可复用软件模块的接口设计
在上一篇博客中模块化代码的基本写法举例_青衫客36的博客-CSDN博客,我们给出了模块化代码的基本写法,本文我们继续探讨对menu程序进行改造,使之成为可复用软件模块。
下面先引入可重用软件的一些相关概念。
消费者复用和生产者复用
软件复用可分为消费者复用和生产者复用。
消费者重用是指软件开发者在项目中重用已有的一些软件模块代码,以加快项目工作进度。软件开发者在重用已有的软件模块代码时一般会重点考虑如下四个关键因素:
- 该软件模块是否能满足项目所要求的功能;
- 采用该软件模块代码是否比从头构建一个需要更少的工作量,包括构建软件模块和集成软件模块等相关的工作;
- 该软件模块是否有完善的文档说明;
- 该软件模块是否有完整的测试及修订记录;
如上四个关键因素需要按照顺序依次评估。
我们清楚了消费者重用时考虑的因素,那么生产者在进行可重用软件设计时需要重点考虑的因素也就清楚了,但是除此之外还有一些事项在进行可重用软件设计时牢记在心,我们简要列举如下:
- 通用的模块才有更多重用的机会;
- 给软件模块设计通用的接口,并对接口进行清晰完善的定义描述;
- 记录下发现的缺陷及修订缺陷的情况;
- 使用清晰一致的命名规则;
- 对用到的数据结构和算法要给出清晰的文档描述;
- 与外部的参数传递及错误处理部分要单独存放易于修改;
可复用软件设计的关键是接口设计,接下来我们重点来看接口的基本概念和写法。
接口的基本概念
我们回到menu菜单项目,尽管已经做了初步的模块化软件设计,但是分离出来的数据结构及其操作还有很多菜单业务的痕迹。我们要求这一个软件模块只做一件事,就是功能内聚,也就是要让他做好链表数据结构及其链表的操作,不应该涉及菜单业务功能上的东西。同时我们希望这一个软件模块与其他软件模块之间松散耦合,就需要定义简洁、清晰、明确的接口。
接口就是互相联系的双方共同遵守的一种协议规范。在我们软件系统内部,一般的接口是指通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义软件模块对系统的其他部分提供怎样的服务,以及系统的其他部分如何访问所提供的服务。
在面向过程编程中,接口一般定义数据结构及其操作这些数据结构的函数;而在面向对象编程中,接口是对象对外开放的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
接口规格是软件系统的开发者正确使用某个软件模块需要知道的所有信息,那么这个软件模块的接口规格定义必须清晰明确的说明正确使用本软件模块的信息。一般来说,接口规格包含5个基本要素,如下:
- 接口的目的
- 接口使用前所需满足的条件,一般称为前置条件或假定条件
- 使用接口的双方需要遵循的数据规格
- 接口使用后的效果,一般称为后置条件
- 接口所隐含的质量属性
软件模块接口举例
软件模块接口在面向过程编程中一般是定义一些数据结构和函数接口,在面向对象的编程中一般在类或接口类中定义一些公有属性和方法。两类编程在接口形式上有很大不同,但是不管是函数接口还是对象对外开放的(public)方法,本质上都是函数定义。
我们将重点介绍两种方式的函数接口,这里我们先以Call-in方式的函数接口为例来理解函数接口规格。
以下函数接口代码是从链表中取出链表的头结点的函数声明,以此为例,我们先来理解接口规格包含的5个基本要素。
/*
* get LinkTableHead
*/
tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable);- 该接口的目标是从链表中取出链表的头结点,函数名GetLinkTableHead清晰表明了接口的目标。
- 该接口的前置条件是链表必须存在,使用该接口才有意义,也就是链表pLinkTable != NULL。
- 使用该接口的双方需要遵循的数据规格是通过数据结构tLinkTableNode 和 tLinkTable 定义的。
- 使用该接口之后的效果是找到了链表的头结点。这里是以tLinkTableNode类型的指针为返回值来作为后置条件,C语言中也可以使用指针类型的参数作为后置条件。
- 该接口没有特别要求接口的质量属性,如果搜索一个节点,可能需要在可以接受的延迟时间范围内完成搜索。
下面是一个完整的链表软件模块的接口示例linktable.h的代码,以供参考。
#ifndef _LINK_TABLE_H_
#define _LINK_TABLE_H_
#include "linktableInternal.h"
#define SUCCESS 0
#define FAILURE (-1)
/*
* LinkTable Node Type
*/
typedef struct LinkTableNode tLinkTableNode;
/*
* LinkTable Type
*/
typedef struct LinkTable tLinkTable;
/*
* Create a LinkTable
*/
tLinkTable * CreateLinkTable();
/*
* Delete a LinkTable
*/
int DeleteLinkTable(tLinkTable *pLinkTable);
/*
* Add a LinkTableNode to LinkTable
*/
int AddLinkTableNode(tLinkTable *pLinkTable, tLinkTableNode *pNode);
/*
* Delete a LinkTableNode from LinkTable
*/
int DelLinkTableNode(tLinkTable *pLinkTable, tLinkTableNode *pNode);
/*
* Serach a LinkTableNode from LinkTable
* int Condition(tLinkTableNode *pNode, void * args);
*/
tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Condition(tLinkTableNode *pNode, void *args), void * args);
/*
* get LinkTableHead
*/
tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable);
/*
* get next LinkTableNode
*/
tLinkTableNode *GetNextLinkTableNode(tLinkTable *pLinkTable, tLinkTableNode *pNode);
#endif /* _LINK_TABLE_H_ */其中引用的linktableInternal.h代码如下:
#include
/*
* LinkTable Node Type
*/
struct LinkTableNode
{
struct LinkTableNode * pNext;
};
/*
* LinkTable Type
*/
struct LinkTable
{
struct LinkTableNode *pHead;
struct LinkTableNode *pTail;
int SumOfNode;
pthread_mutex_t mutex;
};
微服务接口举例
微服务接口一般使用RESTful API来定义接口。RESTful API是目前最流行的一种互联网软件接口定义方式。它结构清晰、符合标准、易于理解、扩展方便,得到了越来越多网站的采用。 在微服务接口举例之前,我们先需要简单的理解微服务架构和RESTful API的基本概念。
RESTful API
REST即REpresentational State Transfer的缩写,可以翻译为”表现层状态转化”。有表现层就有背后的信息实体,信息实体就是URI代表的资源,也可以是一种服务,状态转化就是通过HTTP协议里定义的四个表示操作方式的动词:GET、POST、PUT、DELETE,分别对应四种基本操作:
- GET用来获取资源;
- POST用来新建资源(也可以用于更新资源);
- PUT用来更新资源;
- DELETE用来删除资源。
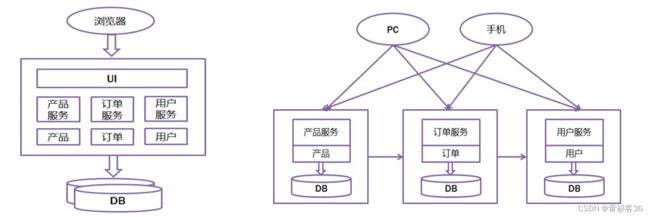
传统单体集中式架构与微服务架构
在模块化思想的指导下目前主要有两种软件架构模式,即传统单体集中式(Monolithic)架构与微服务(Microservice)架构。传统单体集中式架构是相对于新型的微服务架构而言的,因此我们先来看看什么是微服务。 微服务这个概念是2012年出现的,作为加快Web和移动应用程序(App)开发效率的一种方法提出,2014年开始受到各方的关注,而2015年,可以说是微服务的元年得到了广泛的关注。
显然微服务架构是传统单体集中式架构基础上的进化。为什么会出现这样的进化?一定是微服务架构比传统单体集中式架构更适应不断变化的环境。进一步思考就是环境发生了怎样的变化?显然与微服务架构的出现是伴随着单体服务器向基于虚拟化技术和分布式计算的云服务变化趋势的。
传统单体集中式架构是适应大型机、小型机单体服务器环境的软件架构模式;微服务架构则是为了适应PC服务器的大规模集群及基于虚拟化技术和分布式计算的云计算环境的架构模式。
微服务的概念
由一系列独立的微服务共同组成软件系统的一种架构模式;
每个微服务单独部署,跑在自己的进程中,也就是说每个微服务可以有一个自己独立的运行环境和软件堆栈;
每个微服务为独立的业务功能开发,一般每个微服务应分解到最小可变产品(MVP),达到功能内聚的理想状态。微服务一般通过RESTful API接口方式进行封装;
系统中的各微服务是分布式管理的,各微服务之间非常强调隔离性,互相之间无耦合或者极为松散的耦合,系统通过前端应用或API网关来聚合各微服务完成整体系统的业务功能。
微服务架构的基本概念可以简单概括为通过模块化的思想垂直划分业务功能,传统单体集中式架构和微服务架构如下图示意。
我们以手写识别微服务https://api.website.cn/service/ocr-handwriting 为例来理解接口规格包含的五个基本要素。 如下为调用微服务ocr-handwriting的HTTP请求信息简易示意代码。
POST /service/ocr-handwriting?code=auth_code HTTP/1.1
Content-Type: image/png
[content of handwriting.png]
微服务ocr-handwriting成功执行后HTTP响应返回的JSON数据示意代码。

- 该微服务接口的目标是手写识别服务,通过微服务命名ocr-handwriting来表明接口的目的;
- 该微服务接口的前置条件包括取得调用该微服务接口的授权auth_code,以及已经有一张手写图片handwriting.png
- 调用该微服务接口的双方遵守的协议规范除HTTP协议外还包括PNG图片格式和识别结果JSON数据格式定义;
- 调用该微服务接口的效果即后置条件为以JSON数据的方式得到了识别的结果;
- 从以上示意代码中该微服务接口的质量属性没有具体指定,但因为底层使用了TCP协议,因此该接口隐含的响应时间质量属性应小于TCP连接超时定时器。
接口与耦合度之间的关系
对于软件模块之间的耦合度,前文中曾提及到,耦合度是指软件模块之间的依赖程度,一般可分为紧密耦合、松散耦合和无耦合。一般在软件设计中我们追求松散耦合。
如果更细致地对耦合度进一步划分,按耦合度依次递增可以分为无耦合、数据耦合、标记耦合、控制耦合、公共耦合和内容耦合。这些耦合度划分的依据主要就是接口的定义方式。我们接下来重点分析数据耦合、标记耦合和公共耦合。
1、数据耦合
在软件模块之间仅通过显式的调用传递基本数据类型为数据耦合。
2、标记耦合
在软件模块之间仅通过显式的调用传递复杂的数据结构(结构化数据)为标记耦合,这时数据的结构成为调用双方软件模块隐含的数据规格约定,因此标记耦合的耦合度要比数据耦合的耦合度高。但比公共耦合没有经过显式的调用传递数据的方式,耦合度要低。
3、公共耦合
当软件模块之间共享数据区或变量名时,软件模块直接为公共耦合,显然两个软件模块之间的接口定义不是通过显式的调用方式,而是隐式地共享了数据区或变量名。
同步接口和异步接口
使用同步接口意味着调用接口的一方需要阻塞等待接口任务目标达成,然后返回才能继续执行,也就是调用接口的双方是串行执行的。
使用异步接口是指调用接口的一方只是发出调用接口的命令,并不需要阻塞等待接口任务目标达成后才返回,而是直接返回,继续执行其他任务,在之后接到任务目标达成的结果或者主动查询任务目标达成的结果。
异步接口的情况比较复杂,往往会借助多线程编程或异步I/O,甚至结合线程池、消息队列、信号传递等,这需要明确定义较为复杂的异步接口机制。
接下来,我们的menu菜单项目中的LinkTable模块会具体用到回调函数,敬请期待下一篇博客吧hh~
以上内容为中科大软件学院《高级软件工程》课后总结,感谢孟宁老师的倾心教授,老师讲的太好啦(^_^)
参考资料:《代码中的软件工程》 孟宁 编著