Mysql 常用语句 面试复习 常用命令大全
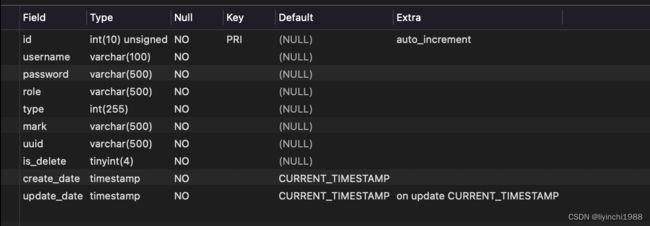
以下均以此表结构为示例
1.创建数据库
create database 数据库名查看数据库
show databases使用数据库
use 数据库名2.创建表
create table if not exists 表名(
`id` int not null unsigned auto_increment,
`name` varchar(200) not null comment "用户名",
`born` timestamp not null default current_timestamp comment "出生日期",
`created` datetime(3) not null default current_timestamp(3),
`update` timestamp null default current_timestamp on update current_timestamp
primary key('id'),
)ENGINE=innoDB default charset =utf8;(1)查看所有表
show tables(2)直接将查询结果导入或复制到新创建的表
create table 表名1 select * from 表名2;(3)新创建的表与一个存在的表的数据结构类似
create table 表名1 like 表名2;注意:它只复制表的结构和相关属性比如包括存储引擎、备注、主键、索引等,like并不复制数据。
(4)复制旧表的结构和数据,创建新表
create table 新表 as select * from 旧表
复制表不会复制主键,所以还要再执行一次添加主键命令
alter table 表名 add primary key(id)3.删除数据库、删除表
drop database 数据库名
drop table 表名4.删除表数据
DELETE FROM `user` WHERE `create_date` = '2023-03-10 07:22:22'5.修改表数据
update 表名 set 字段名=字段值,字段名=字段值,字段名=字段值
where id =16.修改表结构
(1)加字段
alter table 表名 add 字段名 字段类型
alter table user add `username` varchar(200) not null 指定新添加的字段位置,可以使用first(放在首位),after 字段名(在指定字段名之后)
alter table istester add istester7 first;
alter table istester add istester8 after id;
(2)修改字段类型
alter table 表名 modify 字段名 字段类型(3)删除表字段
alter table 表名 drop 字段名(4)需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
例如,把字段istester6 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:
ALTER TABLE 表名 MODIFY 字段名 CHAR(10);
ALTER TABLE 表名 CHANGE column_name1 column_name2 BIGINT;
ALTER TABLE 表名 CHANGE column_name1 column_name1 INT;
备注:修改表名使用rename to
# 更改存在表的名称
ALTER TABLE n RENAME m;
RENAME TABLE n TO m;7.插入表数据
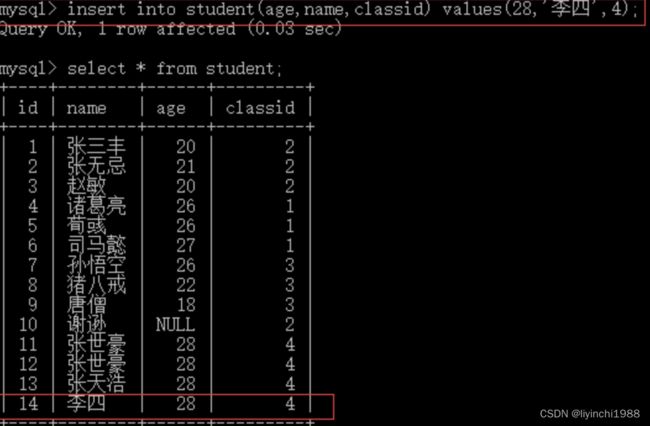
(1)使用Inset into 表名 values(值1,值2)
注意:这种简写的方式虽然非常简单,但是values后面的值必须和表中的类顺序对应,且类型要保持一致,即使表中某一个列不需要值也必须赋值为null,例如:主键id设置的是递增实际上是不用设置值的,但是使用这种方式必须赋值为null。
(2)使用Inset into 表名(字段1,字段2) values(值1,值2)
insert into user (`password`,`username`, `role`,`type`,`mark`,`uuid`,`is_delete`) values('123456789','王五五','vip',1,'备注','123hjkh123345',0)推荐这种方式:
这一次我们设置了没有给id赋任何值包括null,而且不用关心表中字段的顺序,比如下面不按照正常顺序添加,我们将password放在第一,username放在第二个也能添加成功;需要注意的是表名后面的字段名必须和后面values赋的值保持一致;实际开发中在维护和扩张方面都比方案一要好。
如果添加过主键自增(PRINARY KEY AUTO_INCREMENT)第一列在增加数据的时候,可以写为0或者null,这样添加数据可以自增
(3)以某个查询结果数据,作为插入表的数据 i
insert into 表名1 select * from 表名2
insert INTO user ( `username`,`password`, `role`,`type`,`mark`,`uuid`,`is_delete`)
select `username`,`password`, `role`,`type`,`mark`,`uuid`,`is_delete` from `user` where id= 15(4)insert ignore into 表名(字段...) values(值...)
此语句的作用是如果插入的数据已经存在那么就忽略插入的数据(也就是不改变原来的数据),如果不存在则插入新的数据。
注意:却分是否存在是通过主键来确定的。
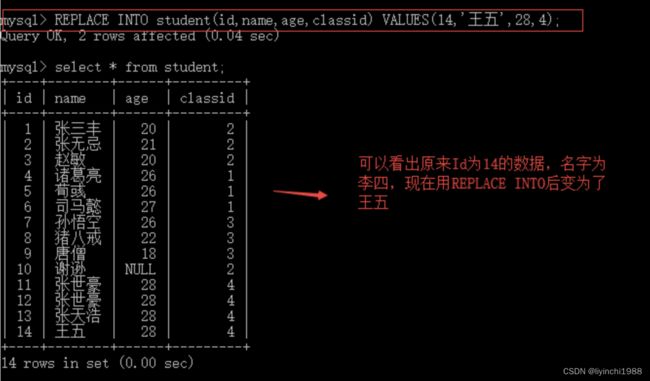
(5)replace instert into 表名(字段...) values(值...)
此语句的作用是当我们在插入一条数据时,如果此条已经存在,那么先删除原来存在的数据再添加插入的数据,如果不存在那么直接插入新的数据。
注意:却分是否存在是通过主键来确定的
(6)批量插入
使用Inset into 表名(字段1,字段2,字段3) values(值1,值2,值3),(值1,值2,值3)
insert into user (`password`,`username`, `role`,`type`,`mark`,`uuid`,`is_delete`) values('123456789','王五五','vip',1,'备注','123hjkh123345',0),('123456789','王LIULIU','vip',1,'备注','123hjkh123345',0)8.限制查询条数
(1)LIMIT 属性来设定返回的记录数N
select * from tablename limit N;(2)指定范围
从第N条到第M条的记录,其中N为开始的位置,从原始记录中从0开始计算,M为要取出的条数。
select * from tablename limit N,M;
比如:select * from 表 limit 5,2; 取得数据是从第6行到第7行。

若想查询出从第N条记录到表结束的记录来(不含N),如下其中的999,代表着一个较大的数值,可根据实际情况改变
select * from table_name limit N-1,999;
如果想查询出某表中从第三行到第五行的数据可用offset
select * from table_name limit 3 offset 2;等同于
select * from table_name limit 2,3;#从第4条数据开始取数,取1条数据,即只取第四条
SELECT * FROM 表名 LIMIT 3,1;
#从第4条数据开始取数,取1条数据,即只取第四条
SELECT * FROM 表名 LIMIT 1 OFFSET 3;
#从第4条数据开始取数,取2条数据,即取第4条,第5条
SELECT * FROM 表名 LIMIT 3,2;
#从第4条数据开始取数,取2条数据,即取第4条,第5条
SELECT * FROM 表名 LIMIT 2 OFFSET 3;limit+offset 先偏移,再取数
9.查看表结构
show create table 表名
10.查看表字段
show columns from 表名desc user11.表连接
# 内联接
SELECT * FROM m INNER JOIN n ON m.id = n.id;
# 左外联接
SELECT * FROM m LEFT JOIN n ON m.id = n.id;
# 右外联接
SELECT * FROM m RIGHT JOIN n ON m.id = n.id;
# 交叉联接
SELECT * FROM m CROSS JOIN n; # 标准写法
SELECT * FROM m, n;
# 类似全连接full join的联接用法
SELECT id,name FROM m
UNION
SELECT id,name FROM n;(1)内连接
关键字:inner join on
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集的阴影部分。
备注:通过共有的字段id连接了两个表
(2)左(外)连接
关键字:left join on / left outer join on
语句:SELECT * FROM a_table a left join b_table b ON a.a_id = b.b_id;
说明: left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
(3)右(外)连接
关键字:right join on / right outer join on
语句:SELECT * FROM a_table a right outer join b_table b on a.a_id = b.b_id;
说明:right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
(4)全连接
关键字:union /union all
语句:(select colum1,colum2...columN from tableA ) union (select colum1,colum2...columN from tableB )
或 (select colum1,colum2...columN from tableA ) union all (select colum1,colum2...columN from tableB );
union语句注意事项:
1.通过union连接的SQL它们分别单独取出的列数必须相同;
2.不要求合并的表列名称相同时,以第一个sql 表列名为准;
3.使用union 时,完全相等的行,将会被合并,由于合并比较耗时,一般不直接使用 union 进行合并,而是通常采用union all 进行合并;
4.被union 连接的sql 子句,单个子句中不用写order by ,因为不会有排序的效果。但可以对最终的结果集进行排序;
(select id,name from A order by id) union all (select id,name from B order by id); //没有排序效果
(select id,name from A ) union all (select id,name from B ) order by id; //有排序效果
(5)交叉联接
SELECT * FROM m CROSS JOIN n; # 标准写法
SELECT * FROM m, n;12.函数
(1)count(*) 函数返回表中的记录数
例如:查询年龄大于20岁的数据量
select count(id) from 表 where age >20
# 聚合函数
SELECT count(id) AS total FROM n; # 总数
SELECT sum(age) AS all_age FROM n; # 总和
SELECT avg(age) AS all_age FROM n; # 平均值
SELECT max(age) AS all_age FROM n; # 最大值
SELECT min(age) AS all_age FROM n; # 最小值
# 数学函数
SELECT abs(-5); # 绝对值
SELECT bin(15), oct(15), hex(15); # 二进制,八进制,十六进制
SELECT pi(); # 圆周率3.141593
SELECT ceil(5.5); # 大于x的最小整数值6
SELECT floor(5.5); # 小于x的最大整数值5
SELECT greatest(3,1,4,1,5,9,2,6); # 返回集合中最大的值9
SELECT least(3,1,4,1,5,9,2,6); # 返回集合中最小的值1
SELECT mod(5,3); # 余数2
SELECT rand(); # 返回0到1内的随机值,每次不一样
SELECT rand(5); # 提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
SELECT round(1415.1415); # 四舍五入1415
SELECT round(1415.1415, 3); # 四舍五入三位数1415.142
SELECT round(1415.1415, -1); # 四舍五入整数位数1420
SELECT truncate(1415.1415, 3); # 截短为3位小数1415.141
SELECT truncate(1415.1415, -1); # 截短为-1位小数1410
SELECT sign(-5); # 符号的值负数-1
SELECT sign(5); # 符号的值正数1
SELECT sqrt(9); # 平方根3
SELECT sqrt(9); # 平方根3
# 字符串函数
SELECT concat('a', 'p', 'p', 'le'); # 连接字符串-apple
SELECT concat_ws(',', 'a', 'p', 'p', 'le'); # 连接用','分割字符串-a,p,p,le
SELECT insert('chinese', 3, 2, 'IN'); # 将字符串'chinese'从3位置开始的2个字符替换为'IN'-chINese
SELECT left('chinese', 4); # 返回字符串'chinese'左边的4个字符-chin
SELECT right('chinese', 3); # 返回字符串'chinese'右边的3个字符-ese
SELECT substring('chinese', 3); # 返回字符串'chinese'第三个字符之后的子字符串-inese
SELECT substring('chinese', -3); # 返回字符串'chinese'倒数第三个字符之后的子字符串-ese
SELECT substring('chinese', 3, 2); # 返回字符串'chinese'第三个字符之后的两个字符-in
SELECT trim(' chinese '); # 切割字符串' chinese '两边的空字符-'chinese'
SELECT ltrim(' chinese '); # 切割字符串' chinese '两边的空字符-'chinese '
SELECT rtrim(' chinese '); # 切割字符串' chinese '两边的空字符-' chinese'
SELECT repeat('boy', 3); # 重复字符'boy'三次-'boyboyboy'
SELECT reverse('chinese'); # 反向排序-'esenihc'
SELECT length('chinese'); # 返回字符串的长度-7
SELECT upper('chINese'), lower('chINese'); # 大写小写 CHINESE chinese
SELECT ucase('chINese'), lcase('chINese'); # 大写小写 CHINESE chinese
SELECT position('i' IN 'chinese'); # 返回'i'在'chinese'的第一个位置-3
SELECT position('e' IN 'chinese'); # 返回'i'在'chinese'的第一个位置-5
SELECT strcmp('abc', 'abd'); # 比较字符串,第一个参数小于第二个返回负数- -1
SELECT strcmp('abc', 'abb'); # 比较字符串,第一个参数大于第二个返回正数- 1
# 时间函数
SELECT current_date, current_time, now(); # 2018-01-13 12:33:43 2018-01-13 12:33:43
SELECT hour(current_time), minute(current_time), second(current_time); # 12 31 34
SELECT year(current_date), month(current_date), week(current_date); # 2018 1 1
SELECT quarter(current_date); # 1
SELECT monthname(current_date), dayname(current_date); # January Saturday
SELECT dayofweek(current_date), dayofmonth(current_date), dayofyear(current_date); # 7 13 13
# 控制流函数
SELECT if(3>2, 't', 'f'), if(3<2, 't', 'f'); # t f
SELECT ifnull(NULL, 't'), ifnull(2, 't'); # t 2
SELECT isnull(1), isnull(1/0); # 0 1 是null返回1,不是null返回0
SELECT nullif('a', 'a'), nullif('a', 'b'); # null a 参数相同或成立返回null,不同或不成立则返回第一个参数
SELECT CASE 2
WHEN 1 THEN 'first'
WHEN 2 THEN 'second'
WHEN 3 THEN 'third'
ELSE 'other'
END ; # second
# 系统信息函数
SELECT database(); # 当前数据库名-test
SELECT connection_id(); # 当前用户id-306
SELECT user(); # 当前用户-root@localhost
SELECT version(); # 当前mysql版本
SELECT found_rows(); # 返回上次查询的检索行数13.键
# 添加主键
ALTER TABLE n ADD PRIMARY KEY (id);
ALTER TABLE n ADD CONSTRAINT pk_n PRIMARY KEY (id); # 主键只有一个,所以定义键名似乎也没有什么用
# 删除主键
ALTER TABLE n DROP PRIMARY KEY ;
# 添加外键
ALTER TABLE m ADD FOREIGN KEY (id) REFERENCES n(id); # 自动生成键名m_ibfk_1
ALTER TABLE m ADD CONSTRAINT fk_id FOREIGN KEY (id) REFERENCES n(id); # 使用定义的键名fk_id
# 删除外键
ALTER TABLE m DROP FOREIGN KEY `fk_id`;
# 修改外键
ALTER TABLE m DROP FOREIGN KEY `fk_id`, ADD CONSTRAINT fk_id2 FOREIGN KEY (id) REFERENCES n(id); # 删除之后从新建
# 添加唯一键
ALTER TABLE n ADD UNIQUE (name);
ALTER TABLE n ADD UNIQUE u_name (name);
ALTER TABLE n ADD UNIQUE INDEX u_name (name);
ALTER TABLE n ADD CONSTRAINT u_name UNIQUE (name);
CREATE UNIQUE INDEX u_name ON n(name);
# 添加索引
ALTER TABLE n ADD INDEX (age);
ALTER TABLE n ADD INDEX i_age (age);
CREATE INDEX i_age ON n(age);
# 删除索引或唯一键
DROP INDEX u_name ON n;
DROP INDEX i_age ON n;14.查询表
# 增加数据
INSERT INTO n VALUES (1, 'tom', '23'), (2, 'john', '22');
INSERT INTO n SELECT * FROM n; # 把数据复制一遍重新插入
# 删除数据
DELETE FROM n WHERE id = 2;
# 更改数据
UPDATE n SET name = 'tom' WHERE id = 2;
# 数据查找
SELECT * FROM n WHERE name LIKE '%h%';
# 数据排序(反序)
SELECT * FROM n ORDER BY name, id DESC ;15.用户
# 增加用户
CREATE USER 'test'@'localhost' IDENTIFIED BY 'test';
INSERT INTO mysql.user(Host, User, Password) VALUES ('localhost', 'test', Password('test')); # 在用户表中插入用户信息,直接操作User表不推荐
# 删除用户
DROP USER 'test'@'localhost';
DELETE FROM mysql.user WHERE User='test' AND Host='localhost';
FLUSH PRIVILEGES ;
# 更改用户密码
SET PASSWORD FOR 'test'@'localhost' = PASSWORD('test');
UPDATE mysql.user SET Password=Password('t') WHERE User='test' AND Host='localhost';
FLUSH PRIVILEGES ;
# 用户授权
GRANT ALL PRIVILEGES ON *.* TO test@localhost IDENTIFIED BY 'test';
# 授予用'test'密码登陆成功的test@localhost用户操作所有数据库的所有表的所有的权限
FLUSH PRIVILEGES ; # 刷新系统权限表,使授予权限生效
# 撤销用户授权
REVOKE DELETE ON *.* FROM 'test'@'localhost'; # 取消该用户的删除权限16.存储过程
# 创建存储过程
DELIMITER // # 无参数
CREATE PROCEDURE getDates()
BEGIN
SELECT * FROM test ;
END //
CREATE PROCEDURE getDates_2(IN id INT) # in参数
BEGIN
SELECT * FROM test WHERE a = id;
END //
CREATE PROCEDURE getDates_3(OUT sum INT) # out参数
BEGIN
SET sum = (SELECT count(*) FROM test);
END //
CREATE PROCEDURE getDates_4(INOUT i INT) # inout参数
BEGIN
SET i = i + 1;
END //
DELIMITER ;
# 删除存储过程
DROP PROCEDURE IF EXISTS getDates;
# 修改存储过程的特性
ALTER PROCEDURE getDates MODIFIES SQL DATA ;
# 修改存储过程语句(删除再重建)略
# 查看存储过程
SHOW PROCEDURE STATUS LIKE 'getDates'; # 状态
SHOW CREATE PROCEDURE getDates_3; # 语句
# 调用存储过程
CALL getDates();
CALL getDates_2(1);
CALL getDates_3(@s);
SELECT @s;
SET @i = 1;
CALL getDates_4(@i);
SELECT @i; # @i = 217.视图
# 创建视图
CREATE VIEW v AS SELECT id, name FROM n;
CREATE VIEW v(id, name) AS SELECT id, name FROM n;
# 查看视图(与表操作类似)
SELECT * FROM v;
DESC v;
# 查看创建视图语句
SHOW CREATE VIEW v;
# 更改视图
CREATE OR REPLACE VIEW v AS SELECT name, age FROM n;
ALTER VIEW v AS SELECT name FROM n ;
# 删除视图
DROP VIEW IF EXISTS v;