并发编程—ForkJoin分治思想
前言:ForkJoin框架包含ForkJoinTask、ForkJoinWorkerThread、ForkJoinPool 和若干ForkJoinTask的子类,核心在于 分治 和 工作窍取,最大程度利用线程池中的工作线程,避免忙的忙死,饿的饿死。
文章重点讲解:ForkJoinPool、ForkJoinTask的使用
一、什么是ForkJoin
简单理解:一个大需求,通常是由多个开发人员一起开发,每个开发人员只负责其中一小部分需求,开发完成后,最后把每个人开发的模块合并到master分支。
分工合作,将大需求拆分为n个小需求,最后将各个小需求的开发结果合并到一个总结果上!
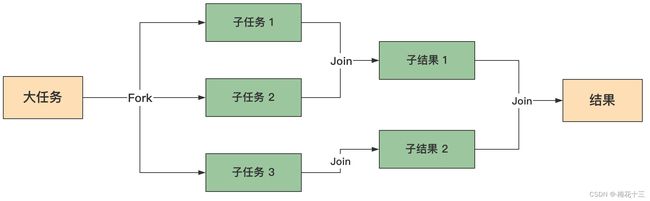
ForkJoinPool 是JDK7引入的线程池,核心思想是将一个大的任务拆分成n个小任务(即fork),然后在将多个小任务处理汇总到一个结果上(即join)可理解为:大事化小,小事化了,图解如下:
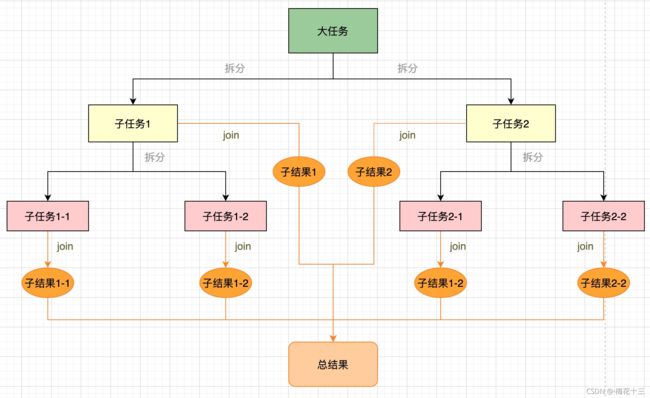
★ 分治原理
特点:充分利用多核cpu的优势,把一个大任务拆分成多个 “小任务”,每个小任务可以由不同的CPU或同一CPU上的不同线程执行;当多个 “小任务” 执行完后,再将执行结果合并起来
每一个线程有任务后,如果任务足够小,就直接执行任务逻辑,如果不够小,就会去拆分为两个独立的子任务,通过fork方法不断拆解,直到能够计算为止,然后按照层级去执行,从拆分后最小的层级执行完任务,一层层向上回收任务结果,再将这些结果用join合并。逐次递归。
★ 工作窃取
每个线程都维护自己的工作队列。这是一个双端队列,既可以先进先出(队列头部获取任务),也可以后进先出(队列尾部获取任务)。队列两端都可做出队操作。

原理: 线程工作时,从自己队列的队尾获取任务来执行(LIFO后进先出),没有任务时,会尝试随机窃取其它有任务的工作线程的队列头部,获取任务执行(FIFO先进先出)。
工作线程获取自己队列任务和窃取别人任务的方式不同。这能减少竞争。 fork采用LIFO,保证了队列头部任务都会是更大的任务,尾部是分解出来的子任务。窃取采用FIFO,窃取更大的任务有助于本次窃取的性价比很高。
▎常用方法
如果一个任务足够小,则执行任务逻辑。如果不够小,则拆分为两个独立的子任务。子任务执行后, 取得两个子任务的执行结果进行合并。
ForkJoinPool 通过 submit 执行 ForkJoinTask 类型的任务;不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
- RecursiveAction:递归事件,无返回值
- RecurisiveTask: 递归任务,有返回值(如果需要返回结果,则继承此类即可)
☛ 举例说明:累加 1-10亿之间的和
如何快速累加 1-10亿之间的和,本文将讲述3种方法,充分向读者展示每种方法的利弊
① 方式一:最普通的方法 for 循环
public static void main(String[] args) {
// 求和 1-10亿
Long sum = 0L;
long start = System.currentTimeMillis();
for (Long i = 1L; i <= 10_0000_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 执行毫秒:"+(end-start));
}执行结果:执行速度跟自身的电脑配置有关,作者是8核CPU
② 方式二:高端一点使用ForkJoin
a. 先定义ForkDemo类,计算结果:
/**
使用ForkJoin计算:1-10亿之间的和
1. 继承ForkJoinTask 的实现类:RecursiveTask<返回结果的类型>
2. 实现 compute()方法
3. 在compute方法中计算结果,任务大于临界值,则递归拆解任务,最后返回计算结果只和
*/
public class ForkJoinDemo extends RecursiveTask {
private Long start; // 开始值 1
private Long end; // 结束值 10_0000_0000
private Long temp = 10000L; // 临界值。当拆解的任务数大于临界值,则继续拆分成小任务
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 1.当拆解的任务大于临界点值,则继续拆解任务
if((end - start) > temp){
// a.将大任务拆解为2个小任务
long middle = (end + start) / 2;
// b.任务1 比如:累加1-100的和 ,任务1累加:1-50的和
ForkJoinDemo task1 = new ForkJoinDemo(start, middle);
task1.fork(); // 拆分任务,把任务压入线程队列
// c.任务2 比如:累加1-100的和 ,任务2累加:51-100的和
ForkJoinDemo task2 = new ForkJoinDemo(middle+1, end);
task2.fork();
// d.返回子任务的结果和
return task1.join() + task2.join();
// 2.当拆解的任务小于临界点值,直接计算并返回最后结果
}else{
Long sum = 0L;
for(Long i=start; i<=end; i++){
sum+=i;
}
return sum;
}
}
} b. 编写测试类,调用计算方法:
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
// 1. 初始化一个线程池
ForkJoinPool pool = new ForkJoinPool();
// 2. 将任务提交到池中 (开始值:1 结束值:10_0000_0000)
ForkJoinTask result = pool.submit(new ForkJoinDemo(1L, 10_0000_0000L));
// 3. 获取结果(可能会阻塞)
Long sum = result.get();
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 执行毫秒:"+(end-start));
}
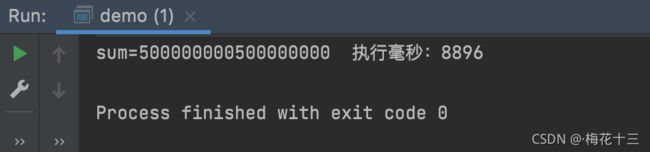
执行结果:执行速度会比for循环要快2秒
③ 方式三:终极计算——使用Stream流式计算
public static void main(String[] args){
long start = System.currentTimeMillis();
long sum = LongStream.rangeClosed(1L, 10_0000_0000L).reduce(0, (a, b) -> a + b);
long end = System.currentTimeMillis();
System.out.println("sum="+sum+" 执行毫秒:"+(end-start));
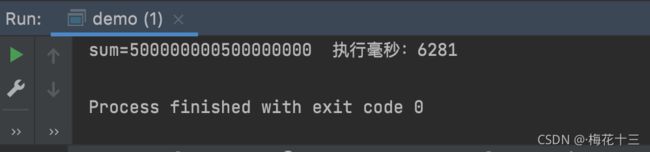
}执行结果:速度得到了质的飞跃

LongStream 是Java8推出的流式计算中的一种
rangeClosed(long startInclusive, final long endInclusive)返回的是一个有序的LongStream。包含开始节点和结束节点两个参数之间所有的参数,间隔为1,例如rangeClosed(1,3)返回的是:1,2,3
reduce 合并流的元素并产生单个值。long reduce(long identity, LongBinaryOperator op),identity表示默认值或初始值,函数式接口,取两个值并产生一个新值。(注: java Function 函数中的 BinaryOperator 接口用于执行 lambda 表达式并返回一个 T 类型的返回值)
注意:不清楚函数式接口和Stream流式计算的小伙伴,可去参考我的博文前2篇文章,有做详细的说明和使用,这里就不贴出链接了。
扩展:上述流式方式是属于顺序流,如果要想速度更快,可以加上parallel方法生成并行流:

执行结果:比顺序流快了一倍,0.3秒!
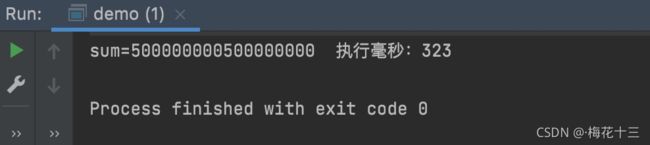
说明:并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样在使用流处理数据规模较大的集合对象时可以充分的利用多核CPU来提高处理效率。
针对数据量小的,使用并行流反而比顺序流要更慢,比如:1到1000的整数求和。将流并行化所带来的额外开销比逻辑代码开销还大,所以要根据场景选择!
结论
ForkJoin对于大量的任务,可以充分利用资源,减少竞争,并且通过窃取算法。实现任务的负载均衡。但是对于较少的任务。多队列以及线程频繁的窃取会导致性能的急剧下降。针对阻塞时间久的任务,也不推荐使用,阻塞会占用线程资源。
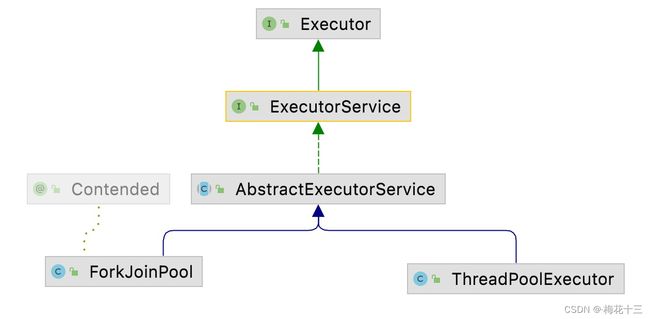
ForkJoinPool 和 ThreadPoolExecutor 区别
都是juc里面的线程池。其实现原理有很大的区别,FJ使用工作窃取算法。通过多个队列可以减少并发。而TP则是单个队列。
它和 ThreadPoolExecutor 都继承自 AbstractExecutorService,实现了 ExecutorService 和 Executor 接口。
❥ 怎么选择?
- FJ使用递归的思想,可以在任务执行的过程中将任务分解。而使用TP时,如果分解出来大量的任务,会导致更多的队列竞争。
- FJ对于大量的任务,可充分利用资源,减少竞争,并且通过窃取算法。实现任务的负载均衡。可以说FJ完全是通过工作窃取来驱动任务完成的。 对于较少的任务。多队列以及线程频繁的窃取会导致性能的急剧下降。
- 对于阻塞时间比较久的任务。更适合使用TP,毕竟阻塞会占用线程资源。我们需要更多的线程去处理任务。并且阻塞会降低队列的竞争。