kafka基础
一、介绍
消息队列。可以应用到复杂的场景中。
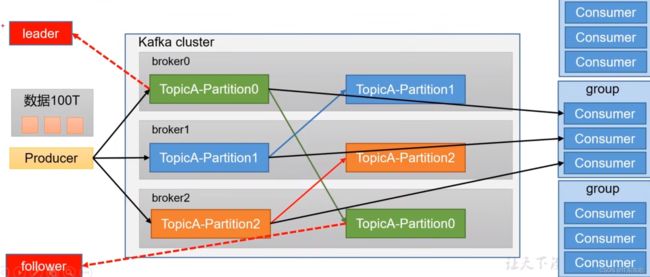
kafka由3部分组成:生产者,消费者,主题。
kafka集群:如果数据量大的话,一台服务器存储不了那么多数据,就引入了kafka集群,每个节点存储一部分数据。当然消费者也分组消费,一个消费者只能消费一个分区。
kafka副本:直接进行生产和消费的节点叫做leader,副本叫做follower。
二、安装
点击下载即可:
https://kafka.apache.org/downloads
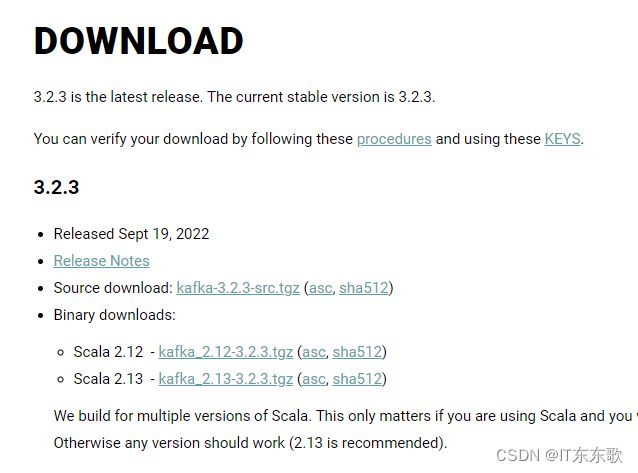
kafka_2.12-3.2.3.tgz 版本说明:kafka的生产者消费者者是用java写的,broker是用scala编写的,所以,2.12是scala版本,后面才是真正的kafka的版本号。
1、下载解压后,进入目录,首先是config目录
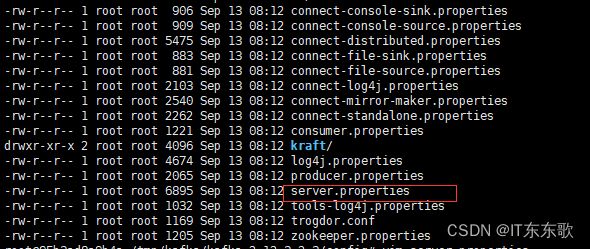
server.properties配置文件说明:
# 集群的时候用到,每个节点要不一样
broker.id=0
2、java环境
apt-get install openjdk-8-jre-headless
3、zookeeper
下载解压到服务器
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz 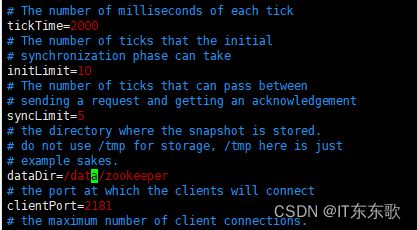
# 修改数据存储路径,要不然,服务器重启会丢失
dataDir=/data/zookeeper
重命名配置文件
mv zoo_sample.cfg zoo.cfg
进入bin目录启动
./zkServer.sh start
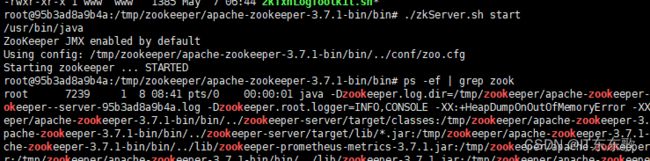
4、最后启动kafka
./kafka-server-start.sh -daemon ../config/server.properties
三、基本操作
1、新增主题
新增 topic-test 主题
./kafka-topics.sh --bootstrap-server localhost:9092 --topic topic-test --create --partitions 1 --replication-factor 1
查看所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list
查看详情
./kafka-topics.sh --bootstrap-server localhost:9092 --topic topic-test --describe
![]()
PartitionCount:1个分区
ReplicationFactor:1个副本
Partition:分区号
Leader:主副本号,生成消费都是针对leader
Replicas:副本号,如果多个就是0,1,2,3
生产数据
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic topic-test
![]()
消费数据
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-test
# 加--from-beginning参数会把历史数据也消费掉
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-test --from-beginning
![]()
四、kafka集群
1、Controller
Kafka集群中的broker在zk中创建临时序号节点,序号最小的节点(最先创建的节点)将作为集群的controller负责管理整个集群中的所有分区和副本的状态︰
·当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
·当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
·当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
2、Rebalance机制
前提是︰消费者没有指明分区消费。当消费组里消费者和分区的关系发生变化,那么就会触发rebalance机制。这个机制会重新调整消费者消费哪个分区。在触发rebalance机制之前,消费者消费哪个分区有三种策略:
range:通过公示来计算某个消费者消费哪个分区
轮询:大家轮着消费
sticky:在触发了rebalance后,在消费者消费的原分区不变的基础上进行调整。
3、HW和LEO
LEO是某个副本最后消息的消息位置(log- end-offset)
HW是已完成同步的位置。消息在写入broker时,且每个broker完成这条消息的同步后,hw才 会变化。在这之前消费者是消费不到这消息的。在同步完成之后,HW更新之后,消费者才能消费到这条消息,这样的目的是防止消息的丢失。
五、优化
1、防止消息丢失
●发送方: ack是1 或者-1/all可以防止消息丢失,如果要做到9.999%, ack设成ll, 把min.insync.replcas配置成分区 备份数
●消费方:把自动提交改为手动提交。
2、重复消费
A 在消费端幂等性保证:
1) 幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端 都只会持久化一条,保证了不重复。
精确一次(Exactly Once) =幂等性+至少一次( ack=-1 +分区副本数>=2 + ISR最小副本数量>=2)。
重复数据的判断标准:具有
所以幂等性只能保证的是在单分区单会话内不重复。
2)如何使用幂等性∈
开启参数enable.idempotence默认为true,false关闭。
B 事务
C 消费端处理
主键去重
3、顺序消费
主题只能设置-个分区,消费组中只能有一个消费者
4、消息积压
1)多线程消费
2)增加分区,多个消费组,多个消费者进行消费
5、延时队列
场景:30分钟过后订单未支付就取消订单
1)kafka中创建创建相应的主题
2)消费者消费该主题的消息(轮询)
3)消费者消费消息时判断消息的创建时间和当前时间是否超过30分钟(前提是订单没支付)
。如果是:去数据库中修改订单状态为已取消
。如果否:记录当前消息的offset, 并不再继续消费之后的消息。等待1分钟后,再次向kafka拉取该offset及之后的消息, 继续进行
判断,以此反复。
6、顺序生产
1) kafka在 1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1 ( 不需要考虑是否开启幂等性)。
2) kafka在1.x及 以后版本保证数据单分区有序,条件如下:
(1)未开启幂等性 max.in.flight.requests.per.connection需要设置为1。
(2)开启幂等性 max.in.flight.requests.per.connection需要设置小于等于5。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服 务端会缓存producer发来的最近5个request的元数据,
故无论如何,都可以保证最近5个request的数据都是有序的。
六、监控平台搭建
可自己搭建Eagle