Python数据处理及分析详解
一、Python环境搭建与配置
Python作为一门优秀的编程语言,受到很多程序员和编程爱好者的青睐。近年来,Python还在办公领域大展拳脚,许多白领纷纷加入了学习Python的行列。这是因为Python在数据的采集、处理、分析与可视化方面有着独特的优势,能够帮助职场人士从容应对大数据时代的挑战。
要想编写和运行Python代码,需要在计算机中搭建Python的编程环境,并安装相关的第三方模块。
1、Python编程环境的搭建
使用Anaconda和PyCharm来搭建Python的编程环境。
Anaconda是Python的一个发行版本,安装好了Anaconda就相当于安装好了Python,并且它里面还集成了很多大数据分析与科学计算的第三方模块,如NumPy、pandas、Matplotlib等。
PyCharm则是一款Python代码编辑器,它比Anaconda自带的两款编辑器Spyder和Jupyter Notebook更好用。
下面就一起来学习Anaconda和PyCharm的下载、安装与设置方法。
1. 安装与配置Anaconda
步骤1:在浏览器中打开网址
https://www.anaconda.com/products/individual,进入Anaconda的下载页面,向下滚动页面,在“Anaconda Installers”栏目中可看到与不同类型的计算机操作系统对应的安装包,这里选择适用于64位Windows系统的Python 3.8版本,如下图所示。

如果官网下载速度较慢,可以到清华大学开源软件镜像站下载安装包,网址为:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
步骤2:安装包下载完毕后,双击安装包,在打开的安装界面中无须更改任何设置,直接进入下一步。如果要将程序安装在默认路径下,直接单击“Next”按钮,如下左图所示。如果想要改变安装路径,可单击“Browse”按钮,在打开的对话框中选择安装路径,建议使用默认路径。
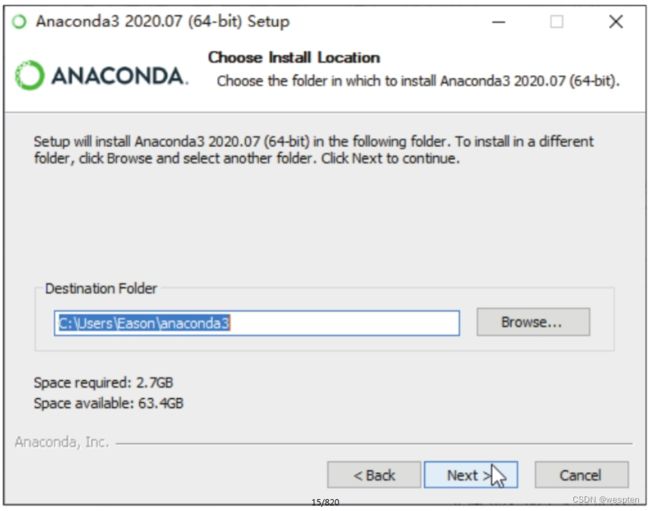
步骤3:在新的安装界面中勾选“Advanced Options”选项组下的两个复选框,单击“Install”按钮,如下图所示。

步骤4:随后可看到Anaconda的安装进度,等待一段时间,如果窗口中出现“Installation Complete”的提示文字,说明Anaconda安装成功,直接单击“Next”按钮,如下图所示。

步骤5:在后续的安装界面中也无须更改设置,直接单击“Next”按钮。当跳转到如下右图所示的界面时,取消勾选两个复选框,单击“Finish”按钮,即可完成Anaconda的安装。

步骤6:单击桌面左下角的“开始”按钮,在打开的“开始”菜单中单击“Anaconda3(64-bit)”文件夹,在展开的列表中可看到Anaconda自带的编辑器Jupyter Notebook和Spyder,如下图所示。

其中,Jupyter Notebook可在线编辑和运行代码,是一款适合初学者和教育工作者的优秀编辑器。Spyder则提供一些非常漂亮的可视化选项,可以让数据看起来更加简洁。
2. 安装与配置PyCharm
步骤1:在浏览器中打开网址https://www.jetbrains.com/pycharm/download/,进入PyCharm的下载页面,默认显示的是适用于Windows操作系统的PyCharm安装包,这里选择下载免费的Community版,如下图所示。在新页面下方弹出的下载提示框中单击“保存”按钮,即可开始下载PyCharm安装包。

如果操作系统是macOS或Linux,则需先单击“Mac”或“Linux”按钮切换操作系统,再下载安装包。此外,从2019.1版开始,PyCharm不再支持32位操作系统,如果需要在32位操作系统中安装PyCharm,可单击下载页面左侧的“Other versions”链接,下载2018.3版PyCharm。
步骤2:安装包下载完毕后,双击安装包,在打开的安装界面中直接单击“Next”按钮。
步骤3:跳转到新的安装界面,单击“Browse”按钮,在打开的对话框中设置自定义的安装路径,也可以直接在文本框中输入自定义的安装路径。然后单击“Next”按钮,如下图所示。
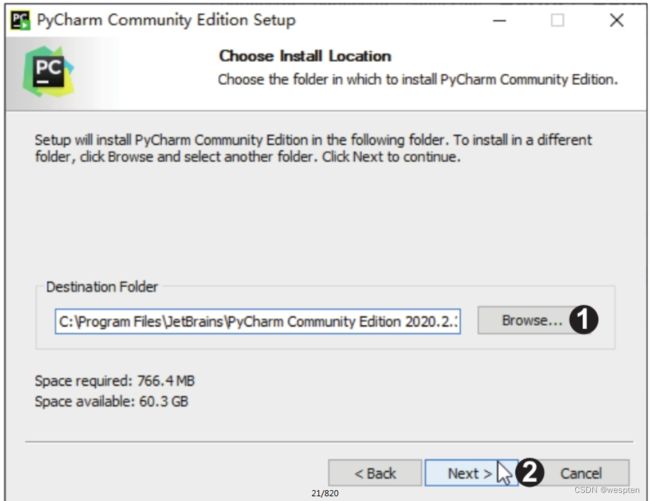
步骤4:在新的安装界面中勾选“64-bit launcher”复选框,然后勾选“.py”复选框,单击“Next”按钮,如下图所示。

步骤5:在新的安装界面中不做任何设置,直接单击“Install”按钮,如下图所示。随后可看到PyCharm的安装进度,安装完成后单击“Finish”按钮结束安装。

步骤6:初次启用PyCharm时需要进行一些设置。运行PyCharm,在打开的对话框中单击“Do not import settings”单选按钮,单击“OK”按钮,如下图所示。在打开的对话框中选择“Light”主题风格,单击“Next: Featured plugins”按钮,在新的界面中不做任何设置,直接单击“Start using PyCharm”按钮。

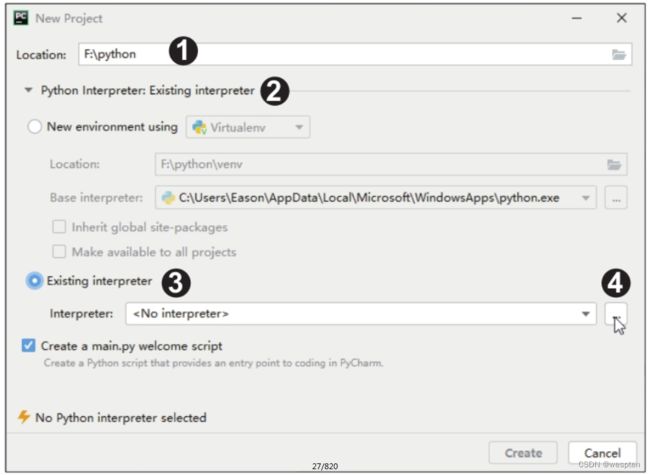
步骤7:完成设置后,在界面中单击“New Project”按钮,创建Python项目文件,如下图所示。

步骤8:在新界面的“Location”后设置项目文件夹的位置和名称,此处设置为“F:\python”,单击下方的折叠按钮,在展开的列表中单击“Existing interpreter”单选按钮,此时“Interpreter”显示为“
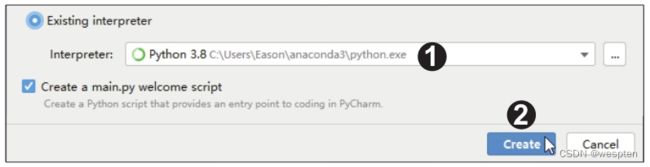
步骤9:在打开的对话框中单击“System Interpreter”选项,此时右侧的“Interpreter”列表框中自动列出了Anaconda中的Python解释器,如果自动列出的解释器不是我们需要的,可以在下拉列表框中选择其他解释器,最后单击“OK”按钮,如下图所示。

步骤10:返回项目文件的创建界面,可看到“Interpreter”后显示了前面设置的Python解释器,单击“Create”按钮,如下图所示。随后等待界面跳转,在出现提示信息后,直接单击“Close”按钮,然后等待Python运行环境配置完成即可。
步骤11:完成配置后就可以开始编程。右击步骤8中创建的项目文件夹,在弹出的快捷菜单中单击“New>Python File”命令,如下图所示。在弹出的“New Python file”对话框中输入新建的Python文件的名称,如“hello python”,选择文件类型为“Python file”,按【Enter】键确认。

步骤12:文件创建成功后,进入如下图所示的界面,此时便可以编写程序了。在代码编辑区中输入代码“print('hello python')”,然后右击代码编辑区的空白区域或代码文件的标题栏,在弹出的快捷菜单中单击“Run 'hello python'”命令。如果右击后没有看到“Run 'hello python'”命令,说明步骤10中的Python运行环境配置还没完成,需等待几分钟再右击。

步骤13:随后在界面的下方可看到程序的运行结果“hello python”,如下图所示。

步骤14:如果想要设置代码的字体、字号和行距,单击菜单栏中的“File”按钮,在展开的菜单中单击“Settings”命令,如下图所示。

步骤15:在弹出的对话框中展开“Editor”选项组,在展开的列表中单击“Font”选项,在右侧的界面中按照自己的喜好设置“Font”“Size”“Line spacing”选项即可,如右图所示。完成设置后单击“OK”按钮。

2、Python的模块
Python最大的魅力之一就是拥有丰富的第三方模块,用户在编程时可以直接调用模块来实现强大的功能,无须自己编写复杂的代码。
下面就来学习Python模块的知识和安装方法。
1. 模块简介
如果要在多个程序中重复实现某一个特定功能,那么能不能直接在新程序中调用自己或他人已经编写好的代码,而不用在新程序中重复编写功能类似的代码呢?答案是肯定的,这就要用到Python中的模块。模块也可以称为库或包,简单来说,每一个以“.py”为扩展名的文件都可以称为一个模块。Python的模块主要分为下面3种。
1)内置模块
内置模块是指Python自带的模块,如sys、time、math等。
2)第三方的开源模块
通常所说的模块就是指开源模块,这类模块是由一些程序员或企业开发并免费分享给大家使用的,通常能实现某一个大类的功能。例如,xlwings模块就是专门用于控制Excel的模块。
Python之所以能风靡全球,其中一个很重要的原因就是它拥有很多第三方的开源模块,当我们要实现某种功能时就无须绞尽脑汁地编写基础代码,而是可以直接调用这些开源模块。第三方模块在使用前一般需要用户自行安装,而有些第三方模块会在安装编辑器(如PyCharm)时自动安装好。
3)自定义模块
Python用户可以将自己编写的代码或函数封装成模块,以方便在编写其他程序时调用,这样的模块就是自定义模块。需要注意的是,自定义模块不能和内置模块重名,否则将不能再导入内置模块。
2. 模块的安装
上述3种模块中最常用的就是内置模块和第三方的开源模块,并且第三方的开源模块在使用前需要安装。模块有两种常用的安装方式:一种是使用pip命令安装;一种是通过编辑器(如PyCharm)安装。下面以xlwings模块为例,介绍模块的两种安装方法。
1)用pip命令安装模块
pip是Python提供的一个命令,主要功能就是安装和卸载第三方模块。用pip命令安装模块的方法最简单也最常用,这种方法默认将模块安装在Python安装目录中的“site-packages”文件夹下。下面来学习用pip命令安装模块的具体方法。
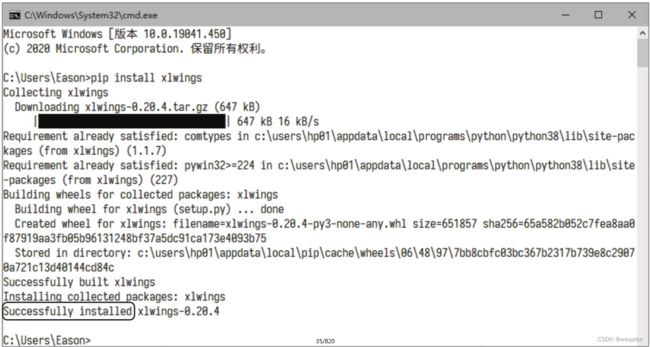
步骤1:按快捷键【Win+R】,在打开的“运行”对话框中输入“cmd”,再单击“确定”按钮,如下左图所示。此时会打开一个命令行窗口,输入命令“pip install xlwings”,如下右图所示。命令中的“xlwings”就是需要下载的模块名称,如果需要下载其他模块,可以将其修改为相应的模块名称。

步骤2:按【Enter】键,等待一段时间,如果出现“Successfully installed”的提示文字,说明模块安装成功,如下图所示。之后在编写代码时,就可以使用xlwings模块中的函数了。
技巧:通过镜像服务器安装模块
pip命令下载模块时默认访问的服务器设在国外,速度不稳定,可能会导致安装失败,大家也可以通过国内的一些企业、院校、科研机构设立的镜像服务器来安装模块。
例如,从清华大学的镜像服务器安装xlwings模块的命令为:
pip install xlwings -i https://pypi.tuna.tsinghua.edu.cn/simple命令中的“-i”是一个参数,用于指定pip命令下载模块的服务器地址:“https://pypi.tuna.tsinghua.edu.cn/simple”则是由清华大学设立的模块镜像服务器的地址,更多镜像服务器的地址读者可以自行搜索。
2)在PyCharm中安装模块
如果使用的编辑器是PyCharm,也可以直接在PyCharm中安装模块。下面仍以xlwings模块为例,详细介绍在PyCharm中安装模块的方法。
步骤1:启动PyCharm,单击菜单栏中的“File”按钮,在展开的菜单中单击“Settings”命令,如下图所示。
步骤2:在打开的“Settings”对话框中展开“Project: python”选项组,在展开的列表中单击“Project Interpreter”选项,在右侧的界面中可看到系统中已安装的模块,单击右侧的按钮,如下图所示。

步骤3:在打开的对话框中输入模块名,如“xlwings”,按【Enter】键,在搜索结果中选择要安装的模块,单击左下角的“Install Package”按钮,如下图所示。安装完成后关闭对话框。

随后在“Project Interpreter”选项右侧的界面中即可看到安装好的xlwings模块。需要注意的是,在安装一个模块时,有可能会同时安装一些该模块需要调用的其他模块,例如,在安装xlwings模块时,会同时安装comtypes和pywin32模块。
3. 模块的导入
要使用模块,就需要安装和导入模块。这里来讲解模块的两种导入方法:import语句导入法和from语句导入法。
1)import语句导入法
import语句导入法是导入模块的常规方法。该方法会导入指定模块中的所有函数,适用于需要使用指定模块中的大量函数的情况。
import语句的基本语法格式如下:import 模块名
演示代码如下:
import math # 导入math模块
import turtle # 导入turtle模块用该方法导入模块后,在后续编程中如果要调用模块中的函数,则要在函数名前面加上模块名的前缀,演示代码如下:
import math
a = math.sqrt(16)
print(a)第2行代码要调用math模块中的sqrt()函数来计算16的平方根,所以在sqrt()函数前加上了模块名math的前缀。运行结果如下:
4.02)from语句导入法
有些模块中的函数特别多,用import语句全部导入后会导致程序运行速度较慢,将程序打包后得到的文件体积也会很大。如果只需要使用模块中的少数几个函数,就可以采用from语句导入法,这种方法可以指定要导入的函数。
from语句的基本语法格式如下:from 模块名 import 函数名
演示代码如下:
from math import sqrt # 导入math模块中的单个函数
from turtle import forward, backward, right, left # 导入turtle模块中的多个函数使用该方法导入模块的最大优点就是在调用函数时可以直接写出函数名,无须添加模块名前缀,演示代码如下:
from math import sqrt # 导入math模块中的sqrt()函数
a = sqrt(16)
print(a)因为第1行代码中已经写明了要导入哪个模块中的哪个函数,所以第2行代码中就可以直接用函数名调用函数。
运行结果如下:
4.0这两种导入模块的方法各有优缺点,编程时根据实际需求选择即可。
此外,如果模块名或函数名很长,可以在导入时使用as保留字对它们进行简化,以方便后续代码的编写。
通常用模块名或函数名中的某几个字母来代替模块名或函数名,演示代码如下:
import numpy as np # 导入NumPy模块,并将其简写为np
from math import factorial as fc # 导入math模块中的factorial()函数,并将其简写为fc提示
使用from语句导入法时,如果将函数名用通配符“*”代替,写成“from 模块名 import *”,则和import语句导入法一样,会导入模块中的所有函数,演示代码如下:
from math import * # 导入math模块中的所有函数
a = sqrt(16)
print(a)这种方法的优点是在调用模块中的函数时无须添加模块名前缀,缺点是不能使用as保留字来简化函数名。
3、Python编码规范
1. 变量
变量是程序代码不可缺少的要素之一。简单来说,变量是一个代号,它代表的是一个数据。在Python中,定义一个变量的操作分为两步:首先要为变量起一个名字,称为变量的命名;然后要为变量指定其所代表的数据,称为变量的赋值。这两个步骤在同一行代码中完成。
变量的命名要遵循如下规则:
● 变量名可以由任意数量的字母、数字、下划线组合而成,但是必须以字母或下划线开头,不能以数字开头。建议用英文字母开头,如a、b、c、a_1、b_1等。
● 不要用Python的保留字或内置函数来命名变量。例如,不要用import来命名变量,因为它是Python的保留字,有特殊的含义。
● 变量名对英文字母区分大小写。例如,D和d是两个不同的变量。
● 建议使用英文字母和数字组成变量名,并且变量名要有一定的意义,能直观地描述变量所代表的数据内容。例如,用变量name代表姓名数据,用变量age代表年龄数据,等等。
变量的赋值用等号“=”来完成,“=”的左边是一个变量,右边是该变量所代表的值。Python有多种数据类型,但在定义变量时并不需要指明变量的数据类型,在变量赋值的过程中,Python会自动根据所赋的值的类型来确定变量的数据类型。
定义变量的演示代码如下:
x = 1
print(x)
y = x + 25
print(y)上述代码中的x和y就是变量。第1行代码表示定义一个名为x的变量,并赋值为1;第2行代码表示输出变量x的值;第3行代码表示定义一个名为y的变量,并将变量x的值与25相加后的结果赋给变量y;第4行代码表示输出变量y的值。
代码的运行结果如下:
1
26第2行和第4行代码中用到的print()函数是Python的一个内置函数,用于输出信息,以后会经常用这个函数来输出结果。
2. 缩进
缩进是Python中非常重要的一个知识点,类似于Word的首行缩进。如果缩进不规范,代码在运行时就会报错。缩进的快捷键是【Tab】键,在if、for、while等语句中都会用到缩进。
先来看下面的代码:
1 x = 10
2 if x > 0:
3 print('正数')
4 else:
5 print('负数')第2~5行代码是之后会讲到的if语句,其中,if表示“如果”,else表示“否则”,将上述代码翻译成中文就是:
1 让x等于10
2 如果x大于0:
3 输出字符串'正数'
4 否则:
5 输出字符串'负数'在输入第3行和第5行代码之前,必须按【Tab】键来缩进,否则运行代码时会报错。
如果要减小缩进量,可按快捷键【Shift+Tab】。如果要同时调整多行代码的缩进量,可选中要调整的多行代码,按【Tab】键统一增加缩进量,按快捷键【Shift+Tab】统一减小缩进量。
3. 注释
注释是对代码的解释和说明,Python代码的注释分为单行注释和多行注释两种。
1)单行注释
单行注释以“#”号开头,其可以放在被注释代码的后面,也可以作为单独的一行放在被注释代码的上方。
放在被注释代码后的单行注释的演示代码如下:
1 a = 1
2 b = 2
3 if a == b: # 注意表达式里是两个等号
4 print('a和b相等')
5 else:
6 print('a和b不相等')运行结果如下:
1 a和b不相等第3行代码中“#”号后的内容就是注释内容,它不参与程序的运行。上述代码中的注释也可放在被注释代码的上方,演示代码如下:
1 a = 1
2 b = 2
3 # 注意表达式里是两个等号
4 if a == b:
5 print('a和b相等')
6 else:
7 print('a和b不相等')为了增强代码的可读性,建议在编写单行注释时遵循以下规范:
- 单行注释放在被注释代码上方时,在“#”号之后先输入一个空格,再输入注释内容;
- 单行注释放在被注释代码后面时,“#”号和代码之间至少要有两个空格,“#”号与注释内容之间也要有一个空格。
2)多行注释
当注释内容较多,放在一行中不便于阅读时,可以使用多行注释。在Python中,使用3个单引号或3个双引号将多行注释的内容括起来。
用3个单引号表示多行注释的演示代码如下:
1 '''
2 这是多行注释,用3个单引号
3 这是多行注释,用3个单引号
4 这是多行注释,用3个单引号
5 '''
6 print('Hello, Python!')第1~5行代码就是注释,不参与运行,所以运行结果如下:
1 Hello, Python!用3个双引号表示多行注释的演示代码如下:
1 """
2 这是多行注释,用3个双引号
3 这是多行注释,用3个双引号
4 这是多行注释,用3个双引号
5 """
6 print('Hello, Python!')第1~5行代码也是注释,不参与运行,所以运行结果如下:
1 Hello, Python!技巧:注释在程序调试中的妙用
在调试程序时,如果有暂时不需要运行的代码,不必将其删除,可以先将其转换为注释,等调试结束后再取消注释,这样能减少代码输入的工作量。
二、NumPy模块
NumPy模块是Python语言的一个科学计算的第三方模块,其名字由“Numerical Python”缩写而来。NumPy模块可以构建多维数据的容器,将各种类型的数据快速地整合在一起,完成多维数据的计算及大型矩阵的存储和处理。因此,Python中的很多模块都是在NumPy模块的基础上编写的。
1、创建数组
NumPy模块最主要的特点就是引入了数组的概念。数组是一些相同类型的数据的集合,这些数据按照一定的顺序排列,并且每个数据占用大小相同的存储空间。要使用数组组织数据,首先就要创建数组。NumPy模块提供多种创建数组的方法,创建的数组类型也多种多样,下面就来学习创建数组的方法。
1)使用array()函数创建数组
代码文件:使用array()函数创建数组.py
创建数组最常用的方法是使用array()函数,该函数可基于序列型的对象(如列表、元组、集合等,还可以是一个已创建好的数组)创建任意维度的数组。下面先来学习如何基于列表创建一维数组,演示代码如下:
1 import numpy as np
2 a = np.array([1, 2, 3, 4])
3 b = np.array(['产品编号', '销售数量', '销售单价', '销售金额'])
4 print(a)
5 print(b)第1行代码表示导入NumPy模块,并简写为np,这是为了之后能更方便地调用模块中的函数。第2行和第3行代码使用array()函数基于列表创建一维数组。需要注意的是,同一个数组中各元素的数据类型必须相同,如a的元素全是整型数字,b的元素则全是字符串。
代码运行结果如下:
1 [1 2 3 4]
2 ['产品编号' '销售数量' '销售单价' '销售金额']从运行结果可以看出,数组中的元素是通过空格分隔的。
上面介绍的是一维数组的创建方法,如果要创建多维数组,可以为array()函数传入一个嵌套列表作为参数。
演示代码如下:
1 import numpy as np
2 c = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
3 print(c)代码运行结果如下:
1 [[1 2 3]
2 [4 5 6]
3 [7 8 9]]可以看到,创建的数组c是一个3行3列的二维数组。
上面演示的是array()函数最简单和最基本的用法,下面详细介绍该函数的语法格式和参数含义,大家简单了解即可。
array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)参数说明见下表:

2)创建等差数组
代码文件:创建等差数组.py
如果要创建的数组中的元素能构成一个等差序列,那么使用arange()函数创建数组会更加方便,演示代码如下:
1 import numpy as np
2 d = np.arange(1, 20, 4)
3 print(d)第2行代码表示生成一个起始值为1、结束值为20(结果不含该值)、步长为4的等差序列,然后用这个等差序列创建一个一维数组。
代码运行结果如下:
1 [ 1 5 9 13 17]如果省略arange()函数的第3个参数,则步长默认为1。演示代码如下:
1 import numpy as np
2 d = np.arange(1, 20)
3 print(d)第2行代码表示生成一个起始值为1、结束值为20(结果不含该值)、步长为1的等差序列,然后用这个等差序列创建一个一维数组。
代码运行结果如下:
1 [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]如果只在arange()函数的括号里输入1个参数,则arange()函数将此参数作为结束值,起始值默认为0,步长默认为1。
演示代码如下:
1 import numpy as np
2 d = np.arange(20)
3 print(d)第2行代码表示生成一个起始值为0、结束值为20(结果不含该值)、步长为1的等差序列,然后用这个等差序列创建一个一维数组。
代码运行结果如下:
1 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]下面详细介绍一下arange()函数的语法格式和参数含义。
arange(start, stop, step, dtype=None)参数说明见下表:

3)创建随机数组
代码文件:创建随机数组.py
如果要创建以随机数为元素的数组,可使用NumPy模块的子模块random中的函数,主要有rand()函数、randn()函数、randint()函数。下面分别来学习使用这3个函数创建随机数组的方法。
- rand()函数
用rand()函数创建的数组中的每个元素都是[0,1)区间内的随机数。演示代码如下:
1 import numpy as np
2 e = np.random.rand(3)
3 print(e)第2行代码表示创建一个有3个元素的一维数组,其元素为位于[0,1)区间内的随机数。
代码运行结果如下:
1 [0.52629764 0.60120953 0.928765 ]如果给rand()函数传入一对参数值,就会生成一个相应行、列数的二维数组,且数组的元素为位于[0,1)区间内的随机数。
演示代码如下:
1 import numpy as np
2 e = np.random.rand(2, 3)
3 print(e)第2行代码表示生成一个2行3列的二维数组,其元素为位于[0,1)区间内的随机数。
代码运行结果如下:
1 [[0.47760649 0.77905762 0.44320408]
2 [0.33504138 0.95236697 0.12665502]]- randn()函数
用randn()函数创建的数组中的元素是符合标准正态分布(均值为0,标准差为1)的随机数。
演示代码如下:
1 import numpy as np
2 e = np.random.randn(3)
3 print(e)第2行代码表示创建一个有3个元素的一维数组,这3个元素为符合标准正态分布的随机数。代码运行结果如下:
1 [0.53532424 1.21974306 0.16032314]如果给randn()函数传入一对参数值,则会生成相应行、列数的二维数组,且数组元素符合标准正态分布。
演示代码如下:
1 import numpy as np
2 e = np.random.randn(3, 3)
3 print(e)第2行代码表示创建一个3行3列的二维数组,数组元素为符合标准正态分布的随机数。代码运行结果如下:
1 [[ 0.28850844 0.9403601 -1.53854975]
2 [-2.28107582 1.06579641 0.69591266]
3 [-0.8554639 -0.28063843 -0.5227256 ]]- randint()函数
用randint()函数创建的数组中的元素是指定范围内的随机整数。演示代码如下:
1 import numpy as np
2 e = np.random.randint(1, 5, 10)
3 print(e)第2行代码表示创建一个有10个元素的一维数组,这10个元素是[1,5)区间内的随机整数。需要注意的是,这里生成的随机整数不包括5。
代码运行结果如下:
1 [4 2 2 2 2 2 1 3 2 1]使用randint()函数也可以创建二维的随机整数数组,演示代码如下:
1 import numpy as np
2 e = np.random.randint(1, 10, (4, 2))
3 print(e)第2行代码表示创建一个4行2列的二维数组,数组元素为[1,10)区间内的随机整数。代码运行结果如下:
1 [[6 6]
2 [9 4]
3 [3 2]
4 [9 7]]2、查看数组的属性
代码文件:查看数组的属性.py
数组的属性主要是指数组的行列数、元素个数、元素的数据类型、数组的维数。下面分别讲解这些属性的查看方法。
1)查看数组的行数和列数
数组的shape属性用于查看数组的行数和列数。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 print(arr.shape)第3行代码表示通过shape属性获取数组arr的行数和列数并打印输出。
代码运行结果如下:
1 (3, 2)从运行结果可以看出,数组arr为3行2列的数组。
通过shape属性获得的是一个元组,如果只想查看数组的行数或列数,可以通过从元组中提取元素来实现。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 print(arr.shape[0])
4 print(arr.shape[1])第3行代码中的shape[0]表示查看数组arr的行数,第4行代码中的shape[1]表示查看数组arr的列数。代码运行结果如下:
1 3
2 22)查看数组的元素个数
数组的size属性用于查看数组的大小,也就是数组的元素个数。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 print(arr.size)代码运行结果如下:
1 6运行结果表示数组arr一共有6个元素。
3)查看和转换数组元素的数据类型
数组的dtype属性用于查看数组元素的数据类型。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1.3, 2, 3.6, 4], [5, 6, 7.8, 8]])
3 print(arr.dtype)代码运行结果如下:
1 float64运行结果表示数组arr的元素的数据类型为浮点型数字。
如果数组元素的数据类型不能满足工作需要,可以使用astype()函数进行转换。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1.3, 2, 3.6, 4], [5, 6, 7.8, 8]])
3 arr1 = arr.astype(int)
4 print(arr1)
5 print(arr1.dtype)第2行代码创建了一个数组arr,其元素为浮点型数字。第3行代码使用astype()函数将数组arr中元素的数据类型转换为整型数字。第4行代码用于输出转换后的数组arr1。第5行代码用于查看数组arr1中元素的数据类型。
代码运行结果如下:
1 [[1 2 3 4]
2 [5 6 7 8]]
3 int32从运行结果可以看出,数组arr1中的元素都被取整了,并且数据类型由原来的浮点型数字变为了整型数字。
4)查看数组的维数
数组的维数是指数组是几维数组,可直接调用数组的ndim属性查看数组的维数。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 print(arr.ndim)代码运行结果如下:
1 2运行结果表示数组arr是二维数组。
3、选取数组元素
数组元素可以通过数组的索引值和切片功能来选取。主要讲解一维数组和二维数组中元素的选取方法。
1. 一维数组的元素选取
代码文件:一维数组的元素选取.py
一维数组的结构比较简单,数组元素的选取也比较简单。既可以选取单个元素,也可以选取多个连续的元素,还可以按照一定的规律选取多个不连续的元素。下面就来分别讲解具体的方法。
1)选取单个元素
在一维数组中选取单个元素的方法非常简单,直接根据数组元素的索引值来选取即可。演示代码如下:
1 import numpy as np
2 arr = np.array([12, 2, 40, 64, 56, 6, 57, 18, 95, 17, 21, 12])
3 print(arr[0])
4 print(arr[5])
5 print(arr[-1])
6 print(arr[-4])第3~6行代码的中括号[]中的数值为要选取的元素在数组中的索引值。其中,第3行和第4行代码使用的是正序索引,其值是从0开始计数的,即:第1个元素的索引值为0,第2个元素的索引值为1,第3个元素的索引值为2,依此类推。而第5行和第6行代码使用的是倒序索引,其值是从-1开始计数的,即:倒数第1个元素的索引值为-1,倒数第2个元素的索引值为-2,倒数第3个元素的索引值为-3,依此类推。
因此,第3行和第4行代码分别表示选取数组的第1个元素和第6个元素,第5行和第6行代码分别表示选取数组的倒数第1个元素和倒数第4个元素。
代码运行结果如下:
1 12
2 6
3 12
4 952)选取连续的元素
如果想要在一维数组中选取连续的多个元素,给出这些元素的起始位置和结束位置的索引值即可。需要注意的是,起始位置和结束位置的索引值构成的是一个“左闭右开”的区间,也就是说,选取起始位置的元素,但是不选取结束位置的元素。
演示代码如下:
1 import numpy as np
2 arr = np.array([12, 2, 40, 64, 56, 6, 57, 18, 95, 17, 21, 12])
3 print(arr[1:6])
4 print(arr[3:-2])
5 print(arr[:3])
6 print(arr[:-3])
7 print(arr[3:])
8 print(arr[-3:])第3行代码表示选取索引值1(第2个元素)到索引值6(第7个元素)之间的元素,但是不包含索引值6的这个元素。第4行代码表示选取索引值3(第4个元素)到索引值-2(倒数第2个元素)之间的元素,但是不包含索引值-2的这个元素。
第5行和第6行代码的“[]”中省略了区间的起始位置,只指明了结束位置,表示选取结束位置之前的所有元素,不包含结束位置的元素。第7行和第8行代码的“[]”中省略了区间的结束位置,只指明了起始位置,表示选取起始位置之后的所有元素,并包含起始位置的元素。
代码运行结果如下:
1 [ 2 40 64 56 6]
2 [64 56 6 57 18 95 17]
3 [12 2 40]
4 [12 2 40 64 56 6 57 18 95]
5 [64 56 6 57 18 95 17 21 12]
6 [17 21 12]3)选取不连续的元素
如果想要在指定的区间中每隔几个元素就选取一个元素,也可以通过数组切片的方式来实现。演示代码如下:
1 import numpy as np
2 arr = np.array([12, 2, 40, 64, 56, 6, 57, 18, 95, 17, 21, 12])
3 print(arr[1:5:2])
4 print(arr[5:1:-2])
5 print(arr[::3])
6 print(arr[3::])
7 print(arr[:3:])第3~7行代码的“[]”中都有两个冒号。其中,第1个冒号前和第2个冒号前的数值分别为数组元素的起始位置和结束位置,第2个冒号后的数值为步长,例如,第3行代码中第2个冒号后的数值2表示在每两个元素中选取1个元素(每隔1个元素选取1个元素)。如果步长为负值,则表示反向选取,例如,第4行代码中的-2也表示在每两个元素中选取1个元素(每隔1个元素选取1个元素),但要从后向前选取。
第5行代码中省略了起始位置和结束位置,步长3表示从头到尾在每3个元素中选取1个元素(每隔2个元素选取1个元素)。第6行代码省略了结束位置和步长,表示从起始位置选取至数组末尾,且在每1个元素中选取1个元素(每隔0个元素选取1个元素)。
第7行代码省略了起始位置和步长,表示选取结束位置之前的元素,且在每1个元素中选取1个元素(每隔0个元素选取1个元素)。
代码运行结果如下:
1 [ 2 64]
2 [ 6 64]
3 [12 64 57 17]
4 [64 56 6 57 18 95 17 21 12]
5 [12 2 40]2. 二维数组的元素选取
代码文件:二维数组的元素选取.py
二维数组中元素的选取与一维数组中元素的选取类似,也是基于索引值进行的,但要用英文逗号“,”分隔数组的行和列的索引值。
1)选取单个元素
如果要选取二维数组中的某个元素,直接传入元素在数组中的行和列的索引值即可。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
3 print(arr[1, 2])第3行代码表示选取数组arr中行索引值1(第2行)和列索引值2(第3列)的元素。代码运行结果如下:
1 62)选取单行或单列的元素
如果要选取二维数组中单行或单列的元素,直接指定这一行或这一列的索引位置即可。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
3 print(arr[2])
4 print(arr[:, 1])第3行代码表示选取数组arr中行索引值2(第3行)的元素。第4行代码表示选取数组arr中列索引值1(第2列)的元素。需要注意的是,在选取单列时,“[]”中的逗号前必须有一个冒号,当冒号前后没有参数时,表示选取所有行,随后再选取指定的列。其实在选取单行时,也可以在“[]”中输入逗号和冒号,也就是说第3行代码也可以写为print(arr[2, :])。
代码运行结果如下:
1 [7 8 9]
2 [ 2 5 8 11]3)选取某些行或某些列的元素
如果要选取某些行的元素,指定这些行的索引值区间即可,选取时同样遵循“左闭右开”的规则。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
3 print(arr[1:3])
4 print(arr[:2])
5 print(arr[2:])第3行代码表示选取行索引值1(第2行)到行索引值3(第4行)的行元素,但不包括行索引值3(第4行)的行元素。第4行代码中省略了起始位置,表示选取行索引值2(第3行)之前的所有行元素,但不包括行索引值2(第3行)的行元素。第5行代码中省略了结束位置,表示选取行索引值2(第3行)及其之后的所有行元素,包括最后一行的行元素。
代码运行结果如下(第1行和第2行为第3行代码的运行结果,第3行和第4行为第4行代码的运行结果,第5行和第6行为第5行代码的运行结果):
1 [[4 5 6]
2 [7 8 9]]
3 [[1 2 3]
4 [4 5 6]]
5 [[7 8 9]
6 [10 11 12]]选取某些列的元素也是使用同样的原理。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
3 print(arr[:, 1:3])
4 print(arr[:, :2])
5 print(arr[:, 2:])第3行代码表示选取第2列到第4列,但不包括第4列。第4行代码表示选取第3列之前的所有列,但不包括第3列。第5行代码表示选取第3列及其之后的所有列,包括最后一列。
代码运行结果如下(第1~4行为第3行代码的运行结果,第5~8行为第4行代码的运行结果,第9~12行为第5行代码的运行结果):
1 [[ 2 3]
2 [ 6 7]
3 [10 11]
4 [14 15]]
5 [[ 1 2]
6 [ 5 6]
7 [ 9 10]
8 [13 14]]
9 [[3 4]
10 [7 8]
11 [11 12]
12 [15 16]]4)同时选取行列元素
如果要同时选取行和列的元素,同时给出要选取的行和列的索引值区间即可。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
3 print(arr[0:2, 1:3])第3行代码表示选取第1行到第2行中,第2列到第3列的元素。
代码运行结果如下:
1 [[2 3]
2 [6 7]]4、数组的重塑与转置
数组的重塑是指更改数组的形状,也就是将某个维度的数组转换为另一个维度的数组,例如,将一维数组转换为多维数组,或者将3行4列的二维数组转换为4行3列的二维数组。转置是重塑的一种特殊形式,是指将数组的行旋转为列,列旋转为行。
无论是数组重塑还是数组转置,操作前后的数组元素个数都是不会改变的。
1. 一维数组的重塑
代码文件:一维数组的重塑.py
NumPy模块中的reshape()函数可以在不改变数组元素内容和个数的情况下重塑数组的形状。下面先从较简单的一维数组的重塑开始讲解。一维数组的重塑就是将一行或一列的数组转换为多行多列的数组,演示代码如下:
1 import numpy as np
2 arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
3 a = arr.reshape(2, 4)
4 b = arr.reshape(4, 2)
5 print(a)
6 print(b)第2行代码创建了一个含有8个元素的一维数组arr。第3行代码将数组arr转换为2行4列的二维数组,并将转换结果赋给变量a。第4行代码将数组arr转换为4行2列的二维数组,并将转换结果赋给变量b。
代码运行结果如下(第1行和第2行为一维数组arr转换为2行4列的二维数组a的效果。第3~6行为一维数组arr转换为4行2列的二维数组b的效果):
1 [[1 2 3 4]
2 [5 6 7 8]]
3 [[1 2]
4 [3 4]
5 [5 6]
6 [7 8]]从运行结果可以看出,无论数组形状怎么转换,数组的元素内容和个数都没有变化。
提示:
在进行数组重塑时,新数组的形状应该与原数组的形状兼容,即新数组的形状不能导致元素的个数发生改变,否则运行时会报错。
例如,要将一个有12个元素的一维数组转换为二维数组,则二维数组的形状只能为1行12列、2行6列、3行4列、4行3列、6行2列或12行1列。
2. 多维数组的重塑
代码文件:多维数组的重塑.py
reshape()函数除了可以将一维数组转换为多维数组,还可以更改多维数组的形状。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 c = arr.reshape(4, 3)
4 d = arr.reshape(2, 6)
5 print(c)
6 print(d)第2行代码创建了一个3行4列的二维数组arr。第3行代码使用reshape()函数将数组arr转换为一个4行3列的二维数组,并将转换结果赋给变量c。第4行代码使用reshape()函数将数组arr转换为一个2行6列的二维数组,并将转换结果赋给变量d。
代码运行结果如下(第1~4行为将二维数组arr转换为4行3列的二维数组c的效果,第5行和第6行为将数组arr转换为2行6列的二维数组d的效果):
1 [[ 1 2 3]
2 [ 4 5 6]
3 [ 7 8 9]
4 [10 11 12]]
5 [[ 1 2 3 4 5 6]
6 [ 7 8 9 10 11 12]]从运行结果可以看出,转换后的数组的元素内容和个数也没有发生变化。
前面讲解的是如何让多维数组在维度不变的情况下变换行列数,下面来讲解如何将多维数组转换为一维数组。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 print(arr.flatten())
4 print(arr.ravel())第3行代码中的flatten()和第4行代码中的ravel()是NumPy模块中将多维数组转换为一维数组的函数。
代码运行结果如下:
1 [ 1 2 3 4 5 6 7 8 9 10 11 12]
2 [ 1 2 3 4 5 6 7 8 9 10 11 12]3. 数组的转置
代码文件:数组的转置.py
关于数组的转置,NumPy模块提供了T属性和transpose()函数两种方法,下面一起来看看具体的实现过程。
1)T属性
T属性的用法很简单,只需在要转置的数组后调用T属性即可。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 print(arr)
4 print(arr.T)第2行代码创建了一个3行4列的二维数组arr。第3行代码输出数组arr。第4行代码调用T属性转置数组arr并输出转置结果。
代码运行结果如下(第1~3行为二维数组arr的内容,第4~7行为转置二维数组arr的结果):
1 [[ 1 2 3 4]
2 [ 5 6 7 8]
3 [ 9 10 11 12]]
4 [[ 1 5 9]
5 [ 2 6 10]
6 [ 3 7 11]
7 [ 4 8 12]]从运行结果可以看出,转置数组后,数组的元素内容和个数没有变化,但是数组的行变为了列,列变为了行。
2)transpose()函数
transpose()函数是通过调换数组的行和列的索引值来转置数组的。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 arr1 = np.transpose(arr)
4 print(arr1)代码运行结果如下:
1 [[ 1 5 9]
2 [ 2 6 10]
3 [ 3 7 11]
4 [ 4 8 12]]从运行结果可以看出,数组arr由3行4列的二维数组变为4行3列的二维数组arr1,与使用T属性转置数组的效果相同。
5、数组的处理
数组的常见处理操作包括在数组中添加或删除元素,处理数组中的缺失值和重复值,对数组进行拼接和拆分,等等。下面就来讲解相应的方法。
1. 添加数组元素
代码文件:添加数组元素.py
使用NumPy模块中的append()函数和insert()函数可以方便地在数组中添加元素,这两个函数的具体用法如下。
1)append()函数
append()函数可以在数组的末尾添加元素。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6]])
3 arr1 = np.append(arr, [[7, 8, 9]])
4 print(arr1)代码运行结果如下:
1 [1 2 3 4 5 6 7 8 9]从运行结果可以看出,使用append()函数在二维数组arr中添加元素后,返回的数组arr1变成了一维数组。
如果想要在不改变数组维度的情况下在数组末尾添加元素,可以为append()函数添加参数axis。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6]])
3 arr1 = np.append(arr, [[7, 8, 9]], axis=0)
4 print(arr1)第3行代码中为append()函数设置参数axis的值0,我们可以简单地将其理解为,元素会添加在数组arr的行方向上,也就是说,数组的行数会增加,而列数不变。
代码运行结果如下:
1 [[1 2 3]
2 [4 5 6]
3 [7 8 9]]从运行结果可以看出,2行3列的二维数组arr变成了3行3列的二维数组arr1,数组的维度和列数没有变化,但是数组的行数和元素个数增加了。
append()函数的参数axis也可以设置为1,表示元素会添加在数组的列方向上,也就是说,数组的列数会增加,而行数不变。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6]])
3 arr1 = np.append(arr, [[7, 8], [9, 10]], axis=1)
4 print(arr1)代码运行结果如下:
1 [[ 1 2 3 7 8]
2 [ 4 5 6 9 10]]从运行结果可以看出,2行3列的二维数组arr变成了2行5列的二维数组arr1,数组的维度和行数没有变化,但是数组的列数和元素个数增加了。
为了帮助大家更全面地掌握append()函数的用法,这里详细介绍一下append()函数的语法格式和参数含义。
append(arr, values, axis=None)参数说明见下表:

2)insert()函数
insert()函数用于在数组的指定位置插入元素。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 arr1 = np.insert(arr, 1, [7, 8])
4 print(arr1)代码运行结果如下:
1 [1 7 8 2 3 4 5 6]从运行结果可以看出,使用insert()函数在二维数组arr中插入元素后,返回的数组arr1变成了一维数组,且插入的元素位于数组arr1索引值1(第2个元素)之前。
如果想要在不改变数组维度的情况下,在数组的指定位置插入元素,可以为insert()函数添加参数axis。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2], [3, 4], [5, 6]])
3 arr1 = np.insert(arr, 1, [7, 8], axis=0)
4 arr2 = np.insert(arr, 1, [7, 8, 9], axis=1)
5 print(arr1)
6 print(arr2)第3行代码为insert()函数添加了参数axis,并设置值为0,表示在行方向上的指定位置(这里为索引值1的位置,即第2行)插入元素,也就是说,数组的行数会增加,而列数不变。
第4行代码为insert()函数添加了参数axis,并设置值为1,表示在列方向上的指定位置(这里为索引值1的位置,即第2列)插入元素,也就是说,数组的列数会增加,而行数不变。
代码运行结果如下(第1~4行为数组arr1,第5~7行为数组arr2):
1 [[1 2]
2 [7 8]
3 [3 4]
4 [5 6]]
5 [[1 7 2]
6 [3 8 4]
7 [5 9 6]]从运行结果可以看出,3行2列的二维数组arr在行方向上索引值1的位置插入元素后,变为4行2列的二维数组arr1,在列方向上索引值1的位置插入元素后,变为3行3列的二维数组arr2。
为了帮助大家更全面地掌握insert()函数的用法,这里详细介绍一下insert()函数的语法格式和参数含义。
insert(arr, obj, values, axis)参数说明见下表:

2. 删除数组元素
代码文件:删除数组元素.py
既然可以在数组中添加元素,自然也可以删除数组元素,需要用到的是NumPy模块中的delete()函数。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
3 arr1 = np.delete(arr, 2)
4 arr2 = np.delete(arr, 2, axis=0)
5 arr3 = np.delete(arr, 2, axis=1)
6 print(arr1)
7 print(arr2)
8 print(arr3)第3、4、5行代码都使用了delete()函数删除数组元素,区别在于:第3行代码中的函数未设置参数axis,表示先将数组arr展开成一维数组,再删除指定位置的元素(这里为索引值2的元素,即第3个元素);第4行代码设置参数axis的值为0,表示删除数组arr中指定的行(这里为索引值2的行,即第3行);第5行代码设置参数axis的值为1,表示删除数组arr中指定的列(这里为索引值2的列,即第3列)。
代码运行结果如下(第1行为数组arr1的内容,第2行和第3行为数组arr2的内容,第4~6行为数组arr3的内容):
1 [1 2 4 5 6 7 8 9]
2 [[1 2 3]
3 [4 5 6]]
4 [[1 2]
5 [4 5]
6 [7 8]]3. 处理数组的缺失值
代码文件:处理数组的缺失值.py
数组的缺失值处理可分两步进行:第一步是找出缺失值的位置;第二步是用指定的值对缺失值进行填充。
使用NumPy模块中的isnan()函数可以标记数组中缺失值的位置。
演示代码如下:
1 import numpy as np
2 arr = np.array([1, 2, 3, 4, 5, 6, np.nan, 8, 9])
3 print(arr)
4 print(np.isnan(arr))第2行代码创建了一个含有缺失值的一维数组arr,其中的np.nan即表示缺失值。第3行代码输出含有缺失值的数组arr。第4行代码使用isnan()函数标记缺失值的位置,如果数组中某一位置的值为缺失值,则在该位置填充True,否则填充False。
代码运行结果如下:
1 [ 1. 2. 3. 4. 5. 6. nan 8. 9.]
2 [False False False False False False True False False]从运行结果可以看出,数组arr的第7个元素为缺失值。
找到缺失值的位置后,还可以利用isnan()函数对缺失值进行填充,例如,使用数字0填充缺失值。在上面的代码后继续输入如下代码:
1 arr[np.isnan(arr)] = 0
2 print(arr)代码运行结果如下:
1 [1. 2. 3. 4. 5. 6. 0. 8. 9.]从运行结果可以看出,数组arr中的第7个元素的缺失值被替换为0。
4. 处理数组的重复值
代码文件:处理数组的重复值.py
数组中除了可能存在缺失值,还可能存在重复值。使用NumPy模块中的unique()函数即可处理重复值。该函数除了会去除数组中的重复元素,还会将去重后的数组元素从小到大排列。演示代码如下:
1 import numpy as np
2 arr = np.array([8, 4, 2, 3, 5, 2, 5, 5, 6, 8, 8, 9])
3 arr1 = np.unique(arr)
4 arr1, arr2 = np.unique(arr, return_counts=True)
5 print(arr1)
6 print(arr2)第3行代码直接调用unique()函数对数组arr进行去重处理。第4行代码为unique()函数添加了一个参数return_counts,并设置参数值为True,用于查看去重后数组中的元素在原数组中出现的次数。代码运行结果如下:
1 [2 3 4 5 6 8 9]
2 [2 1 1 3 1 3 1]运行结果的第1行为数组arr去重后的效果,可以看到去重后的数组元素从小到大排列。第2行为去重后的数组arr1中的每个元素在原数组arr中出现的次数,例如,数字2在数组arr中出现了2次,数字3在数组arr中出现了1次。
5. 拼接数组
代码文件:拼接数组.py
数组的拼接是指将多个数组合并为一个数组,可使用NumPy模块中的concatenate()函数、hstack()函数和vstack()函数实现。需要注意的是,待合并的几个数组的维度必须相同,即一维数组只能和一维数组合并,二维数组只能和二维数组合并。此外,如果合并的是一维数组,数组的形状可以不一样;但如果合并的是多维数组,则数组的形状必须相同,也就是数组的行列数必须一样。
1)concatenate()函数
concatenate()函数能一次合并多个数组,是数组拼接最常用的方法。
演示代码如下:
1 import numpy as np
2 arr1 = np.array([[1, 2, 3], [4, 5, 6]])
3 arr2 = np.array([[7, 8, 9], [10, 11, 12]])
4 arr3 = np.concatenate((arr1, arr2), axis=0)
5 arr4 = np.concatenate((arr1, arr2), axis=1)
6 print(arr3)
7 print(arr4)第2行和第3行代码分别创建了二维数组arr1和arr2,这两个数组的形状相同,都为2行3列。第4行和第5行代码使用concatenate()函数在不同的方向上拼接数组arr1和arr2,函数中的参数axis用于指定数组拼接的方向,参数值省略或为0时表示在列方向上拼接,为1时表示在行方向上拼接。代码运行结果如下:
1 [[ 1 2 3]
2 [ 4 5 6]
3 [ 7 8 9]
4 [10 11 12]]
5 [[ 1 2 3 7 8 9]
6 [ 4 5 6 10 11 12]]运行结果的第1~4行为在列方向上拼接数组arr1和arr2的效果,第5行和第6行为在行方向上拼接数组arr1和arr2的效果。可以看出,在列方向上拼接后的数组行数是原先的多个数组的行数之和,而列数不会改变;在行方向上拼接后的数组行数不会改变,而列数是原先的多个数组的列数之和。
2)hstack()函数和vstack()函数
hstack()函数能以水平堆叠的方式拼接数组。
演示代码如下:
1 import numpy as np
2 arr1 = np.array([[1, 2, 3], [4, 5, 6]])
3 arr2 = np.array([[7, 8, 9], [10, 11, 12]])
4 arr3 = np.hstack((arr1, arr2))
5 print(arr3)代码运行结果如下:
1 [[ 1 2 3 7 8 9]
2 [ 4 5 6 10 11 12]]从运行结果可以看出,hstack()函数拼接数组的效果等同于concatenate()函数在行方向上拼接数组的效果。
vstack()函数能以垂直堆叠的方式拼接数组。
演示代码如下:
1 import numpy as np
2 arr1 = np.array([[1, 2, 3], [4, 5, 6]])
3 arr2 = np.array([[7, 8, 9], [10, 11, 12]])
4 arr3 = np.vstack((arr1, arr2))
5 print(arr3)代码运行结果如下:
1 [[ 1 2 3]
2 [ 4 5 6]
3 [ 7 8 9]
4 [10 11 12]]从运行结果可以看出,vstack()函数拼接数组的效果等同于concatenate()函数在列方向上拼接数组的效果。
6. 拆分数组
代码文件:拆分数组.py
数组的拆分就是将一个数组分割成多个数组,可以使用NumPy模块中的split()函数、hsplit()函数和vsplit()函数实现。
1)split()函数
split()函数可以按指定的份数将一个数组均分为多个数组。
演示代码如下:
1 import numpy as np
2 arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
3 arr1 = np.split(arr, 2)
4 arr2 = np.split(arr, 4)
5 print(arr1)
6 print(arr2)第2行代码创建了一个一维数组arr。第3行和第4行代码中,split()函数的第2个参数都是一个整数,分别表示将一维数组arr拆分为两个大小相等的一维数组和4个大小相等的一维数组。
代码运行结果如下:
1 [array([1, 2, 3, 4, 5, 6]), array([ 7, 8, 9, 10, 11, 12])]
2 [array([1, 2, 3]), array([4, 5, 6]), array([7, 8, 9]), array([10, 11, 12])]split()函数除了可以均分数组,还可以按照指定的索引位置拆分数组,此时需要将split()函数的第2个参数设置为一个数组。
演示代码如下:
1 import numpy as np
2 arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
3 arr3 = np.split(arr, [2, 6])
4 arr4 = np.split(arr, [2, 3, 8, 10])
5 print(arr3)
6 print(arr4)第3行代码中,split()函数的第2个参数为[2, 6],表示在数组arr的索引值2(第3个元素)和索引值6(第7个元素)的位置之前进行拆分。第4行代码中,split()函数的第2个参数为[2, 3, 8, 10],表示在数组arr的索引值2(第3个元素)、索引值3(第4个元素)、索引值8(第9个元素)和索引值10(第11个元素)的位置之前进行拆分。
代码运行结果如下:
1 [array([1, 2]), array([3, 4, 5, 6]), array([ 7, 8, 9, 10, 11, 12])]
2 [array([1, 2]), array([3]), array([4, 5, 6, 7, 8]), array([ 9, 10]), array([11, 12])]从运行结果可以看出,一维数组arr被分别拆分为3个一维数组和5个一维数组,拆分出的各个数组的大小并不相同。
2)hsplit()函数和vsplit()函数
hsplit()函数能将一个数组横向拆分为多个数组。vsplit()函数能将一个数组纵向拆分为多个数组。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])
3 arr5 = np.hsplit(arr, 2)
4 arr6 = np.vsplit(arr, 2)
5 print(arr5)
6 print(arr6)代码运行结果如下(第1~7行为将数组arr横向拆分成两个数组的效果,第8~10行为将数组arr纵向拆分成两个数组的效果):
1 [array([[ 1, 2],
2 [ 5, 6],
3 [ 9, 10],
4 [13, 14]]), array([[ 3, 4],
5 [ 7, 8],
6 [11, 12],
7 [15, 16]])]
8 [array([[1, 2, 3, 4],
9 [5, 6, 7, 8]]), array([[ 9, 10, 11, 12],
10 [13, 14, 15, 16]])]6、数组的运算
NumPy模块的优势不仅在于支持多个维度数据的存储和展示,它还能很好地支持数组的数学运算,如数组之间的四则运算和数组元素的统计运算。
1. 数组之间的四则运算
代码文件:数组之间的四则运算.py
对于多个形状一致的数组,我们可以直接对它们进行加、减、乘、除等运算,运算结果是一个由对应位置上的元素分别进行四则运算后的数组。为了便于读者理解,通过以下代码来演示数组之间四则运算的过程。
1 import numpy as np
2 arr1 = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
3 arr2 = np.array([[9, 10, 11, 12], [13, 14, 15, 16]])
4 arr3 = arr1 + arr2
5 arr4 = arr1 * arr2
6 print(arr3)
7 print(arr4)第2行和第3行代码创建了两个形状相同的二维数组arr1和arr2。第4行和第5行代码对二维数组arr1和arr2分别进行了加法和乘法运算。
代码运行结果如下(第1行和第2行为数组arr3的内容,第3行和第4行为数组arr4的内容):
1 [[10 12 14 16]
2 [18 20 22 24]]
3 [[ 9 20 33 48]
4 [ 65 84 105 128]]从运行结果可以看出,数组arr3为数组arr1和arr2中相同位置的元素分别相加后的结果,数组arr4为数组arr1和arr2中相同位置的元素分别相乘后的结果。同理,如果要对两个数组中相同位置的元素分别进行减法和除法运算,改变上面代码中的运算符即可。
除了可以在多个数组之间进行四则运算,还可以对一个数组和一个数值进行四则运算。演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
3 arr5 = arr + 5
4 arr6 = arr * 10
5 print(arr5)
6 print(arr6)代码运行结果如下(第1行和第2行为数组arr5的内容,第3行和第4行为数组arr6的内容):
1 [[ 6 7 8 9]
2 [10 11 12 13]]
3 [[10 20 30 40]
4 [50 60 70 80]]从运行结果可以看出,数组arr5为数组arr中的元素分别加上5的结果,数组arr6为数组arr中的元素分别乘以10的结果。
2. 数组元素的统计运算
代码文件:数组元素的统计运算.py
使用NumPy模块中的一些函数可以对数组元素进行统计运算,如求和、求平均值、求最大值和最小值等。
1)求和
sum()函数用于求和,它除了能对整个数组的所有元素求和,还能对数组的每一行或每一列元素分别求和。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 arr1 = arr.sum()
4 arr2 = arr.sum(axis=0)
5 arr3 = arr.sum(axis=1)
6 print(arr1)
7 print(arr2)
8 print(arr3)第2行代码创建了一个3行4列的二维数组arr。第3、4、5行代码使用sum()函数对数组arr进行不同方式的求和:第3行代码中sum()函数的括号内没有参数,表示对整个数组的所有元素求和;第4行代码中为sum()函数设置参数axis的值为0,表示对数组的每一列元素分别求和;第5行代码中为sum()函数设置参数axis的值为1,表示对数组的每一行元素分别求和。
代码运行结果如下:
1 78
2 [15 18 21 24]
3 [10 26 42]2)求平均值
mean()函数用于求平均值,它除了能对整个数组的所有元素求平均值,还能对数组的每一行或每一列元素分别求平均值。
演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 arr1 = arr.mean()
4 arr2 = arr.mean(axis=0)
5 arr3 = arr.mean(axis=1)
6 print(arr1)
7 print(arr2)
8 print(arr3)第2行代码创建了一个3行4列的二维数组arr。第3、4、5行代码使用mean()函数对数组arr以不同方式求平均值:第3行代码中mean()函数的括号内没有参数,表示对整个数组的所有元素求平均值;第4行代码中为mean()函数设置参数axis的值为0,表示对数组的每一列元素分别求平均值;第5行代码中为mean()函数设置参数axis的值为1,表示对数组的每一行元素分别求平均值。
代码运行结果如下:
1 6.5
2 [5. 6. 7. 8.]
3 [ 2.5 6.5 10.5]3)求最值
max()函数和min()函数分别用于求数组元素的最大值和最小值。与sum()函数和mean()函数类似,max()函数和min()函数也可以通过设置参数来指定求最值的方式。下面以max()函数为例进行讲解,演示代码如下:
1 import numpy as np
2 arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
3 arr1 = arr.max()
4 arr2 = arr.max(axis=0)
5 arr3 = arr.max(axis=1)
6 print(arr1)
7 print(arr2)
8 print(arr3)第2行代码创建了一个3行4列的二维数组arr。第3、4、5行代码使用max()函数对数组arr以不同方式求最大值:第3行代码中max()函数的括号内没有参数,表示对整个数组的所有元素求最大值;第4行代码中为max()函数设置参数axis的值为0,表示对数组的每一列元素分别求最大值;第5行代码中为max()函数设置参数axis的值为1,表示对数组的每一行元素分别求最大值。
代码运行结果如下:
1 12
2 [ 9 10 11 12]
3 [ 4 8 12]如果要求数组元素的最小值,则将上面第3~5行代码中的max改为min即可。
三、pandas模块
pandas模块是基于NumPy模块开发的,它不仅能直观地展现数据的结构,还具备强大的数据处理和分析功能。从某种程度上来说,pandas模块是Python成为强大而高效的数据分析工具的重要因素之一。
1、数据结构
pandas模块中有两个重要的数据结构对象——Series和DataFrame。使用这两个数据结构对象可以在计算机的内存中构建虚拟的数据库。下面一起来学习如何使用这两个对象创建数据结构。
1. Series对象
代码文件:Series对象.py
Series是一种类似于NumPy模块创建的一维数组的对象,与一维数组不同的是,Series对象不仅包含数据元素,还包含一组与数据元素对应的行标签。
使用Series对象可以基于列表创建数据结构。
演示代码如下:
1 import pandas as pd
2 s = pd.Series(['短裤', '毛衣', '连衣裙', '牛仔裤'])
3 print(s)代码运行结果如下:
1 0 短裤
2 1 毛衣
3 2 连衣裙
4 3 牛仔裤
5 dtype: object从运行结果可以看出,创建了一个一维数据结构s,结构中的每个元素都有一个行标签,其值默认为从0开始的数字序列,例如,s中4个元素的行标签分别为0、1、2、3。通过行标签可以定位数据结构中的元素,例如,s[1]表示s中行标签为1的元素,即“毛衣”。
如果想要在创建数据结构时自定义元素的行标签,可以使用Series对象的参数index传入元素的行标签列表。
演示代码如下:
1 import pandas as pd
2 s1 = pd.Series(['短裤', '毛衣', '连衣裙', '牛仔裤'], index=['a001', 'a002', 'a003', 'a004'])
3 print(s1)代码运行结果如下:
1 a001 短裤
2 a002 毛衣
3 a003 连衣裙
4 a004 牛仔裤
5 dtype: object从运行结果可以看出,数据结构s1中4个元素的行标签分别为自定义的a001、a002、a003、a004。需要注意的是,此时s1的行标签不是整数,则s1[1]表示s1的第2个元素,即“毛衣”。
使用Series对象还可以基于字典创建数据结构。
演示代码如下:
1 import pandas as pd
2 s2 = pd.Series({'a001': '短裤', 'a002': '毛衣', 'a003': '连衣裙', 'a004': '牛仔裤'})
3 print(s2)第2行代码为Series对象传入了一个字典来创建数据结构,字典的键(key)是数据结构元素的行标签,字典的值(value)则是数据结构的元素。
代码运行结果如下:
1 a001 短裤
2 a002 毛衣
3 a003 连衣裙
4 a004 牛仔裤
5 dtype: object2. DataFrame对象
代码文件:DataFrame对象.py
DataFrame是一种二维的数据结构对象,用该对象创建的数据结构在形式上类似于Excel表格。相比Series对象,DataFrame对象在实际工作中的应用更为广泛,因此,后续章节与pandas模块相关的内容都主要围绕DataFrame对象展开。先来学习使用DataFrame对象基于列表创建数据结构的方法,演示代码如下:
1 import pandas as pd
2 df = pd.DataFrame([['短裤', 45], ['毛衣', 69], ['连衣裙', 119], ['牛仔裤', 99]])
3 print(df)第2行代码为DataFrame对象传入了一个嵌套的列表来创建二维的数据结构。
代码运行结果如下:
1 0 1
2 0 短裤 45
3 1 毛衣 69
4 2 连衣裙 119
5 3 牛仔裤 99从运行结果可以看出,创建了一个二维的数据结构,数据结构中的元素既有行标签又有列标签,其值都默认为从0开始的数字序列。
在使用DataFrame对象创建数据结构时,还可以通过设置参数columns和index来分别自定义行标签和列标签。
演示代码如下:
1 import pandas as pd
2 df1 = pd.DataFrame([['短裤', 45], ['毛衣', 69], ['连衣裙', 119], ['牛仔裤', 99]], columns=['产品', '单价'], index=['a001', 'a002', 'a003', 'a004'])
3 print(df1)第2行代码中的参数columns用于设置列标签,参数index用于设置行标签。
代码运行结果如下:
1 产品 单价
2 a001 短裤 45
3 a002 毛衣 69
4 a003 连衣裙 119
5 a004 牛仔裤 99使用DataFrame对象还可以基于字典创建数据结构。
演示代码如下:
1 import pandas as pd
2 df2 = pd.DataFrame({'产品': ['短裤', '毛衣', '连衣裙', '牛仔裤'], '单价': [45, 69, 119, 99]})
3 print(df2)第2行代码为DataFrame对象传入了一个字典来创建数据结构,字典的键(key)是数据结构元素的列标签,字典的值(value)则是数据结构的元素。
代码运行结果如下:
1 产品 单价
2 0 短裤 45
3 1 毛衣 69
4 2 连衣裙 119
5 3 牛仔裤 99从运行结果可以看出,由于没有设置行标签,数据结构的行标签默认为从0开始的数字序列。如果要自定义行标签,可以使用参数index。
演示代码如下:
1 import pandas as pd
2 df3 = pd.DataFrame({'产品': ['短裤', '毛衣', '连衣裙', '牛仔裤'], '单价': [45, 69, 119, 99]}, index=['a001', 'a002', 'a003', 'a004'])
3 print(df3)代码运行结果如下:
1 产品 单价
2 a001 短裤 45
3 a002 毛衣 69
4 a003 连衣裙 119
5 a004 牛仔裤 992、读取数据
使用pandas模块可以从多种类型的文件中读取数据。主要从Excel工作簿和csv格式文件中读取数据为例讲解具体方法。
1. 读取Excel工作簿数据
代码文件:读取Excel工作簿数据.py
使用pandas模块中的read_excel()函数即可读取Excel工作簿数据。
1)读取某个工作表的数据
一个Excel工作簿可能会有多个工作表,可通过read_excel()函数的参数sheet_name指定从哪个工作表中读取数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data)read_excel()函数的第1个参数用于指定要读取的工作簿文件路径。第2行代码中将第1个参数设置为'订单表.xlsx',表示从工作簿“订单表.xlsx”中读取数据。此处使用的文件路径是相对路径,表示要读取的工作簿“订单表.xlsx”与代码文件位于同一个文件夹下,如果两者的文件路径不同,则需要将第1个参数设置为绝对路径,如'E:\\example\\订单表.xlsx'或r'E:\example\订单表.xlsx'。
第2个参数sheet_name用于指定从哪个工作表中读取数据,其值可以为整型数字或字符串。当参数值为整型数字时,以0代表第1个工作表,以1代表第2个工作表,依此类推。第2行代码中设置的参数值是3,表示读取工作簿“订单表.xlsx”中的第4个工作表。当参数值为字符串时,表示要读取的工作表的名称。例如,要读取的第4个工作表名为“4月”,则第2行代码中的sheet_name=3可修改为sheet_name='4月'。此外,如果省略参数sheet_name,则默认读取工作簿中的第1个工作表。
代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 34从运行结果可以看出,read_excel()函数使用读取的数据创建了一个DataFrame对象。
2)指定读取数据的列标签
在使用read_excel()函数读取数据时,可以通过设置参数header来指定使用数据表的第几行(从0开始计数)的内容作为列标签。当省略该参数或将其值设置为0时,表示使用数据表第1行的内容作为列标签。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, header=0)
3 print(data)
代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 34如果将参数header的值设置为1,则表示使用数据表第2行的内容作为列标签。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, header=1)
3 print(data)代码运行结果如下:
1 d001 投影仪 5台 2000
2 0 d002 马克笔 5盒 300
3 1 d003 打印机 1台 298
4 2 d004 点钞机 1台 349
5 3 d005 复印纸 2箱 100
6 4 d006 条码纸 6卷 34如果要将列标签设置为从0开始的数字序列,可以将参数header设置为None。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, header=None)
3 print(data)代码运行结果如下:
1 0 1 2 3
2 0 订单编号 产品 数量 金额
3 1 d001 投影仪 5台 2000
4 2 d002 马克笔 5盒 300
5 3 d003 打印机 1台 298
6 4 d004 点钞机 1台 349
7 5 d005 复印纸 2箱 100
8 6 d006 条码纸 6卷 343)指定读取数据的行标签
read_excel()函数的参数index_col用于指定使用数据表的第几列(同样是从0开始计数)的内容作为行标签。当省略该参数或将其值设置为0时,表示使用数据表第1列的内容作为行标签。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data)代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d001 投影仪 5台 2000
4 d002 马克笔 5盒 300
5 d003 打印机 1台 298
6 d004 点钞机 1台 349
7 d005 复印纸 2箱 100
8 d006 条码纸 6卷 34也可以指定其他列作为读取数据的行标签。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=1)
3 print(data)第2行代码中设置参数index_col为1,表示使用数据表第2列的内容作为行标签。代码运行结果如下:
1 订单编号 数量 金额
2 产品
3 投影仪 d001 5台 2000
4 马克笔 d002 5盒 300
5 打印机 d003 1台 298
6 点钞机 d004 1台 349
7 复印纸 d005 2箱 100
8 条码纸 d006 6卷 344)读取指定列
如果只需要读取数据表的某一列或某几列,可以使用参数usecols来指定要读取的列。先从最简单的读取某一列数据开始讲解。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, usecols=[2])
3 print(data)第2行代码中设置参数usecols为[2],表示读取数据表的第3列。需要注意的是,参数usecols的值应为一个列表,即使只读取一列,也要以列表的形式给出。
代码运行结果如下:
1 数量
2 0 5台
3 1 5盒
4 2 1台
5 3 1台
6 4 2箱
7 5 6卷继续来学习通过设置参数usecols读取指定的多列数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, usecols=[1, 3])
3 print(data)第2行代码中设置参数usecols为[1, 3],表示读取数据表的第2列和第4列。
代码运行结果如下:
1 产品 金额
2 0 投影仪 2000
3 1 马克笔 300
4 2 打印机 298
5 3 点钞机 349
6 4 复印纸 100
7 5 条码纸 342. 读取csv文件数据
代码文件:读取csv文件数据.py
csv是一种存储数据的文件格式,其本质上是一个文本文件,只能存储文本,不能存储格式、公式、宏等,所以所占存储空间通常较小。csv文件一般用逗号分隔一系列值,它既可以用Excel程序打开,也可以用文本编辑器(如记事本)打开。
读取csv文件数据需要用到pandas模块中的read_csv()函数。
演示代码如下:
1 import pandas as pd
2 data = pd.read_csv('订单表.csv')
3 print(data)第2行代码表示读取一个名为“订单表”的csv文件。此处使用的文件路径是相对路径,表示要读取的csv文件与代码文件位于同一个文件夹下,可以根据需要更改为绝对路径。
代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 34如果只想读取csv文件的前几行数据,可在read_csv()函数中设置参数nrows的值。
例如,读取csv文件的前3行数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_csv('订单表.csv', nrows=3)
3 print(data)代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298从运行结果可以看出,read_csv()函数是先从csv文件中读取第1行数据作为列标签,再接着往下读取3行数据的。此外,read_excel()函数也支持通过设置参数nrows来控制读取数据的行数。
3、查看数据
当我们有了数据后,还需要查看数据的基本情况。对数据有了初步的了解,才能更好地分析数据。下面就来讲解使用pandas模块查看数据的几种常用操作。
1. 查看数据的前几行
代码文件:查看数据的前几行.py
使用read_excel()函数或read_csv()函数读取数据并创建DataFrame对象后,如果想通过查看数据的前几行来大致判断读取结果是否满足需求,可以使用DataFrame对象的head()函数来控制要显示的行数。
当head()函数中不设置参数值时,表示查看数据的前5行。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.head())代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100也可以在head()函数中输入要查看的行数。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.head(3))代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 2982. 查看数据的行数和列数
代码文件:查看数据的行数和列数.py
如果要查看DataFrame对象中数据的行数和列数,可以使用DataFrame对象的shape属性来实现。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data)
4 print(data.shape)代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 34
8 (6, 4)运行结果的第1~7行为读取的数据,第8行为数据的行数和列数。可以看出,用shape属性获取数据的行数和列数时不会把行索引和列索引计算在内,返回的结果是一个元组,其中的两个元素分别代表数据的行数和列数。可以通过从元组中提取元素的方法来单独获取数据的行数或列数。
3. 查看数据的类型
代码文件:查看数据的类型.py
使用DataFrame对象的info()函数可查看读取的数据中各列的数据类型。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.info())代码运行结果如下:
1
2 RangeIndex: 6 entries, 0 to 5
3 Data columns (total 4 columns):
4 订单编号 6 non-null object
5 产品 6 non-null object
6 数量 6 non-null object
7 金额 6 non-null int64
8 dtypes: int64(1), object(3)
9 memory usage: 320.0+ bytes
10 None 从运行结果的第3行可以得知读取的数据有4列,从第4~7行可以得知各列的标签和数据类型,其中第1~3列的数据类型均为object,第4列的数据类型为int64。
如果只想查看某一列的数据类型,可使用dtype属性。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data['金额'].dtype)第3行代码表示查看“金额”列的数据类型,如果要查看其他列的数据类型,更改为相应的标签即可。
代码运行结果如下:
1 int64技巧:转换数据的类型
如果需要转换数据的类型,可以使用astype()函数。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 data['金额'] = data['金额'].astype('float64')
4 print(data)
5 print(data['金额'].dtype)第3行代码表示将“金额”列的数据类型更改为'float64',为astype()函数传入的参数是要转换的目标类型,随后用转换数据类型后的“金额”列覆盖原始的“金额”列。第4行和第5行代码输出转换数据类型后的数据结构data及data中“金额”列的数据类型。
代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000.0
3 1 d002 马克笔 5盒 300.0
4 2 d003 打印机 1台 298.0
5 3 d004 点钞机 1台 349.0
6 4 d005 复印纸 2箱 100.0
7 5 d006 条码纸 6卷 34.0
8 float64运行结果的第1~7行为转换数据类型后的数据结构data的内容,可以发现“金额”列的数据类型由原来的整型数字变为浮点型数字。第8行为“金额”列当前的数据类型,即float64。
4、选择数据
要对读取的数据进行编辑,需要先学会选择数据的操作,如选择行数据、选择列数据或者同时选择行列数据。下面就来讲解选择数据的方法。
1. 选择行数据
代码文件:选择行数据.py
在读取的数据中,我们既可以选择单行数据,也可以选择多行数据,还可以按照指定的条件选择行数据。
先用read_excel()函数读取Excel工作簿中某个工作表的数据,创建一个DataFrame作为选择行数据的操作对象。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data)代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d001 投影仪 5台 2000
4 d002 马克笔 5盒 300
5 d003 打印机 1台 298
6 d004 点钞机 1台 349
7 d005 复印纸 2箱 100
8 d006 条码纸 6卷 341)选择单行数据
在DataFrame中选择单行数据有loc和iloc两种方法,它们选择数据时的依据不同,下面分别介绍。
使用loc方法可以依据行标签选择单行数据。
演示代码如下。
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data.loc['d001'])第3行代码中loc后的“[]”中输入的是要选择的行的行标签,此处的'd001'表示选择行标签为“d001”的行。
代码运行结果如下:
1 产品 投影仪
2 数量 5台
3 金额 2000
4 Name: d001, dtype: object使用iloc方法可以依据行序号(从0开始计数)选择单行数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data.iloc[2])第3行代码表示选择行序号为2的行,即第3行。
代码运行结果如下:
1 产品 打印机
2 数量 1台
3 金额 298
4 Name: d003, dtype: object2)选择多行数据
loc方法和iloc方法除了能选择单行数据外,还能选择多行数据。
使用loc方法依据行标签选择多行数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data.loc[['d002', 'd004']])第3行代码表示选择行标签为“d002”和“d004”的行,可以看到,多个行标签要以列表的形式给出。代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d002 马克笔 5盒 300
4 d004 点钞机 1台 349使用iloc方法依据行序号选择多行数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data.iloc[[1, 5]])第3行代码表示选择行序号为1和5的行,即第2行和第6行,多个行序号同样要以列表的形式给出。代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d002 马克笔 5盒 300
4 d006 条码纸 6卷 34使用iloc方法还可以通过类似列表切片的方式,对指定的行序号区间按照“左闭右开”的规则选择连续的行数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 print(data.iloc[1:5])第3行代码的“[]”中指定的行序号区间为“1:5”,根据“左闭右开”的规则,它表示选择行序号为1~4的行,也就是第2~5行。代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d002 马克笔 5盒 300
4 d003 打印机 1台 298
5 d004 点钞机 1台 349
6 d005 复印纸 2箱 1003)选择满足条件的行
除了依据行标签或行序号选择行数据外,还能依据指定条件选择行数据。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 a = data['金额'] < 300
4 print(data[a])第3行代码将“‘金额’列中数据小于300”的条件赋给变量a。第4行代码表示输出data中满足条件a的行数据。
代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d003 打印机 1台 298
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 342. 选择列数据
代码文件:选择列数据.py
选择列数据有两种方法:第一种是通过直接指定列标签来实现;第二种是使用iloc方法,通过指定行序号和列序号来实现。
先用read_excel()函数读取Excel工作簿中某个工作表的数据,创建一个DataFrame作为选择列数据的操作对象。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data)代码运行结果如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 341)选择单列数据
选择单列数据通过指定列标签来实现最为直观和方便。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data['产品'])第3行代码表示选择列标签为“产品”的列。
代码运行结果如下:
1 0 投影仪
2 1 马克笔
3 2 打印机
4 3 点钞机
5 4 复印纸
6 5 条码纸
7 Name: 产品, dtype: object2)选择多列数据
通过指定列标签来选择多列数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data[['产品', '金额']])第3行代码表示选择列标签为“产品”和“金额”的列。
代码运行结果如下:
1 产品 金额
2 0 投影仪 2000
3 1 马克笔 300
4 2 打印机 298
5 3 点钞机 349
6 4 复印纸 100
7 5 条码纸 34用iloc方法也可以选择多列数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.iloc[:, [1, 3]])第3行代码中,iloc方法的“[]”中逗号之前的部分表示要选择的行序号,当只输入一个冒号而不输入任何数值时,表示选择所有行;逗号之后的部分为要选择的列序号,多个列序号可以用列表的形式给出。因此,第3行代码表示选择列序号为1和3的列,即第2列和第4列。
代码运行结果如下:
1 产品 金额
2 0 投影仪 2000
3 1 马克笔 300
4 2 打印机 298
5 3 点钞机 349
6 4 复印纸 100
7 5 条码纸 34如果要选择连续的多列数据,可以使用iloc方法通过类似列表切片的方式来实现。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.iloc[:, 1:3])第3行代码中,iloc方法的“[]”中逗号之后的部分表示要选择的列序号区间,按照“左闭右开”的规则,“1:3”表示选择列序号为1和2的列,也就是第2列和第3列。
代码运行结果如下:
1 产品 数量
2 0 投影仪 5台
3 1 马克笔 5盒
4 2 打印机 1台
5 3 点钞机 1台
6 4 复印纸 2箱
7 5 条码纸 6卷
3. 同时选择行列数据
代码文件:同时选择行列数据.py
如果要同时选择行列数据,可以通过loc方法和iloc方法来实现。这里以开头创建的DataFrame作为操作对象,讲解同时选择行列数据的方法。
使用loc方法依据行标签和列标签同时选择行列数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 data1 = data.loc[['d001', 'd005'], ['产品', '金额']]
4 print(data1)第3行代码表示选择行标签为“d001”和“d005”的行,以及列标签为“产品”和“金额”的列。代码运行结果如下:
1 产品 金额
2 订单编号
3 d001 投影仪 2000
4 d005 复印纸 100使用iloc方法依据行序号和列序号同时选择行列数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3, index_col=0)
3 data2 = data.iloc[[2, 4], [0, 2]]
4 print(data2)第3行代码表示选择行序号为2(第3行)和4(第5行)的行,以及列序号为0(第1列)和2(第3列)的列。
代码运行结果如下:
1 产品 金额
2 订单编号
3 d003 打印机 298
4 d005 复印纸 1005、修改行标签和列标签
代码文件:修改行标签和列标签.py
行标签和列标签是查找数据的依据,读取数据后,如果生成的标签不便于我们查找数据,可以修改标签。
这里以开头创建的DataFrame作为操作对象,讲解具体的方法。
该DataFrame的内容如下:
1 订单编号 产品 数量 金额
2 0 d001 投影仪 5台 2000
3 1 d002 马克笔 5盒 300
4 2 d003 打印机 1台 298
5 3 d004 点钞机 1台 349
6 4 d005 复印纸 2箱 100
7 5 d006 条码纸 6卷 34可以看到,读取数据时默认添加的行标签为从0开始的整数序列。如果要将“订单编号”列作为行标签,可使用set_index()函数修改行标签。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 print(data.set_index('订单编号'))代码运行结果如下:
1 产品 数量 金额
2 订单编号
3 d001 投影仪 5台 2000
4 d002 马克笔 5盒 300
5 d003 打印机 1台 298
6 d004 点钞机 1台 349
7 d005 复印纸 2箱 100
8 d006 条码纸 6卷 34还可以使用rename()函数重命名行标签和列标签。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 data = data.rename(columns={'订单编号': '编号', '产品': '产品名称', '数量': '订单数量', '金额': '订单金额'}, index={0: 'A', 1: 'B', 2: 'C', 3: 'D', 4: 'E', 5: 'F'})
4 print(data)第3行代码将rename()函数的参数columns和index都设置为一个字典,字典的key(键)为原来的列标签或行标签,value(值)为新的列标签或行标签。
代码运行结果如下:
1 编号 产品名称 订单数量 订单金额
2 A d001 投影仪 5台 2000
3 B d002 马克笔 5盒 300
4 C d003 打印机 1台 298
5 D d004 点钞机 1台 349
6 E d005 复印纸 2箱 100
7 F d006 条码纸 6卷 34还可以通过为DataFrame的columns属性和index属性重新赋值来分别修改列标签和行标签。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('订单表.xlsx', sheet_name=3)
3 data.columns = ['编号', '产品名称', '订单数量', '订单金额']
4 data.index = ['A', 'B', 'C', 'D', 'E', 'F']
5 print(data)代码运行结果如下:
1 编号 产品名称 订单数量 订单金额
2 A d001 投影仪 5台 2000
3 B d002 马克笔 5盒 300
4 C d003 打印机 1台 298
5 D d004 点钞机 1台 349
6 E d005 复印纸 2箱 100
7 F d006 条码纸 6卷 346、数据的查找和替换
查找和替换是日常工作中很常见的数据预处理操作,下面就来讲解如何使用pandas模块中的函数对DataFrame中的数据进行查找和替换。
1. 查找数据
代码文件:查找数据.py
使用pandas模块中的isin()函数可以查看DataFrame是否包含某个值。先用read_excel()函数读取工作表数据并创建DataFrame格式的数据表。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 print(data)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 背包 16 65 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 4 a005 钱包 90 187 78 7020 14586 7566
7 5 a006 单肩包 58 124 63 3654 7812 4158
8 6 a007 单肩包 58 124 58 3364 7192 3828接下来就可以使用isin()函数查看数据表是否包含单个值或多个值。
演示代码如下:
1 data1 = data.isin(['a005', '钱包'])
2 print(data1)第1行代码表示在整个数据表中查找是否有值“a005”和“钱包”,将等于“a005”或“钱包”的地方标记为True,将不等于“a005”或“钱包”的地方标记为False。需要注意的是,要查找的值必须以列表的形式给出。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 False False False False False False False False
3 1 False True False False False False False False
4 2 False False False False False False False False
5 3 False False False False False False False False
6 4 True True False False False False False False
7 5 False False False False False False False False
8 6 False False False False False False False False从运行结果可以看出,数据表的第2行和第5行都有True值,说明数据表中有“a005”或“钱包”。
使用isin()函数还可以判断数据表的某一列中是否有某个值。
演示代码如下:
1 data2 = data['产品'].isin(['手提包'])
2 print(data2)第1行代码表示在“产品”列中查找值“手提包”,将等于“手提包”的地方标记为True,将不等于“手提包”的地方标记为False。
代码运行结果如下:
1 0 False
2 1 False
3 2 False
4 3 True
5 4 False
6 5 False
7 6 False
8 Name: 产品, dtype: bool从运行结果可以看出,“产品”列的第4行有一个True值,说明“产品”列中有“手提包”这个值。
2. 替换数据
代码文件:替换数据.py
如果需要将数据表中的单个或多个值替换为其他值,可以使用pandas模块中的replace()函数来完成。该函数可以对数据表中的数据进行一对一替换、多对一替换和多对多替换。
1)一对一替换
一对一替换是将数据表中的某个值全部替换为另一个值。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data.replace('背包', '挎包', inplace=True)
4 print(data)第3行代码表示将数据表中的值“背包”全部替换为“挎包”。replace()函数括号中逗号前面的参数是需要替换的值,逗号后面的参数是替换后的值。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 背包 16 65 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 4 a005 钱包 90 187 78 7020 14586 7566
7 5 a006 单肩包 58 124 63 3654 7812 4158
8 6 a007 单肩包 58 124 58 3364 7192 3828从运行结果可以看出,执行替换操作后,数据表中的“背包”并没有被替换为“挎包”。这是因为replace()函数在默认情况下不是直接对原数据表执行替换操作,而是用替换操作的结果生成一个新的数据表。
如果想要直接对原数据表执行替换操作,除了把用replace()函数执行替换操作的结果重新赋给原数据表,还可以为replace()函数添加参数inplace,并将该参数的值设置为True。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data.replace('背包', '挎包')
4 print(data)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 挎包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 挎包 16 65 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 4 a005 钱包 90 187 78 7020 14586 7566
7 5 a006 单肩包 58 124 63 3654 7812 4158
8 6 a007 单肩包 58 124 58 3364 7192 3828从运行结果可以看出,数据表中的“背包”被替换为了“挎包”。
2)多对一替换
多对一替换是把数据表中的多个值替换为某一个值。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data.replace(['背包', '手提包'], '挎包', inplace=True)
4 print(data)第3行代码表示将数据表中的值“背包”和“手提包”都替换为“挎包”。代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 挎包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 挎包 16 65 23 368 1495 1127
5 3 a004 挎包 36 147 26 936 3822 2886
6 4 a005 钱包 90 187 78 7020 14586 7566
7 5 a006 单肩包 58 124 63 3654 7812 4158
8 6 a007 单肩包 58 124 58 3364 7192 38283)多对多替换
多对多替换可以看成是多个一对一替换。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data.replace({'背包': '挎包', 16: 39, 65: 88}, inplace=True)
4 print(data)第3行代码中以字典的形式为replace()函数指定需要替换的值和替换后的值,字典的key(键)为需要替换的值,value(值)为替换后的值。因此,第3行代码表示将“背包”“16”“65”分别替换为“挎包”“39”“88”。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 挎包 39 88 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 挎包 39 88 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 4 a005 钱包 90 187 78 7020 14586 7566
7 5 a006 单肩包 58 124 63 3654 7812 4158
8 6 a007 单肩包 58 124 58 3364 7192 38287、数据的处理
本节要介绍pandas模块中常用的一些数据处理操作,包括数据的插入和删除、缺失值和重复值的处理、数据的排序和筛选等。
1. 插入数据
代码文件:插入数据.py
pandas模块没有专门提供插入行的方法,因此,插入数据主要是指插入一列新的数据。常用的方法有两种:第一种是以赋值的方式在数据表的最右侧插入列数据,第二种是用insert()函数在数据表的指定位置插入列数据。
以赋值的方式在数据表的最右侧插入列数据的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data['品牌'] = ['AM', 'DE', 'SR', 'AM', 'TY', 'DE', 'UD']
4 print(data)第3行代码表示在数据表的最右侧插入一个列标签为“品牌”的列,该列的数据分别为“AM、DE、SR、AM、TY、DE、UD”。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元) 品牌
2 0 a001 背包 16 65 60 960 3900 2940 AM
3 1 a002 钱包 90 187 50 4500 9350 4850 DE
4 2 a003 背包 16 65 23 368 1495 1127 SR
5 3 a004 手提包 36 147 26 936 3822 2886 AM
6 4 a005 钱包 90 187 78 7020 14586 7566 TY
7 5 a006 单肩包 58 124 63 3654 7812 4158 DE
8 6 a007 单肩包 58 124 58 3364 7192 3828 UD如果需要在数据表的指定位置插入列数据,可以使用pandas模块中的insert()函数。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 data.insert(2, '品牌', ['AM', 'DE', 'SR', 'AM', 'TY', 'DE', 'UD'])
4 print(data)第3行代码中为insert()函数设置了3个参数:第1个参数为插入列的位置,这里设置为2,表示在序号为2的列(即第3列)前面插入一列新数据;第2个参数为插入列的列标签;第3个参数以列表的形式给出插入列的数据。
代码运行结果如下:
1 编号 产品 品牌 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 AM 16 65 60 960 3900 2940
3 1 a002 钱包 DE 90 187 50 4500 9350 4850
4 2 a003 背包 SR 16 65 23 368 1495 1127
5 3 a004 手提包 AM 36 147 26 936 3822 2886
6 4 a005 钱包 TY 90 187 78 7020 14586 7566
7 5 a006 单肩包 DE 58 124 63 3654 7812 4158
8 6 a007 单肩包 UD 58 124 58 3364 7192 38282. 删除数据
代码文件:删除数据.py
如果要删除数据表中的数据,可以使用pandas模块中的drop()函数。该函数既可以删除指定的列,也可以删除指定的行。
1)删除列
在drop()函数中直接给出要删除的列的列标签就可以删除列。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data.drop(['成本价(元/个)', '成本(元)'], axis=1)
4 print(a)第3行代码为drop()函数设置了两个参数:第1个参数以列表的形式给出要删除的行或列的标签;第2个参数axis用于设置按行删除还是按列删除,设置为0表示按行删除(即第1个参数中给出的标签是行标签),设置为1表示按列删除(即第1个参数中给出的标签是列标签)。因此,第3行代码表示删除“成本价(元/个)”列和“成本(元)”列。
代码运行结果如下:
1 编号 产品 销售价(元/个) 数量(个) 收入(元) 利润(元)
2 0 a001 背包 65 60 3900 2940
3 1 a002 钱包 187 50 9350 4850
4 2 a003 背包 65 23 1495 1127
5 3 a004 手提包 147 26 3822 2886
6 4 a005 钱包 187 78 14586 7566
7 5 a006 单肩包 124 63 7812 4158
8 6 a007 单肩包 124 58 7192 3828还可以通过列序号来获取列标签,然后作为drop()函数的第1个参数使用。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 b = data.drop(data.columns[[2, 5]], axis=1)
4 print(b)第3行代码表示删除数据表data中列序号为2和5的列,即第3列和第6列。
代码运行结果如下:
1 编号 产品 销售价(元/个) 数量(个) 收入(元) 利润(元)
2 0 a001 背包 65 60 3900 2940
3 1 a002 钱包 187 50 9350 4850
4 2 a003 背包 65 23 1495 1127
5 3 a004 手提包 147 26 3822 2886
6 4 a005 钱包 187 78 14586 7566
7 5 a006 单肩包 124 63 7812 4158
8 6 a007 单肩包 124 58 7192 3828也可以通过将列标签以列表的形式传递给drop()函数的参数columns来删除列。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 c = data.drop(columns=['成本价(元/个)', '成本(元)'])
4 print(c)代码运行结果如下:
1 编号 产品 销售价(元/个) 数量(个) 收入(元) 利润(元)
2 0 a001 背包 65 60 3900 2940
3 1 a002 钱包 187 50 9350 4850
4 2 a003 背包 65 23 1495 1127
5 3 a004 手提包 147 26 3822 2886
6 4 a005 钱包 187 78 14586 7566
7 5 a006 单肩包 124 63 7812 4158
8 6 a007 单肩包 124 58 7192 38282)删除行
删除行的方法和删除列的方法类似,都要用到drop()函数,只不过需要将参数axis设置为0。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx', index_col=0)
3 a = data.drop(['a001', 'a004'], axis=0)
4 print(a)第3行代码表示删除行标签为“a001”和“a004”的行,其中的参数axis也可以省略。代码运行结果如下:
1 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 编号
3 a002 钱包 90 187 50 4500 9350 4850
4 a003 背包 16 65 23 368 1495 1127
5 a005 钱包 90 187 78 7020 14586 7566
6 a006 单肩包 58 124 63 3654 7812 4158
7 a007 单肩包 58 124 58 3364 7192 3828同样可以通过行序号来获取行标签,然后作为drop()函数的第1个参数使用。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx', index_col=0)
3 b = data.drop(data.index[[0, 4]], axis=0)
4 print(b)第3行代码表示删除数据表data中行序号为0和4的行,即第1行和第5行。
代码运行结果如下:
1 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 编号
3 a002 钱包 90 187 50 4500 9350 4850
4 a003 背包 16 65 23 368 1495 1127
5 a004 手提包 36 147 26 936 3822 2886
6 a006 单肩包 58 124 63 3654 7812 4158
7 a007 单肩包 58 124 58 3364 7192 3828还可以通过将行标签以列表的形式传递给drop()函数的参数index来删除行。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx', index_col=0)
3 c = data.drop(index=['a001', 'a004'])
4 print(c)代码运行结果如下:
1 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 编号
3 a002 钱包 90 187 50 4500 9350 4850
4 a003 背包 16 65 23 368 1495 1127
5 a005 钱包 90 187 78 7020 14586 7566
6 a006 单肩包 58 124 63 3654 7812 4158
7 a007 单肩包 58 124 58 336 7192 38283. 处理缺失值
代码文件:处理缺失值.py
获取的数据表中可能有部分数据为空值,这些空值就是我们所说的缺失值。下面来学习如何使用pandas模块查看、删除和填充缺失值。
1)查看缺失值
先用read_excel()函数从Excel工作簿中读取一个含有空值的数据表。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 print(data)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16.0 65 60 960.0 3900 2940
3 1 a002 钱包 90.0 187 50 4500.0 9350 4850
4 2 a003 背包 NaN 65 23 368.0 1495 1127
5 3 a004 手提包 36.0 147 26 936.0 3822 2886
6 4 a005 钱包 90.0 187 78 7020.0 14586 7566
7 5 a006 单肩包 58.0 124 63 3654.0 7812 4158
8 6 a007 单肩包 58.0 124 58 NaN 7192 3828在Python中,缺失值一般用NaN表示。从运行结果可以看出,数据表的第3行和第7行含有缺失值。
如果要查看每一列的缺失值情况,可以使用pandas模块中的info()函数。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 print(data.info())代码运行结果如下:
1
2 RangeIndex: 7 entries, 0 to 6
3 Data columns (total 8 columns):
4 编号 7 non-null object
5 产品 7 non-null object
6 成本价(元/个) 6 non-null float64
7 销售价(元/个) 7 non-null int64
8 数量(个) 7 non-null int64
9 成本(元) 6 non-null float64
10 收入(元) 7 non-null int64
11 利润(元) 7 non-null int64
12 dtypes: float64(2), int64(4), object(2)
13 memory usage: 576.0+ bytes 从运行结果可以看出,“成本价(元/个)”列和“成本(元)”列都是“6 non-null”,表示这两列都有6个非空值,而其他列都有7个非空值,说明这两列各有1个空值(即缺失值)。
还可以使用isnull()函数判断数据表中的哪个值是缺失值,并将缺失值标记为True,非缺失值标记为False。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 a = data.isnull()
4 print(a)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 False False False False False False False False
3 1 False False False False False False False False
4 2 False False True False False False False False
5 3 False False False False False False False False
6 4 False False False False False False False False
7 5 False False False False False False False False
8 6 False False False False False True False False2)删除缺失值
使用dropna()函数可以删除数据表中含有缺失值的行。默认情况下,只要某一行中有缺失值,该函数就会把这一行删除。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 b = data.dropna()
4 print(b)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16.0 65 60 960.0 3900 2940
3 1 a002 钱包 90.0 187 50 4500.0 9350 4850
4 3 a004 手提包 36.0 147 26 936.0 3822 2886
5 4 a005 钱包 90.0 187 78 7020.0 14586 7566
6 5 a006 单肩包 58.0 124 63 3654.0 7812 4158如果只想删除整行都为缺失值的行,则需要为dropna()函数设置参数how的值为'all'。演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 c = data.dropna(how='all')
4 print(c)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16.0 65 60 960.0 3900 2940
3 1 a002 钱包 90.0 187 50 4500.0 9350 4850
4 2 a003 背包 NaN 65 23 368.0 1495 1127
5 3 a004 手提包 36.0 147 26 936.0 3822 2886
6 4 a005 钱包 90.0 187 78 7020.0 14586 7566
7 5 a006 单肩包 58.0 124 63 3654.0 7812 4158
8 6 a007 单肩包 58.0 124 58 NaN 7192 3828从运行结果可以看出,因为数据表中不存在整行都为缺失值的行,所以没有行被删除。
3)缺失值的填充
缺失值的处理方式除了删除,还包括填充。使用fillna()函数可以将数据表中的所有缺失值填充为指定的值。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 d = data.fillna(0)
4 print(d)第3行代码表示将数据表中所有的缺失值都填充为0。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16.0 65 60 960.0 3900 2940
3 1 a002 钱包 90.0 187 50 4500.0 9350 4850
4 2 a003 背包 0.0 65 23 368.0 1495 1127
5 3 a004 手提包 36.0 147 26 936.0 3822 2886
6 4 a005 钱包 90.0 187 78 7020.0 14586 7566
7 5 a006 单肩包 58.0 124 63 3654.0 7812 4158
8 6 a007 单肩包 58.0 124 58 0.0 7192 3828还可以通过为fillna()函数传入一个字典,为不同列中的缺失值设置不同的填充值。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表1.xlsx')
3 e = data.fillna({'成本价(元/个)': 16, '成本(元)': 3364})
4 print(e)第3行代码表示将“成本价(元/个)”列中的缺失值填充为16,将“成本(元)”列中的缺失值填充为3364。代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16.0 65 60 960.0 3900 2940
3 1 a002 钱包 90.0 187 50 4500.0 9350 4850
4 2 a003 背包 16.0 65 23 368.0 1495 1127
5 3 a004 手提包 36.0 147 26 936.0 3822 2886
6 4 a005 钱包 90.0 187 78 7020.0 14586 7566
7 5 a006 单肩包 58.0 124 63 3654.0 7812 4158
8 6 a007 单肩包 58.0 124 58 3364.0 7192 38284. 处理重复值
代码文件:处理重复值.py
重复值的常用处理操作包括删除重复值和提取唯一值,前者可以使用drop_duplicates()函数来完成,后者可以使用unique()函数来完成。
1)删除重复行
先用read_excel()函数从Excel工作簿中读取含有重复值的数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表2.xlsx')
3 print(data)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 背包 16 65 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 4 a004 手提包 36 147 26 936 3822 2886
7 5 a005 钱包 90 187 78 7020 14586 7566
8 6 a006 单肩包 58 124 63 3654 7812 4158可以看到,上述数据表的第4行和第5行中每列数据都完全相同,这样的行称为重复行。如果要只保留第4行,删除与第4行重复的行,可直接使用drop_duplicates()函数,无须设置任何参数。
演示代码如下:
1 a = data.drop_duplicates()
2 print(a)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 2 a003 背包 16 65 23 368 1495 1127
5 3 a004 手提包 36 147 26 936 3822 2886
6 5 a005 钱包 90 187 78 7020 14586 7566
7 6 a006 单肩包 58 124 63 3654 7812 41582)删除某一列中的重复值
如果要删除某一列中的重复值,则为drop_duplicates()函数添加参数subset,并设置该参数的值为要处理的列的标签。
演示代码如下:
1 b = data.drop_duplicates(subset='产品')
2 print(b)第1行代码表示删除“产品”列中的重复值。如果要对多列进行删除重复值的操作,则将参数subset设置为一个包含多个列标签的列表。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 3 a004 手提包 36 147 26 936 3822 2886
5 6 a006 单肩包 58 124 63 3654 7812 4158从运行结果可以看出,使用drop_duplicates()函数删除重复值时,默认保留第一个重复值所在的行,删除其他重复值所在的行。可以利用drop_duplicates()函数的参数keep来自定义删除重复值时保留哪个重复值所在的行。例如,将参数keep设置为'first',表示保留第一个重复值所在的行。
演示代码如下:
1 c = data.drop_duplicates(subset='产品', keep='first')
2 print(c)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 0 a001 背包 16 65 60 960 3900 2940
3 1 a002 钱包 90 187 50 4500 9350 4850
4 3 a004 手提包 36 147 26 936 3822 2886
5 6 a006 单肩包 58 124 63 3654 7812 4158如果要保留最后一个重复值所在的行,则将参数keep设置为'last'。
演示代码如下:
1 d = data.drop_duplicates(subset='产品', keep='last')
2 print(d)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 2 a003 背包 16 65 23 368 1495 1127
3 4 a004 手提包 36 147 26 936 3822 2886
4 5 a005 钱包 90 187 78 7020 14586 7566
5 6 a006 单肩包 58 124 63 3654 7812 4158此外,还可以将参数keep设置为False,表示把重复值一个不留地全部删除。
演示代码如下:
1 e = data.drop_duplicates(subset='产品', keep=False)
2 print(e)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 6 a006 单肩包 58 124 63 3654 7812 41583)获取唯一值
使用pandas模块中的unique()函数可以获取某一列数据的唯一值。
演示代码如下:
1 f = data['产品'].unique()
2 print(f)代码运行结果如下:
1 ['背包' '钱包' '手提包' '单肩包']从运行结果可以看出,获取的唯一值是按照其在数据表中出现的顺序排列的。
5. 排序数据
代码文件:排序数据.py
排序数据主要会用到sort_values()函数和rank()函数。sort_values()函数的功能是将数据按照大小进行升序排序或降序排序,rank()函数的功能则是获取数据的排名。
1)用sort_values()函数排序数据
sort_values()函数的常用参数有两个:一个是by,用于指定要排序的列;另一个是ascending,用于指定排序方式是升序还是降序。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表2.xlsx')
3 a = data.sort_values(by='数量(个)', ascending=True)
4 print(a)第3行代码表示对“数量(个)”列进行排序,设置参数ascending为True,表示升序排序。代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 2 a003 背包 16 65 23 368 1495 1127
3 3 a004 手提包 36 147 26 936 3822 2886
4 4 a004 手提包 36 147 26 936 3822 2886
5 1 a002 钱包 90 187 50 4500 9350 4850
6 0 a001 背包 16 65 60 960 3900 2940
7 6 a006 单肩包 58 124 63 3654 7812 4158
8 5 a005 钱包 90 187 78 7020 14586 7566如果要进行降序排序,将参数ascending设置为False即可。
演示代码如下:
1 b = data.sort_values(by='数量(个)', ascending=False)
2 print(b)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 5 a005 钱包 90 187 78 7020 14586 7566
3 6 a006 单肩包 58 124 63 3654 7812 4158
4 0 a001 背包 16 65 60 960 3900 2940
5 1 a002 钱包 90 187 50 4500 9350 4850
6 3 a004 手提包 36 147 26 936 3822 2886
7 4 a004 手提包 36 147 26 936 3822 2886
8 2 a003 背包 16 65 23 368 1495 11272)用rank()函数获取数据的排名
rank()函数的常用参数有两个:一个是method,用于指定数据有重复值时的处理方式;另一个是ascending,用于指定排序方式是升序还是降序。
演示代码如下:
1 c = data['利润(元)'].rank(method='average', ascending=False)
2 print(c)第1行代码中,参数method设置为'average',表示在数据有重复值时,返回重复值的平均排名;参数ascending设置为False,表示降序排序。
代码运行结果如下:
1 0 4.0
2 1 2.0
3 2 7.0
4 3 5.5
5 4 5.5
6 5 1.0
7 6 3.0
8 Name: 利润(元), dtype: float64从运行结果可以看出,参数method设置为'average'时,会将重复值的自然排名取平均值,作为重复值的最终排名。例如,行标签为3和4的数据是重复值,它们的自然排名为5和6,那么就将5和6的平均值5.5作为这两个数据的最终排名。
如果将参数method设置为'first',则表示在数据有重复值时,越先出现的数据排名越靠前。
演示代码如下:
1 d = data['利润(元)'].rank(method='first', ascending=False)
2 print(d)代码运行结果如下:
1 0 4.0
2 1 2.0
3 2 7.0
4 3 5.0
5 4 6.0
6 5 1.0
7 6 3.0
8 Name: 利润(元), dtype: float646. 筛选数据
代码文件:筛选数据.py
根据指定条件对数据进行筛选的演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data[data['产品'] == '单肩包']
4 print(a)第3行代码表示筛选出“产品”列的值等于“单肩包”的数据。需要注意的是,判断两者是否相等要使用比较运算符“==”,不要写成赋值运算符“=”。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 5 a006 单肩包 58 124 63 3654 7812 4158
3 6 a007 单肩包 58 124 58 3364 7192 3828下面使用比较运算符“>”筛选出“数量(个)”列的值大于60的数据,演示代码如下:
1 b = data[data['数量(个)'] > 60]
2 print(b)代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 4 a005 钱包 90 187 78 7020 14586 7566
3 5 a006 单肩包 58 124 63 3654 7812 4158如果要进行多条件筛选,并且这些条件之间是“逻辑与”的关系,可以用“&”符号连接多个筛选条件。需要注意的是,每个条件要分别用括号括起来。
演示代码如下:
1 c = data[(data['产品'] == '单肩包') & (data['数量(个)'] > 60)]
2 print(c)第1行代码表示筛选出“产品”列的值等于“单肩包”且“数量(个)”列的值大于60的数据。代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 5 a006 单肩包 58 124 63 3654 7812 4158如果要进行多条件筛选,并且这些条件之间是“逻辑或”的关系,可以用“|”符号连接多个筛选条件,每个条件也要分别用括号括起来。
演示代码如下:
1 d = data[(data['产品'] == '单肩包') | (data['数量(个)'] > 60)]
2 print(d)第1行代码表示筛选出“产品”列的值等于“单肩包”或“数量(个)”列的值大于60的数据。
代码运行结果如下:
1 编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 4 a005 钱包 90 187 78 7020 14586 7566
3 5 a006 单肩包 58 124 63 3654 7812 4158
4 6 a007 单肩包 58 124 58 3364 7192 38288、数据表的处理
数据表的处理主要是指对数据表中的数据进行行列转置、将数据表转换为树形结构、对多个数据表进行拼接等操作。
1. 转置数据表的行列
代码文件:转置数据表的行列.py
转置行列就是将数据表的行数据转换到列方向上,将列数据转换到行方向上。在pandas模块中,可直接调用DataFrame对象的T属性来转置行列。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data.T
4 print(a)代码运行结果如下:
1 0 1 2 3 4 5 6
2 编号 a001 a002 a003 a004 a005 a006 a007
3 产品 背包 钱包 背包 手提包 钱包 单肩包 单肩包
4 成本价(元/个) 16 90 16 36 90 58 58
5 销售价(元/个) 65 187 65 147 187 124 124
6 数量(个) 60 50 23 26 78 63 58
7 成本(元) 960 4500 368 936 7020 3654 3364
8 收入(元) 3900 9350 1495 3822 14586 7812 7192
9 利润(元) 2940 4850 1127 2886 7566 4158 38282. 将数据表转换为树形结构
代码文件:将数据表转换为树形结构.py
将数据表转换为树形结构就是在维持二维表格的行标签不变的情况下,把列标签也变成行标签,通俗来讲,就是为二维表格建立层次化的索引。
先用read_excel()函数从Excel工作簿中读取一个二维表格型的数据表。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表3.xlsx')
3 print(data)代码运行结果如下:
1 编号 产品 销售价(元/个) 数量(个) 收入(元)
2 0 a001 背包 65 60 3900
3 1 a002 钱包 187 50 9350
4 2 a003 单肩包 124 58 7192随后使用stack()函数将上述数据表转换为树形结构。演示代码如下:
1 a = data.stack()
2 print(a)代码运行结果如下:
1 0 编号 a001
2 产品 背包
3 销售价(元/个) 65
4 数量(个) 60
5 收入(元) 3900
6 1 编号 a002
7 产品 钱包
8 销售价(元/个) 187
9 数量(个) 50
10 收入(元) 9350
11 2 编号 a003
12 产品 单肩包
13 销售价(元/个) 124
14 数量(个) 58
15 收入(元) 7192
16 dtype: object3. 数据表的拼接
代码文件:数据表的拼接.py
数据表的拼接是指将两个或多个数据表合并为一个数据表,主要会用到pandas模块中的merge()函数、concat()函数和append()函数。
1)merge()函数
merge()函数可以根据一个或多个相同的列将不同数据表的行连接起来。
先用read_excel()函数从一个Excel工作簿中读取两个工作表的数据。
演示代码如下:
1 import pandas as pd
2 data1 = pd.read_excel('产品表.xlsx', sheet_name=0)
3 data2 = pd.read_excel('产品表.xlsx', sheet_name=1)
4 print(data1)
5 print(data2)代码运行结果如下:
1 员工编号 员工姓名 员工性别
2 0 a001 张三 男
3 1 a002 李四 女
4 2 a003 王五 男
5 3 a004 赵六 男
6 员工编号 员工姓名 销售业绩
7 0 a001 张三 360000
8 1 a002 李四 458000
9 2 a003 王五 369000
10 3 a004 赵六 450000
11 4 a005 钱七 500000随后使用merge()函数连接数据表data1和data2。
演示代码如下:
1 a = pd.merge(data1, data2)
2 print(a)代码运行结果如下:
1 员工编号 员工姓名 员工性别 销售业绩
2 0 a001 张三 男 360000
3 1 a002 李四 女 458000
4 2 a003 王五 男 369000
5 3 a004 赵六 男 450000从运行结果可以看出,merge()函数直接依据相同的列标签“员工编号”对数据表进行了合并操作,并且选取的是两个表中共有的员工编号的数据,也就是说,默认的合并方式是取交集。如果想合并两个表的所有数据,则需要为merge()函数添加参数how,并设置其值为'outer'。
演示代码如下:
1 b = pd.merge(data1, data2, how='outer')
2 print(b)代码运行结果如下:
1 员工编号 员工姓名 员工性别 销售业绩
2 0 a001 张三 男 360000
3 1 a002 李四 女 458000
4 2 a003 王五 男 369000
5 3 a004 赵六 男 450000
6 4 a005 钱七 NaN 500000如果两个表中相同的列标签不止一个,可以利用参数on来指定依据哪一列进行合并操作。演示代码如下:
1 c = pd.merge(data1, data2, on='员工姓名')
2 print(c)代码运行结果如下:
1 员工编号_x 员工姓名 员工性别 员工编号_y 销售业绩
2 0 a001 张三 男 a001 360000
3 1 a002 李四 女 a002 458000
4 2 a003 王五 男 a003 369000
5 3 a004 赵六 男 a004 4500002)concat()函数
concat()函数采用的是全连接数据的方式,它可以直接将两个或多个数据表合并,即不需要两表的某些列或索引相同,也可以把数据整合到一起。
演示代码如下:
1 d = pd.concat([data1, data2])
2 print(d)代码运行结果如下:
1 员工姓名 员工性别 员工编号 销售业绩
2 0 张三 男 a001 NaN
3 1 李四 女 a002 NaN
4 2 王五 男 a003 NaN
5 3 赵六 男 a004 NaN
6 0 张三 NaN a001 360000.0
7 1 李四 NaN a002 458000.0
8 2 王五 NaN a003 369000.0
9 3 赵六 NaN a004 450000.0
10 4 钱七 NaN a005 500000.0从运行结果可以看出,如果一个表中的列在另外一个表中不存在,则合并后的表中会将该列数据填充为缺失值NaN。此外,合并后的表中每一行的行标签仍然为原先两个表各自的行标签,如果想要重置行标签,可以在concat()函数中设置参数ignore_index为True。
演示代码如下:
1 e = pd.concat([data1, data2], ignore_index=True)
2 print(e)代码运行结果如下:
1 员工姓名 员工性别 员工编号 销售业绩
2 0 张三 男 a001 NaN
3 1 李四 女 a002 NaN
4 2 王五 男 a003 NaN
5 3 赵六 男 a004 NaN
6 4 张三 NaN a001 360000.0
7 5 李四 NaN a002 458000.0
8 6 王五 NaN a003 369000.0
9 7 赵六 NaN a004 450000.0
10 8 钱七 NaN a005 500000.03)append()函数
append()函数的用法比较简单,它可以直接将一个或多个数据表中的数据合并到其他数据表中。演示代码如下:
1 f = data1.append(data2)
2 print(f)代码运行结果如下:
1 员工姓名 员工性别 员工编号 销售业绩
2 0 张三 男 a001 NaN
3 1 李四 女 a002 NaN
4 2 王五 男 a003 NaN
5 3 赵六 男 a004 NaN
6 0 张三 NaN a001 360000.0
7 1 李四 NaN a002 458000.0
8 2 王五 NaN a003 369000.0
9 3 赵六 NaN a004 450000.0
10 4 钱七 NaN a005 500000.0append()函数也可以用于在数据表的末尾追加行数据。
演示代码如下:
1 g = data1.append({'员工编号': 'a005', '员工姓名': '孙七', '员工性别': '男'}, ignore_index=True)
2 print(g)第1行代码在append()函数中传入了一个字典,字典的key(键)为要追加的数据的列标签,value(值)为要追加的数据的值。需要注意的是,在使用append()函数新增行数据时,一定要设置参数ignore_index为True来忽略原有的行标签,并生成一个从0开始的数字序列作为新的行标签,否则会报错。
代码运行结果如下:
1 员工编号 员工姓名 员工性别
2 0 a001 张三 男
3 1 a002 李四 女
4 2 a003 王五 男
5 3 a004 赵六 男
6 4 a005 孙七 男9、数据的运算
数据的运算包含的内容有多个方面,主要有数据的统计运算、数值分布情况的获取、相关系数的计算、数据的分组汇总、数据透视表的创建。
1. 数据的统计运算
代码文件:数据的统计运算.py
常见的统计运算包括求和、求平均值、求最值,分别要用到sum()函数、mean()函数、max()函数和min()函数。
1)求和
pandas模块中的sum()函数可以对数据表的每一列数据分别进行求和。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data.sum()
4 print(a)代码运行结果如下:
1 编号 a001a002a003a004a005a006a007
2 产品 背包钱包背包手提包钱包单肩包单肩包
3 成本价(元/个) 364
4 销售价(元/个) 899
5 数量(个) 358
6 成本(元) 20802
7 收入(元) 48157
8 利润(元) 27355
9 dtype: object从运行结果可以看出,对于非数值数据,运算结果是将它们依次连接得到的一个字符串;对于数值数据,运算结果才是数据之和。
也可以单独对某一列进行求和,演示代码如下:
1 b = data['利润(元)'].sum()
2 print(b)代码运行结果如下:
1 273552)求平均值
pandas模块中的mean()函数可以对数据表的所有数值数据列分别计算平均值。
演示代码如下:
1 c = data.mean()
2 print(c)代码运行结果如下:
1 成本价(元/个) 52.000000
2 销售价(元/个) 128.428571
3 数量(个) 51.142857
4 成本(元) 2971.714286
5 收入(元) 6879.571429
6 利润(元) 3907.857143
7 dtype: float64从运行结果可以看出,所有非数值数据列被自动跳过了。也可以单独对某一列计算平均值,演示代码如下:
1 d = data['利润(元)'].mean()
2 print(d)代码运行结果如下:
1 3907.85714285714273)求最值
pandas模块中的max()函数可以统计每一列数据的最大值,min()函数可以统计每一列数据的最小值。下面以max()函数为例讲解具体用法。
演示代码如下:
1 e = data.max()
2 print(e)代码运行结果如下:
1 编号 a007
2 产品 钱包
3 成本价(元/个) 90
4 销售价(元/个) 187
5 数量(个) 78
6 成本(元) 7020
7 收入(元) 14586
8 利润(元) 7566
9 dtype: object也可以单独对某一列求最大值,演示代码如下:
1 f = data['利润(元)'].max()
2 print(f)代码运行结果如下:
1 75662. 获取数值分布情况
代码文件:获取数值分布情况.py
pandas模块中的describe()函数可以按列获取数据表中所有数值数据的分布情况,包括数据的个数、均值、最值、方差、分位数等。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data.describe()
4 print(a)代码运行结果如下:
1 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 count 7.000000 7.000000 7.000000 7.000000 7.000000 7.000000
3 mean 52.000000 128.428571 51.142857 2971.714286 6879.571429 3907.857143
4 std 31.112698 50.483849 20.053500 2391.447659 4352.763331 2002.194498
5 min 16.000000 65.000000 23.000000 368.000000 1495.000000 1127.000000
6 25% 26.000000 94.500000 38.000000 948.000000 3861.000000 2913.000000
7 50% 58.000000 124.000000 58.000000 3364.000000 7192.000000 3828.000000
8 75% 74.000000 167.000000 61.500000 4077.000000 8581.000000 4504.000000
9 max 90.000000 187.000000 78.000000 7020.000000 14586.000000 7566.000000也可以单独查看某一列数据的分布情况,演示代码如下:
1 b = data['利润(元)'].describe()
2 print(b)代码运行结果如下:
1 count 7.000000
2 mean 3907.857143
3 std 2002.194498
4 min 1127.000000
5 25% 2913.000000
6 50% 3828.000000
7 75% 4504.000000
8 max 7566.000000
9 Name: 利润(元), dtype: float643. 计算相关系数
代码文件:计算相关系数.py
相关系数通常用来衡量两个或多个元素之间的相关程度,使用pandas模块中的corr()函数可以计算相关系数。先用read_excel()函数读取要计算相关系数的数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('相关性分析.xlsx')
3 print(data)代码运行结果如下:
1 代理商编号 年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
2 0 A-001 20.5 5.6 2.00 0.80
3 1 A-003 24.5 16.7 2.54 0.94
4 2 B-002 31.8 20.4 2.96 0.88
5 3 B-006 34.9 22.6 3.02 0.79
6 4 B-008 39.4 25.7 3.14 0.84
7 5 C-003 44.5 28.8 4.00 0.80
8 6 C-004 49.6 32.1 6.84 0.85
9 7 C-007 54.8 35.9 5.60 0.91
10 8 D-006 58.5 38.7 6.45 0.90然后使用corr()函数计算数据表data中各列之间的相关系数。
演示代码如下:
1 a = data.corr()
2 print(a)代码运行结果如下:
1 年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
2 年销售额(万元) 1.000000 0.996275 0.914428 0.218317
3 年广告费投入额(万元) 0.996275 1.000000 0.918404 0.223187
4 成本费用(万元) 0.914428 0.918404 1.000000 0.284286
5 管理费用(万元) 0.218317 0.223187 0.284286 1.000000如果只想查看某一列与其他列的相关系数,可以用列标签来指定列。
演示代码如下:
1 b = data.corr()['年销售额(万元)']
2 print(b)代码运行结果如下:
1 年销售额(万元) 1.000000
2 年广告费投入额(万元) 0.996275
3 成本费用(万元) 0.914428
4 管理费用(万元) 0.218317
5 Name: 年销售额(万元), dtype: float644. 分组汇总数据
代码文件:分组汇总数据.py
pandas模块中的groupby()函数可以对数据进行分组。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = data.groupby('产品')
4 print(a)第3行代码表示依据“产品”列对数据进行分组。代码运行结果如下:
1 从运行结果可以看出,groupby()函数返回的是一个DataFrameGroupBy对象,该对象包含分组后的数据,但是不能直观地显示出来,还需要继续运用函数对其进行求和、求平均值、求最值等特定的汇总计算,以获得更有意义的结果。
例如,依据“产品”列对数据进行分组,再对分组后的数据分别进行求和运算。
演示代码如下:
1 b = data.groupby('产品').sum()
2 print(b)代码运行结果如下:
1 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
2 产品
3 单肩包 116 248 121 7018 15004 7986
4 手提包 36 147 26 936 3822 2886
5 背包 32 130 83 1328 5395 4067
6 钱包 180 374 128 11520 23936 12416如果只想在分组后对某一列进行汇总计算,可以用列标签来指定列。演示代码如下:
1 c = data.groupby('产品')['利润(元)'].sum()
2 print(c)代码运行结果如下:
1 产品
2 单肩包 7986
3 手提包 2886
4 背包 4067
5 钱包 12416
6 Name: 利润(元), dtype: int64当然,也可以选取多列进行分组后的汇总计算。
演示代码如下:
1 d = data.groupby('产品')['数量(个)', '利润(元)'].sum()
2 print(d)代码运行结果如下:
1 数量(个) 利润(元)
2 产品
3 单肩包 121 7986
4 手提包 26 2886
5 背包 83 4067
6 钱包 128 124165. 创建数据透视表
代码文件:创建数据透视表.py
数据透视表可对数据表中的数据进行快速分组和计算。pandas模块中的pivot_table()函数可以制作数据透视表。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('产品统计表.xlsx')
3 a = pd.pivot_table(data, values='利润(元)', index='产品', aggfunc='sum')
4 print(a)第3行代码中,参数values用于指定要计算的列;参数index用于指定一个列作为数据透视表的行标签;参数aggfunc用于指定参数values的计算类型,这里的'sum'表示求和。
代码运行结果如下:
1 利润(元)
2 产品
3 单肩包 7986
4 手提包 2886
5 背包 4067
6 钱包 12416如果要计算的列不止一个,可以为参数values传入一个列表。
演示代码如下:
1 b = pd.pivot_table(data, values=['利润(元)', '成本(元)'], index='产品', aggfunc='sum')
2 print(b)代码运行结果如下:
1 利润(元) 成本(元)
2 产品
3 单肩包 7986 7018
4 手提包 2886 936
5 背包 4067 1328
6 钱包 12416 1152010、案例:获取并分析股票历史数据
代码文件:获取并分析股票历史数据.py
股市中每天都会产生大量的交易数据,分析一只股票的历史数据可以帮助我们预测这只股票的收益。Python的第三方模块Tushare是一个免费且专业的财经数据接口,它能获取指定股票的历史数据,并生成DataFrame类型的数据表,便于我们使用pandas模块对数据进行处理和分析。
下面以“ST天业”为例,讲解获取和分析股票历史数据的方法。在开始编程之前,先使用“pip install tushare”命令安装Tushare模块,然后用搜索引擎查询到“ST天业”的上市时间为1994年1月3日、股票代码为600807。
步骤1:使用Tushare模块中的get_k_data()函数获取“ST天业”的股票历史数据。
演示代码如下:
1 import tushare as ts
2 import pandas as pd
3 tianye = ts.get_k_data(code='600807', start='1994-01-01') # 获取1994年1月1日到今天的所有交易数据
4 print(tianye)第3行代码中,get_k_data()函数的参数code用于指定股票代码,参数start用于指定获取数据的开始时间,如果指定的开始时间比上市时间还早,则获取的数据是从上市时间开始的。
代码运行结果如下图所示。可以看到,尽管代码中指定的开始时间是1994年1月1日,但是获取到的数据是从该股票的上市时间1994年1月3日开始的。

步骤2:将获取到的数据存储为csv文件。
演示代码如下:
1 tianye.to_csv('tianye.csv')步骤3:读取csv文件,将date列作为行标签,并将该列数据转换为date(日期)类型,以便做数据分析。
演示代码如下:
1 Tianye = pd.read_csv('tianye.csv', index_col='date', parse_dates=['date']) # 将date列作为行标签,并将该列数据转换为date(日期)类型
2 print(Tianye)代码运行结果如下图所示:

步骤4:因为10年前的数据对于现在进行股票数据预测的帮助不是很大,所以需要对数据进行时间范围选择,这里只选择2010—2019年的数据。
演示代码如下:
1 Tianye = Tianye['2010':'2019'] # 使用行标签做切片获取2010—2019年的数据步骤5:假设我们从2010年开始,每月第一天以开盘价买入1000股该股票,当月最后一天以收盘价全部卖出,计算出2010—2019年的收益。
演示代码如下:
1 month_first = Tianye.resample('M').first() # 获取每月第一天的股价数据
2 month_first_money = month_first['open'].sum() * 1000 # 计算每月第一天以开盘价买入1000股该股票的总支出
3 month_max = Tianye.resample('M').last() # 获取每月最后一天的股价数据
4 month_max_money = month_max['close'].sum() * 1000 # 计算每月最后一天以收盘价卖出的总收入
5 get_money = month_max_money - month_first_money # 计算10年收益
6 print(get_money)第1行和第3行代码使用resample()函数重新取样,参数值'M'代表按月分组,first()函数用于获取每月第一天的数据,last()函数则用于获取每月最后一天的数据。代码的运行结果就是10年的收益。
需要说明的是,本案例的侧重点是讲解Tushare和pandas模块的使用,而不是股票的投资方法。
为了不增加代码的复杂度,本案例采用了一种非常简单的交易策略,实践中采用的策略要复杂得多。
提示
目前Tushare模块已升级为Tushare Pro版本。Tushare Pro的安装方法同旧版本一样,也是使用“pip install tushare”命令。如果读者已经安装了旧版本的Tushare模块,可以使用“pip install tushare --upgrade”命令升级到Tushare Pro。
安装了Tushare Pro后,旧版本的函数目前还可以正常使用,只是在运行过程中会收到如下所示的提示信息:
1 本接口即将停止更新,请尽快使用Pro版接口:https://waditu.com/document/2如果旧版本的函数已能满足工作需求,可不必理会上述提示信息。如果读者对Tushare Pro感兴趣,可以访问提示信息中给出的网址做进一步了解。这里也对Tushare Pro做一个简单的介绍。
Tushare Pro大幅提升了数据稳定性和获取速度,并将数据内容扩展到股票、基金、期货、债券、外汇、数字货币等领域,极大地减轻了金融分析人员在金融数据采集、加工、存储过程中的工作量。
为了避免少部分用户无限制地恶意调取数据,更好地保证大多数用户调取数据的稳定性,Tushare Pro引入了积分制度,不同积分级别的用户拥有不同的数据调取权限。用户需要在Tushare Pro的官网注册账号并获取token凭证,在Python代码中使用token凭证才能调取数据,下面就来介绍具体步骤。
步骤1:在浏览器中访问Tushare社区门户,网址为https://waditu.com,单击右上角的“注册”按钮,注册一个账号并进行登录。注册和登录的操作比较简单,这里就不详细讲解了。
步骤2:完成登录后,单击页面右上角的用户账号,在展开的列表中单击“个人主页”选项,如下图所示:

步骤3:在“用户中心”界面可看到用户信息,其中最重要的是积分,积分的多少决定了用户能调取哪些数据。
单击“接口TOKEN”按钮,如下图所示:
步骤4:在“接口令牌”界面可看到自己的token凭证。单击右侧眼睛形状的按钮,可查看token凭证的明文。单击右侧的“复制”按钮,可复制token凭证,如下图所示。token凭证是调取金融数据的唯一凭证,需妥善保管。

如果发现自己的token凭证被别人盗用,可在本页面单击“刷新”按钮,生成新的token凭证,之前的token凭证将失效。
完成账号的注册和token凭证的获取后,就可以在Python代码中使用Tushare Pro获取金融数据了。下面以获取股票日线行情数据为例,介绍Tushare Pro的用法。
演示代码如下:
1 import tushare as ts
2 ts.set_token('6f440************************************e8a33')
3 pro = ts.pro_api()
4 df = pro.daily(trade_date='20200918')
5 print(df)第1行代码用于导入Tushare模块(版本必须高于1.2.10)。第2行代码用于设置token凭证,括号里的字符串内容就是前面步骤4中复制的token凭证。第3行代码用于初始化Tushare Pro的接口。第4行代码使用daily()函数获取2020年9月18日的所有股票的行情数据。
运行以上代码,即可得到如下图所示的日线行情数据:

因为旧版本Tushare模块的函数还可以免费正常使用,后面有关Tushare模块的内容还是以讲解旧版本的函数为主。
四、Python数据分析实战
前面介绍了NumPy、pandas等模块让Python拥有了非常强大的数据分析能力,可以轻松应对实战中的各种数据分析问题。
这里将结合典型案例详细介绍如何使用Python来完成几类基础的数据分析,如相关性分析、假设检验、方差分析、描述性统计分析、线性回归分析等。
1、相关性分析
相关性分析是指对多个可能具备相关关系的变量进行分析,从而衡量变量之间的相关程度或密切程度。本节将通过计算皮尔逊相关系数,判断两只股票的股价数据的相关程度。
1. 获取股价数据
代码文件:获取股价数据.py
要分析股价数据的相关程度,首先就要获取股价数据。我们已经初步接触了可以获取股票历史数据的Python第三方模块Tushare,下面就来全面详细地学习这个模块的使用方法。
1)获取日K线级别的股价数据
使用Tushare模块中的get_hist_data()函数可获取日K线级别的股价数据。演示代码如下:
1 import tushare as ts
2 data = ts.get_hist_data('000061', start='2018-01-01', end='2019-01-01')
3 print(data.head(10))第1行代码导入Tushare模块,并简写为ts,以方便后面调用该模块中的函数。
第2行代码使用get_hist_data()函数获取股票代码为000061的股票从2018年1月1日到2019年1月1日的日K线级别的股价数据,得到的是一个DataFrame类型的二维数据表。get_hist_data()函数中的第1个参数为股票代码,通常为6位数字;第2个参数start和第3个参数end分别表示开始日期和结束日期,日期格式为YYYY-MM-DD。
第3行代码使用head()函数输出前10行数据。
代码运行结果如下图所示:

上图中各列数据的含义见下表:
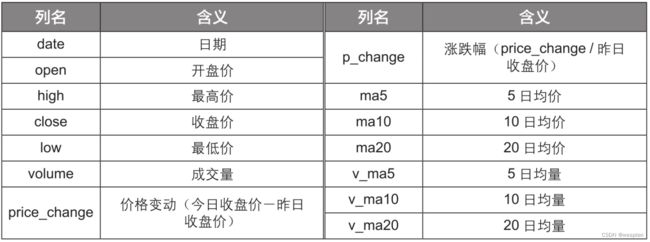
某些编辑器(如PyCharm)在使用print()函数打印输出数据结果时有可能不会显示所有列,此时可以在上面的代码中添加两行代码来强制显示所有列。
演示代码如下:
1 import pandas as pd
2 pd.set_option('display.max_columns', None)2)获取分钟级别的股价数据
使用get_hist_data()函数还可以获取分钟级别的股价数据。
演示代码如下:
1 data = ts.get_hist_data('000061', ktype='5')代码中为get_hist_data()函数设置的参数ktype表示获取数据的类型,其值为'D'、'W'、'M'时分别表示获取日K线、周K线、月K线级别的数据,为'5'、'15'、'30'、'60'时分别表示获取5分钟、15分钟、30分钟、60分钟级别的数据。
运行代码后,得到的数据如下图所示:
最后一列turnover是换手率。

3)获取实时股价数据
如果要获取实时的股价数据,可以使用Tushare模块中的get_realtime_quotes()函数。演示代码如下:
1 data = ts.get_realtime_quotes('000061')运行代码后,会得到股票代码为000061的股票在当时的行情数据,这个数据有1行33列。如果觉得列数太多,可以通过DataFrame对象选取列的方法选取需要的列。
演示代码如下:
1 data = data[['code', 'name', 'price', 'bid', 'ask', 'volume', 'amount', 'date', 'time']]运行代码后,得到的数据如下图所示:

4) 获取分笔股价数据
分笔股价数据是指每笔成交的信息,可以使用Tushare模块中的get_tick_data()函数来获取。
演示代码如下:
1 data = ts.get_tick_data('000002', date='2018-12-12', src='tt')运行代码后,得到的数据如下图所示。其中的change表示价格变动,amount表示成交金额(元),type表示买卖类型(买盘、卖盘、中性盘)。

5)获取指数信息
指数信息是指大盘指数的实时行情数据,可以使用Tushare模块中的get_index()函数来获取。演示代码如下:
1 data = ts.get_index()运行代码后,得到的数据如下图所示。其中的change表示涨跌幅,preclose表示昨日收盘点位。

2. 合并股价数据
代码文件:合并股价数据.py
学习完Tushare模块的用法后,接下来就利用该模块获取用于相关性分析的股价数据。假设要分析的两只股票的股票代码分别为000061和399300,用于计算相关系数的股价数据是2018年1月1日到2019年1月1日的日K线级别的数据,获取数据后将其保存到Excel工作簿中。
演示代码如下:
1 import tushare as ts
2 data = ts.get_hist_data('000061', start='2018-01-01', end='2019-01-01')
3 data.to_excel('农产品.xlsx')
4 data1 = ts.get_hist_data('399300', start='2018-01-01', end='2019-01-01')
5 data1.to_excel('沪深300.xlsx')运行代码后,在代码文件所在的文件夹下会生成两个Excel工作簿。打开工作簿“农产品.xlsx”,可看到股票代码000061的股价数据,如下图所示。
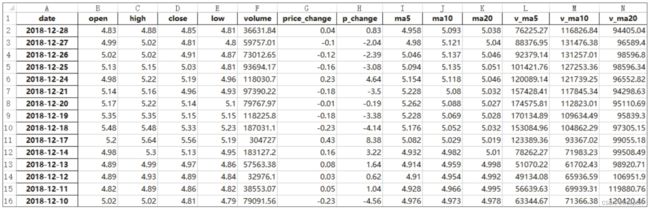
打开工作簿“沪深300.xlsx”,可看到股票代码399300的股价数据,如下图所示:

可以发现,获取的股价数据的日期是不连续的,这是因为股市并不是每天都开市,所以周末和节假日没有股价数据。
接下来使用pandas模块中的merge()函数将两个Excel工作簿中的数据合并到一个Excel工作簿中,便于后面分析两只股票股价的相关性。
演示代码如下:
1 import pandas as pd
2 stock = pd.read_excel('农产品.xlsx')
3 stock = stock[['date', 'close']]
4 stock = stock.rename(columns={'close': 'price_农产品'})
5 stock1 = pd.read_excel('沪深300.xlsx')
6 stock1 = stock1[['date', 'close']]
7 stock1 = stock1.rename(columns={'close': 'price_沪深300'})
8 data_merge = pd.merge(stock, stock1, on='date', how='inner')
9 data_merge.to_excel('合并股价数据.xlsx', index=False)第1行代码导入pandas模块,并简写为pd。
第2~4行代码读取Excel工作簿“农产品.xlsx”中的数据,并且只选取其中的“date”和“close”两列数据,随后使用rename()函数将“close”列重命名为“price_农产品”。
第5~7行代码读取Excel工作簿“沪深300.xlsx”中的数据,并且也只选取其中的“date”和“close”两列数据,随后使用rename()函数将“close”列重命名为“price_沪深300”。
第8行和第9行代码使用merge()函数将更改列名后的数据合并到一个数据表中,再使用to_excel()函数将合并后的数据表写入名为“合并股价数据.xlsx”的Excel工作簿中。
运行代码后,得到如下图所示的数据表:

3. 股价数据相关性分析
代码文件:股价数据相关性分析.py
在实际工作中,为了做出更科学的决策,常常需要研究若干数据之间是否存在关联,如此增彼长或此消彼长等,以及这种关联的密切程度。下面就来介绍一个对数据的相关性进行定量分析的主要工具——皮尔逊相关系数。
皮尔逊相关系数(Pearson correlation coefficient)是一个用于反映两个随机变量之间的线性相关程度的统计指标,通常用r表示。
皮尔逊相关系数的计算公式如下:
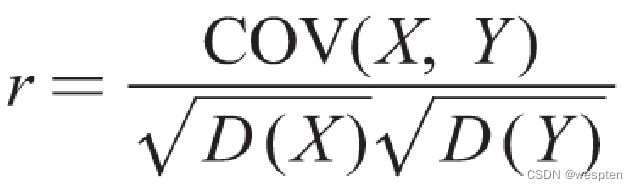
其中COV(X, Y)是变量X和变量Y的协方差,D(X)和D(Y)分别为变量X和变量Y的方差。

分别为变量X和变量Y的标准差。
由公式可知,皮尔逊相关系数是用两个变量的协方差除以两个变量的标准差得到的。虽然协方差能反映两个随机变量的相关程度(协方差为正值表示两者正相关,为负值表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的相关程度。例如,在二维空间中分布着一些数据点,我们想知道数据点的x坐标和y坐标的相关程度,如果两者的相关程度较小但是数据分布得比较离散,就会导致求出的协方差值较大,用这个值来度量相关程度是不合理的。因此,为了更好地度量两个随机变量的相关程度,引入了皮尔逊相关系数。
r的取值范围为[-1,1]。r的正负表示相关性的类型:r为正值表示线性正相关,即两个变量的增长趋势相同;r为负值表示线性负相关,即两个变量的增长趋势相反;r为0表示不存在线性相关性。r的绝对值表示相关性的强弱,绝对值越接近1,说明相关性越强。
需要注意的是,r的绝对值小不一定意味着变量之间的相关性弱。这是因为r衡量的仅仅是变量之间的线性相关关系,而变量之间的关系除了线性关系之外,还有指数关系、多项式关系、幂关系等,这些“非线性相关”的关系不在r的衡量范围之内。
在实际工作中,我们通常不需要自己编写计算皮尔逊相关系数的代码,因为许多Python第三方模块已经封装好了计算皮尔逊相关系数的函数。这里使用SciPy模块中的pearsonr()函数计算皮尔逊相关系数。
演示代码如下:
1 from scipy.stats import pearsonr
2 corr = pearsonr(X, Y)给pearsonr()函数传入两个数组,会返回一个包含两个元素的元组,两个元素分别代表皮尔逊相关系数r和显著性水平P值。r的含义前面已经讲解过,而P值与皮尔逊相关显著性检验有关,P<0.05时表示显著相关,即两个变量之间真的存在相关性,而不是由偶然因素引起的。只有在显著相关的前提下,r的值才有意义。
简单来说,在使用pearsonr()函数计算出结果后,要先根据P值是否小于0.05来判断两个变量之间是否真的存在相关性,再根据r的正负判断相关性的类型,根据r的绝对值判断相关性的强弱。
学习完皮尔逊相关系数的计算和使用方法,下面就对处理好的两只股票的股价数据进行相关性的计算。
演示代码如下:
1 import pandas as pd
2 from scipy.stats import pearsonr
3 data = pd.read_excel('合并股价数据.xlsx')
4 corr = pearsonr(data['price_农产品'], data['price_沪深300'])
5 print('相关系数r值为' + str(corr[0]) + ',显著性水平P值为' + str(corr[1]))第4行代码表示用“price_农产品”列和“price_沪深300”列的数据计算相关性。
此外,因为pearsonr()函数返回的元组的两个元素是浮点型数字,所以在第5行代码中进行字符串拼接时就需要使用str()函数将这两个浮点型数字转换成字符串。
代码运行结果如下:
1 相关系数r值为0.9424989951941217,显著性水平P值为6.213473367651319e-112从运行结果可以看出,显著性水平P值约为6.213×10-112,满足小于0.05的条件,说明“price_农产品”列和“price_沪深300”列的数据显著相关,即它们的确具有相关性。相关系数r值约为0.942,为正值,且绝对值接近1,说明“price_农产品”列和“price_沪深300”列的数据具有较强的线性正相关性。最后可以得出结论:000061和399300这两只股票的股价具有较强的线性正相关性,即增长趋势基本相同。
2、假设检验
代码文件:假设检验.py
事物的个体差异总是客观存在的,抽样的误差也就不可避免。我们不能只依据个别样本的值来对整体数据下结论。当一些样本均数与已知的总体均数有很大的差别时,一般来说有两点主要原因:一是抽样误差的偶然性;二是样本来自不同的总体,从而使得试验因素不同。此时,运用假设检验方法就能够排除误差的影响,区分差别在统计上是否成立,并了解误差事件发生的概率。
假设检验又称为显著性检验,是统计推断中的一种重要的数据统计方法。它首先对研究总体的参数做出某种假设,然后从总体中抽取样本进行观察,用样本提供的信息对假设的正确性进行判断,从而决定假设是否成立。若观察结果与理论不符,则假设不成立;若观察结果与理论相符,则认为没有充分的证据表明假设错误。
在实际工作中广泛使用的假设检验主要有t检验、z检验、F检验。
t检验是一种推论统计量,用于确定在某些特征中两组的均值之间是否存在显著差异,主要用于数据集。t检验主要有两种类型:单样本t检验和双样本t检验。单样本t检验用于确定样本均值是否与已知或假设的总体均值具有统计学差异。双样本t检验用于比较两个独立组的均值,以确定是否有统计证据表明这两个独立组存在显著差异。
z检验用于在两组样本的总体方差未知时,检验两组数据表现情况的差异。它与t检验的区别在于:z检验常用于样本量较大的情况;而t检验则用于样本量较小、总体标准差未知的正态分布情况的数据。
F检验用于检验两个正态随机变量的总体方差是否相等,常用于判断应该选择使用t检验中的哪种检验方法,根据该检验方法计算出的方差比值可以用来检验两组数据是否存在显著性差异。
这一节主要介绍如何使用t检验分析两个品种水稻的产量是否存在显著性差异。

已知在Excel工作簿“样本数据.xlsx”中记录了两种水稻在8个地区的单位面积产量,具体数据如右图所示。水稻的品种分别用A和B表示。
现在需要在置信度为95%的前提下,使用t检验判断两种水稻的产量是否有显著性差异。提出的假设是两种水稻的产量没有显著性差异。
使用Python的第三方模块SciPy即可进行t检验。先用pandas模块从Excel工作簿中读取要进行t检验的数据。
演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('样本数据.xlsx')
3 print(data.head())运行代码后,可看到读取的数据的前5行。
1 品种 产量
2 0 A 85
3 1 A 87
4 2 A 56
5 3 A 90
6 4 A 84随后把A品种水稻和B品种水稻的产量分别赋给变量x和变量y。
演示代码如下:
1 x = data[data['品种'] == 'A']['产量']
2 y = data[data['品种'] == 'B']['产量']然后导入SciPy模块,调用进行双样本t检验的ttest_ind()函数检验这两种水稻的产量是否有显著性差异。
演示代码如下:
1 from scipy.stats import ttest_ind
2 print(ttest_ind(x, y))代码运行结果如下:
1 Ttest_indResult(statistic=1.0044570121313174, pvalue=0.3322044373983689)运行结果中的pvalue就是计算出的显著性水平P值。如果P值小于选定的显著性水平,则拒绝原假设;如果P值远大于选定的显著性水平,则不拒绝原假设。
前面选定的置信度为95%,则选定的显著性水平为1-95%=5%=0.05。这里计算出的P值约为0.332,远大于选定的显著性水平0.05,因此不拒绝原假设,即认为这两个品种水稻的产量并没有显著性差异。
3、描述性统计分析
代码文件:描述性统计分析.py
描述性统计分析主要指求一组数据的平均值、中位数、众数、极差、方差和标准差等指标,通过这些指标来发现这组数据的分布状态、数字特征等内在规律。在Python中进行描述性统计分析,可以借助NumPy、pandas、SciPy等科学计算模块计算出指标,然后用绘图模块Matplotlib绘制出数据的分布状态和频率及频数直方图,以更直观的方式展示数据分析的结果。
1. 描述性统计指标的计算
假设某企业要对销售人员实行销售业绩目标管理,根据目标完成情况采取相应的奖惩措施。销售业绩目标的制定大有学问,目标定得太高会导致很多员工因为不能完成任务而失去工作的信心,目标定得过低则不利于激发员工的工作积极性。
为了更科学地制定目标,销售部经理从企业的几百名销售人员中随机抽取了100人,并将他们在前年的销售业绩数据制作成一张统计表格,保存在一个Excel工作簿中,如下图所示。

经过初步观察,销售部经理发现这100人中有很大一部分人的销售业绩都在一定的区间内徘徊,因此,可以基于这100人的销售业绩的均值、中位数、众数等描述性统计指标,估算出销售业绩目标。下面就用Python编程来完成计算。先从Excel工作簿中读取数据,演示代码如下:
1 import pandas as pd
2 data = pd.read_excel('销售业绩统计.xlsx', index_col='序号')
3 print(data.head())代码运行结果如下:
1 销售业绩(万元)
2 序号
3 1 33.02
4 2 11.63
5 3 33.15
6 4 35.45
7 5 15.64描述性统计指标的计算需要用到NumPy模块和SciPy模块。
SciPy是一个基于NumPy模块开发的高级模块,它提供了许多用于解决科学计算问题的数学算法和函数,而且在符号计算、信号处理、数值优化等方面有突出表现。SciPy模块包含很多子模块,其中,子模块stats在统计分布分析方面有很大的作用。
下面就一起来看看如何使用NumPy模块和SciPy模块进行描述性统计分析。
首先计算100名销售人员的销售业绩的均值、中位数和众数。演示代码如下:
1 from numpy import mean, median
2 from scipy.stats import mode
3 mean = mean(data['销售业绩(万元)'])
4 median = median(data['销售业绩(万元)'])
5 mode = mode(data['销售业绩(万元)'])[0][0]
6 print('均值:' + str(mean))
7 print('中位数:' + str(median))
8 print('众数:' + str(mode))第3行和第4行代码中的mean()和median()是NumPy模块中的函数,用于计算一组数据的均值和中位数。均值就是算术平均数。中位数是指将一组数据升序排列,位于该组数据最中间位置的值,如果数据个数为偶数,则取中间两个值的均值为中位数。
第5行代码中的mode()是SciPy模块的子模块stats中的函数,这个函数用于寻找一组数据中的众数及众数出现的次数。众数是在一组数据中出现次数最多的值,常用于描述一般水平。在一组数据中可能存在多个众数,如在1、2、2、3、3、4、5中,2和3均为众数;也可能不存在众数,如在1、2、3、4、5中就不存在众数。众数不仅适用于数值型数据,也适用于非数值型数据,如在“苹果、苹果、香蕉、桃”中,“苹果”就是众数。因为一组数据可能存在多个众数,所以第5行代码中用切片格式“[0][0]”获取数据中第一个位置的众数。
代码运行结果如下:
1 均值:27.952599999999993
2 中位数:30.455
3 众数:36.45均值、中位数和众数主要用于描述数据的集中趋势,它们各有优点和缺点。均值可以充分利用所有数据,但是容易受到极端值的影响;中位数不受极端值的影响,但是缺乏敏感性;众数也不受极端值的影响,且当数据具有明显的集中趋势时,代表性好,但是缺乏唯一性。
因此,在分析了数据的集中趋势,也就是数据的中心位置后,一般会想要知道数据以中心位置为标准有多发散,也就是分析数据的离散程度。如果以中心位置来预测新数据,那么离散程度决定了预测的准确性。数据的离散程度可用极差、方差和标准差来衡量。
极差是指一组数据中最大值与最小值的差。
方差是每个样本值与总体均值之差的平方值的均值,体现每个样本值偏离总体均值的程度。标准差是方差的开方。使用NumPy模块中的ptp()、var()和std()函数可以分别计算数据的极差、方差和标准差。
演示代码如下:
1 from numpy import ptp, var, std
2 ptp = ptp(data['销售业绩(万元)'])
3 var = var(data['销售业绩(万元)'])
4 std = std(data['销售业绩(万元)'])
5 print('极差:' + str(ptp))
6 print('方差:' + str(var))
7 print('标准差:' + str(std))代码运行结果如下:
1 极差:45.42
2 方差:146.67877524000002
3 标准差:12.12. 数据的分布状态分析
根据数据的分布是否对称,数据的分布状态可分为正态分布与偏态分布。偏态分布又分为正偏态分布与负偏态分布:若众数<中位数<均值,则为正偏态分布;若均值<中位数<众数,则为负偏态分布。
偏度和峰度是描述数据分布状态时常用的两个概念,它们描述的是数据的分布状态与正态分布的偏离程度。
偏度是数据分布的偏斜方向和程度的度量,常用于衡量随机分布的不均衡性。如果数据对称分布,如标准正态分布,则偏度为0;如果数据左偏分布,则偏度小于0;如果数据右偏分布,则偏度大于0。
峰度用来描述数据分布陡峭或平滑的情况,可以理解为数据分布的高矮程度。峰度的比较是相对于标准正态分布而言的:标准正态分布的峰度为3;峰度越大,代表分布越陡峭,尾部越厚;峰度越小,代表分布越平滑。很多情况下,将峰度值减3,让标准正态分布的峰度变为0,以方便比较。
先来计算标准正态分布的偏度和峰度。
演示代码如下:
1 import numpy as np
2 standard_normal = pd.Series(np.random.normal(0, 1, size=1000000))
3 normal_p = standard_normal.skew()
4 normal_f = standard_normal.kurt()
5 print('标准正态分布的偏度:' + str(normal_p))
6 print('标准正态分布的峰度:' + str(normal_f))第2行代码使用NumPy模块的子模块random中的normal()函数生成一组符合正态分布的随机数。normal()函数的前两个参数分别代表正态分布的均值和标准差,这里分别设置为0和1,表示生成的随机数符合标准正态分布。
第3行代码中的skew()函数用于统计随机数的偏度。第4行代码中的kurt()函数用于统计随机数的峰度。
代码运行结果如下:
1 标准正态分布的偏度:-0.000727961870080489
2 标准正态分布的峰度:0.001021764823831539接着计算销售业绩数据的偏度和峰度。
演示代码如下:
1 p = data['销售业绩(万元)'].skew()
2 f = data['销售业绩(万元)'].kurt()
3 print('偏度:' + str(p))
4 print('峰度:' + str(f))代码运行结果如下:
1 偏度:0.03279571847827727
2 峰度:-0.9749688324183667完成了偏度和峰度的计算后,就可以绘制标准正态分布图和销售业绩的分布图了。在Python中,常用Matplotlib模块来绘制图表。这里我们还要结合使用Seaborn模块,它是基于Matplotlib模块开发的,不需要进行复杂的参数设置就能绘制出外观精美的图表。
演示代码如下:
1 import seaborn as sns
2 import matplotlib.pyplot as plt
3 plt.rcParams['font.sans-serif'] = ['SimHei']
4 plt.rcParams['axes.unicode_minus'] = False
5 sns.kdeplot(standard_normal, shade=True, label='标准正态分布')
6 sns.kdeplot(data['销售业绩(万元)'], shade=True, label='销售业绩分布')
7 plt.show()第1行和第2行代码导入绘图需要的模块。第3行和第4行代码用于解决Matplotlib模块在绘图时默认不支持显示中文的问题。
第5行和第6行代码使用Seaborn模块中的kdeplot()函数绘制分布图。kdeplot()函数的功能是对单变量和双变量进行核密度估计及可视化,可以帮助我们比较直观地看出样本数据的分布特征。核密度估计是在概率论中用来估计未知数的密度函数,属于非参数检验方法之一。
kdeplot()函数的参数shade用于控制是否用颜色填充核密度估计曲线下的面积,为True时代表填充;参数label用于指定图例的显示内容。
第7行代码使用Matplotlib模块中的show()函数显示绘制的分布图。
代码运行结果如下图所示:
只观察分布图可能无法直观判断销售业绩的分布特征,但由计算结果可知,销售业绩的均值<中位数<众数,所以销售业绩的分布状态属于负偏态分布。
3. 数据的频数和频率分析
完成了描述性统计指标的计算和数据的分布状态分析后,还可以通过绘制直方图来分析数据的分布情况:先统计一组数据的每个分段中值的个数,然后根据统计结果绘制类似柱形图的图表,可以更直观地展示数据的频数或频率分布情况。
频数是指数据中的类别变量的每种取值出现的次数。频率是指每个类别变量的频数与总次数的比值,通常用百分数表示。
计算频数和频率的演示代码如下:
1 frequency = data['销售业绩(万元)'].value_counts()
2 percentage = frequency / len(data['销售业绩(万元)'])
3 print(frequency.head())
4 print(percentage.head())第1行代码中的value_counts()函数用于计算数据的频数。第2行代码中的len()函数用于计算“销售业绩(万元)”列的长度,即该列中数据的个数。
代码运行结果如下:
1 50.45 2
2 36.45 2
3 40.36 2
4 40.26 2
5 22.63 1
6 Name: 销售业绩(万元), dtype: int64
7 50.45 0.02
8 36.45 0.02
9 40.36 0.02
10 40.26 0.02
11 22.63 0.01
12 Name: 销售业绩(万元), dtype: float64接着使用Matplotlib模块中的hist()函数绘制频数分布直方图。
演示代码如下:
1 import matplotlib.pyplot as plt
2 plt.rcParams['font.sans-serif'] = ['SimHei']
3 plt.rcParams['axes.unicode_minus'] = False
4 plt.hist(data['销售业绩(万元)'], bins=9, density=False, color='g', edgecolor='k', alpha=0.75)
5 plt.xlabel('销售业绩')
6 plt.ylabel('频数')
7 plt.title('销售业绩频数分布直方图')
8 plt.show()第4行代码中,hist()函数的第1个参数是用于绘制直方图的一维数组;参数bins用于指定绘制的直方图的柱子个数,即数据分段的数量;参数density为False时表示绘制频数分布直方图,为True时表示绘制频率分布直方图;参数color用于设置直方图柱子的填充颜色,这里的'g'代表绿色;参数edgecolor用于设置直方图柱子的轮廓颜色,这里的'k'代表黑色;参数alpha用于设置柱子颜色的透明度。
第5行和第6行代码中的xlabel()和ylabel()函数分别用于设置x轴和y轴的标题内容。第7行代码中的title()函数用于设置图表标题。第8行代码则用于显示绘制的直方图。
代码运行结果如下图所示:
如果要绘制频率分布直方图,可以在hist()函数中设置参数density为True,并将第6行代码ylabel()函数中的y轴标题更改为“频率/组距”,将第7行代码title()函数中的图表标题更改为“销售业绩频率分布直方图”。
代码运行结果如下图所示:

hist()函数的参数bins的值设置为一个整型数字时表示自动均匀分组,也可以自行设定分组组距,如设置bins=[5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55]。
代码运行结果如下图所示:
从直方图可以看出,抽取的100名销售人员的销售业绩在30万元~35万元区间内的人数最多。得到销售业绩的均值、中位数和众数分别约为27.95、30.46和36.45。结合描述统计中的各项指标数据以及直方图中的销售业绩频数和频率分布情况,可将销售人员的销售业绩目标定在30万元~35万元之间,因为这个区间的销售业绩是大多数人能够完成的。