Python中urllib库详解
1、概述
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
主要包含模块有:
模块 |
描述 |
urllib.request |
模拟浏览器从服务器获取内容。 |
urllib.error |
包含 urllib.request 抛出的异常。 |
urllib.parse |
解析、编码URL |
urllib.robotparser |
解析 robots.txt 文件。 |

2、urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
实例①:获取百度首页源码(填坑)
import urllib.request
# 定义URL
url = "http://www.baidu.com/"
# 模拟浏览器向服务器发起请求获取响应
response = urllib.request.urlopen(url)
# 获取响应内容
content = response.read()
# 打印内容
print(content)

注意:如果发现获取的内容开头是"b"字母,读取的是字节,需要转换为相应的编码格式,具体转换成什么编码格式,则需要看要获取的网页源码的Content-Type元素值。
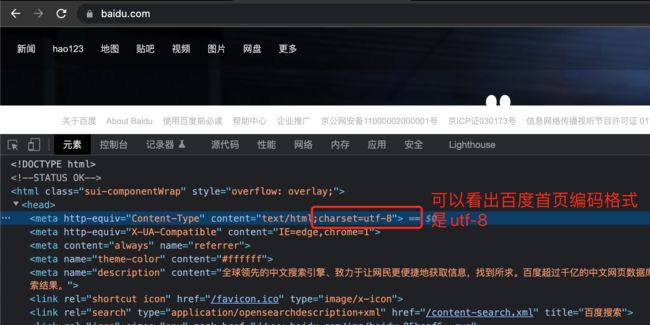
改造代码,增加字节编码解析
# 获取响应内容
content = response.read().decode('utf-8')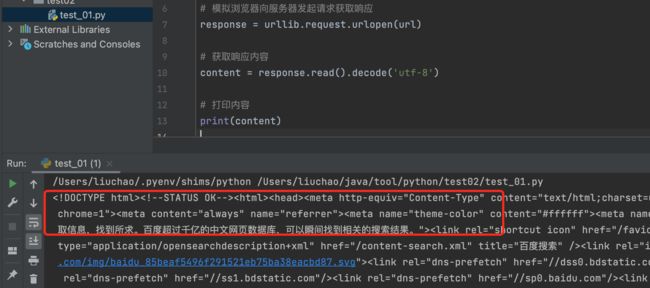
2.1、response方法列表
方法 |
描述 |
read() |
字节形式读取二进制 |
read(num) |
字节形式读取二进制,读取前几个字节 |
readline() |
读取一行数据 |
readlines() |
一行一行读取,直到结束 |
getcode() |
获取响应状态码 |
geturl() |
获取请求的URL |
getheaders() |
获取请求头 |
注意:读取数据时,如果已经读取再次调用方法是不会返回数据的

2.2、请求增加header
我们将请求百度首页的URL地址由http换为https,在不增加请求头的情况下,会遇到反爬,返回内容如下:

这个时候我们就需要在headers中增加UA
获取百度首页URL的UA(其他网页地址获取UA方式一致)

改造代码:
import urllib.request
# 定义URL
url = "https://www.baidu.com/"
# headers
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发起请求获取响应
response = urllib.request.urlopen(request)
# 第一次获取全部内容
content = response.read().decode('utf-8')
# 打印内容
print(content)

2.3、get请求增加参数
先看下百度首页搜索的请求

改造代码:
import urllib.request
# 定义URL
url = "https://www.baidu.com/s?wd="
# headers
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
url += "java"
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发起请求获取响应
response = urllib.request.urlopen(request)
# 第一次获取全部内容
content = response.read().decode('utf-8')
# 打印内容
print(content)
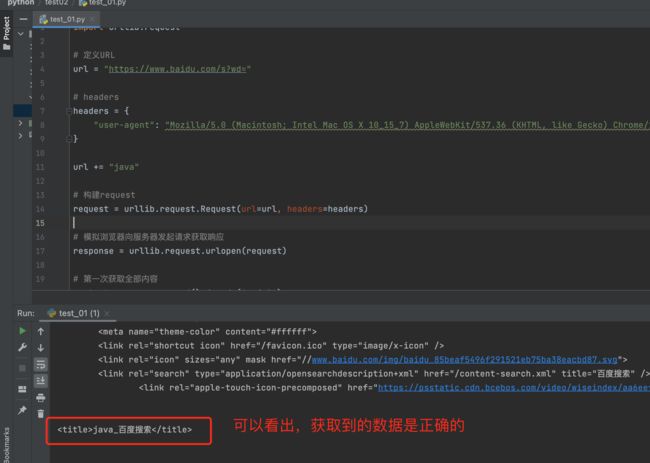
因为上面查询的关键字”java“是字母,换成中文则会报错

因为请求URL只识别ascii码,这个时候就需要用到urllib.parse 模块了
3、urllib.parse
我们将2.3代码改造下
# 导入包
import urllib.request
import urllib.parse
# 定义URL
url = "https://www.baidu.com/s?wd="
# headers
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
# 将中文编码为ascii码
url += urllib.parse.quote("中文")
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发起请求获取响应
response = urllib.request.urlopen(request)
# 第一次获取全部内容
content = response.read().decode('utf-8')
# 打印内容
print(content)

这种方式只能一个一个参数处理,多个参数处理方式
data = {
"kw": "中文",
"other": "也是中文"
}
# 打印结果:kw=%E4%B8%AD%E6%96%87&other=%E4%B9%9F%E6%98%AF%E4%B8%AD%E6%96%87
print(urllib.parse.urlencode(data))多参数改造:
import urllib.request
import urllib.parse
# 定义URL
url = "https://www.baidu.com/s"
# headers
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
# 定义多参数
data = {
"kw": "中文",
"other": "也是中文"
}
# 将参数编码,附加在URL后面
url += "?" + urllib.parse.urlencode(data)
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发起请求获取响应
response = urllib.request.urlopen(request)
# 第一次获取全部内容
content = response.read().decode('utf-8')
# 打印内容
print(content)
4、urllib.error
我们将3的代码改造,将地址写错增加错误捕获
import urllib.request
import urllib.parse
import urllib.error
# 定义URL
url = "https://www.baidu.com3/s"
# headers
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
data = {
"kw": "中文",
"other": "也是中文"
}
url += "?" + urllib.parse.urlencode(data)
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发起请求获取响应
try:
response = urllib.request.urlopen(request)
print(f"本次请求响应状态码:{response.getcode()}")
# 第一次获取全部内容
content = response.read().decode('utf-8')
# 打印内容
print(content)
except urllib.error.HTTPError as e:
if e.code == 404:
print("地址未找到")
else:
print("其他错误")
except urllib.error.URLError as e:
print(f"URLError:{e.reason}")

5、post请求
post请求是不能通过url传参,就得换另一种方式,咱们以百度翻译为例

改造代码,增加post请求入参
import urllib.request
import urllib.parse
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent": 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
data = {
"kw": "python"
}
# 编码请求参数,注意这里还得再次encode
data = urllib.parse.urlencode(data).encode("utf-8")
# 构建request
request = urllib.request.Request(url=url, data=data, headers=headers)
# 构建response
response = urllib.request.urlopen(request)
# 获取响应
content = response.read().decode('utf-8')
print(content)
但是响应结果:

说明我们的请求不符合要求,的改造请求头
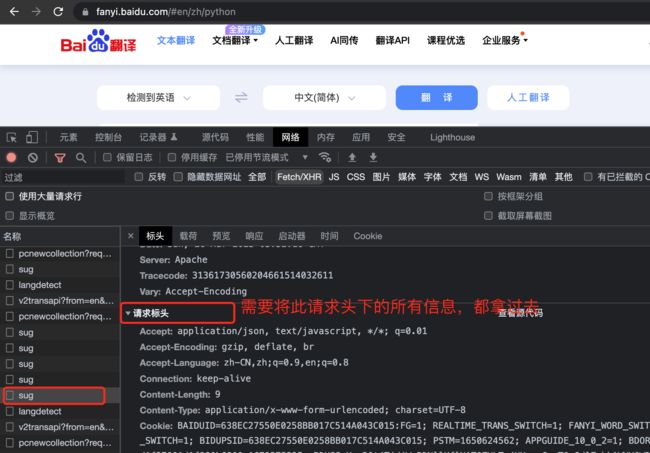
这里注意:一定不能将“Accept-Encoding” 加入请求头,否则获取的数据解码失败,报错信息如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1:invalid start byte
改造后代码:
import urllib.request
import urllib.parse
import json
url = "https://fanyi.baidu.com/sug"
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Content-Length': '9',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BAIDUID=638EC27550E0258BB017C514A043C015:FG=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BIDUPSID=638EC27550E0258BB017C514A043C015; PSTM=1650624562; APPGUIDE_10_0_2=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; Hm_lvt_afd111fa62852d1f37001d1f980b6800=1679375325; BDUSS=XgwR0t4TjdjWnBDNllKflN1T0ZVLTg4UXgxeGxnT0pSdlZwbk1WNVJWRTQ0RU5rRVFBQUFBJCQAAAAAAAAAAAEAAAC4iyA01ri84l~Q~cLJMTE2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADhTHGQ4Uxxka; BDUSS_BFESS=XgwR0t4TjdjWnBDNllKflN1T0ZVLTg4UXgxeGxnT0pSdlZwbk1WNVJWRTQ0RU5rRVFBQUFBJCQAAAAAAAAAAAEAAAC4iyA01ri84l~Q~cLJMTE2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADhTHGQ4Uxxka; H_WISE_SIDS=219946_234925_131861_216844_213352_214805_219943_213042_204917_230288_241994_242158_110085_227870_236308_243706_243873_244712_240595_244956_245412_246176_234208_246906_247981_236537_248724_107314_248312_249605_245945_248124_249814_240805_249924_249910_249123_250059_250137_250182_250120_247148_250738_250861_250888_251127_251259_248975_247510_251424_251461_245919_248087_251620_247130_250534_251132_251414_245217_252005_252035_251165_252129_252261_250759_252581_252392_251569_249892_247460_252577_252945_252901_246986_251150_253045_247585_253174_249501_234296_245043_253067_248079_248645_253481_252353_253427_253569; H_WISE_SIDS_BFESS=219946_234925_131861_216844_213352_214805_219943_213042_204917_230288_241994_242158_110085_227870_236308_243706_243873_244712_240595_244956_245412_246176_234208_246906_247981_236537_248724_107314_248312_249605_245945_248124_249814_240805_249924_249910_249123_250059_250137_250182_250120_247148_250738_250861_250888_251127_251259_248975_247510_251424_251461_245919_248087_251620_247130_250534_251132_251414_245217_252005_252035_251165_252129_252261_250759_252581_252392_251569_249892_247460_252577_252945_252901_246986_251150_253045_247585_253174_249501_234296_245043_253067_248079_248645_253481_252353_253427_253569; BAIDUID_BFESS=638EC27550E0258BB017C514A043C015:FG=1; BDRCVFR[feWj1Vr5u3D]=mk3SLVN4HKm; delPer=0; PSINO=1; BA_HECTOR=2l8h258gal248l8halag2h831i1vf161m; ZFY=c0rJ4j:AdzLjo4kODrTIyJlMpZ55Z63CyammYOfSmiyY:C; H_PS_PSSID=38185_36542_38368_38403_37861_38468_38173_38289_38377_37922_38382_37900_26350_38417_37881; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1679468059,1679487499,1679634739,1679802660; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1679802722; ab_sr=1.0.1_ZjIxMTUxZTFiNjhmMmE3MmM3MzQ0ZjIxOThmNDlhNmI4OWFjYzgxZmY4ODY3MGM1OWI1MGIwOTlmNzFiOTE3MGNhMDRkZDE2MjJjZjRlZTA5M2NhZDg2NTMwYjdmNjllODI5MDc3YWVkNmEzY2NlYzdjMTQzY2RhNDBkNjc5Mzc5MWVmM2JjNGE5ZmY3NDBiOGY1ZDAzODNkOWZkMWVhNzU5NWRkMDA5OGZiMGRkODdjYTJiZDQxZDczNzU5NTRm',
'Host': 'fanyi.baidu.com',
'Origin': 'https://fanyi.baidu.com',
'Referer': 'https://fanyi.baidu.com/',
'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
data = {
"kw": "python"
}
# 编码请求参数,注意这里还得再次encode
data = urllib.parse.urlencode(data).encode("utf-8")
# 构建request
request = urllib.request.Request(url=url, data=data, headers=headers)
# 构建response
response = urllib.request.urlopen(request)
# 获取响应
content = response.read().decode("utf-8")
# 因为获取到的数据是JSON格式,需要将字符串转换为JSON格式
obj = json.loads(content)
print(obj)
响应结果:

6、网页、图片、视频下载
代码:
import urllib.request
# 要下载的URL
url = "http://www.baidu.com/"
# 请求下载,filename为要存储为文件名称
urllib.request.urlretrieve(url=url, filename="baidu.html")