组织构建的大规模可扩展云基础架构的罕见情况。
高性能系统在保证正常运行时间、延迟和带宽方面具有最低服务质量的 SLA 要求。SLA 的级别会对网络架构和系统冗余要求产生重大影响。
混合云设计必须适应提供商之间 SLA 的差异,并考虑其可执行性。
应用准备
一些应用程序可以容忍缺少同步对象存储,而另一些应用程序可能需要这些对象被复制并跨区域可用。了解云实施如何影响新的和现有的应用程序对于缓解风险以及云项目的整体成功非常重要。可能必须为几乎没有冗余的基础架构编写或重写应用程序,或者考虑到云。
申请势头
拥有现有应用程序的企业可能会发现,将应用程序集成到多个云平台上比将它们迁移到单个平台更具成本效益。
没有预定义的使用模型
缺乏预定义的使用模型使用户能够运行各种各样的应用程序,而无需提前知道应用程序的需求。这提供了其他云方案无法提供的独立性和灵活性。
按需和自助服务应用程序
根据定义,云为最终用户提供了以简单灵活的方式自行配置计算能力、存储、网络和软件的能力。用户必须能够在不中断底层主机操作的情况下将其资源扩展到相当大的水平。使用通用云架构的好处之一是能够从有限的资源开始,并随着用户需求的增长而随着时间的推移增加资源。
验证
建议使用单个身份验证域,而不是为每个站点单独实现。这需要一种高度可用和分布式的身份验证机制,以确保连续运行。身份验证服务器位置可能是必需的,并且应该进行规划。
迁移、可用性、站点丢失和恢复
中断可能导致站点功能部分或全部丧失。应实施策略以了解和计划恢复方案。
- 部署的应用程序需要继续运行,更重要的是,您必须考虑站点不可用时对应用程序性能和可靠性的影响。
- 重要的是要了解当站点出现故障时站点之间的对象和数据复制会发生什么。如果这导致队列开始建立,请考虑这些队列可以安全存在多长时间,直到发生错误。
- 停电后,确保站点恢复正常运行的方法在站点重新上线时得到实施。我们建议您构建恢复以避免竞争条件。
灾难恢复和业务连续性
更便宜的存储使公共云适合维护备份应用程序。
迁移场景
混合云架构支持应用程序在不同云之间的迁移。
提供者可用性或实施细节
业务变化可能会影响提供商的可用性。同样,提供商服务的变化可能会破坏混合云环境或增加成本。
提供者 API 更改
外部云的消费者很少能够控制提供者对 API 的更改,并且更改可能会破坏兼容性。仅使用最常见和基本的 API 可以最大限度地减少潜在冲突。
image可移植性
在 Kilo 版本中,没有可供所有云使用的通用图像格式。如果在云之间迁移,则需要转换或重新创建图像。要简化部署,请使用可行的最小和最简单的映像,仅安装必要的部分,并使用 Chef 或 Puppet 等部署管理器。除非您在同一云上重复部署相同的映像,否则不要使用黄金映像来加快进程。
API 差异
避免将混合云部署与 OpenStack(或不同版本的 OpenStack)一起使用,因为 API 更改可能会导致兼容性问题。
业务或技术多样性
利用基于云的服务的组织可以拥抱业务多样性,并利用混合云设计将其工作负载分布在多个云提供商之间。这确保了没有一个云提供商是应用程序的唯一主机。
操作要求
网络设计
OpenStack 集群的网络设计包括有关集群内互连需求的决策、允许客户端访问其资源的需求以及操作员管理集群的访问要求。您应该考虑这些网络的带宽、延迟和可靠性。
考虑有关监控和警报的其他设计决策。如果您使用的是外部提供商,服务水平协议 (SLA) 通常会在您的合同中定义。带宽、延迟和抖动等操作考虑因素可以成为 SLA 的一部分。
随着对网络资源的需求增加,请确保您的网络设计能够适应扩展和升级。运营商添加额外的 IP 地址块并增加额外的带宽容量。此外,考虑管理硬件和软件生命周期事件,例如升级、退役和中断,同时避免租户服务中断。
将可维护性因素纳入整体网络设计。这包括管理和维护 IP 地址以及使用覆盖标识符(包括 VLAN 标签 ID、GRE 隧道 ID 和 MPLS 标签)的能力。例如,如果您可能需要更改网络上的所有 IP 地址(称为重新编号的过程),则设计必须支持此功能。
在考虑某些运营现实时解决以网络为中心的应用程序。例如,考虑即将耗尽的 IPv4 地址、向 IPv6 的迁移以及使用专用网络来隔离应用程序接收或生成的不同类型的流量。在从 IPv4 迁移到 IPv6 的情况下,应用程序应遵循存储 IP 地址的最佳做法。我们建议您避免依赖未延续到 IPv6 协议或在实现上存在差异的 IPv4 功能。
要隔离流量,请允许应用程序为数据库和存储网络流量创建专用租户网络。对于需要从 Internet 直接访问客户端的服务,请使用公共网络。在隔离流量时,请考虑服务质量 (QoS)和安全性,以确保每个网络都具有所需的服务级别。
还要考虑网络流量的路由。对于某些应用程序,开发一个复杂的路由策略框架。要创建满足业务需求的路由策略,除了带宽、延迟和抖动要求之外,还要考虑通过昂贵链路与更便宜链路传输流量的经济成本。
最后,考虑如何响应网络事件。在故障情况下负载如何从一个链路转移到另一个链路可能是设计中的一个因素。如果您没有正确规划网络容量,故障转移流量可能会淹没其他端口或网络链路,并产生级联故障情况。在这种情况下,故障转移到一个链路的流量会淹没该链路,然后移动到后续链路,直到所有网络流量停止。
SLA 注意事项
服务级别协议 (SLA) 定义了将影响 OpenStack 云设计以提供冗余和高可用性的可用性级别。
影响设计的 SLA 条款包括:
- API 可用性保证意味着多个基础设施服务和高可用性负载平衡器。
- 网络正常运行时间保证会影响交换机设计,这可能需要冗余交换机和电源。
- 网络安全策略要求。
在任何大于几台主机的环境中,有两个区域可能需要遵守 SLA:
- 数据平面 - 提供虚拟化、网络和存储的服务。客户通常要求这些服务持续可用。
- 控制平面 - 辅助服务,例如 API 端点,以及控制 CRUD 操作的服务。此类别中的服务通常受制于不同的 SLA 预期,并且可能更适合与数据平面服务分开的硬件或容器。
为了有效地运行云安装,初始停机时间规划包括创建支持计划内维护和计划外系统故障的流程和架构。
作为 SLA 协商的一部分,在发生中断时确定哪一方负责监控和启动计算服务实例非常重要。
对于某些服务,升级、修补和更改配置项可能需要停机。停止构成控制平面的服务可能不会影响数据平面。可能需要实时迁移计算实例来执行任何需要停机到数据平面组件的操作。
在纯 OpenStack 代码领域之外有许多服务会影响云设计满足 SLA 的能力,包括:
- 数据库服务,例如MySQL或PostgreSQL。
- 提供 RPC 的服务,例如RabbitMQ.
- 外部网络附件。
- 物理限制,例如电源、机架空间、网络布线等。
- 共享存储,包括基于 SAN 的阵列、存储集群(如Ceph)和/或 NFS 服务。
根据设计,某些网络服务功能可能同时属于控制平面和数据平面类别。例如,neutron L3 代理服务可能被认为是控制平面组件,但路由器本身将是数据平面组件。
在具有多个区域的设计中,SLA 还需要考虑使用共享服务,例如身份服务和仪表板。
任何 SLA 协商还必须考虑对第三方设计关键方面的依赖。例如,如果存储系统等组件上存在现有 SLA,则 SLA 必须考虑此限制。如果云所需的 SLA 超过云组件商定的正常运行时间水平,则需要额外的冗余。这种考虑在涉及多个第三方的混合云设计中至关重要。
支持和维护
操作人员支持、管理和维护 OpenStack 环境。他们的技能可能是专业的或因安装的大小和目的而异。
应考虑操作员的维护功能:
维护任务
操作系统修补、硬件/固件升级和数据中心相关更改,以及对 OpenStack 组件的次要和版本升级都是持续的操作任务。OpenStack 项目的六个月发布周期需要被视为持续维护成本的一部分。该解决方案应考虑存储和网络维护以及对底层工作负载的影响。
可靠性和可用性
可靠性和可用性取决于许多支持组件的可用性以及服务提供商采取的预防措施水平。这包括网络、存储系统、数据中心和操作系统。
有关管理和维护 OpenStack 环境的更多信息,请参阅 OpenStack 操作指南。
记录和监控
OpenStack 云需要适当的监控平台来识别和管理错误。
笔记
我们建议利用现有的监控系统来查看它们是否能够有效地监控 OpenStack 环境。
对捕获至关重要的特定仪表包括:
- 映像磁盘利用率
- 计算 API 的响应时间
对于多站点 OpenStack 云,日志记录和监控没有显着差异。操作指南中的日志记录和监控中描述的工具仍然适用。可以在每个站点的基础上,在一个公共的集中位置提供日志记录和监控。
在尝试将日志记录和监控设施部署到集中位置时,必须注意站点间网络链接上的负载
管理软件
经常使用为云环境提供集群、日志记录、监视和警报详细信息的管理软件。这会影响和影响整个 OpenStack 云设计,并且必须考虑额外的资源消耗,例如 CPU、RAM、存储和网络带宽。
是否包含集群软件(例如 Corosync 或 Pacemaker)主要取决于云基础架构的可用性以及部署后支持配置的复杂性。OpenStack 高可用性指南提供了有关 Corosync 和 Pacemaker 的安装和配置的 更多详细信息,如果这些软件包需要包含在设计中。
其他一些潜在的设计影响包括:
- 操作系统-管理程序组合
确保选定的日志记录、监视或警报工具支持建议的操作系统管理程序组合。- 网络硬件
网络硬件选择需要得到日志、监控和警报软件的支持。
数据库软件
大多数 OpenStack 组件需要访问后端数据库服务来存储状态和配置信息。选择满足 OpenStack 服务的可用性和容错要求的适当后端数据库。
MySQL 是 OpenStack 的默认数据库,但也可以使用其他兼容的数据库。
所选的高可用性数据库解决方案会根据所选数据库而变化。例如,MySQL 提供了几个选项。使用 Galera 等复制技术进行主动-主动集群。对于主动-被动使用某种形式的共享存储。这些潜在的解决方案中的每一个都会对设计产生影响:
- 采用 Galera/MariaDB 的解决方案至少需要三个 MySQL 节点。
- MongoDB 对高可用性有自己的设计考虑。
- OpenStack 设计通常不包括共享存储。但是,对于某些高可用性设计,某些组件可能需要它,具体取决于具体实现。
操作员访问系统
在云环境中托管云操作系统是一种趋势。操作员需要访问这些系统来解决重大事件。
确保网络结构连接所有云,形成一个集成系统。还要考虑切换状态,该状态必须可靠且延迟最小,以实现系统的最佳性能。
如果云的很大一部分位于外部管理的系统上,请为可能无法进行更改的情况做好准备。此外,云提供商可能会在必须如何管理和公开基础设施方面有所不同。这可能会导致根本原因分析的延迟,其中供应商坚持认为责任在于其他供应商。
高可用性
数据平面和控制平面
在设计 OpenStack 云时,重要的是要考虑服务水平协议 (SLA)规定的需求。这包括维持正在运行的计算服务实例、网络、存储和在这些资源之上运行的其他服务的可用性所需的核心服务。这些服务通常被称为数据平面服务,并且通常期望始终可用。
其余的服务,负责创建、读取、更新和删除 (CRUD) 操作、计量、监控等,通常称为控制平面。SLA 可能会规定这些服务的正常运行时间要求较低。
构成 OpenStack 云的服务有许多要求,您需要了解这些要求才能满足 SLA 条款。例如,为了提供最少的存储空间,消息队列和数据库服务以及它们之间的网络是必需的。
如果数据平面和控制平面系统在逻辑和物理上分离,则持续维护操作会变得更加简单。例如,可以在不影响客户的情况下重新启动控制器。如果一个服务故障影响了整个服务器的运行 ( ),控制平面和数据平面之间的分离可以实现快速维护,而对客户运营的影响有限。
消除每个站点内的单点故障
OpenStack 适合以高度可用的方式进行部署,预计至少需要使用 2 台服务器。这些可以运行消息队列服务所涉及的所有服务,例如RabbitMQor QPID,以及适当部署的数据库服务,例如MySQLor MariaDB。随着云中服务的横向扩展,后端服务也需要扩展。监控和报告服务器利用率和响应时间,以及对系统进行负载测试,将有助于确定横向扩展决策。
OpenStack 服务本身应该部署在不代表单点故障的多台服务器上。通过将这些服务置于具有多个 OpenStack 服务器作为成员的高可用性负载平衡器之后,可以确保可用性。
有少量 OpenStack 服务旨在一次只在一个地方运行(例如,ceilometer-agent-central服务)。为了防止这些服务成为单点故障,可以通过集群软件如Pacemaker.
在 OpenStack 中,基础设施是提供服务不可或缺的一部分,并且应该始终可用,尤其是在使用 SLA 操作时。确保网络可用性是通过设计网络架构来实现的,以便不存在单点故障。核心基础设施以及相关的网络绑定应考虑交换机的数量、路由和电源冗余的数量,以便为您的高可用性交换机基础设施提供多种路由。
在决定网络功能时必须小心。目前,OpenStack 支持传统的网络(nova-network)系统和更新的、可扩展的 OpenStack 网络(neutron)。OpenStack 网络和传统网络都有其优点和缺点。它们都是适用于OpenStack Operations Guide中描述的不同网络部署模型的有效且受支持的选项。
使用网络服务时,OpenStack 控制器服务器或单独的网络主机处理路由,除非选择了用于路由的动态虚拟路由器模式。直接在控制器服务器上运行路由会混合数据和控制平面,并可能导致复杂的性能和故障排除问题。可以使用第三方软件和外部设备来帮助维护高度可用的第三层路由。这样做允许通用应用程序端点控制网络硬件,或以安全的方式提供复杂的多层 Web 应用程序。也可以从 Networking 中完全移除路由,转而依赖硬件路由功能。在这种情况下,交换基础设施必须支持第三层路由。
应用程序设计还必须考虑到底层云基础设施的功能。如果计算主机不提供无缝实时迁移功能,那么必须预计如果计算主机发生故障,该实例以及该实例本地的任何数据都将被删除。但是,当向用户提供实例具有高水平正常运行时间保证的期望时,必须以一种在计算主机消失时消除任何单点故障的方式部署基础设施。这可能包括利用企业存储或 OpenStack 块存储上的共享文件系统来提供与服务特性相匹配的保证水平。
如果使用包含对集中式存储的共享访问的存储设计,请确保其设计也没有单点故障,并且解决方案的 SLA 匹配或超过数据平面的预期 SLA。
消除多区域设计中的单点故障
一些服务通常在多个区域之间共享,包括身份服务和仪表板。在这种情况下,有必要确保支持服务的数据库被复制,并且在丢失单个区域的情况下可以保持对每个站点的多个工作人员的访问。
应在站点之间部署多个网络链接,以为所有组件提供冗余。这包括存储复制,它应该被隔离到一个专用网络或 VLAN 中,并能够分配 QoS 来控制复制流量或为此流量提供优先级。
注意
如果数据存储高度可变,则网络要求可能会对维护站点的运营成本产生重大影响。
如果设计包含多个站点,则在两个站点中保持对象可用性的能力对对象存储设计和实施具有重大影响。它还对站点之间的 WAN 网络设计产生重大影响。
如果在云中运行的应用程序不是云感知的,则应该有明确的措施和期望来定义基础设施可以支持和不能支持的内容。一个例子是站点之间的共享存储。这是可能的,但是这样的解决方案不是 OpenStack 原生的,需要第三方硬件供应商来满足这样的要求。另一个例子可以在能够直接消耗对象存储资源的应用程序中看到。
连接两个以上的站点会增加挑战并增加设计考虑的复杂性。多站点实施需要规划解决用于内部和外部连接的附加拓扑。一些选项包括全网状拓扑、中心辐条、脊叶和 3D Torus。
网站丢失和恢复
中断可能导致站点功能部分或全部丧失。应实施策略以了解和计划恢复方案。
- 部署的应用程序需要继续运行,更重要的是,您必须考虑站点不可用时对应用程序性能和可靠性的影响。
- 重要的是要了解当站点出现故障时站点之间的对象和数据复制会发生什么。如果这导致队列开始建立,请考虑这些队列可以安全存在多长时间,直到发生错误。
- 中断后,确保站点恢复联机时恢复运行。我们建议您构建恢复以避免竞争条件。
复制站点间数据
传统上,复制一直是保护对象存储实现的最佳方法。存储架构中存在多种复制方法,例如同步和异步镜像。大多数对象存储和后端存储系统在存储子系统层实现复制方法。对象存储还定制复制技术以适应云的要求。
组织必须在数据完整性和数据可用性之间找到适当的平衡。复制策略也可能影响灾难恢复方法。
跨不同机架、数据中心和地理区域的复制增加了对确定和确保数据位置的关注。保证从最近或最快的存储访问数据的能力对于应用程序的良好运行可能是必要的。
注意
运行嵌入式对象存储方法时,请确保您不会引发额外的数据复制,因为这可能会导致性能问题。
设计
设计 OpenStack 云需要了解云用户的需求,并需要确定最佳配置。本章为您在设计过程中需要做出的决定提供指导。
要设计、部署和配置 OpenStack,管理员必须了解逻辑架构。OpenStack 模块是以下类型之一:
守护进程
作为后台进程运行。在 Linux 平台上,守护程序通常作为服务安装。
脚本
安装虚拟环境并运行测试。
命令行界面 (CLI)
使用户能够通过命令向 OpenStack 服务提交 API 调用。
OpenStack 逻辑架构展示了 OpenStack 中最常见的集成服务的一个示例,以及它们如何相互交互。最终用户可以通过仪表板、CLI 和 API 进行交互。所有服务都通过公共身份服务进行身份验证,并且各个服务通过公共 API 相互交互,除非需要特权管理员命令。

OpenStack 逻辑架构
计算架构
计算服务器架构概述
在设计计算资源池时,请考虑处理器数量、内存量、网络要求、每个管理程序所需的存储量,以及对通过 Ironic 配置的裸机主机的任何要求。
在构建 OpenStack 云时,作为规划过程的一部分,您不仅要确定要使用的硬件,还要确定计算资源是在单个池中提供,还是在多个池或可用区中提供。您应该考虑云是否会为计算提供截然不同的配置文件。
例如,基于 CPU、内存或本地存储的计算节点。对于基于 NFV 或 HPC 的云,甚至可能存在应为特定计算节点上的特定工作负载保留的特定网络配置。这种将特定资源设计成计算组或区域的方法可以称为装箱。
注意
在 bin oacking 设计中,每个独立的资源池都为特定的口味提供服务。由于实例被调度到计算管理程序上,每个独立节点的资源将被分配以有效地使用可用硬件。虽然 bin 打包可以将工作负载特定资源分离到各个服务器上,但 bin 打包还需要通用硬件设计,计算资源池中的所有硬件节点共享通用处理器、内存和存储布局。这使得在节点的整个生命周期内部署、支持和维护节点变得更加容易。
增加支持计算环境的大小会增加网络流量和消息,增加用于支持 OpenStack 云或网络节点的控制器和管理服务的负载。在考虑控制器节点的硬件时,无论是使用单片控制器设计,其中所有控制器服务都位于一个或多个物理硬件节点上,还是在任何较新的无共享控制平面模型中,都必须分配和扩展足够的资源以满足规模要求。对环境的有效监控将有助于扩展容量决策。随着云的扩展,适当的规划将有助于避免瓶颈和网络超额订阅。
计算节点自动连接到 OpenStack 云,从而在向 OpenStack 云添加额外计算容量时实现水平扩展过程。为了进一步对计算节点进行分组并将节点放置到适当的可用区和主机聚合中,需要进行额外的工作。有必要规划机架容量和网络交换机,因为横向扩展计算主机会直接影响数据中心基础设施资源,就像任何其他基础设施扩展一样。
虽然在大型企业中并不常见,但计算主机组件也可以升级以满足需求的增长,这称为垂直扩展。根据正在运行的应用程序是 CPU 密集型还是内存密集型,升级具有更多内核的 CPU 或增加整体服务器内存可以增加额外所需的容量。我们建议滚动升级计算节点以实现冗余和可用性。升级后,当计算节点返回 OpenStack 集群时,会重新扫描,并在 OpenStack 数据库中调整发现新资源。
选择处理器时,比较特性和性能特征。一些处理器包括特定于虚拟化计算主机的功能,例如硬件辅助虚拟化,以及与内存分页相关的技术(也称为 EPT 影子)。这些类型的功能会对虚拟机的性能产生重大影响。
处理器内核和线程的数量会影响可以在资源节点上运行的工作线程的数量。设计决策必须与在其上运行的服务直接相关,并为所有服务提供平衡的基础架构。
另一种选择是评估平均工作负载并通过调整过量使用率来增加可以在计算环境中运行的实例数量。此比率可针对 CPU 和内存进行配置。默认 CPU 过量使用比例为 16:1,默认内存过量使用比例为 1.5:1。在设计阶段确定过度使用比率的调整非常重要,因为它直接影响计算节点的硬件布局。
注意
更改 CPU 过度使用率可能会产生不利影响,并导致嘈杂邻居的潜在增加。
磁盘容量不足也可能对包括 CPU 和内存使用在内的整体性能产生负面影响。根据 OpenStack 块存储层的后端架构,容量包括向企业存储系统添加磁盘架或安装额外的块存储节点。可能需要升级安装在计算主机中的直接附加存储,并为共享存储增加容量以便为实例提供额外的临时存储。
考虑非管理程序节点(也称为资源节点)的计算要求。这包括控制器、对象存储节点、块存储节点和网络服务。
应考虑为不可预测的工作负载创建池或可用区的能力。在某些情况下,对某些实例类型或风格的需求可能无法证明单独的硬件设计是合理的。分配能够服务于最常见实例请求的硬件设计。可以稍后将硬件添加到整体架构中。
选择 CPU
计算节点中的 CPU 类型是一个非常重要的决定。您必须确保 CPU 通过VT-x支持 Intel 芯片和AMD-v支持 AMD 芯片的虚拟化。
提示
请查阅供应商文档以检查虚拟化支持。对于英特尔 CPU,请参阅 我的处理器是否支持英特尔® 虚拟化技术?. 对于 AMD CPU,请参阅AMD 虚拟化。您的 CPU 可能支持虚拟化,但它可能被禁用。有关如何启用 CPU 功能的信息,请参阅您的 BIOS 文档。
CPU 的核心数量也会影响您的决定。当前的 CPU 通常拥有多达 24 个内核。此外,如果 Intel CPU 支持超线程,那么这 24 个内核将加倍为 48 个内核。如果您购买支持多个 CPU 的服务器,则内核数量会进一步成倍增加。
从 Kilo 版本开始,OpenStack 代码中添加了关键增强功能,以提高客户性能。这些改进使计算服务能够更深入地了解计算主机的物理布局,从而在工作负载放置方面做出更明智的决策。管理员可以使用此功能为 NFV(网络功能虚拟化)和 HPC(高性能计算)等用例启用更明智的规划选择。
在选择 CPU 大小和类型时,考虑非统一内存访问 (NUMA) 很重要,因为有些用例使用 NUMA 固定来为操作系统进程保留主机内核。这些减少了工作负载的可用 CPU 并保护了操作系统。
提示
当为来宾请求 CPU 固定时,假定没有过度使用(或过度使用比率为 1.0)。当没有为工作负载请求专用资源时,将应用正常的过度使用比率。
因此,我们建议使用主机聚合来分隔裸机主机,以及为需要专用资源的工作负载提供资源的主机。也就是说,当工作负载被配置到 NUMA 主机聚合时,NUMA 节点是随机选择的,vCPU 可以在主机上的 NUMA 节点之间浮动。如果工作负载需要 SR-IOV 或 DPDK,则应将它们分配到具有提供该功能的主机的 NUMA 节点聚合。更重要的是,由于跨节点内存带宽的数量有限,正在为工作负载执行进程的工作负载或 vCPU 应该位于同一个 NUMA 节点上。在所有情况下,都NUMATopologyFilter 必须为nova-scheduler.
此外,CPU 选择可能不是针对企业的一刀切,而是针对企业工作负载调整的更多 SKU 列表。
有关 NUMA 的详细信息,请参阅管理员指南中的CPU 拓扑。
为了利用计算服务中的这些新增强功能,计算主机必须使用支持 NUMA 的 CPU。
提示
多线程注意事项
超线程是英特尔专有的同步多线程实现,用于改进其 CPU 的并行化。您可以考虑启用超线程来提高多线程应用程序的性能。
是否应在 CPU 上启用超线程取决于您的用例。例如,禁用超线程在密集计算环境中可能是有益的。我们建议在打开和关闭超线程的情况下对您的本地工作负载进行性能测试,以确定更适合您的情况。
在大多数情况下,与非超线程 CPU 相比,超线程 CPU 可以提供 1.3 到 2.0 倍的性能优势,具体取决于工作负载的类型。
选择管理程序
管理程序提供软件来管理虚拟机对底层硬件的访问。管理程序创建、管理和监视虚拟机。OpenStack Compute (nova) 在不同程度上支持许多虚拟机管理程序,包括:
Ironic
KVM
LXC
QEMU
VMware ESX/ESXi
Xen (using libvirt)
XenServer
Hyper-V
PowerVM
UML
Virtuozzo
zVM
选择管理程序的一个重要因素是您当前组织的管理程序使用或体验。同样重要的是管理程序的功能对等、文档和社区体验水平。
根据最近的 OpenStack 用户调查,KVM 是 OpenStack 社区中采用最广泛的管理程序。除了 KVM,还有许多运行其他管理程序的部署,例如 LXC、VMware、Xen 和 Hyper-V。但是,与更常用的管理程序相比,这些管理程序要么使用较少,要么是小众管理程序,要么功能有限。
笔记
还可以使用主机聚合或单元在单个部署中运行多个管理程序。但是,单个计算节点一次只能运行一个管理程序。
有关虚拟机管理程序以及 Ironic 和 Virtuozzo(以前称为 Parallels)的功能支持的更多信息,请参阅 配置参考中的虚拟机管理程序支持矩阵 和虚拟机管理程序。
选择服务器硬件
在选择计算服务器硬件时考虑以下因素:
服务器密度
衡量有多少服务器可以放入给定的物理空间度量中,例如机架单元 [U]。
资源容量
给定服务器提供的 CPU 内核数、RAM 量或存储量。
可扩展性
在服务器达到容量之前可以添加到服务器的额外资源的数量。
成本
硬件的相对成本与基于预定要求的硬件可用容量总量相权衡。
权衡这些考虑因素以确定达到预期目的的最佳设计。例如,增加服务器密度意味着牺牲资源容量或可扩展性。它还可以降低可用性并增加嘈杂的邻居问题的机会。增加资源容量和可扩展性会增加成本,但会降低服务器密度。降低成本通常意味着降低可支持性、可用性、服务器密度、资源容量和可扩展性。
在构建云之前确定对云的要求,并规划硬件生命周期,以及可能需要不同硬件的扩展和新功能。
如果云最初是用接近生命周期的但具有成本效益的硬件构建的,那么新工作负载的性能和容量需求将推动购买更现代的硬件。随着单个硬件组件随时间变化,您可能更愿意将配置作为库存单位 (SKU) 进行管理。这种方法为企业提供了一个标准的计算配置单元(服务器),可以放置在任何 IT 服务经理或供应商提供的订购系统中,可以手动或通过高级操作自动化触发。这简化了订购、供应和激活额外计算资源的过程。例如,有几个商业服务管理工具的插件可以与硬件 API 集成。它们根据标准配置从备用硬件配置和激活新的计算资源。使用这种方法,可以为数据中心订购备用硬件,并根据从 OpenStack Telemetry 获得的容量数据进行配置。
计算容量(CPU 内核和 RAM 容量)是选择服务器硬件的次要考虑因素。所需的服务器硬件必须提供足够的 CPU 插槽、额外的 CPU 内核和足够的 RA。有关详细信息,请参阅 选择 CPU。
在计算服务器架构设计中,您还必须考虑网络和存储要求。有关网络注意事项的更多信息,请参阅 网络架构。
选择硬件时的注意事项
以下是为计算服务器选择硬件时需要考虑的其他一些因素。
实例密度
如果设计架构使用双路硬件设计,则需要更多主机来支持预期规模。
对于通用 OpenStack 云,规模是一个重要的考虑因素。每个虚拟机管理程序可以托管的预期或预期实例数量是用于确定部署规模的常用计量器。选定的服务器硬件需要支持预期或预期的实例密度。
主机密度
解决更高主机数量的另一个选择是使用四插槽平台。采用这种方法会降低主机密度,这也会增加机架数量。这种配置会影响电源连接的数量,也会影响网络和冷却要求。
物理数据中心的物理空间、电力和冷却能力有限。可以适应给定指标(机架、机架单元或地砖)的主机(或管理程序)的数量是确定大小的另一种重要方法。地板重量是一个经常被忽视的考虑因素。
数据中心地板必须能够支撑一个或一组机架内建议数量的主机的重量。这些因素需要作为主机密度计算和服务器硬件选择的一部分加以应用。
功率和冷却密度
由于主机密度较低(通过使用 2U、3U 甚至 4U 服务器设计),电源和冷却密度要求可能低于刀片式服务器、底座或 1U 服务器设计。对于基础设施较旧的数据中心,这可能是一个理想的功能。
数据中心向给定的机架或一组机架提供特定数量的电力。较旧的数据中心的每个机架的功率密度可能低至 20A,而当前的数据中心可以设计为支持每个机架高达 120A 的功率密度。选择的服务器硬件必须考虑功率密度。
选择硬件外形
在选择适合您的 OpenStack 设计架构的服务器硬件外形尺寸时,请考虑以下因素:
-
大多数刀片服务器都可以支持双插槽多核 CPU。要避免此 CPU 限制,请选择或刀片。但是请注意,这也会降低服务器密度。例如,HP BladeSystem 或 Dell PowerEdge M1000e 等高密度刀片服务器仅在 10 个机架单元中支持多达 16 个服务器。使用半高刀片的密度是使用全高刀片的两倍,这导致每十个机架单元只有八台服务器。full widthfull height
-
1U 机架式服务器能够提供比刀片服务器解决方案更高的服务器密度,但通常仅限于双插槽、多核 CPU 配置。与 32 个全宽刀片服务器相比,可以在一个机架中放置 40 个 1U 服务器,为架顶式 (ToR) 交换机提供空间。
要在 1U 机架式外形尺寸中获得超过双插槽的支持,客户需要从原始设计制造商 (ODM) 或二级制造商处购买系统
警告
这可能会导致具有首选供应商政策或关注非 1 级供应商的支持和硬件保修的组织出现问题。
-
2U 机架式服务器提供四插槽、多核 CPU 支持,但服务器密度相应降低(是 1U 机架式服务器提供的密度的一半)。
-
更大的机架式服务器,例如 4U 服务器,通常提供更大的 CPU 容量,通常支持四个甚至八个 CPU 插槽。这些服务器具有更大的可扩展性,但此类服务器的服务器密度要低得多,而且通常更昂贵。
-
Sled servers是机架式服务器,支持单个 2U 或 3U 机箱中的多个独立服务器。与典型的 1U 或 2U 机架式服务器相比,它们提供更高的密度。例如,许多雪橇服务器在 2U 中提供四个独立的双插槽节点,在 2U 中总共有八个 CPU 插槽。
扩展你的云
在设计 OpenStack 云计算服务器架构时,您必须决定是要纵向扩展还是横向扩展。选择较少数量的大型主机或大量小型主机取决于多种因素:成本、电力、冷却、物理机架和占地面积、支持-保修和可管理性。通常,横向扩展模型在 OpenStack 中很受欢迎,因为它通过将工作负载分散到更多基础架构中来减少可能的故障域的数量。然而,不利的一面是额外服务器的成本以及为服务器供电、联网和冷却所需的数据中心资源。
过度使用 CPU 和 RAM
OpenStack 允许您在计算节点上过度使用 CPU 和 RAM。这允许您以降低实例性能为代价增加在云上运行的实例数量。Compute 服务默认使用以下比率:
- CPU分配比例:16:1
- RAM分配比例:1.5:1
默认的 CPU 分配比例 16:1 意味着调度程序为每个物理内核分配最多 16 个虚拟内核。例如,如果一个物理节点有 12 个核心,调度程序会看到 192 个可用的虚拟核心。对于每个实例 4 个虚拟内核的典型风味定义,这个比率将在一个物理节点上提供 48 个实例。
计算节点上虚拟实例数的公式为 (OR*PC)/VC,其中:
或者
CPU 过量使用率(每个物理内核的虚拟内核数)
个人电脑
物理核心数
风险投资
每个实例的虚拟核心数
同样,默认的 RAM 分配比率 1.5:1 意味着调度程序将实例分配给物理节点,只要与实例关联的 RAM 总量小于物理节点上可用 RAM 量的 1.5 倍。
例如,如果一个物理节点有 48 GB 的 RAM,则调度程序将实例分配给该节点,直到与实例关联的 RAM 总和达到 72 GB(例如 9 个实例,在每个实例都有 8 GB RAM 的情况下) )。
笔记
无论超量使用率如何,都不能将实例放置在原始(超量使用前)资源少于实例类型所需资源的任何物理节点上。
您必须为您的特定用例选择适当的 CPU 和 RAM 分配比率。
实例存储解决方案
作为计算集群架构设计的一部分,您必须为运行实例化实例的磁盘指定存储。提供临时存储的主要方法有以下三种:
-
离计算节点存储——共享文件系统
-
计算节点存储——共享文件系统
-
在计算节点存储——非共享文件系统
一般来说,您在选择存储时应该问的问题如下:
-
我的工作量是多少?
-
我的工作负载是否有 IOPS 要求?
-
是否有读、写或随机访问性能要求?
-
我对计算存储扩展的预测是什么?
-
我的企业当前使用什么存储?可以重新利用吗?
-
如何在操作上管理存储?
许多运营商使用单独的计算和存储主机,而不是超融合解决方案。计算服务和存储服务有不同的要求,计算主机通常比存储主机需要更多的 CPU 和 RAM。因此,对于固定预算,为您的计算节点和存储节点设置不同的配置是有意义的。计算节点将投资于 CPU 和 RAM,存储节点将投资于块存储。
但是,如果您在可用于创建云的物理主机数量方面受到更多限制,并且您希望能够将尽可能多的主机专用于运行实例,那么在同一台服务器上运行计算和存储是有意义的机器或使用可用的现有存储阵列。
接下来的几节将提供三种主要的实例存储方法。
基于非计算节点的共享文件系统
在此选项中,存储正在运行的实例的磁盘托管在计算节点之外的服务器中。
如果您使用单独的计算和存储主机,您可以将您的计算主机视为“无状态”。只要您当前没有在计算主机上运行任何实例,您就可以使其脱机或完全擦除它,而不会对云的其余部分产生任何影响。这简化了计算主机的维护。
这种方法有几个优点:
-
如果计算节点发生故障,实例通常很容易恢复。
-
运行专用存储系统可以在操作上更简单。
-
您可以扩展到任意数量的主轴。
-
可能出于其他目的共享外部存储。
这种方法的主要缺点是:
-
根据设计,某些实例的大量 I/O 使用可能会影响不相关的实例。
-
使用网络会降低性能。
-
可扩展性会受到网络架构的影响。
在计算节点存储——共享文件系统
在此选项中,每个计算节点都指定有大量磁盘空间,但分布式文件系统将每个计算节点的磁盘绑定到一个安装中。
此选项的主要优点是,当您需要额外存储时,它可以扩展到外部存储。
但是,此选项有几个缺点:
-
与非共享存储相比,运行分布式文件系统可能会使您失去数据局部性。
-
由于依赖于多个主机,实例的恢复变得复杂。
-
计算节点的机箱尺寸会限制计算节点中能够使用的心轴数量。
-
使用网络会降低性能。
-
计算节点的丢失会降低所有主机的存储可用性。
在计算节点存储——非共享文件系统
在此选项中,每个计算节点都指定有足够的磁盘来存储它托管的实例。
有两个主要优点:
-
一个计算节点上的大量 I/O 使用不会影响其他计算节点上的实例。直接 I/O 访问可以提高性能。
-
每个主机可以有不同的存储配置文件用于主机聚合和可用区。
有几个缺点:
-
如果计算节点发生故障,与在该节点上运行的实例关联的数据将丢失。
-
计算节点的机箱尺寸会限制计算节点中能够使用的心轴数量。
-
将实例从一个节点迁移到另一个节点更加复杂,并且依赖于可能不会继续开发的功能。
-
如果需要额外的存储空间,则此选项无法扩展。
在除计算节点之外的存储系统上运行共享文件系统非常适合可靠性和可扩展性是最重要因素的云。在计算节点本身上运行共享文件系统可能最好在您必须部署到您几乎无法控制其规格或具有特定存储性能需求但不需要的预先存在的服务器的情况下持久存储。
实时迁移的问题
实时迁移是云操作不可或缺的一部分。此功能提供了将实例从一个物理主机无缝移动到另一个物理主机的能力,这是执行需要重新启动计算主机的升级的必要条件,但仅适用于共享存储。
使用称为KVM 实时块迁移的功能,也可以使用非共享存储进行实时迁移。虽然早期在 KVM 和 QEMU 中实现基于块的迁移被认为是不可靠的,但在 Mitaka 版本中,基于块的实时迁移实现了更新、更可靠的实现。
实时迁移和块迁移仍然存在一些问题:
-
错误报告在 Mitaka 和 Newton 中受到了一些关注,但还需要改进。
-
实时迁移资源跟踪问题。
-
获救图像的实时迁移。
文件系统的选择
如果要支持共享存储实时迁移,则需要配置分布式文件系统。
可能的选项包括:
-
NFS (default for Linux)
-
Ceph
-
GlusterFS
-
MooseFS
-
Lustre
我们建议您选择运营商最熟悉的选项。NFS 是最容易设置的,并且有广泛的社区知识。
网络连接
选择的服务器硬件必须具有适当数量的网络连接,以及正确类型的网络连接,以支持建议的架构。确保至少有两个不同的网络连接进入每个机架。
外形尺寸或架构的选择会影响服务器硬件的选择。确保所选服务器硬件配置为支持足够的存储容量(或存储可扩展性),以满足所选横向扩展存储解决方案的要求。同样,网络架构会影响服务器硬件选择,反之亦然。
虽然每个企业安装都不同,但强烈建议将以下具有建议带宽的网络用于基本的生产 OpenStack 安装。
安装或 OOB 网络- 大多数发行版和供应工具通常将其用作将基础软件部署到 OpenStack 计算节点的网络。该网络的连接速度至少应为 1Gb,并且通常不需要路由。
内部或管理网络- 用作 OpenStack 计算和控制节点之间的内部通信网络。也可以用作计算和 iSCSI 存储节点之间的 iSCSI 通信网络。同样,这应该是一个至少 1Gb 的 NIC,并且应该是一个非路由网络。对于高可用性 (HA),此接口应该是冗余的。
租户网络- 启用每个租户实例之间通信的专用网络。如果使用平面网络和提供商网络,则此网络是可选的。该网络还应与所有其他网络隔离以确保安全合规。一个 1Gb 的接口对于 HA 应该是足够且冗余的。
存储网络- 可以连接到 Ceph 前端或其他共享存储的专用网络。出于 HA 目的,这应该是带有建议的 10Gb NIC 的冗余配置。该网络将实例的存储与其他网络隔离开来。在负载下,这种存储流量可能会使其他网络不堪重负,并导致其他 OpenStack 服务中断。
(可选)外部或公共网络- 此网络用于从 VM 与公共网络空间进行外部通信。这些地址通常由控制器节点上的中子代理处理,也可以由中子以外的 SDN 处理。但是,当使用带有 OVS 的中子 DVR 时,该网络必须存在于计算节点上,因为南北流量不会由控制器节点处理,而是由计算节点本身处理。有关具有 OVS 和计算节点的 DVR 的更多信息,请参阅 Open vSwitch:使用 DVR 的高可用性
计算服务器日志
计算节点或任何运行 nova-compute 的服务器(例如在超融合架构中)上的日志是解决管理程序和计算服务问题的主要点。此外,操作系统日志也可以提供有用的信息。
随着云环境的增长,日志数据量呈指数级增长。在 OpenStack 服务或操作系统上启用调试会进一步加剧数据问题。
日志记录和监控中更详细地描述了日志记录。但是,在开始运行您的云之前,这是一个重要的设计考虑因素。
OpenStack 会产生大量有用的日志信息,但是为了使这些信息对操作有用,您应该考虑拥有一个中央日志服务器来发送日志,以及一个日志解析/分析系统,例如 Elastic Stack [以前称为 ELK ]。
Elastic Stack 主要由三个组件组成:Elasticsearch(日志搜索和分析)、Logstash(日志接收、处理和输出)和 Kibana(日志仪表板服务)。
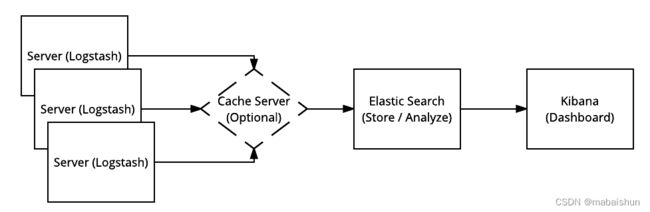
由于在 OpenStack 环境中从服务器发送大量日志,因此可以使用可选的内存数据结构存储。常见的例子是 Redis 和 Memcached。在较新版本的 Elastic Stack 中,名为 Filebeat的文件缓冲区用于类似目的,但在向 Logstash 或 Elasticsearch 发送数据时添加了“背压敏感”协议。
日志分析通常需要不同格式的不同日志。创建 Elastic Stack(即 Logstash)是为了接受许多不同的日志输入并将它们转换为 Elasticsearch 可以编目和分析的一致格式。如上图所示,通过 Logstash 在服务器上进行摄取的过程,转发到 Elasticsearch 服务器进行存储和搜索,然后通过 Kibana 展示出来进行可视化分析和交互。
有关安装 Logstash、Elasticsearch 和 Kibana 的说明,请参阅 Elasticsearch 参考。
为 OpenStack 配置 Logstash 需要一些特定的配置参数。例如,为了让 Logstash 收集、解析日志文件的正确部分并将其发送到 Elasticsearch 服务器,您需要正确格式化配置文件。有输入、输出和过滤器配置。输入配置告诉 Logstash 从哪里接收数据(日志文件/转发器/filebeats/StdIn/Eventlog),输出配置指定放置数据的位置,过滤器配置定义要转发到输出的输入内容。
Logstash 过滤器对每个事件执行中间处理。根据输入和事件的特征应用条件过滤器。过滤的一些示例是:
-
grok
-
date
-
csv
-
json
还有可用的输出过滤器将事件数据发送到许多不同的目的地。一些例子是:
-
csv
-
redis
-
elasticsearch
-
file
-
jira
-
nagios
-
pagerduty
-
stdout
此外,还有几种编解码器可用于更改事件的数据表示,例如:
-
collectd
-
graphite
-
json
-
plan
-
rubydebug
这些输入、输出和过滤器配置通常存储在 /etc/logstash/conf.dLinux 发行版中,但可能会有所不同。应为不同的日志系统(如 syslog、Apache 和 OpenStack)创建单独的配置文件。
一般示例和配置指南可以在 Elastic Logstash 配置页面上找到。
OpenStack 输入、输出和过滤器示例可以在 sorantis/elkstack找到。
配置完成后,Kibana 可以用作 OpenStack 和系统日志记录的可视化工具。这将允许操作员为性能、监控和安全配置自定义仪表板。
Storage 架构
存储概念
在 OpenStack 云环境的许多部分都可以找到存储。了解临时存储和 持久存储之间的区别很重要 :
临时存储 - 如果您只部署 OpenStack 计算服务 (nova),默认情况下您的用户无权访问任何形式的持久存储。与 VM 关联的磁盘是临时的,这意味着从用户的角度来看,它们会在虚拟机终止时消失。
持久存储 - 持久存储意味着存储资源比任何其他资源的寿命都要长,并且始终可用,而不管正在运行的实例的状态如何。
OpenStack 云明确支持三种类型的持久存储:对象存储、块存储和基于文件的存储。
对象存储
对象存储在 OpenStack 中由对象存储服务 (swift) 实现。用户通过 REST API 访问二进制对象。如果您的目标用户需要归档或管理大型数据集,您应该为他们提供对象存储服务。其他好处包括:
OpenStack 可以将您的虚拟机 (VM) 映像存储在对象存储系统中,作为将映像存储在文件系统上的替代方法。
与 OpenStack Identity 集成,并与 OpenStack Dashboard 一起使用。
通过支持异步最终一致性复制,更好地支持跨多个数据中心的分布式部署。
如果您最终计划将存储集群分布在多个数据中心,如果您需要为计算和对象存储的用户提供统一帐户,或者如果您想使用 OpenStack 控制您的对象存储,您应该考虑使用 OpenStack 对象存储服务仪表板。有关更多信息,请参阅Swift 项目页面。
块存储
块存储在 OpenStack 中由块存储服务(cinder)实现。因为这些卷是持久的,所以它们可以从一个实例分离并重新附加到另一个实例,并且数据保持不变。
块存储服务以驱动程序的形式支持多个后端。块存储驱动程序必须支持您选择的存储后端。
大多数块存储驱动程序允许实例直接访问底层存储硬件的块设备。这有助于增加整体读/写 IO。但是,对将文件用作卷的支持也很成熟,完全支持 NFS、GlusterFS 等。
这些驱动程序的工作方式与传统的块存储驱动程序略有不同。在 NFS 或 GlusterFS 文件系统上,会创建一个文件,然后将其作为虚拟卷映射到实例中。这种映射和转换类似于 OpenStack 如何利用 QEMU 的基于文件的虚拟机存储在/var/lib/nova/instances.
基于文件的存储
在多租户 OpenStack 云环境中,共享文件系统服务 (manila) 提供了一组用于管理共享文件系统的服务。共享文件系统服务以驱动程序的形式支持多个后端,并且可以配置为从一个或多个后端提供共享。共享服务器是使用不同文件系统协议(例如 NFS、CIFS、GlusterFS 或 HDFS)导出文件共享的虚拟机。
共享文件系统服务是持久存储,可以安装到任意数量的客户端机器上。它也可以从一个实例分离并附加到另一个实例而不会丢失数据。在此过程中,除非更改或删除共享文件系统服务本身,否则数据是安全的。
用户通过在他们的实例上安装远程文件系统来与共享文件系统服务进行交互,并使用这些系统进行文件存储和交换。共享文件系统服务提供共享,它是一个远程的、可挂载的文件系统。您可以一次挂载一个共享并由多个用户从多个主机访问一个共享。通过共享,您还可以:
-
创建指定其大小、共享文件系统协议、可见性级别的共享。
-
根据选择的后端模式,使用或不使用共享网络,在共享服务器或独立服务器上创建共享。
-
为现有共享指定访问规则和安全服务。
-
将多个共享组合成组,以保持组内的数据一致性,以进行以下安全组操作。
-
创建选定共享或共享组的快照,以一致地存储现有共享或以一致的方式从该快照创建新共享。
-
从快照创建共享。
-
为特定共享和快照设置速率限制和配额。
-
查看共享资源的使用情况。
-
删除共享。
存储类型之间的差异
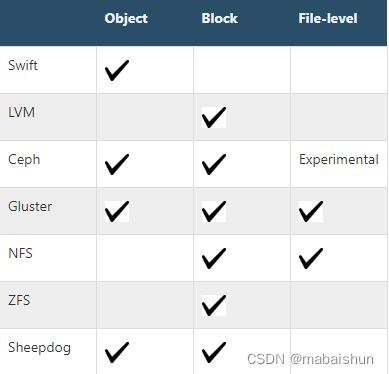
Table. OpenStack storage 存储解释了 Openstack 存储类型之间的差异。
**Table. OpenStack storage **

** 笔记**
用于实时迁移的文件级存储
通过文件级存储,用户可以使用操作系统的文件系统接口访问存储的数据。大多数以前使用过网络存储解决方案的用户都遇到过这种形式的网络存储。Unix 最常用的文件系统协议是 NFS,Windows 是 CIFS(以前是 SMB)。
OpenStack 云不向最终用户提供文件级存储。但是,在设计云时考虑存储实例的文件级存储很重要/var/lib/nova/instances,因为如果要支持实时迁移,则必须具有共享文件系统。
Commodity storage technologies
有各种可用的商品存储后端技术。根据您的云用户的需求,您可以以不同的组合实施这些技术中的一种或多种。
Ceph
Ceph 是一种可扩展的存储解决方案,可跨商品存储节点复制数据。
Ceph 利用对象存储机制进行数据存储,并通过不同类型的存储接口向最终用户公开数据,它支持以下接口: - 对象存储 - 块存储 - 文件系统接口
Ceph 提供对与 swift 相同的对象存储 API 的支持,可用作块存储服务 (cinder) 的后端以及用于 Glance 图像的后端存储。
Ceph 支持使用写时复制实现的精简配置。这在从卷引导时很有用,因为可以非常快速地配置新卷。Ceph 还支持基于 keystone 的身份验证(从 0.56 版开始),因此它可以无缝换入默认的 OpenStack swift 实现。
Ceph 的优势包括:
-
管理员对数据分发和复制策略有更细粒度的控制。
-
对象存储和块存储的整合。
-
使用精简配置快速配置从卷启动的实例。
-
支持分布式文件系统接口 CephFS。
如果您想在单个系统中管理对象和块存储,或者如果您想支持从卷快速启动,则应该考虑 Ceph。
Gluster
分布式共享文件系统。从 Gluster 3.3 版开始,您可以使用 Gluster 将您的对象存储和文件存储整合到一个统一的文件和对象存储解决方案中,称为 Gluster For OpenStack (GFO)。GFO 使用 swift 的定制版本,使 Gluster 可以用作后端存储。
使用 GFO 而不是 swift 的主要原因是,如果您还想支持分布式文件系统,要么支持共享存储实时迁移,要么将其作为单独的服务提供给最终用户。如果您想在单个系统中管理您的对象和文件存储,您应该考虑 GFO。
LVM
逻辑卷管理器 (LVM) 是一个基于 Linux 的系统,它在物理磁盘之上提供一个抽象层以将逻辑卷暴露给操作系统。LVM 后端将块存储实现为 LVM 逻辑分区。
在每个将容纳块存储的主机上,管理员必须首先创建一个专用于块存储卷的卷组。块是从 LVM 逻辑卷创建的。
笔记
LVM 不提供任何复制。通常,管理员在使用 LVM 作为块存储的节点上配置 RAID,以防止单个硬盘驱动器发生故障。但是,RAID 不能防止整个主机出现故障。
iSCSI
Internet 小型计算机系统接口 (iSCSI) 是一种在传输控制协议 (TCP) 之上运行的网络协议,用于链接数据存储设备。它在服务器上的 iSCSI 启动器和存储设备上的 iSCSI 目标之间传输数据。
iSCSI 适用于具有块存储服务以支持应用程序或文件共享系统的云环境。与其他存储后端技术相比,可以以更低的成本实现网络连接,因为 iSCSI 不需要主机总线适配器 (HBA) 或特定于存储的网络设备。
NFS
网络文件系统 (NFS) 是一种文件系统协议,它允许用户或管理员在服务器上安装文件系统。文件客户端可以通过远程过程调用 (RPC) 访问挂载的文件系统。
NFS 的好处是由于共享 NIC 和传统网络组件,实现成本低,并且配置和设置过程更简单。
有关配置块存储以使用 NFS 存储的更多信息,请参阅 OpenStack 管理员指南中的配置 NFS 存储后端。
Sheepdog
Sheepdog 是一个用户空间分布式存储系统。Sheepdog 可扩展到数百个节点,并具有强大的虚拟磁盘管理功能,如快照、克隆、回滚和精简配置。
它本质上是一个对象存储系统,它以智能的方式在商用硬件上以超大规模线性方式管理磁盘并聚合磁盘的空间和性能。Sheepdog 在其对象存储之上,提供弹性卷服务和 http 服务。Sheepdog 确实需要特定的内核版本,并且可以很好地与 xattr 支持的文件系统一起工作。
ZFS
OpenStack 块存储的 Solaris iSCSI 驱动程序将块实现为 ZFS 实体。ZFS 是一个文件系统,它也具有卷管理器的功能。这与 Linux 系统不同,在 Linux 系统中,卷管理器 (LVM) 和文件系统(例如 ext3、ext4、xfs 和 btrfs)是分开的。ZFS 与 ext4 相比具有许多优势,包括改进的数据完整性检查。
OpenStack 块存储的 ZFS 后端仅支持基于 Solaris 的系统,例如 Illumos。虽然有 ZFS 的 Linux 端口,但它不包含在任何标准 Linux 发行版中,并且尚未使用 OpenStack 块存储进行测试。与 LVM 一样,ZFS 自身不提供跨主机复制,如果您的云需要能够处理存储节点故障,则需要在 ZFS 之上添加复制解决方案。
存储架构
在设计 OpenStack 云时,有许多不同的存储架构可用。OpenStack 平台内的编排和自动化的融合实现了快速存储配置,而无需像卷创建和附加这样的传统手动过程的麻烦。
但是,在选择存储架构之前,应该回答几个通用问题:
-
随着云的增长,存储架构会线性扩展吗?它的限制是什么?
-
所需的连接方法是什么:NFS、iSCSI、FC 还是其他?
-
存储是否经过 OpenStack 平台验证?
-
供应商在社区内提供的支持水平如何?
-
cinder 驱动程序支持哪些 OpenStack 功能和增强功能?
-
它是否包括帮助排除故障和解决性能问题的工具?
-
它是否可以与您计划在云中使用的所有项目互操作?
选择存储后端
用户将指出其云架构的不同需求。有些人可能需要快速访问许多不经常更改的对象,或者想要在文件上设置生存时间 (TTL) 值。其他人可能只访问与文件系统本身一起挂载的存储,但希望在启动新实例时立即复制它。对于其他系统,临时存储是首选。当您选择 storage back ends时,请从用户的角度考虑以下问题:
首先也是最重要的:
-
我需要块存储吗?
-
我需要对象存储吗?
-
我需要基于文件的存储吗?
接下来回答以下问题:
-
我需要支持实时迁移吗?
-
我的持久存储驱动器应该包含在我的计算节点中,还是应该使用外部存储?
-
关于 IOPS,我需要什么类型的性能?每个实例的总 IOPS 和 IOPS?我有带有 IOPS SLA 的应用程序吗?
-
我的存储需求主要是读取、写入还是混合?
-
哪些存储选择可以实现我所追求的最佳性价比方案?
-
如何在操作上管理存储?
-
存储的冗余和分布式程度如何?如果存储节点发生故障会怎样?它可以在多大程度上减轻我的数据丢失灾难情况?
-
我的公司目前正在使用什么,我可以将它与 OpenStack 一起使用吗?
-
我需要多个存储选择吗?我需要分层性能存储吗?
虽然这不是所有可能问题的最终列表,但上面的列表有望帮助缩小可能的存储选择列表。
各种各样的用例要求决定了存储后端的性质。此类要求的示例如下:
-
公共、私有或混合云(性能配置文件、共享存储、复制选项)
-
存储密集型用例,例如 HPC 和大数据云
-
Web 规模或开发云,其中存储通常是短暂的
数据安全建议:
-
我们建议对传输中和静态的数据进行加密。为此,请仔细选择磁盘、设备和软件。不要假设所有存储解决方案都包含这些功能。
-
确定您的组织的安全策略并了解您的云地理的数据主权并做出相应的计划。
如果您计划使用实时迁移,我们强烈建议您使用共享存储配置。这允许实例的操作系统和应用程序卷驻留在计算节点之外,并在实时迁移时显着提高性能。
要仅使用商用硬件部署存储,您可以使用许多开源包,如基于文件的持久性存储支持中所述。
持久的基于文件的存储支持
此开源文件级共享存储解决方案列表并不详尽。您的组织可能已经部署了您可以使用的文件级共享存储解决方案。
笔记
存储驱动程序支持
除了开源技术之外,还有许多由 OpenStack 块存储官方支持的专有解决方案。您可以在CinderSupportMatrix wiki上找到所有受支持的块存储驱动程序提供的功能矩阵。
此外,您需要决定是否要支持云中的对象存储。在计算云中提供对象存储的两个常见用例是:
-
具有图像和视频等对象的持久存储机制的用户。
-
用于 OpenStack 虚拟机映像的可扩展、可靠的数据存储。
-
供应用程序使用的 API 驱动的 S3 兼容对象存储。
选择存储硬件
存储硬件架构是通过选择具体的存储架构来确定的。通过针对关键因素、用户要求、技术考虑和操作考虑评估可能的解决方案来确定存储架构的选择。选择存储硬件时考虑以下因素:
成本
存储可能是整个系统成本的重要组成部分。对于关心供应商支持的组织,建议使用商业存储解决方案,尽管它的价格更高。如果初始资本支出需要最小化,则可以设计基于商品硬件的系统。权衡可能是更高的支持成本以及更大的不兼容和互操作性问题的风险。
表现
基于块的存储的性能通常以每秒对非连续存储位置的最大读写操作数来衡量。此测量通常适用于 SAN、硬盘驱动器和固态驱动器。虽然 IOPS 可以进行广泛测量并且不是官方基准,但供应商喜欢使用许多向量来传达性能水平。由于没有衡量 IOPS 的真正标准,因此供应商的测试结果可能会有所不同,有时甚至会大相径庭。但是,与衡量数据可以传输到连续存储位置的速度的传输速率一起,IOPS 可用于性能评估。通常,传输速率由每秒计算的字节数表示,但 IOPS 由整数测量。
要计算单个驱动器的 IOPS,您可以使用:
IOPS = 1 / (AverageLatency + AverageSeekTime) 例如:单个磁盘的平均延迟 = 2.99 毫秒或 0.00299 秒 单个磁盘的平均搜索时间 = 4.7 毫秒或 0.0047 秒 IOPS = 1/(.00299 + .0047) IOPS = 130
要计算磁盘阵列的最大 IOPS:
最大读取 IOPS:为了准确计算磁盘阵列的最大读取 IOPS,请将每个磁盘的 IOPS 乘以每个磁盘的最大读取或写入 IOPS。maxReadIOPS = nDisks * diskMaxIOPS 例如,15 个 10K 旋转磁盘将按以下方式测量:maxReadIOPS = 15 * 130 maxReadIOPS = 1950
每个阵列的最大写入 IOPS:
确定最大写入IOPS 略有不同,因为大多数管理员使用 RAID 配置磁盘复制,并且由于 RAID 控制器本身需要 IOPS,因此存在写入损失。写入惩罚的严重程度取决于所使用的 RAID 类型。
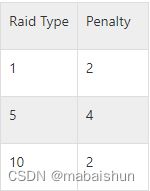
笔记
Raid 5 的惩罚最差(跨磁盘写入最多)。因此,在使用上述示例时,使用 RAID 5 的 15 磁盘阵列能够达到 1950 读取 IOPS,但是,我们需要在确定写入IOPS 时添加惩罚:
maxWriteIOPS = 1950 / 4
maxWriteIOPS = 487.5
RAID 5 阵列的写入 IOPS 仅为读取 IOPS 的 25%,而在这种情况下,RAID 1 阵列最多可产生 975 IOPS。
固态硬盘呢?DRAM固态硬盘?
在 HDD 中,数据传输是顺序的。实际的读/写头在硬盘驱动器中“寻找”一个点来执行操作。寻道时间很重要。传输速率也可能受到文件系统碎片和布局的影响。最后,硬盘的机械特性也有一定的性能限制。
在 SSD 中,数据传输不是顺序的;它是随机的,所以它更快。有一致的读取性能,因为数据的物理位置无关紧要,因为 SSD 没有读/写磁头,因此不会因磁头运动(寻道)而延迟。
笔记
小型读/写的一些基本基准:
HDD:小读取 – 175 IOP,小写入 – 280 IOP
闪存 SSD:小读取 – 1075 IOPS (6x),小写入 – 21 IOP (0.1x)
DRAM SSD:小读取 - 4091 IOPs (23x),小写入 - 4184 IOPs (14x)
可扩展性
可扩展性以及可扩展性是通用 OpenStack 云中的主要考虑因素。由于没有针对通用云的既定使用模式,因此可能难以预测实施的最终预期规模。为了适应增长和用户需求,可能有必要扩展初始部署。许多供应商已经针对这个问题实施了自己的解决方案。一些使用跨越多个设备的集群文件系统,而另一些则使用类似的技术来允许块存储扩展到超过固定容量。Ceph 是一种提供块存储的分布式存储解决方案,旨在解决这个规模问题,并且在域、集群或其他设备驱动模型的规模问题上没有相同的限制。
可扩展性
可扩展性是具有通用 OpenStack 云的存储解决方案的主要架构因素。扩展至 50 PB 的存储解决方案被认为比仅扩展至 10 PB 的解决方案更具可扩展性。此计量表与可扩展性有关,可扩展性是解决方案在扩展时的性能度量。
实现块存储
使用高级 RAID 控制器和高性能磁盘配置块存储资源节点,以提供硬件级别的容错。
我们建议为需要块存储设备额外性能的应用程序部署高性能存储解决方案,例如 SSD 驱动器或闪存存储系统。
在对块存储有大量需求的环境中,我们建议使用多个存储池。在这种情况下,每个设备池应该在该池中的所有硬件节点上具有相似的硬件设计和磁盘配置。这允许设计为应用程序提供对各种块存储池的访问,每个块存储池都有自己的冗余、可用性和性能特征。在部署多个存储池时,考虑对负责跨资源节点配置存储的块存储调度程序的影响也很重要。理想情况下,确保应用程序可以在多个区域调度卷,每个区域都有自己的网络、电源和冷却基础设施。
除了块存储资源节点之外,重要的是设计 API 的高可用性和冗余性,以及负责供应和提供对存储的访问的相关服务。我们建议设计一层硬件或软件负载均衡器,以实现相应的 REST API 服务的高可用性,以提供不间断的服务。在某些情况下,可能还需要部署额外的负载平衡层,以提供对负责服务和存储块存储卷状态的后端数据库服务的访问。必须使用高可用的数据库集群来存储块存储元数据。
在对块存储有大量需求的云中,网络架构应考虑实例利用可用存储资源所需的东西向带宽量。选定的网络设备应支持巨型帧以传输大块数据,并利用专用网络提供实例和块存储之间的连接。
实现对象存储
虽然一致性和分区容错性都是对象存储服务的固有特性,但设计整体存储架构以确保实现的系统满足这些目标非常重要。OpenStack 对象存储服务将特定数量的数据副本作为对象放置在资源节点上。副本分布在整个集群中,基于也存储在集群中每个节点上的一致哈希环。
在设计集群时,您必须考虑持久性和可用性,这取决于数据的分布和位置,而不是硬件的可靠性。
考虑副本数的默认值,即 3。这意味着在一个对象被标记为已写入之前,至少存在两个副本以防单个服务器无法写入,第三个副本可能会在写入操作最初返回时存在,也可能不存在。更改此数字会增加数据的稳健性,但会减少可用的存储量。查看服务器的位置。考虑将它们广泛分布在您的数据中心的网络和电源故障区域中。区域是机架、服务器还是磁盘?
考虑对象存储网络的这些主要流量:
-
在对象、容器和 帐户服务器之间
-
服务器和代理之间
-
在代理和您的用户之间
对象存储在托管数据的服务器之间频繁通信。即使是小型集群也会产生每秒兆字节的流量。
考虑一下整个服务器出现故障并且需要“立即”传输 24 TB 数据以保持三个副本的情况——这会给网络带来很大的负载。
另一个考虑因素是当上传新文件时,代理服务器必须写出与副本一样多的流,从而增加网络流量。对于三副本集群,10 Gbps 输入意味着 30 Gbps 输出。将此与先前的高带宽带宽私有与公共网络建议的复制要求相结合,导致建议您的私有网络的带宽明显高于公共网络所需的带宽。OpenStack 对象存储在内部与未加密、未经身份验证的 rsync 进行通信以提高性能,因此需要专用网络。
带宽的剩余点是面向公众的部分。该 swift-proxy服务是无状态的,这意味着您可以轻松添加更多内容并使用 HTTP 负载平衡方法在它们之间共享带宽和可用性。更多代理意味着更多带宽。
您应该考虑设计具有足够数量的区域的对象存储系统,以便为定义的副本数量提供仲裁。例如,在 swift 集群中配置了三个副本,建议在对象存储集群中配置的区域数量为 5 个。虽然可以部署具有较少区域的解决方案,但这样做的隐含风险是某些数据可能不可用,并且对存储在集群中的某些对象的 API 请求可能会失败。因此,请确保正确考虑对象存储集群中的区域数量。
每个对象存储区域都应在其自己的可用区域内自包含。每个可用区都应该能够独立访问网络、电源和冷却基础设施,以确保不间断地访问数据。此外,提供对存储在对象节点上的数据的访问的对象存储代理服务器池应该为每个可用区提供服务。每个区域中的对象代理应利用本地读写亲和性,以便本地存储资源尽可能方便地访问对象。我们建议部署上游负载平衡以确保代理服务分布在多个区域中,并且在某些情况下,可能需要使用第三方解决方案来帮助服务的地理分布。
对象存储集群中的区域是一个逻辑分区。以下任何一项都可能代表一个区域:
-
单个节点内的磁盘
-
每个节点一个区域
-
每个节点集合的区域
-
多个机架
-
多个数据中心
选择正确的区域设计对于允许对象存储集群扩展同时提供可用和冗余的存储系统至关重要。可能需要配置对副本、保留和其他可能严重影响特定区域中的存储设计的因素有不同要求的存储策略。
规划和扩展存储容量
随着时间的推移运行云的一个重要考虑因素是预测增长和利用率趋势,以便规划短期和长期的资本支出。收集计算、网络和存储的利用率计量表,以及这些计量表的历史记录。虽然保护主要的主力租户会导致资源利用率的快速跳跃,但也需要仔细监控通过正常使用而采用云服务的平均速度。
扩展块存储
您可以升级块存储池以增加存储容量,而不会中断整个块存储服务。通过安装和配置适当的硬件和软件将节点添加到池中,然后允许该节点通过消息总线向适当的存储池报告。块存储节点通常向调度程序服务报告其可用性。这样一来,在节点上线可用后,租户可以立即使用这些存储资源。
在某些情况下,对块存储的需求可能会耗尽可用的网络带宽。因此,设计为块存储资源提供服务的网络基础架构,以便您可以轻松地增加容量和带宽。这通常涉及使用动态路由协议或高级网络解决方案来轻松增加下游设备的容量。前端和后端存储网络设计都应包含快速轻松地增加容量和带宽的能力。
笔记
从一开始就应该进行充分的监控和数据收集,以便及时做出有关容量、输入/输出指标 (IOPS) 或存储相关带宽的决策。
扩展对象存储
向对象存储集群添加后端存储容量需要仔细规划和深思熟虑。在设计阶段,确定对象存储服务所需的最大分区功率很重要,这决定了可以存在的最大分区数。对象存储将数据分布在所有可用存储中,但一个分区不能跨越多个磁盘,因此最大分区数只能与磁盘数一样多。
例如,以单个磁盘启动且分区功率为 3 的系统可以有 8 (2^3) 个分区。添加第二个磁盘意味着每个磁盘有 4 个分区。每个分区一个磁盘的限制意味着该系统永远不能拥有超过 8 个磁盘,从而限制了它的可扩展性。但是,以单个磁盘启动且分区功率为 10 的系统最多可以拥有 1024 (2^10) 个磁盘。
当您向系统添加后端存储容量时,分区映射会在存储节点之间重新分配数据。在某些情况下,这涉及复制非常大的数据集。在这些情况下,我们建议使用不与租户对数据的访问权发生冲突的后端复制链接。
随着越来越多的租户开始访问集群内的数据并且他们的数据集不断增长,有必要增加前端带宽来服务数据访问请求。向对象存储集群添加前端带宽需要仔细规划和设计租户用来访问数据的对象存储代理,以及支持轻松扩展代理层的高可用性解决方案。我们建议设计一个前端负载平衡层,租户和消费者使用它来访问存储在集群中的数据。该负载平衡层可以分布在区域、区域甚至地理边界上,这也可能要求设计包含地理位置解决方案。
在某些情况下,您必须为代理服务器和存储节点之间的网络资源服务请求添加带宽和容量。出于这个原因,用于访问存储节点和代理服务器的网络架构应该使用可扩展的设计。
冗余
当 swift 变得更加冗余时,一种方法是添加额外的代理服务器和负载平衡。HAProxy 是提供负载均衡和高可用性的一种方法,通常与 keepalived 或 pacemaker 结合使用,以确保 HAProxy 服务保持稳定的 VIP。示例 HAProxy 配置可以在OpenStack HA 指南中找到。.
复制
对象存储中的副本独立运行,客户端只需要大多数节点响应请求即可认为操作成功。因此,像网络分区这样的瞬态故障会很快导致副本分叉。修复 这些差异最终通过异步的点对点复制器进程来协调。复制器进程遍历它们的本地文件系统,同时以平衡物理磁盘负载的方式执行操作。
复制使用推送模型,记录和文件通常只从本地复制到远程副本。这很重要,因为节点上的数据可能不属于那里(如切换和环更改的情况),并且复制器无法知道它应该拉入集群中其他地方的数据。这是任何节点的职责包含数据以确保数据到达它所属的位置。副本放置由环处理。
系统中每条已删除的记录或文件都由墓碑标记,以便删除可以与创建一起复制。复制过程在称为一致性窗口的时间段后清理墓碑。一致性窗口包括复制持续时间和瞬时故障可以从集群中删除节点的时间长度。Tombstone 清理必须与复制绑定以达到副本收敛。
如果复制器检测到远程驱动器发生故障,则复制器使用 get_more_nodes环的接口来选择要与之同步的备用节点。面对磁盘故障,复制器可以保持所需的复制级别,尽管某些副本可能不在立即可用的位置。
笔记
当发生其他故障(例如整个节点故障)时,复制器不会维持所需的复制级别,因为大多数故障都是暂时的。
复制是一个积极开发的领域,实现细节可能会随着时间而改变。
复制器有两大类:复制帐户和容器的数据库复制器和复制对象数据的对象复制器。
Network 架构
网络概念
云环境从根本上改变了提供和使用网络的方式。在做出架构决策时,必须了解以下概念和决策。
网络区域
云网络分为多个支持网络流量要求的逻辑区域。我们建议至少定义四个不同的网络区域。
底垫
底层区域被定义为连接存储、计算和控制平台的物理网络交换基础设施。有大量潜在的底层选项可用。
叠加
覆盖区域定义为云组件之间的任何 L3 连接,可以采用 SDN 解决方案的形式,例如中子覆盖解决方案或 3rd Party SDN 解决方案。
边缘
边缘区域是网络流量从云覆盖或 SDN 网络过渡到传统网络环境的地方。
外部
外部网络被定义为提供对云资源和工作负载的访问所需的配置和组件,外部网络被定义为云边缘网关之外的所有组件。
流量
云基础设施中有两种主要类型的流量,网络技术的选择受预期负载的影响。
东/西 - 云中工作负载之间的内部流量以及计算节点和存储节点之间的流量属于东/西类别。通常,这是最重的流量,并且由于需要满足存储访问需求,因此需要满足最少的跃点和低延迟。
北/南 - 工作负载与所有外部网络(包括客户端和远程服务)之间的流量。此流量高度依赖于云中的工作负载和所提供的网络服务类型。
层网络选择
在决定使用第 2 层网络架构还是第 3 层网络架构时,需要考虑几个因素。
使用二层网络的好处
选择基于第 2 层协议设计的网络而不是基于第 3 层协议设计的网络有几个原因。尽管使用网桥来执行路由器的网络角色存在困难,但许多供应商、客户和服务提供商选择在其网络的尽可能多的部分中使用以太网。选择第 2 层设计的好处是:
-
以太网帧包含联网的所有要素。这些包括但不限于全球唯一源地址、全球唯一目标地址和错误控制。
-
以太网帧可以携带任何类型的数据包。第 2 层的网络独立于第 3 层协议。
-
向以太网帧添加更多层只会减慢网络进程。这称为节点处理延迟。
-
您可以像 IP 网络一样轻松地将附加网络功能(例如服务等级 (CoS) 或多播)添加到以太网。
-
VLAN 是一种用于隔离网络的简单机制。
大多数信息在以太网帧内开始和结束。今天,这适用于数据、语音和视频。这个概念是,如果信息从源到目的地的传输采用以太网帧的形式,那么网络将更多地受益于以太网的优势。
虽然它不能替代 IP 网络,但第 2 层网络可以成为 IP 网络的强大辅助。
使用第 2 层以太网比使用第 3 层 IP 网络具有额外的好处:
-
速度
-
减少 IP 层次结构的开销。
-
随着系统的移动,无需跟踪地址配置。
虽然第 2 层协议的简单性可能在拥有数百台物理机器的数据中心中运行良好,但云数据中心需要跟踪所有虚拟机地址和网络的额外负担。在这些数据中心中,一个物理节点支持 30-40 个实例的情况并不少见。
重要的
帧级别的网络没有说明数据包级别 IP 地址的存在与否。LAN 交换机网络上的几乎所有端口、链路和设备仍然具有 IP 地址,所有源主机和目标主机也是如此。持续需要 IP 寻址的原因有很多。最大的一个是需要管理网络。大多数管理应用程序通常看不到没有 IP 地址的设备或链接。包括用于诊断的远程访问、配置和软件的文件传输以及类似应用程序在内的实用程序不能在没有 IP 地址和 MAC 地址的情况下运行。
第 2 层架构限制
第 2 层网络架构有一些限制,在传统数据中心之外使用时会变得很明显。
-
VLAN 数量限制为 4096。
-
存储在交换表中的 MAC 数量是有限的。
-
您必须满足维护一组第 4 层设备来处理流量控制的需要。
-
MLAG 通常用于交换机冗余,是一种专有解决方案,不会扩展到超过两个设备并强制供应商锁定。
-
对没有 IP 地址和 ICMP 的网络进行故障排除可能很困难。
-
在大型第 2 层网络上配置 ARP 可能很复杂。
-
所有网络设备都需要了解所有 MAC,甚至是实例 MAC,因此随着实例的启动和停止,MAC 表和网络状态会不断变化。
-
如果您没有正确设置 ARP 表超时,将 MAC(实例迁移)迁移到不同的物理位置是一个潜在的问题。
重要的是要知道第 2 层的网络管理工具集非常有限。很难控制流量,因为它没有管理网络或调整流量的机制。网络故障排除也很麻烦,部分原因是网络设备没有 IP 地址。因此,没有合理的方法来检查网络延迟。
在第 2 层网络中,所有设备都知道所有 MAC,甚至是属于实例的 MAC。每当实例启动或停止时,骨干网中的网络状态信息都会发生变化。正因为如此,主干交换机上的 MAC 表中存在太多的变动。
此外,在大型第 2 层网络上,配置 ARP 学习可能很复杂。交换机上的 MAC 地址计时器设置非常重要,如果设置不正确,可能会导致严重的性能问题。因此,当将 MAC 迁移到不同的物理位置以支持实例迁移时,可能会出现问题。例如,Cisco 默认 MAC 地址计时器非常长。因此,交换机中维护的网络信息可能与实例的新位置不同步。
使用第 3 层网络的好处
在第 3 层网络中,路由将实例 MAC 和 IP 地址带出网络核心,从而减少状态流失。唯一会发生路由状态变化的情况是架顶式 (ToR) 交换机故障或主干本身的链路故障。使用第 3 层架构的其他优点包括:
-
第 3 层网络提供与 Internet 相同级别的弹性和可扩展性。
-
使用路由指标控制流量很简单。
-
您可以将第 3 层配置为使用边界网关协议 (BGP) 联盟以实现可扩展性。这样,核心路由器的状态与机架数量成正比,而不是与服务器或实例的数量成正比。
-
有各种经过良好测试的工具,例如用于监视和管理流量的 Internet 控制消息协议 (ICMP)。
-
第 3 层架构支持使用服务质量 (QoS)来管理网络性能。
第 3 层架构限制
第 3 层网络的主要限制是没有与第 2 层网络中的 VLAN 相媲美的内置隔离机制。此外,IP 地址的分层特性意味着实例与其物理主机位于同一子网中,因此难以迁移出子网。由于这些原因,网络虚拟化需要在终端主机上使用 IP 封装和软件。这是为了隔离和分离虚拟层中的寻址与物理层中的寻址。第 3 层网络的其他潜在缺点包括需要设计 IP 寻址方案而不是依靠交换机来自动跟踪 MAC 地址,以及在交换机中配置内部网关路由协议。
网络服务(neutron)
OpenStack Networking (neutron) 是 OpenStack 的组件,它提供网络服务 API 和实现软件定义网络 (SDN) 解决方案的参考架构。
网络服务为租户提供对虚拟网络资源创建的完全控制。这通常以隧道协议的形式实现,该协议在现有网络基础设施上建立封装的通信路径,以分割租户流量。此方法因具体实现而异,但一些较常用的方法包括 GRE 隧道、VXLAN 封装和 VLAN 标记。
设计 OpenStack 网络
OpenStack 网络具有复杂要求的原因有很多。一个主要因素是许多组件在系统堆栈的不同级别进行交互。数据流也很复杂。
OpenStack 云中的数据通过网络在实例之间移动(称为东西向流量),以及进出系统(称为南北向流量)。物理服务器节点具有独立于实例网络要求的网络要求,并且必须隔离以考虑可扩展性。我们建议出于安全目的分离网络并通过流量整形调整性能。
在规划和设计 OpenStack 网络时,您必须考虑许多重要的技术和业务需求:
-
避免硬件或软件供应商锁定。设计不应依赖供应商网络路由器或交换机的特定功能。
-
大规模扩展生态系统以支持数百万最终用户。
-
支持不确定的各种平台和应用程序。
-
设计具有成本效益的运营,以利用大规模。
-
确保云生态系统没有单点故障。
-
满足客户 SLA 要求的高可用性架构。
-
容忍机架级故障。
-
最大限度地提高构建未来生产环境的灵活性。
考虑到这些要求,我们建议如下:
-
设计第 3 层网络架构而不是第 2 层网络架构。
-
设计一个密集的多路径网络核心以支持多向扩展和灵活性。
-
使用分层寻址,因为它是扩展网络生态系统的唯一可行选择。
-
使用虚拟网络将实例服务网络流量与管理和内部网络流量隔离开来。
-
使用封装技术隔离虚拟网络。
-
使用流量整形进行性能调整。
-
使用外部边界网关协议 (eBGP) 连接到 Internet 上行链路。
-
使用内部边界网关协议 (iBGP) 扁平化第 3 层网格上的内部流量。
-
确定块存储网络的最有效配置。
其他网络设计注意事项
在设计以网络为中心的 OpenStack 云时,还有其他几个考虑因素。
冗余网络
您应该进行高可用性风险分析以确定是否使用冗余交换机,例如架顶式 (ToR) 交换机。在大多数情况下,使用单个交换机和少量备用交换机来替换故障单元比为整个数据中心配备冗余交换机要经济得多。由于网络和计算资源易于配置且充足,应用程序应容忍机架级中断而不影响正常操作。
研究表明,交换机的平均故障间隔时间 (MTBF) 在 100,000 到 200,000 小时之间。这个数字取决于数据中心交换机的环境温度。如果适当地冷却和维护,这意味着故障前的 11 到 22 年。即使在数据中心通风不良和环境温度高的最坏情况下,MTBF 仍为 2-3 年。
提供 IPv6 支持
当今最重要的网络主题之一是 IPv4 地址的耗尽。截至 2015 年底,ICANN 宣布最终的 IPv4 地址块已完全分配。正因为如此,IPv6 协议已成为以网络为中心的应用的未来。IPv6 显着增加了地址空间,解决了 IPv4 协议中长期存在的问题,并将成为未来以网络为中心的应用程序的必要条件。
OpenStack Networking 在配置后支持 IPv6。要启用 IPv6,请在 Networking 中创建 IPv6 子网,并在创建安全组时使用 IPv6 前缀。
支持非对称链接
在设计网络架构时,应用程序的流量模式会严重影响总带宽的分配以及用于发送和接收流量的链接数量。为客户提供文件存储的应用程序分配带宽和链接以支持传入流量;而视频流应用程序分配带宽和链接以支持传出流量。
优化网络性能
在设计支持以网络为中心的应用程序的环境时,分析应用程序对延迟和抖动的容限非常重要。某些应用程序,例如 VoIP,对延迟和抖动的容忍度较低。当延迟和抖动成为问题时,某些应用程序可能需要调整 QoS 参数和网络设备队列,以确保它们立即排队等待传输或保证最小带宽。由于 OpenStack 目前不支持这些功能,请仔细考虑您选择的网络插件。
服务的位置也可能影响应用程序或消费者体验。如果一个应用程序为不同的用户提供不同的内容,它必须正确地直接连接到那些特定的位置。在适当的情况下,对这些情况使用多站点安装。
您可以通过两种不同的方式实现联网。传统网络 (nova-network) 提供了一个带有单个广播域的平面 DHCP 网络。此实现不支持租户隔离网络或高级插件,但它是目前使用多主机配置实现分布式第 3 层 (L3) 代理的唯一方法。网络服务(neutron)是官方的网络实现,提供了一个支持多种网络方法的可插拔架构。其中一些包括仅第 2 层的提供商网络模型、外部设备插件,甚至是 OpenFlow 控制器。
大规模网络成为一系列边界问题。确定第 2 层域必须有多大取决于域内的节点数量和实例之间传递的广播流量。打破第 2 层边界可能需要实施覆盖网络和隧道。这个决定是在需要更小的开销或需要更小的域之间进行平衡。
在选择网络设备时,请注意,根据最大端口密度做出决定通常会带来一个缺点。聚合交换机和路由器并没有跟上 ToR 交换机的步伐,可能会导致南北流量出现瓶颈。因此,大量的下游网络利用率可能会影响上游网络设备,从而影响对云的服务。由于 OpenStack 目前没有提供流量整形或速率限制的机制,因此有必要在网络硬件级别实现这些功能。
使用可调网络组件
在设计包括 MTU 和 QoS 的网络密集型工作负载时,请考虑与 OpenStack 架构设计相关的可配置网络组件。由于传输大数据块,某些工作负载需要比正常情况更大的 MTU。在为视频流或存储复制等应用程序提供网络服务时,我们建议您尽可能配置 OpenStack 硬件节点和支持巨型帧的网络设备。这允许更好地使用可用带宽。跨数据包遍历的完整路径配置巨型帧。如果一个网络组件无法处理巨型帧,则整个路径将恢复为默认 MTU。
服务质量 (QoS)对网络密集型工作负载也有很大影响,因为它为由于网络性能差的影响而具有更高优先级的数据包提供即时服务。在 IP 语音 (VoIP) 等应用中,差异化服务代码点几乎是正确操作的要求。您还可以对混合工作负载使用相反方向的 QoS,以防止低优先级但高带宽的应用程序(例如备份服务、视频会议或文件共享)阻塞其他工作负载正常运行所需的带宽。可以将文件存储流量标记为较低的类别,例如尽力而为或清道夫,以允许较高优先级的流量通过。
选择网络硬件
网络架构决定了将使用哪种网络硬件。网络软件由选择的网络硬件决定。
还有更微妙的设计影响需要考虑。某些网络硬件(和网络软件)的选择会影响可以使用的管理工具。这也有例外;支持一系列网络硬件的开放网络软件的兴起意味着在某些情况下,网络硬件和网络软件之间的关系没有那么严格定义。
选择网络硬件的一些关键考虑因素包括:
端口数
该设计将需要具有所需端口数的网络硬件。
端口密度
网络设计将受到提供所需端口数所需的物理空间的影响。更高的端口密度是首选,因为它为计算或存储组件留出了更多的机架空间。这也可能导致对故障域和功率密度的考虑。更高密度的交换机更昂贵,因此不要过度设计网络很重要。
端口速度
网络硬件必须支持建议的网络速度,例如:1 GbE、10 GbE 或 40 GbE(甚至 100 GbE)。
冗余
用户对高可用性和成本考虑的要求会影响网络硬件冗余的水平。可以通过添加冗余电源或配对交换机来实现网络冗余。
笔记
硬件必须支持网络冗余。
电源要求
确保物理数据中心为选定的网络硬件提供必要的电力。
笔记
这不是架顶式 (ToR) 交换机的问题。这可能是叶和脊结构中的脊交换机或行尾 (EoR) 交换机的问题。
协议支持
通过使用 RDMA、SRP、iSER 和 SCST 等专用网络技术,可以从单个存储系统中获得更多性能。使用这些技术的细节超出了本书的范围。
支持 OpenStack 云的网络硬件没有单一的最佳实践架构。将对网络硬件的选择产生重大影响的一些关键因素包括:
连接性
OpenStack 云中的所有节点都需要网络连接。在某些情况下,节点需要访问多个网段。设计必须包含足够的网络容量和带宽,以确保云中的所有通信,包括南北向和东西向流量,都有足够的可用资源。
可扩展性
网络设计应包含易于扩展的物理和逻辑网络设计。网络硬件应提供硬件节点所需的适当类型的接口和速度。
可用性
为确保对云中节点的访问不中断,我们建议网络架构识别任何单点故障并提供一定程度的冗余或容错。网络基础设施通常涉及使用网络协议(例如 LACP、VRRP 或其他协议)来实现高度可用的网络连接。考虑网络对 API 可用性的影响也很重要。我们建议在网络架构中设计负载平衡解决方案,以确保云中的 API 和潜在的其他服务具有高可用性。
选择网络软件
OpenStack Networking (neutron) 为实例提供了广泛的网络服务。在管理 OpenStack 组件时,还有许多额外的网络软件包非常有用。一些例子包括:
-
提供负载平衡的软件
-
网络冗余协议
-
路由守护进程。
额外的网络服务
OpenStack 与任何网络应用程序一样,需要考虑许多标准服务,例如 NTP 和 DNS。
NTP
时间同步是确保 OpenStack 组件持续运行的关键要素。确保所有组件都有正确的时间对于避免实例调度、对象存储中的对象复制以及匹配日志时间戳以进行调试时出现错误是必要的。
所有运行 OpenStack 组件的服务器都应该能够访问适当的 NTP 服务器。您可以决定在本地设置一个或使用网络时间协议项目提供的公共池。
域名解析
Designate 是 OpenStack 的多租户 DNSaaS 服务。它提供了一个集成了 keystone 身份验证的 REST API。它可以配置为根据新星和中子动作自动生成记录。Designate 支持多种 DNS 服务器,包括 Bind9 和 PowerDNS。
DNS 服务为 OpenStack 云提供 DNS 区域和 RecordSet 管理。DNS 服务包括一个 REST API、一个命令行客户端和一个 Horizon Dashboard 插件。
有关详细信息,请参阅指定项目 网页。
笔记
安装时,指定服务不为 OpenStack 基础架构提供 DNS 服务。我们建议在安装 OpenStack 时与您的服务提供商合作,以便正确命名您的服务器和其他基础设施硬件。
DHCP
在 OpenStack 中创建网络时,OpenStack neutron 会部署各种代理。这些代理之一是 DHCP 代理。此 DHCP 代理使用 linux 二进制文件 dnsmasq 作为 DHCP 的传递代理。此代理管理为每个项目子网生成的网络命名空间,以充当 DHCP 服务器。dnsmasq 进程能够为网络上运行的所有虚拟机分配 IP 地址。当通过 OpenStack 创建网络并为该网络启用 DHCP 代理时,默认情况下会启用 DHCP 服务。
LBaaS
OpenStack neutron 能够在指定实例之间分配传入请求。使用中子网络和 OVS,可以创建负载平衡即服务 (LBaaS)。工作负载的负载平衡用于在指定实例之间平均分配传入的应用程序请求。此操作可确保在定义的实例之间可预测地共享工作负载,并允许更有效地使用底层资源。OpenStack LBaaS 可以通过以下方式分配负载:
-
Round robin - 多个已定义实例之间的均匀轮换。
-
源 IP - 来自特定 IP 的请求始终定向到同一实例。
-
最少连接 - 向活动连接最少的实例发送请求。
Identity 架构
OpenStack 设计为可大规模水平扩展,允许所有服务广泛分布。但是,为了简化本指南,我们决定使用云控制器的概念来讨论更中心化的服务。云控制器是概念上的简化。在现实世界中,您为云控制器设计了一个架构,以实现高可用性,这样如果任何节点发生故障,另一个节点可以接管所需的任务。实际上,云控制器任务分布在多个节点上。
云控制器为 OpenStack 部署提供中央管理系统。通常,云控制器管理身份验证并通过消息队列向所有系统发送消息。
对于许多部署,云控制器是单个节点。但是,要获得高可用性,您必须考虑一些因素,我们将在本章中介绍这些因素。
云控制器管理云的以下服务:
数据库
跟踪有关用户和实例的当前信息,例如,在数据库中,通常每个服务管理一个数据库实例
消息队列服务
根据队列代理接收和发送服务的所有高级消息队列协议 (AMQP)消息
指挥服务
代理对数据库的请求
身份管理的认证和授权
指示哪些用户可以对某些云资源执行哪些操作;配额管理分散在服务之间,但是身份验证
Image管理服务
存储和提供带有元数据的图像,以便在云中启动
调度服务
指示首先使用哪些资源;例如,根据算法分散启动实例的位置
用户仪表板
提供基于 Web 的前端供用户使用 OpenStack 云服务
API 端点
提供每个服务的 REST API 访问,其中 API 端点目录由身份服务管理
在我们的示例中,云控制器具有nova-* 代表云全局状态的组件集合;与身份验证等服务对话;在数据库中维护有关云的信息;通过队列与所有计算节点和存储 工作者通信;并提供 API 访问。在指定的云控制器上运行的每个服务都可以分解为单独的节点,以实现可扩展性或可用性。
作为另一个示例,您可以将成对的服务器用于集体云控制器(一个活动,一个备用),用于提供一组给定相关服务的冗余节点,例如:
-
API 请求的前端 Web、用于选择在哪个计算节点上启动实例的调度程序、身份服务和仪表板
-
数据库和消息队列服务器(如 MySQL、RabbitMQ)
-
图像管理的图像服务
既然您看到了用于控制您的云的无数设计,请阅读更多关于帮助您做出设计决策的进一步考虑因素。
硬件注意事项
云控制器的硬件可以与计算节点相同,但您可能希望根据您运行的云的大小和类型进一步指定。
还可以将虚拟机用于云控制器管理的所有或部分服务,例如消息队列。在本指南中,我们假设所有服务都直接在云控制器上运行。
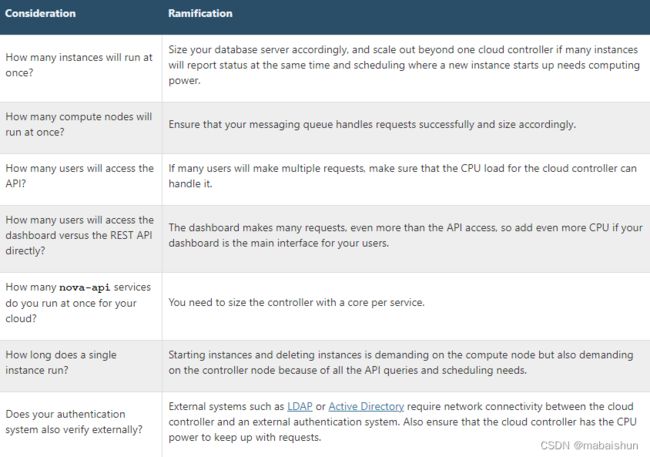
Table. Cloud controller hardware sizing considerations注意事项包含在为云控制器设计选型硬件时要查看的常见注意事项。
Table. Cloud controller hardware sizing considerations
服务分离
虽然我们的示例在一个位置包含所有中央服务,但将服务分隔到不同的物理服务器上是可能的,而且通常也是一个好主意。Table. Deployment scenarios是我们看到的部署方案及其理由的列表。
Table. Deployment scenarios

一个经常出现的选择是是否虚拟化。某些服务(例如nova-compute和服务器)不应虚拟化。然而,控制服务器通常可以愉快地虚拟化——性能损失通常可以通过简单地运行更多服务来抵消。swift-proxyswift-object
数据库
OpenStack Compute 使用 SQL 数据库来存储和检索状态信息。MySQL 是 OpenStack 社区中流行的数据库选择。
数据库丢失会导致错误。因此,我们建议您对数据库进行集群以使其具有容错性。配置和维护数据库集群是在 OpenStack 之外完成的,由您选择在云环境中使用的数据库软件决定。MySQL/Galera 是基于 MySQL 的数据库的流行选项。
消息队列
大多数 OpenStack 服务使用消息队列相互通信. 例如,Compute 通过消息队列与块存储服务和网络服务进行通信。此外,您可以选择为任何服务启用通知。RabbitMQ、Qpid 和 Zeromq 都是消息队列服务的流行选择。通常,如果消息队列出现故障或无法访问,集群会停止并最终处于只读状态,信息会停留在发送最后一条消息的位置。因此,我们建议您对消息队列进行集群。请注意,集群消息队列可能是许多 OpenStack 部署的痛点。虽然 RabbitMQ 具有原生集群支持,但在大规模运行时出现了问题报告。虽然其他队列解决方案可用,例如 Zeromq 和 Qpid,但 Zeromq 不提供有状态队列。Qpid 是 Red Hat 及其衍生产品的首选消息传递系统。Qpid 没有本机集群功能,需要补充服务,例如 Pacemaker 或 Corsync。对于您的消息队列,您需要确定您可以接受的数据丢失级别以及是否使用 OpenStack 项目在发生故障时重试多个 MQ 主机的功能,例如使用 Compute 的功能。
指挥服务
在以前的 OpenStack 版本中,所有nova-compute服务都需要直接访问托管在云控制器上的数据库。这是有问题的,原因有两个:安全性和性能。在安全性方面,如果计算节点受到威胁,攻击者本身就可以访问数据库。关于性能, nova-compute对数据库的调用是单线程和阻塞的。这会造成性能瓶颈,因为数据库请求是串行而不是并行完成的。
指挥服务通过充当nova-compute服务的代理来解决这两个问题。现在,它不再nova-compute 直接访问数据库,而是联系nova-conductor 服务并代表nova-conductor访问数据库 nova-compute。由于nova-compute不再直接访问数据库,安全问题得到解决。此外, nova-conductor它是一项非阻塞服务,因此来自所有计算节点的请求都是并行完成的。
笔记
如果您nova-network在云环境中使用多主机网络,nova-compute仍然需要直接访问数据库。
该nova-conductor服务是水平可扩展的。要实现 nova-conductor高可用性和容错,只需nova-conductor在同一台服务器上或跨多台服务器上启动更多进程实例。
应用程序编程接口 (API)
所有公共访问,无论是直接访问、通过命令行客户端还是通过基于 Web 的仪表板,都使用 API 服务。在OpenStack 云的开发资源中找到 API 参考。
您必须选择是要支持 Amazon EC2 兼容性 API,还是仅支持 OpenStack API。您在运行这两种 API 时可能会遇到的一个问题是在引用图像和实例时体验不一致。
例如,EC2 API 使用包含十六进制的 ID 引用实例,而 OpenStack API 使用名称和数字。同样,EC2 API 倾向于依赖 DNS 别名来联系虚拟机,而 OpenStack 通常会列出 IP 地址。
如果 OpenStack 没有以正确的方式设置,很容易出现用户由于 DNS 别名不正确而无法联系他们的实例的情况。尽管如此,EC2 兼容性可以帮助用户迁移到您的云。
与数据库和消息队列一样,拥有多个API 服务器 是一件好事。传统的 HTTP 负载平衡技术可用于实现高可用性nova-api服务。
扩展
API 规范定义了 OpenStack API 的核心操作、功能和媒体类型。客户端始终可以依赖此核心 API 的可用性,并且始终需要实施者对其进行全面支持。要求严格遵守核心 API 允许客户端在与同一 API 的多个实现交互时依赖最低级别的功能。
OpenStack Compute API 是可扩展的。扩展为 API 添加了超出核心中定义的功能。新特性、MIME 类型、动作、状态、标头、参数和资源的引入都可以通过对核心 API 的扩展来完成。这允许在 API 中引入新功能而无需更改版本,并允许引入特定于供应商的利基功能。
调度
调度服务负责确定应在其中创建虚拟机或块存储卷的计算或存储节点。调度服务从消息队列接收这些资源的创建请求,然后开始确定资源应该驻留的适当节点的过程。这个过程是通过对可用的节点集合应用一系列用户可配置的过滤器来完成的。
当前有两种调度程序:nova-scheduler用于虚拟机和cinder-scheduler用于块存储卷。两个调度程序都能够水平扩展,因此为了高可用性目的,或者对于非常大或高调度频率的安装,您应该考虑运行每个调度程序的多个实例。调度程序都监听共享消息队列,因此不需要特殊的负载平衡。
图片
OpenStack Image 服务由两部分组成:glance-api和 glance-registry. 前者负责图像的传递;计算节点使用它从后端下载图像。后者维护与虚拟机映像相关的元数据信息,并且需要一个数据库。
该glance-api部分是一个抽象层,允许选择后端。目前,它支持:
OpenStack 对象存储
允许您将图像存储为对象。
文件系统
使用任何传统文件系统将图像存储为文件。
S3
允许您从 Amazon S3 获取图像。
HTTP
允许您从 Web 服务器获取图像。您无法使用此模式写入图像。
如果您有 OpenStack 对象存储服务,我们建议将其用作存储图像的可扩展位置。您还可以使用具有足够性能的文件系统或 Amazon S3 — 除非您不需要通过 OpenStack 上传新图像的能力。
仪表板
OpenStack 仪表板 (horizon) 为各种 OpenStack 组件提供基于 Web 的用户界面。仪表板包括一个供用户管理其虚拟基础架构的最终用户区域和一个供云操作员管理整个 OpenStack 环境的管理区域。
仪表板被实现为通常在Apache httpd中运行的 Python Web 应用程序。因此,您可以将它与任何其他 Web 应用程序一样对待,只要它可以通过网络访问 API 服务器(包括它们的管理端点)。
认证和授权
支持 OpenStack 身份验证和授权的概念源自于类似性质的易于理解和广泛使用的系统。用户拥有可用于身份验证的凭据,并且他们可以是一个或多个组(称为项目或租户,可互换)的成员。
例如,云管理员可能能够列出云中的所有实例,而用户只能查看其当前组中的实例。资源配额,例如可以使用的核心数、磁盘空间等,与一个项目相关联。
OpenStack Identity 提供身份验证决策和用户属性信息,然后其他 OpenStack 服务使用这些信息来执行授权。该策略在policy.json文件中设置。有关如何配置这些的信息,请参阅OpenStack 操作指南中的管理项目和用户。
OpenStack Identity 支持用于身份验证决策和身份存储的不同插件。这些插件的示例包括:
In-memory key-value Store(一种简化的内部存储结构)
SQL 数据库(如 MySQL 或 PostgreSQL)
Memcached(分布式内存对象缓存系统)
LDAP(例如 OpenLDAP 或 Microsoft 的 Active Directory)
许多部署使用 SQL 数据库;但是,对于那些需要集成现有身份验证基础架构的用户来说,LDAP 也是一种流行的选择。
网络注意事项
因为云控制器处理如此多不同的服务,它必须能够处理命中它的流量。例如,如果您选择在云控制器上托管 OpenStack Image 服务,云控制器应该能够支持以可接受的速度传输图像。
再举一个例子,如果您选择使用单主机网络,其中云控制器是所有实例的网络网关,那么云控制器必须支持在您的云和公共 Internet 之间传输的总流量。
我们建议您使用快速 NIC,例如 10 GB。您还可以选择使用两个 10 GB NIC 并将它们绑定在一起。虽然您可能无法获得完全绑定的 20 GB 速度,但不同的传输流使用不同的 NIC。例如,如果云控制器传输两个图像,则每个图像使用不同的 NIC 并获得完整的 10 GB 带宽。
云管理架构
复杂的云,尤其是混合云,可能需要工具来促进跨多个云的工作。
云之间的经纪人
代理软件评估不同云平台之间的相对成本。云管理平台 (CMP) 允许设计人员根据预定标准确定工作负载的正确位置。
促进跨云的编排
CMP 简化了公共、私有和混合云平台之间的应用程序工作负载迁移。
我们建议使用云编排工具来管理跨多个云平台的各种系统和应用程序组合。