【Spring源码】循环依赖如何处理?
目录
1、前言
2、什么是循环依赖?
3、Spring解决循环依赖
3.1、图解循环依赖
3.2、Spring源码如何解决
4、三级缓存分别是什么?
5、为什么一定得三级缓存?
5.1、只使用一层缓存可以吗?
5.2、只使用两层缓存可以吗?
6、小结
1、前言
面试官:“看过Spring源码吧,简单说说Spring如何解决循环依赖问题?”
大神仙:“Spring利用到了三级缓存来解决循环依赖问题”。
面试官:“三级缓存是怎么处理的?为什么一定得是三级缓存?三级缓存别是对应存储的是什么?”
大神仙:“......”
2、什么是循环依赖?
循环依赖,顾名思义就是类和类之间相互引用,形成了依赖的闭环关系。比如A依赖B,B又依赖A。
示例代码:
public class A {
private B b;
public A(){
System.out.println("A加载构造器");
}
...
}
public class B {
private A a;
public B(){
System.out.println("B加载构造器");
}
...
}
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("bean.xml");
// 获取ClassA的实例(此时会发生循环依赖)
A classA = (A) context.getBean(A.class);
}以上示例代码便形成了循环依赖。
在《【Spring源码】讲讲Bean的生命周期》一文中,我们讲到了Bean的生命周期,那么我们就Bean的整个生命周期来详细说明整个循环依赖的实例流程图:
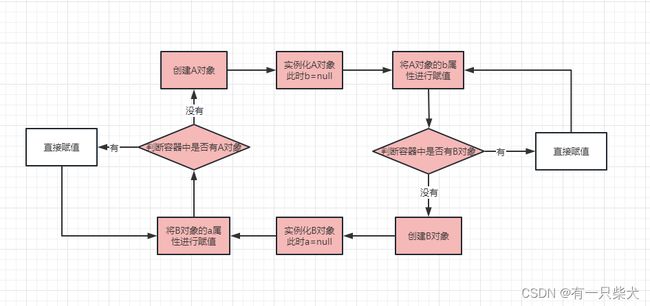
可以看出,图中红色流程形成了依赖相互引用的闭环,也就是循环依赖。
3、Spring解决循环依赖
从上述演示代码以及流程图中可以看出循环依赖,应该是会出错的。 但是实际上执行代码后发现,程序是没有报错的,也就是说Spring对此问题是进行了处理的。

3.1、图解循环依赖
我们回过头来看上面的流程图,要打破闭包最好的办法就是:在形成闭包之前打破它,使他不闭环,那么就天然解决了闭包的问题。所以我们假装不知道Spring是怎么解决的时候,我们来尝试破解他:
- 我们知道整个Bean的生命周期里,分为实例化和初始化。
- 当A创建完之后,由于需要一直等待B对象的初始化;而B又需要等待A的实例,那么在加载到B的时候又需要走一边A的生命周期,同样A在等待B,B有需要走一遍生命周期,循环不止......
- 那么有没有办法在B等待A的实例化过程中,A不需要从头走一遍生命周期呢?比如我们把A实例化的当下状态存储起来。
- 同样的,B实例化完之后的对象我们也可以存储起来。
- 这里我们姑且称实例化且未初始化的对象为“普通对象”,称实例化且初始化完的对象为“容器对象”。
此时我们可以从新规整一下上面的流程图:

这一系列的前提是:
如果缓存中持有某一个对象的引用,那么后续操作能否可以对该对象进行赋值操作?肯定是可以的。
且对象的实例化和初始化是分开的,否则的话缓存也解决不了该问题。
3.2、Spring源码如何解决
既然我们上面通过引入缓存的方式,便可打破循环依赖。那么Spring是否使用缓存的方式来解决呢? 答案确实是通过缓存的方式,只不过更复杂。Spring是通过三级缓存的方式来解决循环依赖问题的。
如果你有看过Bean生命周期的源码,就会发现在org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean有这样一段代码:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
......
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 这里是将早期的bean引用存入三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
......
return exposedObject;
}
// 三级缓存操作
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 添加进三级缓存
this.singletonFactories.put(beanName, singletonFactory);
// 删除二级缓存
this.earlySingletonObjects.remove(beanName);
......
}
}
}在Bean初始化完成后,交由IoC管理,还有这样一段代码,org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#registerSingleton
@Override
public void registerSingleton(String beanName, Object singletonObject) throws IllegalStateException {
Assert.notNull(beanName, "Bean name must not be null");
Assert.notNull(singletonObject, "Singleton object must not be null");
synchronized (this.singletonObjects) {
Object oldObject = this.singletonObjects.get(beanName);
if (oldObject != null) {
throw new IllegalStateException("Could not register object [" + singletonObject +
"] under bean name '" + beanName + "': there is already object [" + oldObject + "] bound");
}
addSingleton(beanName, singletonObject);
}
}
// 添加一级缓存
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
// 移除三级缓存
this.singletonFactories.remove(beanName);
// 移除二级缓存
this.earlySingletonObjects.remove(beanName);
// 添加到一级缓存
this.registeredSingletons.add(beanName);
}
}同样我们在获取实例的时候,也可以发现,org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String, boolean)
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 先从一级缓存中获取bean
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 如果一级缓存中没有获取到,则从二级缓存中获取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 这里做了双重检查
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存还是没有获取到,则从三级缓存中获取
if (singletonObject == null) {
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 获取到对象后,放进二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 同时将三级缓存删除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}由此可见,Spring确实是采用了类似的方式来解决问题。那么为什么需要使用这么复杂的缓存机制呢?普通一级缓存或者二级缓存不行吗?
4、三级缓存分别是什么?
要解答上面的问题,得先了解Spring中的三级缓存分别对应是存储的什么数据,以及作用。

一级缓存(singletonObjects):存储的是初始化完成的实例对象,该缓存需要暴露bean对象,供给Spring框架应用程序使用,因此这里需要保证线程安全,以及较大的初始容量(256)
二级缓存(earlySingletonObjects):存储的是实例化完但还未初始化的bean对象,该bean需要提前暴露引用给框架内部使用。不会暴露给外部程序使用。
三级缓存(singletonFactories):存储的是通过ObjectFactory对象来存储提前暴露的bean实例的引用。该bean需要提前暴露引用给框架内部使用。不会暴露给外部程序使用。
这里重点介绍一下ObjectFactory,因为这个是解决缓存依赖的大功臣。ObjectFactory是一个函数式接口,他的参数可以接收一个lambda表达式,由于lambad表达式的惰性机制,导致该方法并不会在一开始便被执行,而是在调用getObject方法,才会调用该lambda处理的逻辑。如
singletonObject = singletonFactory.getObject();我们再来用上面的流程图,按照Spring的三级缓存来进行改造:
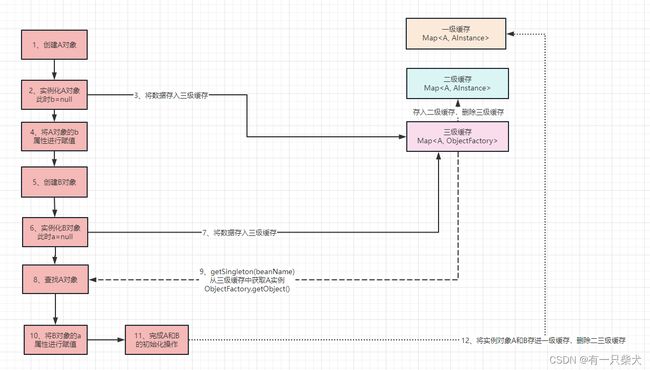
其实整个都是围绕着对象A的实例化,B的实例化,A的初始化,B的初始化生命周期展开,当A实例化后,将其放进三级缓存,随后实例化B,当B要初始化的时候,先从一级缓存->二级缓存依次获取A实例对象,如果没有获取到,再获取三级缓存中的A实例,此时三级缓存中获取到的是A的ObjectFactory传进来的Lambda,接着调用singletonObject.getObject()执行lambda,便得到了A的早期对象, 这时候B就可以进行初始化操作了,当B完成初始化后,也就可以给A赋值了,接着A也完成了初始化操作。当都完成初始化操作后,将实例对象依次存进一级缓存,随后清空二三级缓存。这便是大致的三级缓存解决循环依赖的流程。
5、为什么一定得三级缓存?
从上述的流程中得知,三级缓存解决了循环依赖的问题。二级和三级缓存功能类似,存储的都是创建中的bean。只是一个存储的是实例,一个存储的是工厂类方法。那么这里二三级同时存在的意义是什么呢?如果移除三级缓存,只使用一级和二级缓存,是否也可以解决循环依赖问题。或者说只使用一级缓存,是否也可以解决?
5.1、只使用一层缓存可以吗?
不可以。如果只有一个缓存,那么实例对象和普通对象都将在同一个缓存中,对于普通对象是不能提前暴露给应用程序使用的。Spring为了做区分,所以引进去了2个缓存。当然有人说,我一个缓存,key或value做标识,也不是不行。但是稍微略显麻烦。
5.2、只使用两层缓存可以吗?
可以的。但是有一些特殊场景就会出问题,典型的场景便是:AOP。只要循环依赖中包含了AOP处理逻辑,就会有问题。
那么三级缓存是如何解决代理对象问题?解决前先需要明确以下几个前提:
- 在创建代理对象时,是需要创建出原始对象。
- 同一个容器中能否出现同名的不同对象?答案肯定是不能。
- 如果一个对象被代理,那么代理对象创建完之后应该要覆盖原始对象。
- 代理对象的创建是在BeanPostProcessor后置处理方法中,那么在对象对外暴露的时候,如何给出是原始对象还是代理对象?此时就需要lambda表达式,类似一种回调机制,在确定对外暴露的时候,就唯一性的确定是代理对象还是原始对象,这就是为什么要以lambda表达式的方式放入三级缓存,来给后续执行的原因。
所以我们从bean创建中可以看到这样一段代码:
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));它定义了一个lambda表达式,通过getEarlyBeanReference方法获取代理对象,其实底层是通过AbstractAutoProxyCreator类的getEarlyBeanReference生成代理对象。如果此时不使用三级缓存,那么二级缓存中保存的对象既有原始对象,也会有代理对象(创建后会把原始对象覆盖),那么就不是作者最初设计的流程。因此引入三级缓存来进行扩展,通过惰性机制,只有在确定需要对外暴露的时候才执行对象的确定,也就是确定到底是原始对象还是代理对象。
6、小结
所以总结下来,三级缓存可以简单理解为:
一级缓存:存放初始化后的Bean
二级缓存:存放创建中为初始化的Bean
三级缓存:保证在代理对象间没有循环引用时,代理对象在执行初始化方法后创建代理对象。如果出现了循环引用不可避免的还是需要提前创建出代理对象。