数据结构(Linux环境C语言版)
数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素集合。这种特定关系包括一对一的线性关系,一对多的树形关系,以及多对多的图形关系。数据结构是介于数学算法、计算机软硬件之间桥梁,我们需要学会分析研究计算机加工的数据结构特性,以便为应用选择适当的数据存储结构,支撑从时间和空间分析最优的逻辑与算法。
文章详述了数组、线性表、栈和队列,以及树在Linux环境(数据结构本身实现与环境无关)下用C语言实现的示例。介绍了可以将数据结构实现的接口编译成链接库使用的方法。
文章目录
写在前面的基础
链接库
算法分析
结构体数组
双向链表
队列与栈
队列
栈
哈希表
树
补充说明:内核链表
写在前面的基础
因为大部分的数据结构要服务于上层的算法与逻辑,那么要想理解好数据结构,首先就要对"什么算是好的算法"这一标准有所理解,这样才能更好地对症下药。数据结构的代码实现可以跟业务逻辑很好的剥离开来,我们可以把这些数据结构的实现编译成库,方便在各个项目之间混用,这也是为什么大家都好称C语言是经常用来实现"轮子"的语言原因。
链接库
链接库分为动态链接库和静态链接库,动态库和静态库重名时优先链接动态库。:
- 编译时载入,不占用运行时间。名称为libxx.a。使用命令ar -cr libxx.a yyy.o,头文件放置到/usr/local/include,库文件放到/usr/local/lib。最后使用gcc -L /usr/local/lib -o main mian.o -lxx与静态链接库共同编译。
- 执行时去动态库调用。名称为libxx.so。使用命令gcc -shared -fpic -o libxx.so yyy.c生成动态链接库,头文件发布到/usr/local/include,库文件发布到/usr/local/lib。用户链接库文件的位置放在/etc/ld.so.conf,使用命令gcc -I/usr/local/inclde -L/usr/local/lib -o ... -lxx编译调用动态链接库程序,如果是标准位置-I 和 -L都可以省略。ldd+程序名可以查看程序关联到的动态链接库。
算法分析
算法(algorithm)是对特定问题求解步骤的一种描述。通常一个“好”的算法应考虑一下目标:
- 正确性(correctness)
- 可读性(readability)
- 健壮性(robustness)
- 效率与低存储量需求
最后的效率与低存储量需求就是我们数据结构需要与算法共同达成的目标。
- 时间复杂度(asymptotic time complexity),用
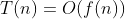 来表示。其中n是问题规模,假设一个计算由0到n累加的算法,那么它的时间复杂度为O(n)线性阶。我们往往需要提供一些不同的数据结构降低对数据排序或搜索等操作的时间消耗。
来表示。其中n是问题规模,假设一个计算由0到n累加的算法,那么它的时间复杂度为O(n)线性阶。我们往往需要提供一些不同的数据结构降低对数据排序或搜索等操作的时间消耗。 - 空间复杂度(space complexity),记作
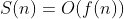 。其中n是为问题规模(或大小)。还是一个计算由0到n累加的算法,它的空间复杂度为O(2),sum和n。
。其中n是为问题规模(或大小)。还是一个计算由0到n累加的算法,它的空间复杂度为O(2),sum和n。
结构体数组
数组是一对一线性关系数据存储,数据大小一致。C语言提供了基于它所定义的数据类型(char,int,long)的数组结构,然而我们常常需要存储一组自定义的数据结构数组,下面这个示例为存储一组(6个)表示学生英语成绩的结构体。示例源文件包含:darr.c、darr.h以及main.c。文中的示例以及增加了中文注释帮助理解,下面是Makefile文件:
.PHONY:install
all:
gcc -shared -fPIC -o libdarr.so darr.c -I. #数据结构实现编译为动态链接库
mv libdarr.so /lib64 #移动库文件至环境变量动态链接库位置
gcc -o softarr main.c -ldarr -I. #编译程序
clean:
rm -f softarr下面是它的main.c文件,提供了学生英语成绩数据结构比较函数并初始化了一个数组,将准备好的6个学生数据插入这个数组(有序),遍历这个数组并打印,然后找到一个特定ID的学生英语成绩数据结构并打印出来,最后销毁这个数组:
#include
#include
#define NAMESIZE 32
struct stu_st {
int id;
char name[NAMESIZE];
int ch;
int english;
};//学生英语成绩数据结构
static void print_arr(const void *data)
{
const struct stu_st *d = data;
printf("%-3d%-10s%-3d%d\n", d->id, d->name, d->ch, d->english);
}//打印传入的学生英语成绩数据结构
int id_cmp(const void *key, const void *data)
{
const int *k = key;
const struct stu_st *d = data;
return *k - d->id;
}//比较传入的学生英语成绩数据结构与结构体ID成员
int data_cmp(const void *data1, const void *data2)
{
const struct stu_st *d1 = data1;
const struct stu_st *d2 = data2;
return d1->id - d2->id;
}//比较两个学生英语成绩数据结构的ID,用于排序
int main(void)
{
srand(time(NULL));
DARR *myarr;
int id[] = {3, 5, 2, 1, 8, 9};
struct stu_st tmp;
int i;
int del_id;
//初始化一个有序结构体数组
myarr = init_sort_darr(sizeof(struct stu_st), data_cmp);
for (i = 0; i < sizeof(id)/sizeof(*id); i++) {
tmp.id = id[i];
snprintf(tmp.name, NAMESIZE, "stu%d", id[i]);
tmp.ch = rand()%100;
tmp.english = rand()%50 + 50;
//有序插入学生英语成绩结构体
insert_sort_darr(myarr, &tmp);
}
//按序打印学生英语成绩结构体
traval_darr(myarr, print_arr);
printf("\n");
del_id = 2;
//搜索ID为2的学生英语成绩并打印
if (search_darr_bin(myarr, &del_id, id_cmp, &tmp) < 0) {
printf("not found\n");
} else {
printf("find it: %s %d\n", tmp.name, tmp.id);
}
//销毁数组
destroy_darr(myarr);
return 0;
}
下图是数组结构体库对外接口,初始化完成了对数组管理结构体的赋值工作,因为此线程存储的元素大小一致,所以数据结构相关的所有值都在此结构体中。

下面是darr.c代码,使用了二分法查找到要插入元素的位置,然后完成了插入实现了有序的数组。文件中的中文注释可以帮助您了解结构体数组实现。
#include
#include
#include
struct darr_st {
char *arr;
int size;
int num;
key_cmp_t diff;
};//结构体数组管理头
DARR *init_sort_darr(int size, key_cmp_t diff)
{
struct darr_st *p = NULL;
p = malloc(sizeof(*p));
//if error
p->arr = NULL;
p->size = size;
p->num = 0;
p->key = key;
p->diff = diff;
return p;
}//初始化一个排序数组
static int bsearch_near(struct darr_st *ptr, const void *data)
{
int ret;
int low, high, mid = 0;
low = 0;
high = ptr->num - 1;
while (low <= high) {
mid = (low + high) / 2;//二分法
ret = ptr->diff(ptr->arr+mid*ptr->size, data);//根据用户提供比较函数,比较元素大小
if (ret == 0) {
break;
}
if (ret < 0) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return mid;
}//根据比较函数,找到元素应该插入的位置
int insert_sort_darr(DARR *p, const void *data)
{
struct darr_st *ptr = p;
int ind;
ptr->arr = realloc(ptr->arr, (ptr->num+1)*ptr->size);//重新申请数据区大小
//if error
if (ptr->num == 0 || ptr->diff == NULL) {
ind = 0;
} else {
ind = bsearch_near(ptr, data);
if (ptr->diff(ptr->arr+ind*ptr->size, data) < 0) {
ind ++;//找到需要插入的位置
}
}
memmove(ptr->arr+(ind+1)*ptr->size, ptr->arr+ind*ptr->size,\
ptr->size*(ptr->num - ind));//只能用memmove,涉及重叠内存拷贝
memcpy(ptr->arr+ind*ptr->size, data, ptr->size);
ptr->num++;
return 0;
}
int delete_darr(DARR *p, const void *key, key_cmp_t cmp)
{
struct darr_st *ptr = p;
int i;
char *tmp = NULL;
for (i = 0; i < ptr->num; i++) {
if (cmp(key, ptr->arr+i*ptr->size) == 0) {
break;
}
}//找到元素位置
if (i == ptr->num) {
return -1;
}
memmove(ptr->arr+i*ptr->size, ptr->arr+(i+1)*ptr->size,\
(ptr->num-i-1)*ptr->size);
ptr->num--;
tmp = malloc(ptr->num * ptr->size);
if (NULL == tmp) {
return -1;
}
memcpy(tmp, ptr->arr, ptr->num * ptr->size);
free(ptr->arr);
ptr->arr = tmp;
return 0;
}//删除某个元素
int search_darr_bin(DARR *p, const void *key, key_cmp_t cmp, void *data)
{
struct darr_st *ptr = p;
char *tmp;
tmp = bsearch(key, ptr->arr, ptr->num, ptr->size, cmp);
if (tmp == NULL) {
return -1;
}
memcpy(data, tmp, ptr->size);
return 0;
}//找到某个元素根据用户输入属性
void traval_darr(DARR *p, print_t op)
{
struct darr_st *ptr = p;
int i;
for (i = 0; i < ptr->num; i++) {
op(ptr->arr + i * ptr->size);
}
}//遍历数组
void destroy_darr(DARR *p)
{
struct darr_st *ptr = p;
free(ptr->arr);
free(ptr);
}//释放申请初始化申请资源。
下面是darr.h代码:
#ifndef MY_DARR_H
#define MY_DARR_H
typedef int (*key_cmp_t)(const void *, const void *);
typedef void (*print_t)(const void *);
typedef void DARR;
DARR *init_sort_darr(int size, key_cmp_t diff);
int insert_sort_darr(DARR *ptr, const void *data);
int delete_darr(DARR *ptr, const void *key, key_cmp_t cmp);
void traval_darr(DARR *ptr, print_t op);
int search_darr_bin(DARR *ptr, const void *key, key_cmp_t cmp, void *data);
void destroy_darr(DARR *);
#endif
双向链表
链表是典型的线性存储结构,它对存储的数据结构大小并没有必须一致的限制,所以所有不同大小的数据都需要有两个指针组成的链表头,一个是前序指针,指向前一个数据的链表头,一个是后序指针,指向后一个数据的链表头,下面是一个链表构成的示意图:

这里要讲的一个示例由main.c、llist.h以及llist.c构成,存储的数据元素是由姓名、性别以及qq号组成的个人信息。main.c创建链表之后将10个随机胜场的数据头插入链表(在链表头后插入元素为头插,链表头前插入元素为尾插),打印链表之后,删除一个女性数据然后再打印链表,然后再按照一个学生的姓名查找链表并打印该学生信息,最后取出(搜索并删除)一个男性数据,打印该男性数据然后再次遍历打印链表,最后销毁链表。下面是main.c的实现:
#include
#include "llist.h"
#define NAMESIZE 32
struct info_t {
char name[NAMESIZE];
char sex;
int qq;
};//数据元素结构定义
void print_info (const void *data)
{
const struct info_t *d = data;
printf("%-10s%-5c%d\n", d->name, d->sex, d->qq);
}//打印元素接口
int chr_cmp(const void *key, const void *data)
{
const char *k = key;
const struct info_t *d = data;
return *k-d->sex;
}//性别字符比较
int str_cmp(const void *key, const void *data)
{
const char *k = key;
const struct info_t *d = data;
return strcmp(k, d->name);
}//姓名字符串比较
int main(void)
{
srand(time(NULL));
LLIST *mylist;
int i;
struct info_t tmp, *search;
int num;
char sexvar;
mylist = init_llist(sizeof(struct info_t));//建立一个链表
//if error
for (i = 0; i < 10; i++) {
snprintf(tmp.name , NAMESIZE, "stu%c", rand()%26+'a');
tmp.sex = (rand() % 2) == 0 ? 'f' : 'm';
tmp.qq = rand()%10000 + 100000;
insert_llist(mylist, &tmp, FORWARD);//头插一个元素
}
traval_llist(mylist, print_info);
printf("\n");
sexvar = 'm';
delete_llist(mylist, &sexvar, chr_cmp);//删除一个sexvar = 'm'的元素
traval_llist(mylist, print_info);//打印链表
search = search_llist(mylist, "stus", str_cmp);//寻找一个名为stus的元素
if (search == NULL) {
printf("not find\n");
} else {
printf("find it: %s %c %d\n", search->name, search->sex, search->qq);
}
printf("\n");
sexvar = 'f';
if (fetch_llist(mylist, &sexvar, chr_cmp, &tmp) != 0) {//取得一个男性元素
printf("invalued...\n");
} else {
printf("fetch it: %s %c %d\n", tmp.name, tmp.sex, tmp.qq);
}
traval_llist(mylist, print_info);//打印链表
destroy_llist(mylist); //销毁链表
return 0;
}
你需要把llist.c与llist.h理解透彻,因为后边很多的数据结构都是基于这个环状线性结构实现的。
下面讲llist.c的实现,在看代码之前主要讲一个对外接口的实现:
-
insert_llist:向列表插入一个元素,头插将当前链表头指针赋值给插入元素的前序指针,然后将链表头的后序指针赋值给插入元素的后序指针,尾插则将当前链表头指针的前序指针赋值给插入元素的前序指针,然后将链表头指针赋值插入元素的后续指针,至此插入元素外指的指针赋值完毕。最后将插入元素的前序指针指向的元素的后序指针赋值为插入元素,将插入元素的后序指针指向的元素的前序指针赋值为插入元素,完成插入操作。
下面是llist.c的实现代码,文中增加了必要的中文注释帮助理解:
#include
#include
#include "llist.h"
LLIST *init_llist(int size)
{
LLIST *list = NULL;
list = malloc(sizeof(*list));
if (NULL == list) {
return NULL;
}
list->head.prev = list->head.next = &list->head;
list->size = size;
return list;
}//初始化一个链表头,前序后序指针都指向自己
status insert_llist(LLIST *list, const void *data, enum insert_em way)
{
struct node_st *node;
node = malloc(sizeof(struct node_st) + list->size);
if (NULL == node) {
return FAIL;
}
memcpy(node->data, data, list->size);
if (way == FORWARD) {
node->prev = &list->head;
node->next = list->head.next;
} else {
node->prev = list->head.prev;
node->next = &list->head;
}
node->prev->next = node;
node->next->prev = node;
return OK;
}//插入一个元素
void *search_llist(LLIST *list,const void *key, cmp_t op)
{
struct node_st *cur;
#if 0
for(cur=list->head.next;cur!=&list->head;cur=cur->next)
{
if(!op(key,cur->data))
break;
}
if (cur == &list->head) {
return NULL;
}
return cur->data;
#endif
cur = list->head.next;
while (op(key, cur->data)) {
cur = cur->next;
if (cur == &list->head) {
return NULL;
}
}
return cur->data;
}//寻找一个元素
int delete_llist(LLIST *list, const void *key, cmp_t op)
{
struct node_st *cur;
for (cur = list->head.next; cur != &list->head; cur= cur->next){
if (!op(key, cur->data)) {
cur->prev->next = cur->next;
cur->next->prev = cur->prev;
cur->prev = cur->next = NULL;
free(cur);
return OK;
}
}
return FAIL;
}//删除一个元素
void traval_llist(LLIST *list, traval_t op)
{
struct node_st *cur;
for (cur = list->head.next; cur != &list->head; cur = cur->next) {
op(cur->data);
}
}//遍历链表
status fetch_llist(LLIST *list, const void *key, cmp_t op, void *node)
{
struct node_st *cur;
for (cur = list->head.next; cur != &list->head; cur = cur->next) {
if (!op(key, cur->data)) {
memcpy(node, cur->data, list->size);
cur->prev->next = cur->next;
cur->next->prev = cur->prev;
free(cur);
return OK;
}
}
return FAIL;
}//取得一个元素
void destroy_llist(LLIST *list)
{
struct node_st *tmp, *cur;
for (tmp = list->head.next; tmp != &list->head; tmp = cur) {
cur = tmp->next;
free(tmp);
}
free(list);
}//销毁创建的链表
下面是对应的llist.h文件:
#ifndef LLIST_H
#define LLIST_H
typedef void (*traval_t)(const void *);
typedef int (*cmp_t) (const void *, const void *);
typedef int status;
#define OK 0
#define FAIL 1
enum insert_em{FORWARD = 1, BEHIND};
struct node_st {
struct node_st *prev;
struct node_st *next;
char data[0];
};
typedef struct {
struct node_st head;
int size;
}LLIST;
LLIST *init_llist(int size);
status insert_llist(LLIST *, const void *data, enum insert_em way);
status delete_llist(LLIST *, const void *key, cmp_t op);
void * search_llist(LLIST *, const void *key, cmp_t op);
status fetch_llist(LLIST *, const void *key, cmp_t op, void *node);
void traval_llist(LLIST *, traval_t op);
void destroy_llist(LLIST *list);
#endif
队列与栈
队列与栈是特殊的线性表,他们允许在表的同一端进行插入和删除。队列采用先进先出原则,栈实现的是后进先出原则。它们都基于llist.c实现,在llist.c的基础上包装一层。

队列
队列的插入操作是尾插,这样就能保证先进先出原则,下面是queue.c的实现:
#include
#include "queue.h"
QUEUE *init_queue(int size)
{
return init_llist(size);
}
int in_queue(QUEUE *ptr, const void *data)
{
return insert_llist(ptr, data, BEHIND);//尾插
}
static int always_ok(const void *k, const void *d)
{
return 0;
}
int out_queue(QUEUE *ptr, void *data)
{
return fetch_llist(ptr, NULL, always_ok, data);
}
int empty_queue(QUEUE *ptr)
{
return !get_nodes(ptr);
}
void destroy_queue(QUEUE *ptr)
{
destroy_llist(ptr);
}
下面是queue.h:
#ifndef LINK_QUEUE_H
#define LINK_QUEUE_H
#include "llist.h"
typedef LLIST QUEUE;
QUEUE *init_queue(int size);
int in_queue(QUEUE *, const void *data);
int out_queue(QUEUE *, void *data);
int empty_queue(QUEUE *);
void destroy_queue(QUEUE *);
#endif
栈
队列的插入操作是头插,这样就能保证后进先出原则,下面是stack.c的实现:
#include
#include "stack.h"
STACK *init_stack(int size)
{
return init_llist(size);
}
int push_stack(STACK *ptr, const void *data)
{
return insert_llist(ptr, data, FORWARD);
}
static int always(const void *d1, const void *d2)
{
return 0;
}
int pop_stack(STACK *ptr, void *data)
{
return fetch_llist(ptr, NULL, always, data);
}
int is_empty(STACK *ptr)
{
return ptr->head.next == &ptr->head;
}
void destroy_stack(STACK *ptr)
{
destroy_llist(ptr);
}
下面是stack.h:
#ifndef _STACK_H
#define _STACK_H
#include "llist.h"
typedef LLIST STACK;
STACK *init_stack(int size);
int push_stack(STACK *, const void *data);
int pop_stack(STACK *, void *data);
void destroy_stack(STACK *);
int is_empty(STACK *);
#endif
逆波兰表达式又叫做后缀表达式,是一种没有括号,并严格遵循“从左到右”运算的后缀式表达方法,其把运算量写在前边,把算符写在后边。比如9 + (2 * 3) - 8 / 2用后缀表达式表示为923*+82/-。栈这种数据结构体特别逆波兰表达式的计算,下面的例子就完成了计算923*+82/-的值:
#include
#include "stack.h"
#define ERROR -100
static STACK *mys;
static int is_number (char tmp)
{
return (tmp >= '0' && tmp <= '9');
}//判断是否为数值
static int is_operator (char tmp)
{
return (tmp == '+' || tmp == '-' || tmp == '*' || tmp == '/');
}//判断是否为运算符
static int real_cacu(int a, char op, int b)
{
int ret;
switch (op) {
case '+':
ret = a + b;
break;
case '-':
ret = a - b;
break;
case '*':
ret = a * b;
break;
case '/':
ret = a / b;
break;
default:
return ERROR;
}
return ret;
}//单目计算
static int caculate(const char *ptr)
{
int left, right;
int result;
int tmp;
mys = init_stack(sizeof(int));
while (*ptr) {
if (is_number(*ptr)) {
tmp = *ptr-'0';
push_stack(mys, &tmp);//如果是数值 入栈
}else if (is_operator(*ptr)) {
if (!is_empty(mys)) {
pop_stack(mys, &right); //如果是运算符,则栈
} else {
break;
}
if (!is_empty(mys)) {
pop_stack(mys, &left);
} else {
break;
}
result = real_cacu(left, *ptr, right);//利用栈数值,计算结果
push_stack(mys, &result);//将结果入栈
} else {
printf("invalued express\n");
return ERROR;
}
ptr++;
}
if (!is_empty(mys)) {
pop_stack(mys, &result);//栈不为空,则将结果输出
if (*ptr=='\0' && is_empty(mys)) {
return result;
}
}
return ERROR;
}
int main(void)
{
printf("result is %d\n", caculate("923*+82/-"));
destroy_stack(mys);
return 0;
}
哈希表
根据设定的哈希函数![]() 将一组关键字映射到一个有限的连续地址集(区间)上,并将元素挂接到映射的地址对应的链表。连续的地址集为链表头数组,最终存储数据的这个表称为哈希表,这一映像的过程称为哈希造表或者散列。所得的存储位置称为哈希地址或者散列地址。
将一组关键字映射到一个有限的连续地址集(区间)上,并将元素挂接到映射的地址对应的链表。连续的地址集为链表头数组,最终存储数据的这个表称为哈希表,这一映像的过程称为哈希造表或者散列。所得的存储位置称为哈希地址或者散列地址。

下面是C语言利用哈希表存储学生信息的例子,同样基于llist.c:
#include
#include "llist.h"
#define HASH_NR 10
#define NAMESIZE 32
struct stu_st {
int id;
char name[NAMESIZE];
};//学生信息
LLIST *hash_arr[HASH_NR];//链表数组
int hash_fun(int key)
{
return key % HASH_NR;
}//计算哈希值
void hash_insert(struct stu_st data)
{
int ind;
ind = hash_fun(data.id);//得到哈希值
insert_llist(hash_arr[ind], &data, FORWARD);//根据哈希值插入相应的链表
}
void print_hash(const void *data)
{
const struct stu_st *d = data;
printf("%d %s\n", d->id,d->name);
}//打印哈希表
int main(void)
{
srand(getpid());
int i;
struct stu_st tmp;
for (i = 0; i < HASH_NR; i++) {
hash_arr[i] = init_llist(sizeof(struct stu_st));//初始化链表
}
for (i = 0; i < 100; i++) {
tmp.id = rand() % 100;
snprintf(tmp.name, NAMESIZE, "stu%d", i);
hash_insert(tmp);//将学生信息插入hash表
}
for (i = 0; i < HASH_NR; i++) {
printf("the %d list:\n", i+1);
traval_llist(hash_arr[i], print_hash);//打印链表
printf("**********************\n");
}
return 0;
}
树
树是一种典型一对多的数据结构,树的实现往往伴随着大量的递归,嵌入式软件用到树这种数据结构的机会很少。下面的图形是它的一个结构:

字典树又称为单词查找树,Trie树,是一种树形结构,可以以极低的存储成本保存大量字符串,且利用了公共的前缀减少了查询的时间。下面的例子将多例从文件读出的key:description按照key存储在字典树数据结构(字典表)中。然后查询'ant'对应的描述,代码中有中文注释帮助读者理解。
#include
#include
#include
#define NR_ARR 26
#define DESC_SIZE 128
#define KEY_SIZE 128
#define BUFSIZE 256
struct node_st
{
struct node_st *ch[NR_ARR];
char desc[DESC_SIZE];
};//树节点
int get_word(FILE *fp,char *key,char *desc)
{
int i;
char buf[BUFSIZE];
char *cur;
char *retp;
retp = fgets(buf,BUFSIZE,fp);
if(retp == NULL)
return -1;
for(cur = buf,i = 0 ; i < KEY_SIZE && *cur != ':'; i++,cur++)
key[i] = *cur;
key[i] = '\0';
for(cur++,i = 0 ; i < DESC_SIZE && *cur != '\n'; i++,cur++)
desc[i] = *cur;
desc[i] = '\0';
return 0;
}//从文章中获取key和对应的description
struct node_st *newnode()
{
int i;
struct node_st *node;
node = malloc(sizeof(*node));
if(node == NULL)
return NULL;
node->desc[0] = '\0';
for(i = 0 ; i < NR_ARR; i++)
node->ch[i] = NULL;
return node;
}//新建一个树节点
int insert(struct node_st **root,char *key,char *desc)
{
if(*root == NULL)
{
*root = newnode();
if(*root == NULL)
return -1;
}
if(*key == '\0')
{
strncpy((*root)->desc,desc,DESC_SIZE);
return 0;
}
return insert((*root)->ch + *key-'a',key+1,desc);
}//递归将desc插入到由key逐个字符决定深度路径的树节点中
char *find(struct node_st *root,char *key)
{
if(root == NULL)
return NULL;
if(*key == '\0')
{
if(root->desc[0] == '\0')
return NULL;
return root->desc;
}
return find(root->ch[*key-'a'],key+1);
}//根据key找到对应的树节点
int main(int argc,char **argv)
{
char key[KEY_SIZE];
char desc[DESC_SIZE];
FILE *fp;
struct node_st *tree = NULL;//将树根节点置为空
if(argc < 2)
{
fprintf(stderr,"Usage....\n");
exit(1);
}
fp = fopen(argv[1],"r");//打开文件
if(fp == NULL)
{
perror("fopen()");
exit(1);
}
while(1)
{
if(get_word(fp,key,desc) != 0)//获取key+description
break;
insert(&tree,key,desc);//将key+description插入树数据结构
}
char *data = "ant";
char *retp;
retp = find(tree,data); //根据key从树数据结构中寻找description
if(retp == NULL)
printf("Can not find!\n");
else
puts(retp);
close(fp);
exit(0);
} 下面这个例子我们常用的平衡二叉树,它具有如下的性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这种数据结构能够有效的提高查找效率,结构如下图:

下面这个示例实现了一个将当前树强制(不考虑父节点与子节点的大小关系)调整成平衡树的过程,只为给读者提供一个平衡树的概念理解,并不能像真正的平衡二叉树提高搜索效率。
示例初始化一个由数值构成的树结构,将他调整成平衡二叉树之后将树结构打印出来,最后通过travel()接口将数据由小到大打印出来(该接口基于之前实现的队列数据结构)。下面我主要将两个函数的实现:
-
insert()函数:树节点包含了其左右子节点的指针,树的实现不需要初始化函数,每一个节点的数据结构开销仅包含两个指针,因为要改变节点指针的值,所以接口传入的是节点指针的地址。插入函数是典型的递归函数实现,递归出口判断传入的节点指针为空时,则申请一个树节点结构体,将结构体地址赋值给该传入结点指针。入口则判断当前数据的节点小于当前树节点所包含数据,则递归调用insert()函数,传入当前树节点左子节点指针地址,大于则传入右子节点指针地址。
-
balance()函数:该函数将传入的树结构调整成平衡二叉树结构。首先针对当前传入树节点,判断当前节点左子节点数与右子节点数的差值,如果差值的绝对值小于1则表示当前节点是平衡的,然后递归调用balance()函数将当前节点的左子节点和右子节点指针地址传入,保证所有的节点都是平衡的。在当前节点左子节点数与右子节点数的差值绝对值大于1的时候,点左子节点数小于右子节点数时,则调用turn_left()函数,反之则调用turn_right()函数,直至当前节点平衡。此例子中的turn_left()函数与turn_right()函数与我们真正实现平衡树插入函数时的左右旋函数并不是一回事,这俩函数时强制的构造一个平衡树结构,会破坏父节点与左右子节点的大小关系。
#include
#include
#include "queue.h"
#define NAMESIZE 32
static struct node_st *tree = NULL;
struct score_st
{
int id;
char name[NAMESIZE];
int math;
};//树节点保存数据
struct node_st
{
struct score_st data;
struct node_st *l,*r;
};
void print_s(struct score_st *s)
{
// printf("%d %s %d\n",s->id,s->name,s->math);
printf("%d \n",s->id);
}
int insert(struct node_st **root,struct score_st *data)
{
struct node_st *node;
if(*root == NULL)
{
node = malloc(sizeof(*node));
if(node == NULL)
return -1;
node->data = *data;
node->l = NULL;
node->r = NULL;
*root = node;
return 0;
}
if(data->id < (*root)->data.id)
return insert(&(*root)->l,data);
return insert(&(*root)->r,data);
}//插入树节点
struct score_st *find(struct node_st *root,int myid)
{
if(root == NULL)
return NULL;
if(myid == root->data.id)
return &root->data;
if(myid < root->data.id)
return find(root->l,myid);
return find(root->r,myid);
}//查找树节点
void draw_(struct node_st *root,int level)
{
int i;
if(root == NULL)
return ;
draw_(root->r,level+1);
for(i = 0 ; i < level; i++)
printf(" ");
print_s(&root->data);
draw_(root->l,level+1);
}
void draw(struct node_st *root)
{
draw_(root,0);
// getchar();
}//画出这个树
int get_num(struct node_st *root)
{
if(root == NULL)
return 0;
return get_num(root->l) + 1 + get_num(root->r);
}
struct node_st *find_min(struct node_st *root)
{
if(root->l == NULL)
return root;
return find_min(root->l);
}//找出ID最小节点
struct node_st *find_max(struct node_st *root)
{
if(root->r == NULL)
return root;
return find_max(root->r);
}//找出ID最大节点
void turn_left(struct node_st **root)
{
struct node_st *cur = *root;
*root = cur->r;
cur->r = NULL;
find_min(*root)->l = cur;
// draw(tree);
}
void turn_right(struct node_st **root)
{
struct node_st *cur = *root;
*root = cur->l;
cur->l = NULL;
find_max(*root)->r = cur;
// draw(tree);
}
void balance(struct node_st **root)
{
int sub;
if(*root == NULL)
return ;
while(1)
{
sub = get_num((*root)->l) - get_num((*root)->r);
if(sub >= -1 && sub <= 1)
break;
if(sub < -1)
turn_left(root);
else
turn_right(root);
}
balance(&(*root)->l);
balance(&(*root)->r);
}//强制调整成平衡二叉树
#if 0
void travel(struct node_st *root)
{
if(root == NULL)
return ;
travel(root->l);
travel(root->r);
print_s(&root->data);
}
#else
void travel(struct node_st *root)
{
QUEUE *qu;
struct node_st *cur;
int ret;
qu = init_queue(sizeof(struct node_st *));
if(qu == NULL)
return ;
in_queue(qu,&root);
while(1)
{
ret = out_queue(qu,&cur);
if(ret == 1)
break;
print_s(&cur->data);
if(cur->l != NULL)
in_queue(qu,&cur->l);
if(cur->r != NULL)
in_queue(qu,&cur->r);
}
destroy_queue(qu);
return ;
}
#endif
int main(void)
{
struct score_st tmp,*datap;
int arr[] = {1,2,3,7,6,5,9,8,4};
int i;
for(i = 0 ; i < sizeof(arr)/sizeof(*arr); i++)
{
tmp.id = arr[i];
snprintf(tmp.name,NAMESIZE,"stu%d",tmp.id);
tmp.math = 100 - arr[i];
insert(&tree,&tmp); //将数据插入到树中
// free(node);
}
draw(tree); printf("\n"); printf("\n");
balance(&tree);//强制调整数结构为平衡
draw(tree);
travel(tree);
#if 0
int myid = 19;
datap = find(tree,myid);
if(datap == NULL)
fprintf(stderr,"find() failed.\n");
else
print_s(datap);
#endif
exit(0);
} 补充说明:内核链表
Linux内核通过宏定义与内联函数实现了双向链表数据结构,部分内核源码如下:
#ifndef _MYTEST_LIST_H
#define _MYTEST_LIST_H
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
struct list_head {
struct list_head *prev;
struct list_head *next;
};
//头结点指针域的初始化
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
#if 0
struct list_head name = { &(name), &(name)
struct list_head *prev;
struct list_head *next;
}
#endif
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new; //head->next->prev = new;
new->next = next; //new->next = head->next;
new->prev = prev; //new->prev = head;
prev->next = new; //head->next = new;
}
//双向循环链表的头插法
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
//双向循环链表的尾插法
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev; //entry->next->prev = entry->prev;
prev->next = next; //entry->prev->next = entry->next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = NULL;
entry->prev = NULL;
}
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#endif
下面的例子往链表插入了6个学生信息,然后遍历链表内容并打印,代码如下:
#include
#include
#include "list.h"
struct data_st {
int id;
char name[32];
struct list_head node;
};
int main(void)
{
LIST_HEAD(list);
struct data_st *tmp;
struct data_st *data;
struct list_head *pos;
printf("struct data..%d\n",sizeof(struct data_st));
printf("tmp..........%d\n",sizeof(tmp));
printf("tmp->id......%d\n",sizeof(tmp->id));
printf("tmp->name....%d\n",sizeof(tmp->name));
printf("&tmp.........%d\n",sizeof(&tmp));
printf("tmp->node....%d\n",sizeof(tmp->node));
printf("&tmp->node...%p\n",tmp->node);
// struct list_head *ttt = { NULL, NULL, NULL};
int id[] = {3,2,6,8,9,1};
int i;
for (i = 0; i < sizeof(id) / sizeof(*id); i++) {
tmp = malloc(sizeof(struct data_st));
if (NULL == tmp) {
return -1;
}
tmp->id = id[i];
snprintf(tmp->name, 32, "stu%d", id[i]);
list_add(&tmp->node, &list);
}
list_for_each(pos, &list) {
data = list_entry(pos, struct data_st, node);
printf("%d %s\n", data->id, data->name);//打印插入信息
}
return 0;
} 十六宿舍 原创作品,转载必须标注原文链接。
©2023 Yang Li. All rights reserved.
欢迎关注 『十六宿舍』,大家喜欢的话,给个,更多关于嵌入式相关技术的内容持续更新中。