4.5-4.6学习总结
文章目录
目录
文章目录
前言
一、List集合
1.List集合定义
1.List集合基本用法
2.List集合的 sort() 和 replaceAll() 方法
2.ArrayList 和 Vector 实现类
ArrayList和Vector区别
3.固定长度的List
二、Queue集合
1.PriorityQueue实现类
PriorityQueue的两种排序
2.Deque接口和ArrayDeque实现类
3.LinkedList实现类
4.各种线性表的性能分析
三、Map集合
1.Map定义
2.HashMap 和 Hashtable实现类
3.LinkedHashMap实现类
4.Properties读写属性文件
一、List集合
1.List集合定义
1.List集合基本用法
List集合代表一个元素有序 , 可重复的集合 , 集合的每个元素都有对应的顺序索引.
List作为Collection 接口额子接口 , 可以使用Collection 接口里的全部方法

package name;
import java.util.ArrayList;
public class ListTest {
public static void main(String [] args)
{
ArrayList books = new ArrayList();
books.add("JavaEE企业应用实战");
books.add("疯狂Java讲义");
books.add("疯狂Android讲义");
System.out.println(books);
books.add(1,new String("疯狂Ajax讲义"));
for(int i=0;iList的独特用法 : List集合可以根据位置索引来访问集合中的元素 , 所以List可以使用普通的for循环来遍历集合元素
List 判断两个对象相等只需要通过equals()方法比较返回true即可
package name;
import java.util.ArrayList;
class AA
{
public boolean equals(Object obj)
{
return true;
}
}
public class ListTest2 {
public static void main(String [ ] args)
{
ArrayList books = new ArrayList();
books.add("轻量级Java EE企业应用实战");
books.add("疯狂Java讲义");
books.add("疯狂Android讲义");
System.out.println(books);
books.remove(new AA());
System.out.println(books);
books.remove(new AA());
System.out.println(books);
}
}
/*
输出:
[轻量级Java EE企业应用实战, 疯狂Java讲义, 疯狂Android讲义]
[疯狂Java讲义, 疯狂Android讲义]
[疯狂Android讲义]
*/当调用 List 的 set( int index , Object element ) 方法来改变 List 集合指定索引处的元素时 , 指定的索引必须是 List 集合的有效索引
set ( int index, Object element ) 方法不会改变 List集合的长度
2.List集合的 sort() 和 replaceAll() 方法
- sort()方法需要一个Comparator 对象
- replaceAll() 需要一个UnaryPperator对象
- sort() 方法排序的规则 : 字符串长度越长 , 字符串越大

package name;
import java.util.ArrayList;
import java.util.ListIterator;
public class ListIteratorTest {
public static void main(String [ ] args)
{
String[] books = {
"疯狂Java讲义",
"疯狂IOS讲义",
"轻量级Java EE企业应用实战"
};
ArrayList bookList = new ArrayList();
for(int i=0;i使用 ListIterator 迭代 List 集合时, 开始也需要采用正向迭代
2.ArrayList 和 Vector 实现类
- ArrayList 和 Vector 是基于数组实现的 List 类 , 所以 ArrayList 和 Vector 类封装了一个动态的 , 允许再分配的 Object[] 数组.
- ArrayList 和 Vector对象使用 initialCapacity 参数来设置该数组的长度
ArrayList 和 Vector 增加元素原则
- 如果向 ArrayList 和 Vector 中添加元素超出了数组的长度时, 他们的 initialCapacity 会自动增加
- 如果要添加大量元素 , 最好使用 ensureCapacity 方法一次性增加 initialCapacity , 减少重分配次数 , 提高性能
- 如果最开始就知道需要保存多少个元素 , 则在创建的时候就指定 initialCapacity 的长度
- 如果创建空的 ArrayList 或 Vector 集合时未指定 initialCapacity 参数 , Object[] 数组的长度默认为10
ArrayList和Vector区别
- ArrayList是线程不安全的 , 当多个线程访问同一个 ArrayList 集合时 , 如果有超过一个线程修改了 ArrayList 集合 , 则程序必须手动保证该集合的同步性;
- Vector 集合线程是安全的 , 无序程序保证改集合的同步性
- Vector的性能比ArrayList的性能要低
Vector还提供了Stack 子类 , 它可以用于模拟 " 栈 " 这种数据结构
3.固定长度的List
操作数组的工具类 : ArrayList 类里的 asList(Object a) 方法 , 可以把一个数组或指定个数的对象转换成一个 List集合 , 这个 List 集合Arrays 内部类ArrayList的实例
Arrays.ArrayList是一个固定长度的List集合 , 程序只能遍历访问该集合里的元素 , 不可增加, 删除该集合里的元素 , 若是试图增加或者删除 , 则会引发 UnsupportedOperationException 异常.
二、Queue集合
Queue用于模拟队列这种数据结构 , 队列通常指 : " 先进先出 " 的容器.
- 队列的头部保存队列中存放时间最长的元素
- 队列的尾部保存在队列中存放时间最短的元素
- 通常 , 队列不允许随机访问队列中的元素

1.PriorityQueue实现类
- PriorityQueue 是一个比较标准的队列实现类.
- PriorityQueue保存队列元素的顺序并不是加入队列的顺序 , 而是按队列元素的大小重新排序
- PriorityQueue使用poll()方法或者 peek()方法取出元素的时候 , 并不是取出最先入列的元素 , 而是取出队列中最小的元素.
package name;
import java.util.PriorityQueue;
public class PriorityQueueTest {
public static void main(String[] args)
{
PriorityQueue pq = new PriorityQueue();
pq.offer(6);
pq.offer(-3);
pq.offer(20);
pq.offer(18);
System.out.println(pq);
System.out.println(pq.poll());
System.out.println(pq.poll());
System.out.println(pq.poll());
System.out.println(pq.poll());
}
}
/*
输出:
[-3, 6, 20, 18]
-3
6
18
20
*/
/*
通过多次调用 poll() 方法可见 , 元素从小到大的顺序"移除队列"
*/PriorityQueue不允许插入 null 元素 , 它还需要对队列元素进行排序
PriorityQueue的两种排序
- 自然排序: 必须实现Comparable接口 , 而且是同一个类的多个实例 , 否则可能导致ClassCastException异常
- 定制排序: 创建PriorityQueue队列时 , 需要传入一个Comparator 对象
2.Deque接口和ArrayDeque实现类
Deque 接口是Queue 接口的子接口 , 它代表一个双端队列

- ArrayList 和 ArrayDeque 两个集合类的实现机制基本相似 , 它们的底层都采用一个动态的 , 可重新分配的 Object[ ] 数组来才存储集合元素 , 如果集合元素超出了数组的容量 , 系统会在底层重新分配一个 Object[ ] 数组来存储集合元素
- ArrayDeque 不仅可以作为栈用 , 也可以作为队列使用
package name;
import java.util.ArrayDeque;
//作为队列使用
public class ArrayDequeQueue {
public static void main(String [] args)
{
ArrayDeque queue = new ArrayDeque();
queue.offer("疯狂Java讲义");
queue.offer("轻量级Java EE企业应用实战");
queue.offer("疯狂Android讲义");
System.out.println(queue);
System.out.println(queue.peek());
System.out.println(queue);
System.out.println(queue.poll());
System.out.println(queue);
}
}package name;
import java.util.ArrayDeque;
//作为栈使用
public class ArrayDequeStack {
public static void main(String [] args)
{
ArrayDeque stack = new ArrayDeque();
stack.push("疯狂Java讲义");
stack.push("轻量级Java EE企业应用实战");
stack.push("疯狂Android讲义");
System.out.println(stack);
System.out.println(stack.peek());
System.out.println(stack.peek());
System.out.println(stack.pop());
System.out.println(stack);
}
}
3.LinkedList实现类
- LinkedList 类是 List 类的实现类 , 也就是说它是一个 List 集合 , 可以根据索引来随机访问集合中的元素
- LinkedList 还实现了 Deque 接口 , 可以被当成双端队列来使用 , 既可以作为" 栈 " , 也可以作为 "队列" 使用 .
- LinkedList 内部以链表的形式来保存数组中的元素 , 因此随机访问集合元素功能性较差
- LinkedList 在插入 , 删除时性能比较出色
- 对于所有的内部基于数组的集合实现 , 使用随机访问的性能比使用 Interator 迭代访问的性能要好 , 因为随机访问会被映射成对数组元素的访问
4.各种线性表的性能分析
- 所有内部以数组作为底层实现的集合在随机访问时性能都比较好
- 所有内部以链表作为底层实现的集合在执行插入 , 删除操作时有较好的性能
- 总体上 , ArrayList 性能比 LinkedList 性能要好
List集合使用建议 :
- 遍历元素的时候 , 对于 ArrayList , Vector 集合 , 应该是使用随机访问法 (get) 来访问遍历集合元素
- 对于 LinkedList 集合 , 则应该采用 (Iterator) 迭代器来遍历集合元素
- 如果要经常执行插入 , 删除操作来改变大量数据的 List 集合的大小 , 则考虑用 LinkedList 集合
- 如果多个线程访问 List 集合中的元素 , 则可考虑使用 Collection 将集合包装成线程安全的集合
三、Map集合
1.Map定义
- Map用于保存具有映射关系的数据
- Map集合里面保存在这两组值 , 一组值用于保存Map里的 Key ,另外一组用于保存 Map 里面的value
- key 和 value 都可以是任何引用类型的数据
- Map的key 不允许重复
- key 和 value 之间存在单向一对一关系 , 即通过指定的 key , 总能找到唯一的 , 确定的 value;
2.HashMap 和 Hashtable实现类
HashMap 和 Hashtable 区别:
- Hashtable 是一个线程安全的Map 实现 , 但HashMap是线程不安全的实现
- Hashtable 不允许使用 null 作为 key 和 value , 如果试图 null 值放进 Hashtable 中, 将会引发 NullPointerException 异常 , 但是 HashMap 可以使用 null 作为 key 或者 value
- HashMap 里面的 key 不能重复 , 所以最多只能有一个 key 为 null , 但可以有无数的 key-value 中的 value 为 null
- 尽量少用Hashtable实现类
HashMap 和 Hashtable 判断两个value 相等的标准 : 只要两个对象通过equals()方法比较返回true
自定义类作为 HashMap , Hashtable 的 key 时 , 如果重写了类的 equals()方法 , 则应该保证:当两个 key 通过 equals() 方法返回true 时 ,两个 key 的 hashCode()返回值也应该相同
- 尽量不要使用可变对象作为HashMap , Hashtable 的 key ,如果确实需要使用可变对象 ,则精良不要在程序中修改作为 key 的可变对象
3.LinkedHashMap实现类
LinkedHashMap类使用双向链表来维护 key-value 对的顺序 , 链表负责维护 Map 的迭代顺序 , 迭代顺序与 key - value 对的插入顺序一致
也就是 LinkedHashMap能记住 key - value 的添加顺序
4.Properties读写属性文件
Properties相当于一个 key , value 都是String 类型的 Map;
Properties可以把Map对象和属性文件关联起来
package name;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.Properties;
public class PropertiesTest {
public static void main(String [ ] args) throws Exception
{
Properties props = new Properties();
props.setProperty("username","Alice");
props.setProperty("password","123456");
props.store(new FileOutputStream("a.ini"),"comment line");
Properties props2 = new Properties();
props2.setProperty("gender" ,"male");
props2.load(new FileInputStream("a.ini"));
System.out.println(props2);
Properties prop3 = new Properties();
}
}
5.SortMap接口和TreeMap实现类
Map接口派生出一个SortMap 的子接口 , SortedMap 接口有一个TreeMap 的实现类 .
TreeMap就是一个红黑树数据结构 , 每个 key-value 对作为一个红黑树的节点
TreeMap 的两种排序方式:
- 自然排序 : TreeMap 的所有 key 必须实现 Comparable 接口 , 而且所有的 key 应该是同一个类的对象 , 否则会引发 ClassCastException
- 定制排序 : 创建 TreeMap 时 , 传入一个 Comparator 对象 , 改对象负责对 TreeMap 中的所有 key 进行排序
6.WeakHashMap 实现类
WeakHashMap 和 HashMap 的用法基本相似
- WeakHashMap 与 HashMap 的区别在于 :
- HashMap 保留了对实际对象的强引用 , 只要 HashMap的对象没有被销毁 , 所有 key 所引用的对象就不会被垃圾回收.
- WeaHashkMap 保留了对实际对象的弱引用 , key所引用的对象可能被垃圾回收, WeakHashMap 可能自动删除 key 值对应的 key-value
7.IdentityHashMap实现类
- IdentityHashMap 类处理两个 key 相等: 当且仅当两个 key 严格相等 ( key1==key2 )时 , IdentityHashMap才认为两个 key 相等 ,
- HashMap: key1 和 key2 通过 equals () 方法比较返回true ,且他们两个的 hashCode 相等就行
8.EnumMap 实现类
- EnumMap类是一个必须和枚举类一起使用的 Map 实现
- EnumMap 中的 key值都必须是单个枚举类的枚举值 .
- 创建 EnumMap 时必须显式或者隐式指定它对应的枚举类
EnumMap的特征:
- 在内部以数组的形式保存 , 这种实现形式非常紧凑 , 高效
- EnumMap 根据 key 的自然顺序 ( 即枚举值在枚举类中的定义顺序 ) 来维护 key-value 对的顺序
- EnumMap 不允许使用 null 作为 key , 但是允许使用 null 作为 value . 如果试图使用 null 作为 key 时将抛出 NullPointerException 异常
三、Collections工具类
Collections是一个操作 Set、List 和Map等集合的工具类
Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
排序操作:(均为static方法)
- reverse(List):反转List 中元素的顺序
- shuffle(List):对List 集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int,int):将指定list 集合中的i处元素和j处元素进行交换
查找、替换
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据Comparator 指定的顺序,返回给定集合中的最大元素
- Object min(Collection)
- Object min(Collection, Comparator)
- int frequency(Collection,Object):返回指定集合中指定元素的出现次数
- void copy(List dest,List src):将src中的内容复制到dest中
- rboolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
四、泛型
1.为什么需要泛型?
Java集合有一个缺点 : 把一个对象 " 丢进 " 集合里之后 , 集合会 " 忘记 "
这个对象的数据类型 ,当再次取出这个对象的时候 , 它就变成了 Object 类
也就说说明: 单纯使用传统的集合会存在一些问题 :
1.不能对加入到集合ArrayList中的数据类型进行约束(不安全)
2.遍历的时候,需要进行类型转换,如果集合中的数据量较大,对效率有影响2.泛型的定义
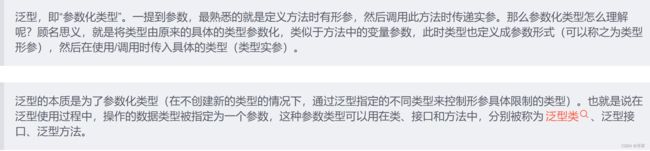
使用了泛型 , 这个集合就只能保存指定类型的对象, 不能再保存其他类型的对象.也可以理解为泛型也是对集合进行了一个约束.
举个例子 : 我定义了一个小狗类型的集合 , 一旦使用了泛型 , 除了小狗的其他类型的对象 , ( 例如: 小猫 , 小兔子等 ) 就不能属于这个集合
3.泛型接口、泛型类 、泛型方法
泛型的实质: 允许在定义接口 , 类时声明泛型形参 , 泛型形参在整个接口 , 类体内可以成类型使用.
可以为任何类 , 任何接口增加泛型声明 ( 并不集合类才可以使用泛型声明 )
定义泛型接口:
package study;
public interface Iterator
{
E next();
boolean hasNext();
} package study;
import java.util.Iterator;
public interface List
{
void add(E x) ;
Iterator iterator();
}
定义泛型类:
package study;
public class Apple {
private T info;
public Apple(){};
public Apple(T info)
{
this.info = info ;
}
public void setInfo(T info)
{
this.info = info;
}
public T getInfo()
{
return this.info;
}
public static void main(String [] args)
{
Apple a1 = new Apple<> ("苹果");
System.out.println(a1.getInfo());
}
} 定义泛型方法:
public T genericMethod(Class tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
} 判断一个方法是否是泛型方法关键看方法返回值前面有没有使用 <> 标记的类型,有就是,没有就不是。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。