面试题 分库分表、主从同步
一、数据库中间件简介
一台数据库服务器(8核16G)一般控制在不超过每秒2000的读写并发
1、client模式
1)介绍:引入一个jar包,程序操作SQL就调用通用接口,接口内部会重写SQL,去相对应的表执行SQL
2)举例:sharding-jdbc
3)优势:直接引入jar包,进行一些配置即可
4)缺点:对于分布式系统来说,如果这个jar包需要升级了,那么几乎每个服务都要升级,比较麻烦,所以推荐中小公司使用
2、proxy模式
1)介绍: 通过一个代理数据库服务来管理多个数据库实例,程序只连接这个代理数据库服务,所有的SQL也是通过代理服务来执行
2)举例:mycat、dble
3)优势:只要修改现有程序的数据库链接即可,不需修改代码
4)缺点:需要专人运维,并且这个代理数据库服务也需要是高可用的,否则数据库没挂它挂了也不行,所以推荐大公司使用
二、如何把单表结构数据迁移到分库分表结构
1、停机迁移
在凌晨发布公告,停止服务后迁移数据,但一旦迁移出现问题,时间不够了,就只能回滚,等下次再重试,不太建议
2、双写迁移方案
修改写库代码,同时往2个库写,再把老库的历史数据写到新库。写入时先查询新表有无数据,如果没有,就直接insert,如果有,就比较updateTime,如果新表的upateTime比旧表小,就更新到新表,具体的更新逻辑要看业务
三、如何设计动态扩容缩容的分库分表方案
1、停机扩容
跟停机迁移一样,如果数据量太大,导数据就会花很多时间,导致停机时间过长,不太建议
2、只扩数据库服务器,不扩库和表
将数据库服务器上的部分库迁移到别的数据库服务器上,可以不用写代码,直接使用现成的工具迁移。比如有4台数据库服务器,每个服务器上有8个库,每个库有32张表,按每个数据库服务器2000的写并发、1t的容量算,总共就是8000的写并发、4t的容量。然后开始扩容,将每台服务器上的其中4个库迁到新的服务器上,这样就是8台数据库服务器,每个服务器上4个库,库和表的总数没有变,但现在可以支持16000的写并发,8t的容量
四、分库分表后全局id如何生成
1、自增id
适用于单表环境,多表环境下id会重复
2、uuid
好处在于几乎不会重复,但uuid太长了,不适合做主键。适合随机生成文件名、编号的场景
3、业务字段拼接成主键
将几个业务字段拼接起来生成主键,这样查询也可以直接使用主键查询。但要注意不能重复,如果太长了也不适合做主键
4、snowflake算法
是twitter的开源算法,高并发、分布式环境下推荐使用,流程如下:
- 部署一个微服务提供接口,内部实现snowflake算法
- 各微服务在存储数据时,会调用接口获取id
- snowflake服务获取到调用方的机器信息,比如哪个机房、哪台机器、机器ip、机器端口这些
- 根据这些信息,通过算法计算出一个64位Long型的id,是全局唯一的,然后返回给调用方
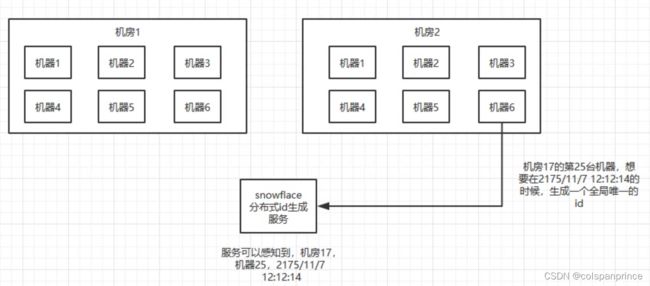
这个64位的id是这样构成的,首位固定0 + 41位的数据时间 + 5位的库 + 5位的表 + 12位的序号,生成逻辑如下:
- 根据存储时间,转成时间戳,再转成二进制,得到一串41位的二进制
- 根据机房id,转成二进制,得到一串5位的二进制
- 根据机器id,转成二进制,得到一串5位的二进制
- 根据同一存储时间、同一机房、同一机器的请求次数,转成二进制,得到一串12位的二进制。比如第一个请求就是000000000000,第二个请求就是000000000001,第三个请求就是000000000010,所以最多4096个序号,但已经完全足够了,毕竟一台机器在一毫秒内不可能存储4096次
五、MySQL主从同步
1、主从同步原理
主库在写入数据时,会往binlog中写入日志,主库和从库都有IO线程,通过IO线程,从库会读取主库的binlog,然后写入relay日志中。从库再另外通过SQL线程,将relay日志中的数据写入到从库中,这样就完成了同步
从库同步数据(读binlog日志、写relay日志、应用日志变更从库数据)是串行化的,但主库是并行化的,所以从库数据是要比主库慢一些,这即是主从同步延迟的原因。一般主库写并发达到1000,延迟几毫米,达到2000,延迟几十毫秒

2、半同步复制
如果数据刚写入主库,还没同步到从库,此时主库宕机,那会导致从库上这条数据缺失。MySQL提供半同步复制这个机制,来解决这一问题。半同步复制是指,主库写入binlog日志后,强制从库立即同步数据,从库在写入自己的relay日志后,会返回一个ack,主库接收到至少一个ack后才认为写操作完成
3、并行复制
从库开启多个线程,一个线程读取relay日志中一个数据库的日志,从而可以并行同步不同数据库的数据,但这是对于库级别的并发,表级别没法并发,所以意义不是很大
4、如何处理MySQL主从同步延迟问题
1)分库,将一个主库拆除多个分库,这样降低了单库的写并发,主从同步延迟就很小可以忽略不计
2)开启MySQL的并行复制,虽然是库级别的并发,对表不一定有效果,但该开还是得开
3)业务代码开发时要考虑到这个问题。比如本来的代码是先insert数据到主库、再select从库得到这条数据,最后update到主库,因为主从同步延迟,select就可能查不到数据,导致报错,像这种问题完全可以修改存储逻辑来解决