Mit6.828_Lab5 File system, Spawn and Shell
Lab 5: File system, Spawn and Shell
Introduction
在本实验中,您将实现spawn,这是一个库调用,可加载并运行磁盘上的可执行文件。 然后,您将充实内核和库操作系统,以在控制台上运行Shell。 这些功能需要一个文件系统,本实验介绍了一个简单的读/写文件系统。
File system preliminaries
您将使用的文件系统比包括xv6 UNIX在内的大多数“真实”文件系统要简单得多,但是它的功能足以提供基本功能:创建,读取,写入和删除以分层目录结构组织的文件。
无论如何,我们目前仅在开发一个单用户操作系统,该操作系统提供的保护足以捕获错误,但不能保护多个相互可疑的用户彼此之间。 因此,我们的文件系统不支持文件所有权或权限的UNIX概念。 我们的文件系统目前也不像大多数UNIX文件系统那样支持硬链接,符号链接,时间戳或特殊设备文件。
On-Disk File System Structure
大多数UNIX文件系统将可用的硬盘空间划分为两种类型的区域:inode索引节点域和数据区。UNIX文件系统会为每个文件分配一个inode,inode中保留了对应文件的关键元数据,例如文件状态属性和指向其数据块的指针。数据区被划分为更大的数据块(一般是8KB大小也可能更大),文件系统在其中存储文件数据和目录元数据。目录项包含文件名和指向inode的指针。如果文件系统中的多个目录项指向同一文件的inode,则该文件称为硬链接文件,因为我们的文件系统不支持硬链接,所以我们不需要该级别的间接寻址,因此可以方便的简化,我们的文件系统也根本不会使用索引节点(inode),而只会在描述该文件的(唯一)目录项中存储文件(或子目录)的所有元数据。
从逻辑上说,文件和目录都由一系列的数据块组成,这些数据块可能离散地分布在硬盘的各个地方就像单个进程的虚拟地址空间所拥有的页在物理内存上离散分布一样。文件系统环境隐藏了块布局的细节,并提供了接口用于在文件内的任意偏移量处读/写一串字节。文件系统环境在内部处理对目录的所有修改,这是执行诸如创建和删除文件之类的操作的一部分。 我们的文件系统确实允许用户环境直接读取目录元数据(例如,通过read),这意味着用户环境可以自己执行目录扫描操作(例如,执行ls程序),而不必依赖于其他特殊调用。 这种目录扫描方法的缺点以及大多数现代UNIX变体操作系统不鼓励这样做的原因是,它使应用程序依赖于目录元数据的格式,从而难以更改文件系统的内部布局,目录元数据格式如果发生变化,那么读取其数据的应用程序代码相应地也要发生改变,至少得重新编译应用程序。
Sectors and Blocks
大多数磁盘无法按字节粒度执行读写操作,而是以扇区为单位执行读写操作。 在JOS中,每个扇区(sector)均为512字节。 文件系统实际上以块(block)为单位分配和使用磁盘存储。 注意两个术语之间的区别:扇区大小是磁盘硬件的属性,而块大小是操作系统使用磁盘时的一个基本单位。 文件系统的块(block)大小必须是基础磁盘的扇区(sector)大小的倍数。
UNIX xv6文件系统使用512字节的块大小,与基础磁盘的扇区大小相同。 但是,大多数现代文件系统使用更大的块大小,因为存储空间变得便宜得多,并且以较大的粒度管理存储更为有效。 我们的文件系统将使用4096字节的块大小,可以方便地匹配处理器的页面大小。
Superblocks
文件系统通常会在硬盘上易于查找的位置保留一些块(如非常前或非常后的位置)来保存描述整个文件系统属性的元数据(例如块大小,硬盘大小,查找根目录所需元数据,文件系统上次装载的时间,文件系统上次检查错误的时间等等)。这些特殊的块被称为超级块(superblocks)。
我们的文件系统将只有一个超级块,在硬盘上是第1块,inc/fs.h中定义的super结构体描述了它的布局,第0块通常用于保存boot loaders和分区表,所以文件系统通常不会用到最起始的块。很多真正的文件系统会维护多个超级块,这些超级块在磁盘的几个间隔很宽的区域中复制,因此,如果其中一个超级块损坏,或者磁盘在该区域中出现介质错误仍然可以找到其它超级块并用来访问文件系统。
File Meta-data
在JOS的文件系统中,inc/fs.h中的file结构体描述了文件的元数据的布局。该元数据包括文件的名称。大小。类型(常规文件或目录)以及指向组成文件的块的指针。如上所述,我们没有索引结点,因此这些元数据存储在磁盘上的一个目录项中。与大多数真正的文件系统不同,为了简单起见,我们将使用这种文件结构来表示文件元数据,因为它同时出现在磁盘和内存中。
struct File中的f_direct数据包含存储文件前10个(NDIRECT)块的块号的空间,我们称之为文件的直接索引块(意思就是这10个块相当于是直接存在结构体的空间中的)。对于大小不到10*4096B=40KB的小文件,使用f_direct就够了。但是,对于较大的文件,我们分配一个额外的磁盘块,称为文件的间接索引块,以容纳4096/4=1024个额外的块号。
因此,我们的文件系统允许的文件大小最多为1034块,即超过4MB一点点。为了支持更大的文件,真正的文件系统通常还支持二级间接索引块和三级间接索引块。
Directories versus Regular Files
我们文件系统中的File结构可以表示常规文件或目录; 这两种类型的“文件”由文件结构中的类型字段(type)区分。 文件系统以完全相同的方式管理常规文件和目录文件,只是它根本不解释与常规文件关联的数据块的内容,而文件系统将目录文件的内容解释为一系列。 描述目录中文件和子目录的文件结构。
我们文件系统中的超级块包含一个File结构(struct Super中的根字段),该结构保存文件系统根目录的元数据。 该目录文件的内容是一系列文件结构,描述了位于文件系统根目录中的文件和目录。 根目录中的任何子目录都可能包含更多表示子子目录的File结构,依此类推。
The File System
本实验的目标不是让你实现整个文件系统,而是让你只实现某些关键组件。你将负责将数据块读入数据块缓存,并将其刷新回磁盘;分配磁盘块;将文件偏移量映射到磁盘块;以及在IPC接口中实现读、写和打开。因为你不会实现所有的文件系统,所以熟悉所提供的代码和文件系统接口是非常重要的。
Disk Access
操作系统中的文件系统环境需要能够访问磁盘,但是我们尚未在内核中实现任何磁盘访问功能。我们没有采用传统的“monolithic”策略来将IDE 磁盘驱动添加到内核中,这种方法必然会携带着相应的系统调用来允许文件系统访问它。取而代之的是,我们将IDE磁盘驱动添加作为用户级文件系统进程的一部分。 为了进行设置,我们仍然需要稍微修改内核,以便文件系统进程具有实现磁盘访问本身所需的特权。(总结:JOS系统将磁盘访问操作视作用户权限的操作)
如果我们只依靠轮询和基于“编程I / O”(PIO)的磁盘访问并且不使用磁盘中断的话,我们可以在用户空间中轻松实现磁盘访问。 也可以在用户模式下实现中断驱动的设备驱动程序(例如L3和L4内核执行此操作),但是由于内核必须现场中断设备并将其分派到正确的用户模式环境,因此会更加困难。
x86处理器通过EFLAGS的IOPL位来决定保护模式下的代码是否有权限执行特殊的设备I/O指令(如IN和OUT指令)。因为我们需要访问的所有集成开发环境磁盘寄存器都位于x86的I/O空间,而不是内存映射的空间,所以为了允许文件系统访问这些寄存器,我们唯一需要做的事是给文件系统进程赋予“I/O特权”。实际上,EFLAGS寄存器中的IOPL位为内核提供了一种简单的“all-or-nothing”的方法来控制用户态代码是否可以访问I/O空间,但我们不希望任何其他进程访问I/O空间。
exercise 1: i386_init通过进程创建函数env_create传递的类型
ENV_TYPE_FS来识别文件系统进程,修改env.c中的env_create,这样它就会给予文件系统进程I/O特权而不会给任何其他进程该特权。确保能够启动文件系统进程并且不发生常规保护错误,在make grade中应当能通过fs i/o的测试。
question1 : 你是否不得不做一些其他事来确保当环境不断切换时,I/O特权设定依然能被保存和恢复? 为什么?
答:不需要,因为在环境切换时,会保存eflags的值,也会用 env_pop_tf恢复eflags的值。
请注意,本实验中的GNUmakefile文件将QEMU设置为使用文件obj / kern / kernel.img作为磁盘0的映像(在DOS / Windows下通常为“ Drive C”),并使用(新)文件 obj / fs / fs.img作为磁盘1(“驱动器D”)的映像。 在本实验中,我们的文件系统只能接触磁盘1; 磁盘0仅用于引导内核。 如果您设法以某种方式损坏任何一个磁盘映像,只需键入以下命令即可将它们重置为原始的“原始”版本:
$ rm obj/kern/kernel.img obj/fs/fs.img
$ make
or by doing:
$ make clean
$ make
测试:(通过)
![]()
The Block Cache
在我们的文件系统中,我们将在处理器的虚拟存储系统的帮助下实现一个简单的缓冲区缓存(实际上就是一个块缓存)。块缓存的代码在fs/bc.c中。
我们的文件系统只能处理3GB以下的硬盘,我们在文件系统进程的地址空间中保留了3GB大小的固定区域,从0X10000000(DISKMAP)到0XD0000000(DISKMAP+DISKMAX),作为磁盘的“内存映射”版本。例如磁盘块0映射到虚拟地址0x10000000,磁盘块1映射到虚拟地址0x10001000,依次类推。fs/bs.c中的diskaddr函数实现了从磁盘块号到虚拟地址的转换(以及一些完整性检查)
因为我们的文件系统进程有其独立的虚拟地址空间,并且它要做的唯一工作就是实现文件访问,因此在文件系统进程的虚拟地址空间中保留这么大的区域是合理的。
当然,将整块硬盘读入内存会非常耗时,所以我们以请求分页的形式实现,我们只在磁盘映射区域分配页和从磁盘中读取相应的块来响应一个发生的页面错误。这种方式下,就像整个硬盘都在内存中一样。
exercise 2:实现fs/bc.c中的bc_pgfault和flush_block函数,bc_pgfault是一个页面错误处理函数就像先前实验中写过的copy-on-write fork一样,只是它的工作是从磁盘加载页面来响应页面错误。写这些代码时,需要注意两点:(1)addr可能没有对齐到block边界。(2)ide_read是操作sectors而不是blocks.
如果需要,flush_block函数应该将一个块写到磁盘上。如果块不在块缓存中(也就是说,页面没有被映射)或者脏位为0,那么flush_block不应该做任何事情。我们将使用虚拟机硬件来跟踪磁盘块自上次从磁盘读取或写入磁盘后是否被修改过。要查看一个块是否需要写入,我们可以只查看在uvpt项中是否设置了PTE_D脏位。(PTE_D位由处理器设置,以响应于对该页的写入)将块写入磁盘后,flush_block应该使用sys_page_map清除PTE_D位。
1.bc_pgfault()函数:
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
addr = (void *) ROUNDDOWN(addr, PGSIZE);
//Allocate a page in the disk map region
if ((r = sys_page_alloc(0, addr, PTE_U | PTE_P | PTE_W)) < 0)
panic("in bc_pgfault, sys_page_alloc: %e", r);
//read the contents of the block from the disk into that page
if ((r = ide_read(blockno * BLKSECTS, addr, BLKSECTS)) < 0)
panic("in bc_pgfault, ide_read: %e", r);
2.flush_block()函数
// LAB 5: Your code here.
//panic("flush_block not implemented");
int r;
addr = ROUNDDOWN(addr, PGSIZE);
//If the block is not in the block cache or is not dirty, does nothing.
if(va_is_mapped(addr) && va_is_dirty(addr)){
//Flush the contents of the block containing VA out to disk
if ((r = ide_write(blockno * BLKSECTS, addr, BLKSECTS)) < 0)
panic("in flush_block, ide_write: %e", r);
//clear the PTE_D bit using sys_page_map
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in flush_block, sys_page_map: %e", r);
}
测试:(通过)
The Block Bitmap
在fs_init函数设置位示图指针后,我们可以把位示图看做一个压缩后的位数组,每位对应硬盘中的一块,例如block_is_free函数中就通过检查位示图块中的每位来判断对应块是否是空闲的。
exercise 3:参考free_block实现fs/fs.c中的alloc_block函数,该函数应当在位示图块中找到一个空闲的磁盘块,然后将其标记为已使用,并返回该块的块号,当分配一块时,你应该立即使用flush_block来将修改过的块写入磁盘,以使文件系统保持一致性。
// LAB 5: Your code here.
//panic("alloc_block not implemented");
for(int block_num=2;block_num<=super->s_nblocks;block_num++){
if(block_is_free(block_num)){
bitmap[block_num/32] &= ~(1<<(block_num%32));
flush_block(diskaddr(block_num));
return block_num;
}
}
return -E_NO_DISK;
测试通过:
File Operations
我们在fs/fs.c中提供了各种函数来实现基本的功能,你将需要这些功能来解释和管理File结构体、扫描和管理目录文件的目录项,以及从root目录遍历文件系统以解析绝对路径名(absolute pathname)。阅读fs/fs.c中的所有代码,确保在继续之前理解每个函数的功能。
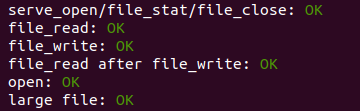
exercise 4:实现file_block_walk和file_get_block,file_block_walk将文件中的块偏移量映射到struct File或间接块中的块的指针,非常类似于pgdir_walk对页表所做的操作。file_get_block进一步映射到实际的磁盘块,如果需要的话分配一个新的磁盘块。使用make grade测试代码。您的代码应该通过“file_open”、“file_get_block”、“file_flush/file_truncated/file rewrite”和“testfile”测试。
1.file_block_walk
static int file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
// LAB 5: Your code here.
//panic("file_block_walk not implemented");
//if filebno is out of range (it's >= NDIRECT + NINDIRECT).
if(filebno>=NDIRECT+NINDIRECT||filebno<0)
return -E_INVAL;
//filebno is a direct block
if(filebno<NDIRECT){
*ppdiskbno = &f->f_direct[filebno];
return 0;
}
//if the function needed to allocate an indirect block, but alloc was 0.
if(!f->f_indirect && !alloc)
return -E_NOT_FOUND;
//When 'alloc' is set, this function will allocate an indirect block
//if necessary.(no indirect , so necessary)
if(!f->f_indirect){
int r = alloc_block();
//if there's no space on the disk for an indirect block.
if(r<0) return r;
//otherwise f->f_indirect point to the number of the alloced block
f->f_indirect = r;
//clear
memset(diskaddr(r),0,BLKSIZE);
flush_block(diskaddr(r));
}
//Set '*ppdiskbno' to point to that slot
if (ppdiskbno)
*ppdiskbno = (uint32_t*)diskaddr(f->f_indirect) + filebno - NDIRECT;
//0 on success
return 0;
}
2.file_get_block
int file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
//panic("file_get_block not implemented");
uint32_t* p_bno;
int r = file_block_walk(f, filebno, &p_bno, 1);
//when error happen,the return for file_block_walk is the same as file_get_block
if(r) return r;
//
if (*p_bno == 0) {
if ((r = alloc_block()) < 0)
return -E_NO_DISK;
*p_bno = r;
//clear
memset(diskaddr(r), 0, BLKSIZE);
flush_block(diskaddr(r));
}
*blk = diskaddr(*p_bno);
return 0;
}
测试通过:
The file system interface
现在文件系统进程内部有了有了必要的函数,我们必须让其他希望能够使用文件系统的进程能够访问到这些函数,因为其他进程不能直接调用文件系统进程内部的函数,所以我们将通过构建在JOS IPC机制之上的远程过程调用(RPC)、抽象来公开对文件系统环境的访问。从图形上看,下面是其他进程对文件系统服务(比如read)的调用:
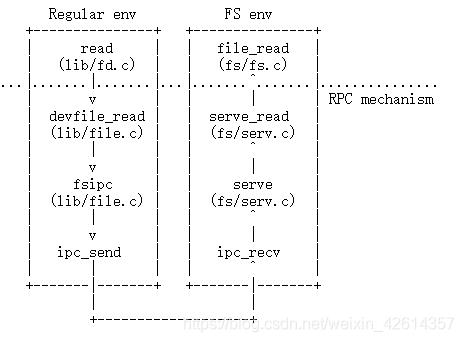
虚线下方的所有内容仅是将读取请求从普通进程获取到文件系统进程的机制。从一开始,read就可以在任何文件描述符上工作,并简单地分派到适当的设备读取功能,在这种情况下为devfile_read(我们可以有更多设备类型,例如管道)。 devfile_read实现专门针对磁盘文件的读取。 lib / file.c中的此函数和其他devfile_ *函数实现了FS操作的客户端,并且所有工作都以大致相同的方式进行,将参数捆绑在请求结构中,调用fsipc发送IPC请求,然后解包并返回结果。 fsipc函数仅处理将请求发送到服务器并接收答复的常见细节。
文件系统服务器代码可以在fs / serv.c中找到。它循环调用serve,无休止地通过IPC接收请求,将该请求分派到适当的处理函数,然后通过IPC发送回结果。在读取示例中,serve将分派到serve_read,该服务将处理特定于读取请求的IPC详细信息,例如解压缩请求结构并最终调用file_read来实际执行文件读取。
回想一下,JOS的IPC机制使环境可以发送单个32位数字,并可以选择性地发送共享页面。要将请求从客户端发送到服务器,我们使用32位数字作为请求类型(对文件系统服务器RPC进行编号,就像对系统调用进行编号一样),并将请求的参数存储在联合Fsipc上,而Fsipc就存储在IPC共享的页面上。在客户端,我们总是在fsipcbuf上共享页面;在服务器端,我们将传入的请求页面映射到fsreq(0x0ffff000)。
服务器还通过IPC发送回响应。我们使用32位数字作为函数的返回码。对于大多数RPC,这就是它们返回的全部。 FSREQ_READ和FSREQ_STAT也返回数据,它们将它们简单地写入客户端发送其请求的页面。无需在响应IPC中发送此页面,因为客户端首先将其与文件系统服务器共享。同样,在响应中,FSREQ_OPEN与客户端共享一个新的“ Fd页面”。
exercise 5:在fs / serv.c中实现serve_read。serve_read的繁重工作将由fs / fs.c中已经实现的file_read(反过来,这只是对file_get_block的一堆调用)完成。 serve_read只需提供RPC接口即可读取文件。 查看serve_set_size中的注释和代码,以大致了解服务器功能的结构。使用make grade测试您的代码。 您的代码应通过“ serve_open / file_stat / file_close”和“ file_read”,得分为70/150。
int serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// Lab 5: Your code here:
//return 0;
struct OpenFile *o;
int r;
if((r = openfile_lookup(envid, req->req_fileid, &o)) < 0) return r;
if((r = file_read(o->o_file,ret->ret_buf, req->req_n, o->o_fd->fd_offset))<0) return r;
//update the offset
o->o_fd->fd_offset += r;
return r;
}
测试通过:
![]()
exercise 6:在fs / serv.c中实现serve_write,在lib / file.c中实现devfile_write。使用make grade测试您的代码。 您的代码应通过“ file_write”,“ file_write之后的file_read”,“ open”和“大文件”,得分为90/150。
这两个函数的实现可以参考devfile_read和serve_read。
代码:
int serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// LAB 5: Your code here.
//panic("serve_write not implemented");
//It is very similarly with the read one
struct OpenFile *o;
int r;
if((r = openfile_lookup(envid,req->req_fileid,&o))<0)
return r;
if((r = file_write(o->o_file,req->req_buf,req->req_n,o->o_fd->fd_offset))<0)
return r;
o->o_fd->fd_offset += r;
return r;
}
devfile_write与devfile_read的不同之处在于,devfile_write先将内容写到fsipcbuf.write.req_buf中,再调用的fsipc,而devfile_read是先执行了fsipc之后再将fsipcbuf.write.req_buf中的数据写入到buf中。
static ssize_t devfile_write(struct Fd *fd, const void *buf, size_t n)
{
// Make an FSREQ_WRITE request to the file system server. Be
// careful: fsipcbuf.write.req_buf is only so large, but
// remember that write is always allowed to write *fewer*
// bytes than requested.
// LAB 5: Your code here
//panic("devfile_write not implemented");
int r;
//set the target id to the fd_file
fsipcbuf.write.req_fileid = fd->fd_file.id;
//write is always allowed to write *fewer* bytes than requested.
fsipcbuf.write.req_n = MIN(sizeof(fsipcbuf.write.req_buf),n);
memmove(fsipcbuf.write.req_buf,buf,fsipcbuf.write.req_n);
if((r = fsipc(FSREQ_WRITE, NULL))<0) return r;
assert(r <= n);
assert(r <= PGSIZE);
return r;
}
测试通过:
Spawning Processes
lib / spawn.c中已经给出了spawn的代码,该代码创建一个新进程,将文件系统中的程序映像加载到其中,然后启动运行该程序的子进程。 然后,父进程将独立于子进程继续运行。 在UNIX中,spawn函数的作用类似于fork后,让子进程中立即执行exec。
我们实现了spawn而不是UNIX风格的exec,因为spawn更容易从用户空间以“ 外内核方式”实现,而无需内核的特殊帮助。
exercise 7:spawn依赖新的系统调用sys_env_set_trapframe来初始化新创建的环境的状态。 在kern / syscall.c中实现sys_env_set_trapframe(不要忘记在syscall函数(kern/syscall.c)中添加新的系统调用)。运行kern / init.c中的user / spawnhello程序来测试您的代码,该程序将尝试从文件系统中生成/hello。使用make grade来测试代码.
static int sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
// LAB 5: Your code here.
// Remember to check whether the user has supplied us with a good
// address!
//panic("sys_env_set_trapframe not implemented");
int r;
struct Env* env;
//check and init the env
if((r = envid2env(envid,&env,1))<0) return r;
//check whether the user has supplied us with a good address!
user_mem_assert(env,tf,sizeof(struct Trapframe),PTE_U);
//CPL = 3
tf->tf_cs |= 3
//IPOL = 0
tf->tf_eflags &= ~FL_IOPL_3;
//interrupts enabled
tf->tf_eflags |= FL_IF;
env->env_tf = *tf;
return 0;
}
测试:(通过)
![]()
Sharing library state across fork and spawn
UNIX文件描述符是一个通用概念,还包含管道,控制台I / O等。在JOS中,这些设备类型中的每一个都有对应的struct Dev,以及指向实现读/写/等功能的指针。针对该设备类型。 lib / fd.c在此之上实现了通用的类似UNIX的文件描述符接口。每个struct Fd都指示其设备类型,并且lib / fd.c中的大多数函数只是将操作分派给相应的struct Dev中的函数。
lib / fd.c还从FDTABLE开始在每个应用程序进程的地址空间中维护文件描述符表区域。该区域为应用程序可以同时打开的最多MAXFD(当前为32个)文件描述符中的每个文件保留一个页面的地址空间(4KB)。在任何给定时间,当且仅当使用相应的文件描述符时,才会映射特定的文件描述符表页面(映射的文件描述符页面与文件系统进程的文件描述符页面共享同一个物理页)。每个文件描述符在从FILEDATA开始的区域中还具有一个可选的“数据页”,设备可以选择使用它们。
我们希望跨fork和spawn共享文件描述符状态,但是文件描述符状态保留在用户空间内存中。现在,在fork时,内存将被标记为写时复制,因此状态将被复制而不是共享。 (这意味着进程将无法在自身未打开的文件中进行搜索,并且管道将无法在fork上工作,我的理解是复制了新页导致子进程的文件描述符页面不再与文件系统进程的文件描述符页面共享更新),在spawn时,内存根本不会被复制。 (spawn创建的子进程在开始时没有打开的文件描述符。)
我们将更改fork,以确定“library operating system”使用的内存区域应该总是共享的。我们将在页表条目中设置一个未使用的位,而不是在某个地方硬编码一个区域列表(就像我们在fork中使用PTE_COW位一样)。
我们在inc / lib.h中定义了一个新的PTE_SHARE位。该位是Intel和AMD手册中标记为“可用于软件使用”的三个PTE位之一。我们将建立一个约定,如果页表条目设置了该位,则应该在fork和spawn中将PTE直接从父进程复制到子进程。请注意,这与将其标记为“写时复制”不同:如第一段所述,我们要确保共享页面更新。
exercise 8: 在lib / fork.c中更改duppage以遵循新约定。如果页表项设置了PTE_SHARE位,则只需直接复制映射。 (应该使用PTE_SYSCALL而不是0xfff来掩盖页表条目中的相关位。0xfff也会设置访问位和脏位。)
同样,在lib / spawn.c中实现copy_shared_pages。它应该遍历当前进程中的所有页表条目(就像fork一样),将所有已设置PTE_SHARE位的页映射复制到子进程中。
static int copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
//return 0;
//for (every page)
for(int s = 0;s*PGSIZE<USTACKTOP;s++){
if((uvpd[(s>>10)]&PTE_P)&&(uvpt[s]&PTE_P) && (uvpt[s]&PTE_SHARE)){
int r = sys_page_map(sys_getenvid(),(void*)(s*PGSIZE),child,(void*)(s*PGSIZE),uvpt[s]&PTE_SYSCALL);
if(r < 0) return r;
}
}
return 0;
}
static int duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
//panic("duppage not implemented");
//If the page is writable or copy-on-write,the new mapping must be created copy-on-write, and then our mapping must be marked copy-on-write as well.
if(uvpt[pn] & (PTE_W | PTE_COW) && !(uvpt[pn]&PTE_SHARE)){
//map child page
if((r = sys_page_map(sys_getenvid(),(void *)(pn*PGSIZE),envid,(void *)(pn*PGSIZE),PTE_P | PTE_U | PTE_COW)) <0)
return r;
//map parent page
if((r =sys_page_map(sys_getenvid(),(void *)(pn*PGSIZE),sys_getenvid(),(void *)(pn*PGSIZE),PTE_P | PTE_U | PTE_COW)) <0)
return r;
}
else{
int perm = uvpt[pn]&PTE_SHARE ? uvpt[pn]&PTE_SYSCALL : PTE_P|PTE_U;
if((r = sys_page_map(sys_getenvid(),(void *)(pn*PGSIZE),envid,(void *)(pn*PGSIZE),perm)) <0)
return r;
}
return 0;
}
The keyboard interface
要让shell工作,我们需要一种方法来键入它。QEMU一直在显示我们写入到CGA显示器和串行端口的输出,但到目前为止,我们只在内核监视器中接受输入。在QEMU中,在图形化窗口中键入的输入显示为从键盘到JOS的输入,而在控制台中键入的输入显示为串行端口上的字符。kern/console.c已经包含了自lab1以来内核监视器一直使用的键盘和串行驱动程序,但是现在需要将它们附加到系统的其他部分。
exercise 9:在kern/trap.c中,调用kbd_intr处理trap IRQ_OFFSET+IRQ_KBD, 调用serial_intr处理IRQ_OFFSET+IRQ_SERIAL.
我们在lib/console.c中实现控制台输入/输出文件类型。kbd_intr和serial_intr用最近读取的输入填充缓冲区,而控制台文件类型耗尽缓冲区 (控制台文件类型默认用于stdin/stdout,除非用户重定向它们)
通过运行make run-testkbd并键入几行代码来测试。系统应该在您键入行之后将您的输入返回给您。如果有可用的控制台和图形窗口,请同时在这两个窗口中输入。
代码:
// Handle keyboard and serial interrupts.
// LAB 5: Your code here.
if(tf->tf_trapno == IRQ_OFFSET + IRQ_KBD){
kbd_intr();
return;
}
if(tf->tf_trapno == IRQ_OFFSET + IRQ_SERIAL){
serial_intr();
return;
}
Exercise 10. shell不支持I/O重定向。运行sh
代码:
// LAB 5: Your code here.
//panic("< redirection not implemented");
int fd = open(t,O_RDONLY);
if(fd<0)
{
cprintf("case <:open err - %e\n",fd);
exit();
}
else if(fd)
{
dup(fd,0); //将fd与其struct fd的映射关系复制到fd 0处
close(fd);//关闭fd
}
break;
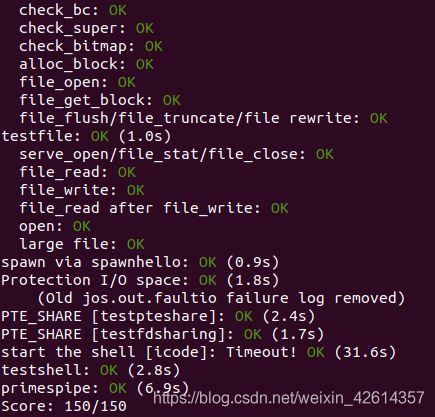
测试结果:(通过)
至此lab5结束。