YOLOv5入门实践(1)——手把手带你环境配置搭建

前言
这两天我将pycharm社区版换成了专业版,也顺带着把环境从CPU改成了GPU版,本篇文章也就是我个人配置过程的一个简单记录,希望能够帮到大家啦~

 本人YOLOv5源码详解系列:
本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
目录
前言
一、了解所需配置
1.1 CUDA
1.2 cuDNN
1.3 Anconda
1.4 pycharm
1.5 pytorch
二、安装CUDA 和cuDNN
2.1 CUDA的下载与安装
2.2 cuDNN的下载与安装
三、安装Anaconda
四、安装pytorch
五、配置YOLOv5环境
六、测试

一、了解所需配置
1.1 CUDA
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。
1.2 cuDNN
cuDNN是NVIDIACUDA®深度神经网络库,是GPU加速的用于深度神经网络的原语库。cuDNN为标准例程提供了高度优化的实现,例如向前和向后卷积,池化,规范化和激活层。
全球的深度学习研究人员和框架开发人员都依赖cuDNN来实现高性能GPU加速。它使他们可以专注于训练神经网络和开发软件应用程序,而不必花时间在底层GPU性能调整上。cuDNN的加快广泛使用的深度学习框架,包括Caffe2,Chainer,Keras,MATLAB,MxNet,PyTorch和TensorFlow。已将cuDNN集成到框架中的NVIDIA优化深度学习框架容器,访问NVIDIA GPU CLOUD了解更多信息并开始使用。
1.3 Anconda
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。 因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等
1.4 pycharm
pycharm是一个用于计算机编程的集成开发环境,主要用于python语言开发,并支持使用Django进行网页开发。简单来说就是人工智能的便捷语言。
1.5 pytorch
PyTorch是一个开源的Python机器学习库,其前身是2002年诞生于纽约大学 的Torch。它是美国Facebook公司使用python语言开发的一个深度学习的框架,2017年1月,Facebook人工智能研究院(FAIR)在GitHub上开源了PyTorch。
想进一步学习pytorch的友友,欢迎关注我的专栏噢!→Pytorch_路人贾'ω'的博客-CSDN博客
二、安装CUDA 和cuDNN
官方教程
CUDA:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
cuDNN:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
2.1 CUDA的下载与安装
1.首先查看自己CUDA的版本,有以下两种方法:
(1)打开nvidia(桌面右键)->选择左下角的系统信息->组件

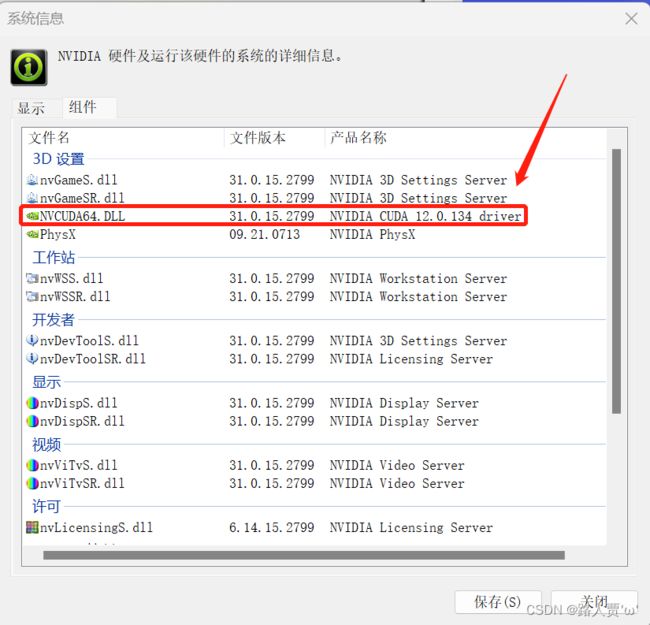
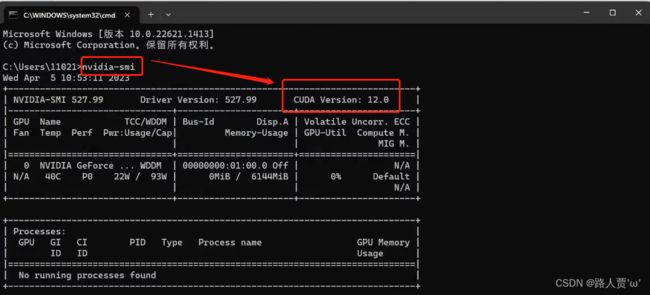
(2)直接在cmd中输入
nvidia-smi这里就可以直接查看啦
2.然后开始进入官网下载对应版本,下载地址→ 官方驱动 | NVIDIA
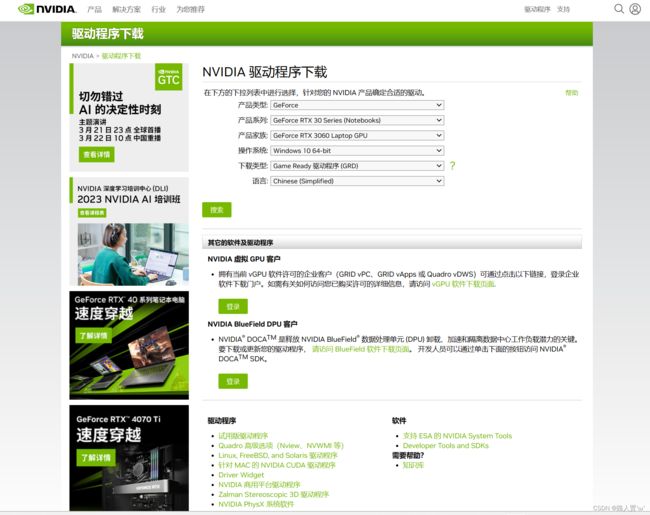
根据自己查到的版本下载对应既可。
然后就是漫长的等待ing

3.下载完了就开始安装
点击下一步
这两个可以不用勾选
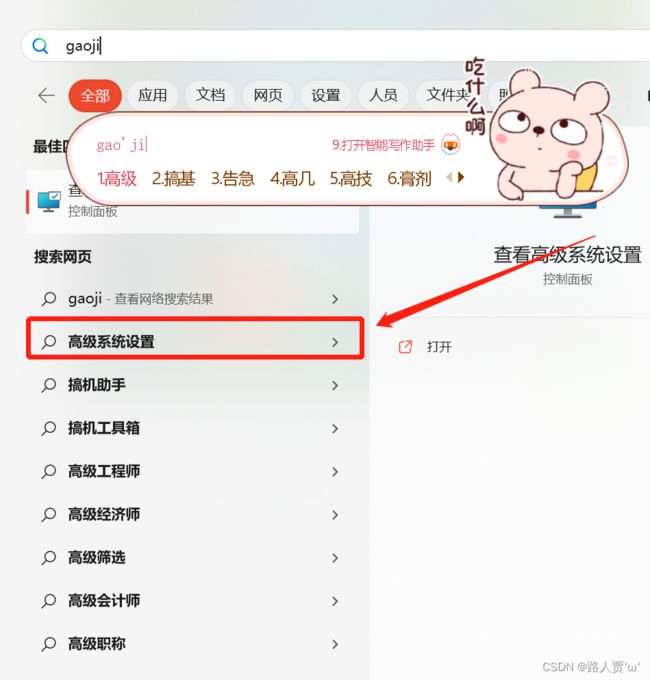
4.查看环境变量
点击开始-->搜索高级系统设置-->查看环境变量
【如果没有需要自己添加】
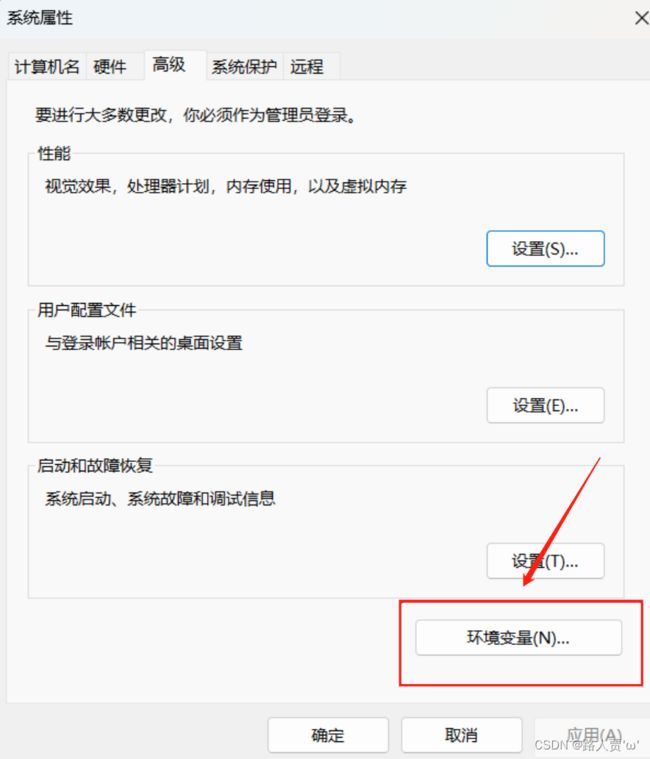
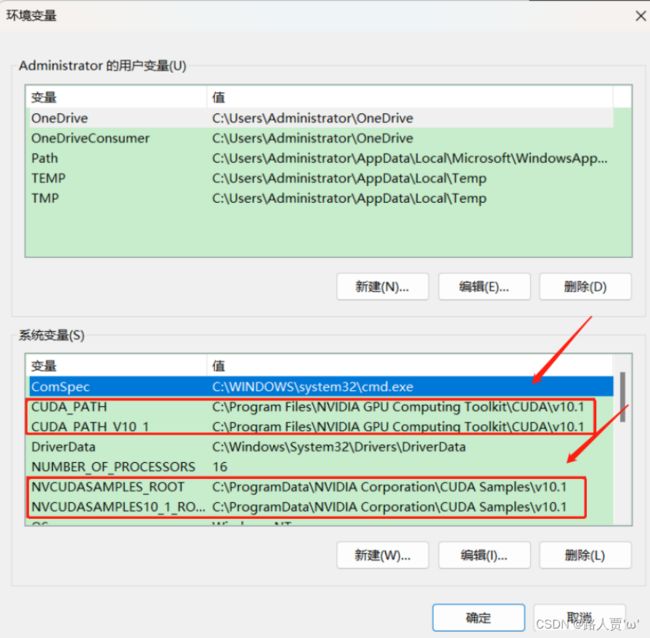
一共四个系统变量,都是自动生成的,但是有时后两个系统变量可能不会自动生成,需要自己添加上去,添加时注意路径。
5.验证CUDA是否安装成功
win+r,运行cmd,输入
nvcc --version
OR
nvcc -V即可查看版本号
 输入
输入
set cuda即可查看 CUDA 设置的环境变量 
至此,CUDA 就已安装完成。但是在完成张量加速运算时还需要cuDNN的辅助,所以接下来我们来安装cuDNN。
2.2 cuDNN的下载与安装
1.查看与CUDA对应的cuDNN版本

2.在官网上下载。官网地址→cuDNN Download | NVIDIA Developer
点击注册
 注册成功
注册成功

3.开始下载

4.解压文件
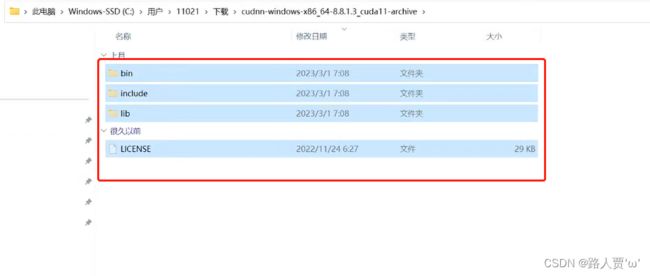
我们下载后发现其实cudnn不是一个exe文件,而是一个压缩包,解压后,有三个文件夹,把三个文件夹拷贝到cuda的安装目录下。
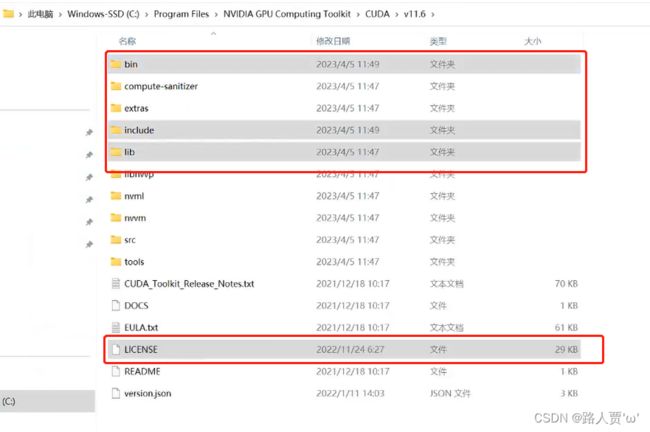 cuDNN 其实是 CUDA 的一个补丁,专为深度学习运算进行优化的。然后再添加环境变量
cuDNN 其实是 CUDA 的一个补丁,专为深度学习运算进行优化的。然后再添加环境变量
5.添加至系统变量
往系统环境变量中的 path 添加如下路径(根据自己的路径进行修改) 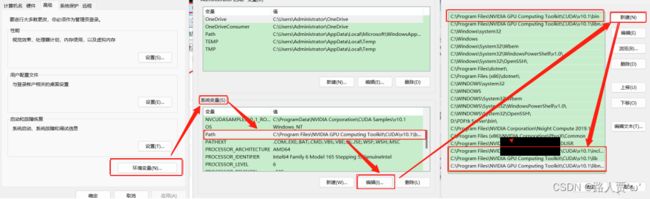
7.验证cuDNN是否安装成功
win+r,启动cmd,cd到安装目录下的.\extras\demo_suite,输入
原目录.\extras\demo_suite然后分别输入.\bandwidthTest.exe和.\deviceQuery.exe(进到目录后需要直接输“bandwidthTest.exe”和“deviceQuery.exe”)
.\bandwidthTest.exe.\deviceQuery.exe得到下图:
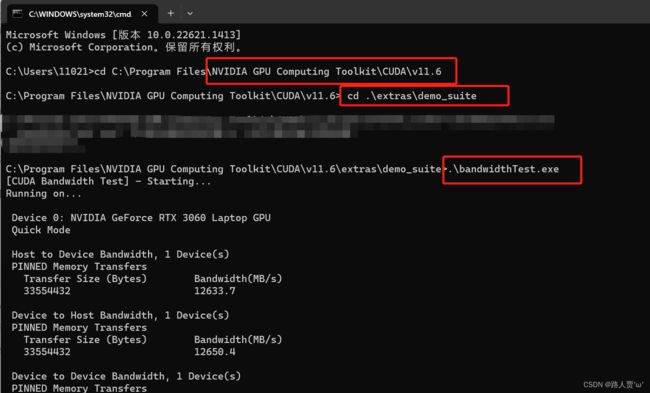

至此,CUDA和cuDNN已全部安装完毕~
三、安装Anaconda
因为我的电脑已经有了Anaconda ,所以没有再安装。没有安装的可以看看这个教程:
最新Anaconda3的安装配置及使用教程(详细过程)_HowieXue的博客-CSDN博客
四、安装pytorch
同样,pytorch我电脑上也安装过了(不然咋出的专栏呢(手动狗头))。没有安装的推荐大家看我同门的这篇文章,步骤非常详细:Win11上Pytorch的安装并在Pycharm上调用PyTorch最新超详细_win11安装pytorch
五、配置YOLOv5环境
1.yolov5的源码下载
下载地址:mirrors / ultralytics / yolov5 · GitCode
方法一:git clone到本地本地仓库
[指令]:git clone https://github.com/ultralytics/yolov5
方法二:直接安装压缩包
没有安装 git 的话,可以直接点击“克隆”下载压缩包
2.预训练模型下载
为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。
YOLOv5给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。在实际场景中是比较看这种速度,所以YOLOv5s是比较常用的。
将安装好的预训练模型放在YOLO文件下。
3.安装yolov5的依赖项
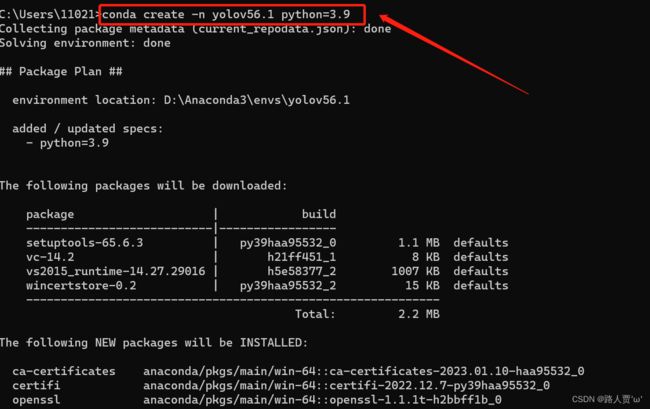
首先创建虚拟环境并激活。conda常用指令如下:
- 创建虚拟环境:
conda create -n [虚拟环境名] python=[版本]
 点“y”
点“y”
- 显示虚拟环境:
conda env list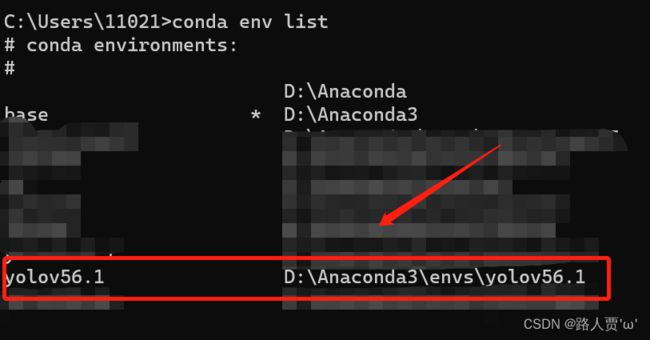
- 激活虚拟环境:
conda activate + [虚拟环境名]
4.安装pytorch-gup版的环境
由于pytorch的官网在国外,下载相关的环境包是比较慢的,所以我们给环境换源。在pytorch环境下执行如下的命名给环境换清华源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
这里要注意网速一定要好,不然就总报错。下图就是本人血泪史。
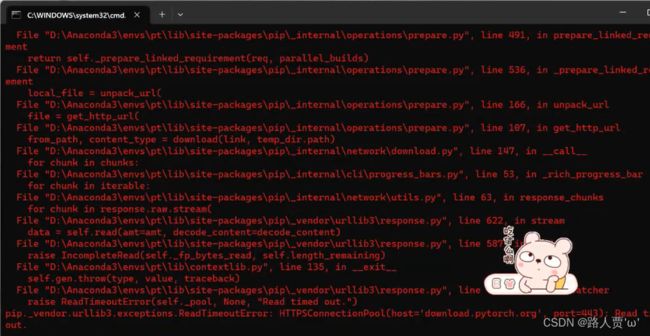
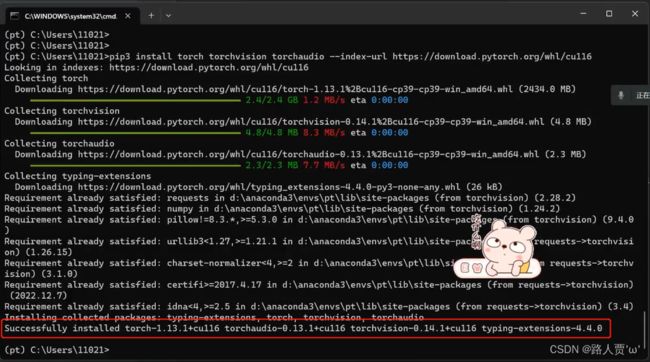
然后就安装完啦
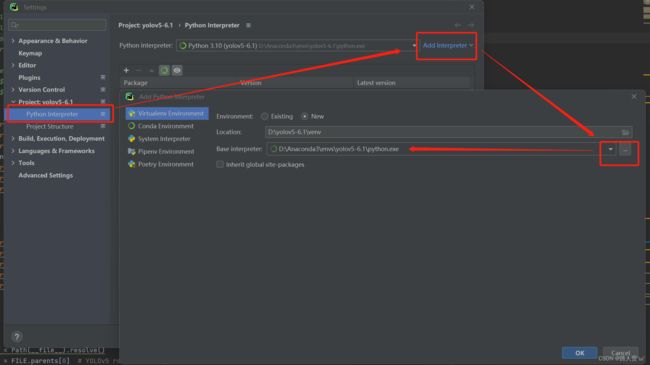
打开我们下载好的源码,点击设置setting
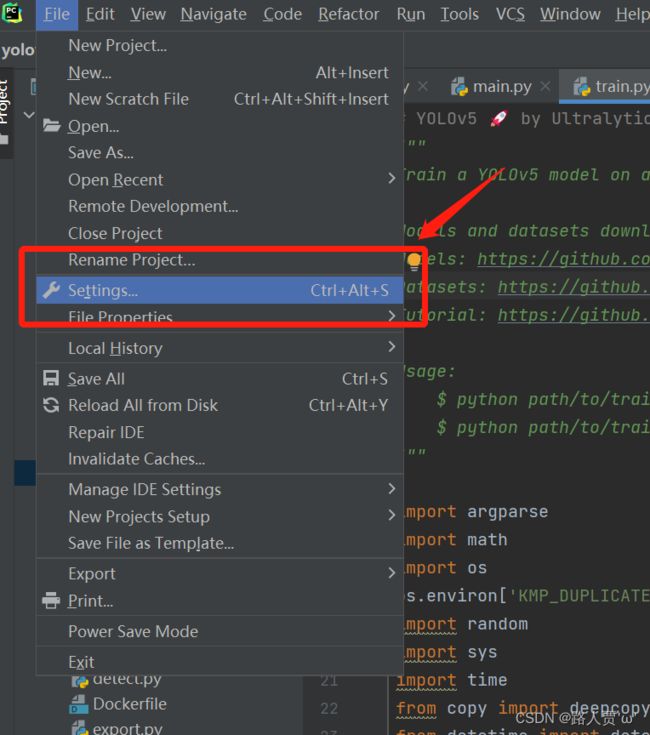
按以下步骤就OK啦!
六、测试
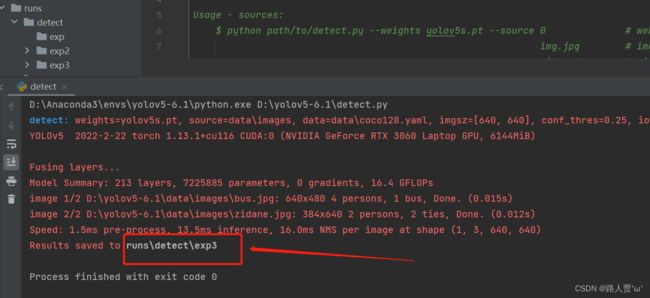
1.我们先运行detect.py

这时会发现出现错误:
AttributeError: 'Upsample' object has no attribute 'recompute scale_factor'
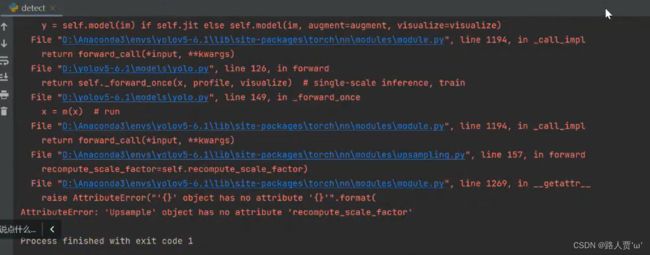
解决方法:
点进蓝色的文件里下图对应位置,更改forward函数,复制一遍,去掉下面一行的代码

再点击run,结果就保存在runs的detect文件下了
2.我们再运行train.py
同样会发生报错
0SError: [winError 1455]页面文件太小,无法完成操作。Error loading"D:\Anaconda3\envslyolov5-6.1lib\site-packages torch\lib\cudidTT"one of its dependencies
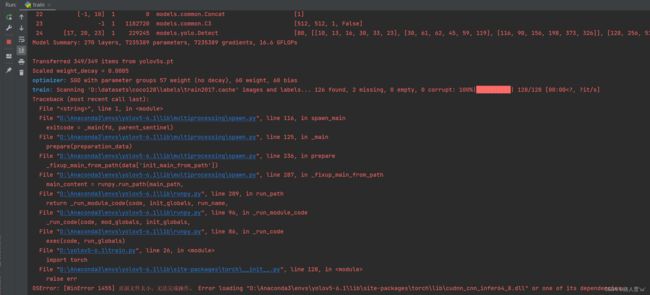
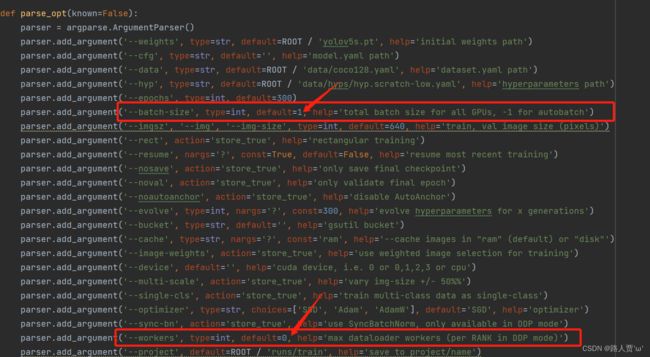
这就是因为我们batchsize和workers设置太大了的原因
解决方法:
找到train.py的parse_opt()函数,将对应batchsize和workers参数调小,如下图:
(你以为这样就完了吗?No!555~)
接着又会出现下面的错误:
OMP: Hint This means that multiple copies of the OpenMp runtime have been linked into theThat is dangerous, since it can degrade performance or cause incorrect results..

解决方法:
在import os下面加入
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE' 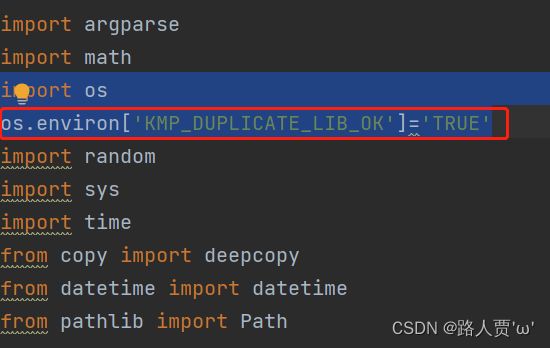
(这下没错了吧?你想多了~)
然后又会出现这样的错误:
RuntimeError: resutt type float can't be cast to the desired output type ._int64 
解决方法:
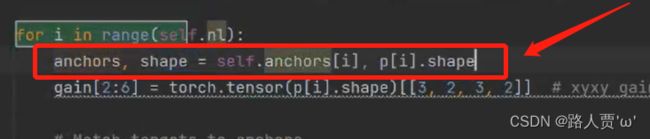
首先进入loss.py文件,将anchors = self.anchors[i]改为
anchors, shape = self.anchors[i], p[i].shape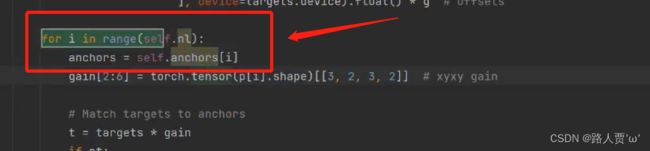
↓ 
接着往下翻,将indices.append((b, a, gj.clamp_(o, gain[3] - 1), gi.clamp_(0, gain[2] - 1))改为
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1)))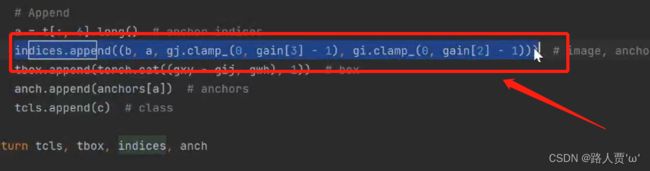
↓ 
到这终于能运行啦!撒花✿✿ヽ(°▽°)ノ✿
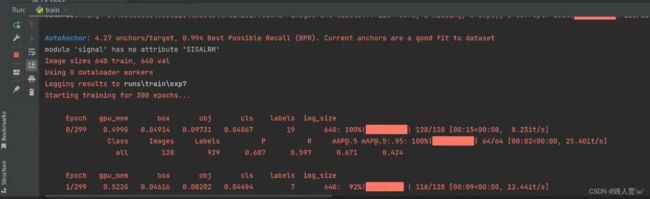
(训练时错误本来就有很多,但是错误原因网上都能找到的哦~)
到此为止,我们的环境就配好了。
本篇文章是我通过录屏复盘总结的,可能有一些地方有遗忘,大家要是配置过程中有问题还是要看看大佬们的教程(感谢大佬们!) 好了,我这个小白先撤了~下一篇再见啦!
本文参考:
CUDA与cuDNN安装教程(超详细)_kylinmin的博客-CSDN博客
【零基础上手yolov5】yolov5的安装与相关环境的搭建_罅隙`的博客-CSDN博客
