ChatGPT研究报告:AIGC带来新一轮范式转移
本文约4000字,目标是快速建立AIGC知识体系,含有大量的计算专业名词,建议阅读同时扩展搜索。
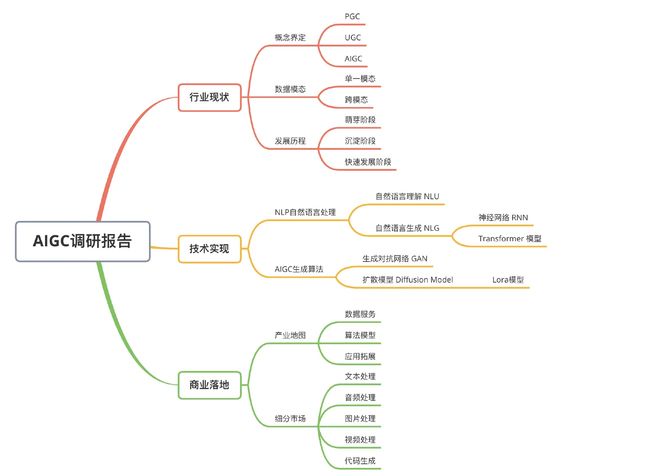
一、行业现状
1、概念界定
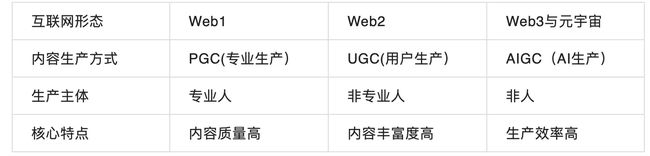
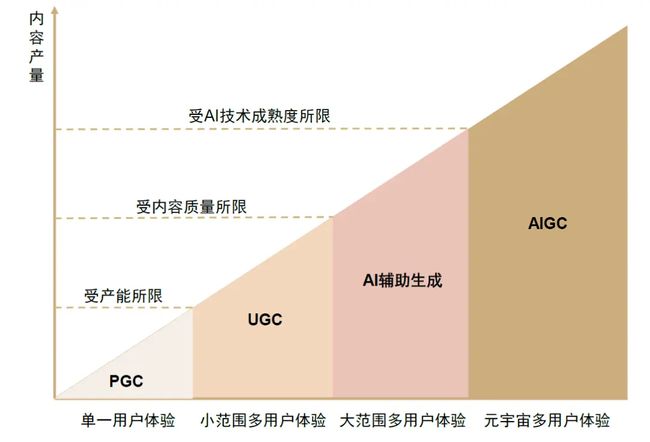
区别于PGC与UGC不同的,AIGC是利用人工智能技术自动生成内容的新型生产方式。
2、数据模态
按照模态区分,AIGC又可分为音频生成、文本生成、图像生成、视频生成及图像、视频、文本间的跨模态生成,细分场景众多,其中跨模态生成值得重点关注。
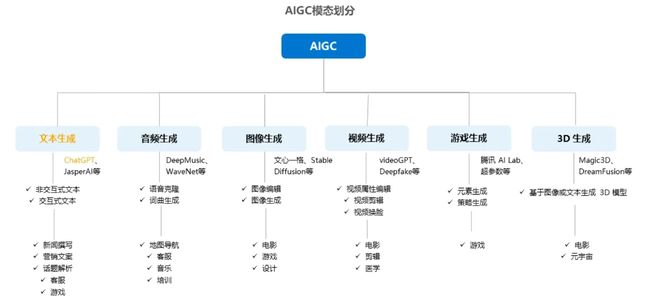
模态是指数据的存在形式,比如文本、音频、图像、视频等文件格式
跨模态,指的是像以文生成图/视频或者以图生成文这种情况
例如,百度的文心一格就是典型的以文生成图:
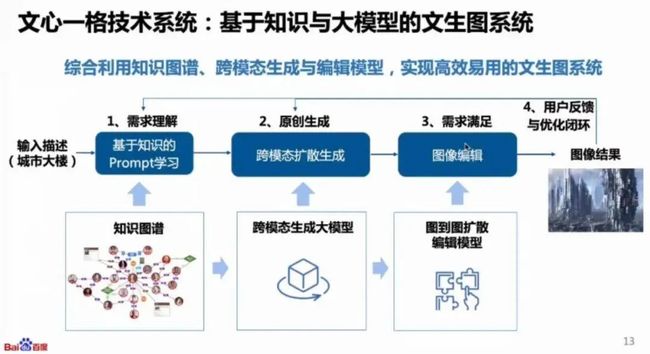
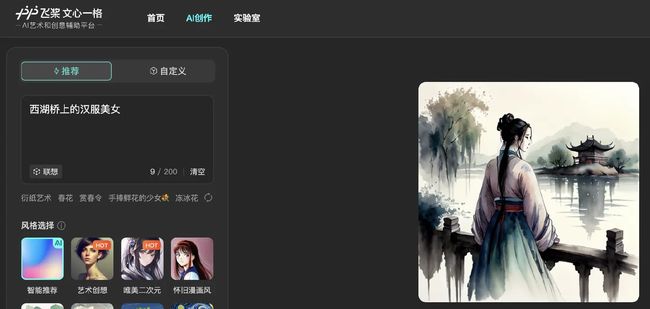
3、发展历程
AIGC 的发展可以大致分为以下三个阶段:
- 早期萌芽阶段:20 世纪 50 年代—90 年代中期,受限于科技水平,AIGC 仅限于小范围实验
- 沉积积累阶段:20 世纪 90 年代中期—21 世纪 10 年代中期,AIGC 从实验向实用转变,受限于算法,无法直接进行内容生成
- 快速发展阶段:21 世纪 10 年代中期—现在,深度学习算法不断迭代,AI 生成内容种类多样丰富且效果逼真

二、技术实现
AIGC 技术主要涉及两个方面:自然语言处理 NLP 和 AIGC 生成算法。
1、NLP自然语言处理
自然语言处理(NLP)赋予了AI理解和生成能力,是实现人与计算机之间如何通过自然语言进行交互的手段。
NLP技术可以分为两个方向:NLU和NLG。
1.1 自然语言理解 NLU
NLU使得计算机能够和人一样,具备正常人的语言理解能力。
过去,计算机只能处理结构化的数据,NLU 使得计算机能够识别和提取语言中的意图来实现对于自然语言的理解。

由于自然语言的多样性、歧义性、知识依赖性和上下文,计算机在理解上有很多难点,所以 NLU 至今还远不如人类的表现。
自然语言理解跟整个人工智能的发展历史类似,一共经历了 3 次迭代:基于规则的方法、基于统计的方法和基于深度学习的方法。

1.2 自然语言生成 NLG
NLG将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
NLG 的发展经历了三个阶段,从早期的简单的数据合并到模板驱动模式再到现在的高级 NLG,使得计算机能够像人类一样理解意图,考虑上下文,并将结果呈现在用户可以轻松阅读和理解的叙述中。

自然语言生成可以分为以下六个步骤:内容确定、文本结构、句子聚合、语法化、参考表达式生成和语言实现。


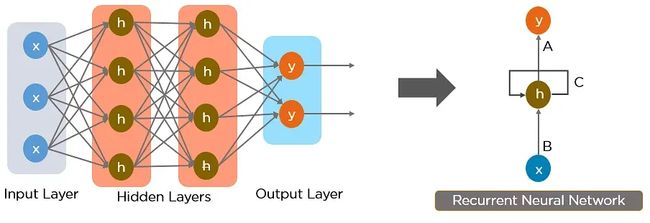
1.3 神经网络 RNN
神经网络,尤其是循环神经网络 (RNN) 是当前 NLP 的主要方法的核心。
其中,2017 年由 Google 开发的 Transformer 模型现已逐步取代长短期记忆(LSTM)等 RNN 模型成为了 NLP 问题的首选模型。
Transformer 的并行化优势允许其在更大的数据集上进行训练,这也促成了 BERT、GPT 等预训练模型的发展。
相关系统使用了维基百科、Common Crawl 等大型语料库进行训练,并可以针对特定任务进行微调。

1.4 Transformer 模型
Transformer 模型是一种采用自注意力机制的深度学习模型,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。
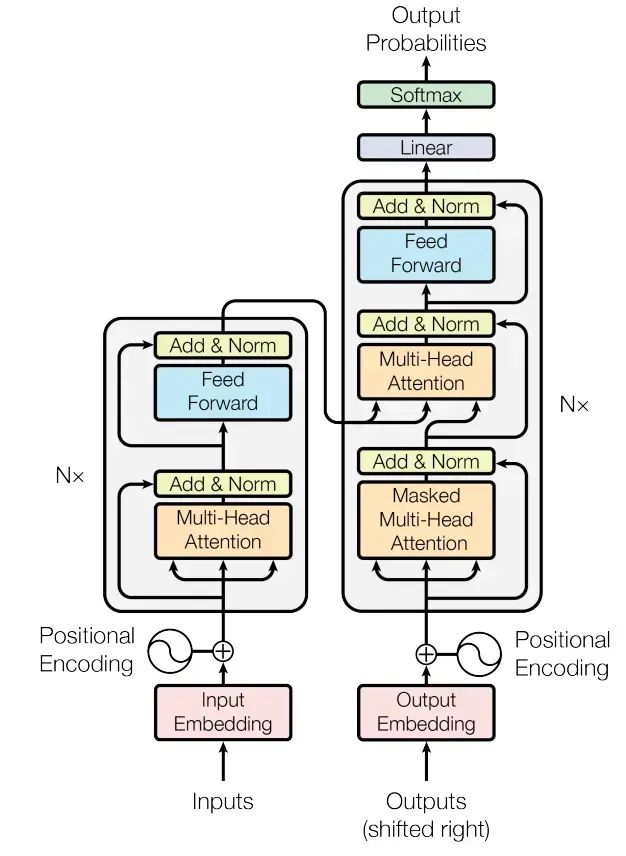
与循环神经网络(RNN)一样,Transformer 模型旨在处理自然语言等顺序输入数据,可应用于翻译、文本摘要等任务。与 RNN 不同的是,Transformer 模型能够一次性处理所有输入数据。

注意力机制可以为输入序列中的任意位置提供上下文。如果输入数据是自然语言,则 Transformer 不必像 RNN 一样一次只处理一个单词,这种架构允许更多的并行计算,并以此减少训练时间。
ChatGPT是OpenAI从GPT-3.5、GPT-4系列中的模型进行微调产生的聊天机器人模型,能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流。
2、AIGC算法
- AIGC 生成算法主流的有生成对抗网络 GAN 和扩散模型
- 扩散模型已经拥有了成为下一代图像生成模型的代表的潜力
2.1 生成对抗网络 GAN
GAN是生成模型的一种,透过两个神经网络相互博弈的方式进行学习。
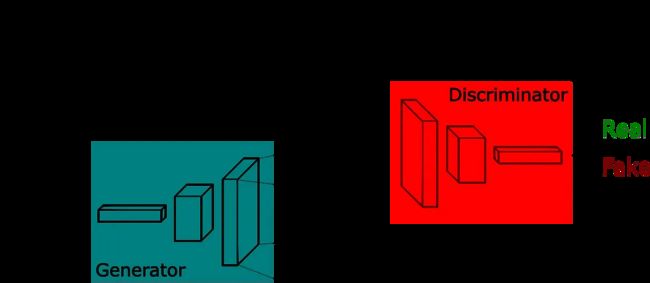
GAN 被广泛应用于广告、游戏、娱乐、媒体、制药等行业,可以用来创造虚构的人物、场景,模拟人脸老化,图像风格变换,以及产生化学分子式等等。
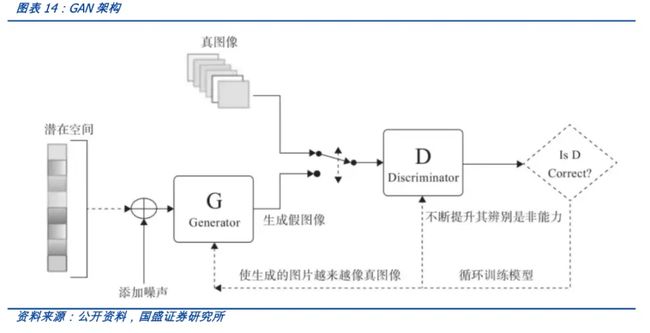
2.2 扩散模型 Diffusion Model
GAN(生成对抗网络)有生成器和鉴别器,它们相互对抗,然后生成图像,由于模型本身具有对抗性,因此很难进行训练,利用扩散模型可以解决这个问题。
扩散模型也是生成模型,扩散模型背后的直觉来源于物理学。在物理学中气体分子从高浓度区域扩散到低浓度区域,这与由于噪声的干扰而导致的信息丢失是相似的。
Diffusion通过引入噪声,然后尝试通过去噪来生成图像。在一段时间内通过多次迭代,模型每次在给定一些噪声输入的情况下学习生成新图像。
2.3 Lora模型
LoRA是Low-Rank Adaption of large language model的缩写,是一种大语言模型fine-tune的方法。
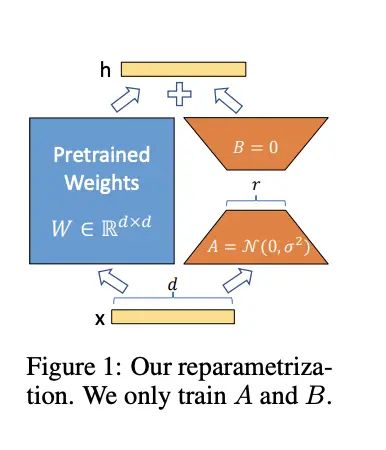
Lora主要思路是在固定大网络的参数,并训练某些层参数的增量,且这些参数增量可通过矩阵分解变成更少的可训练参数,大大降低finetune所需要训练的参数量。

三、商业落地
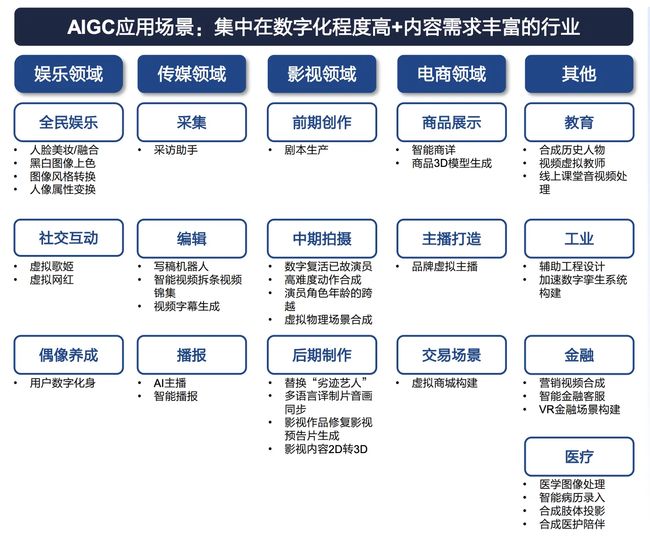
1、A应用场景
- AIGC 在文字、图像、音频、游戏和代码生成中商业模型渐显
2、产业地图
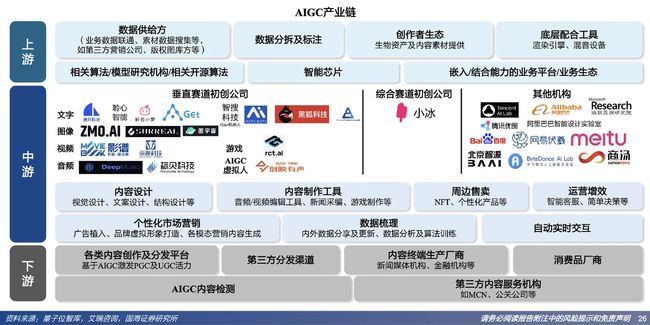
2.1 产业上游:数据服务
- 人工智能的分析、创作、决策能力都依赖海量数据
- 决定不同机器间能力差异的就是数据的数量与质量
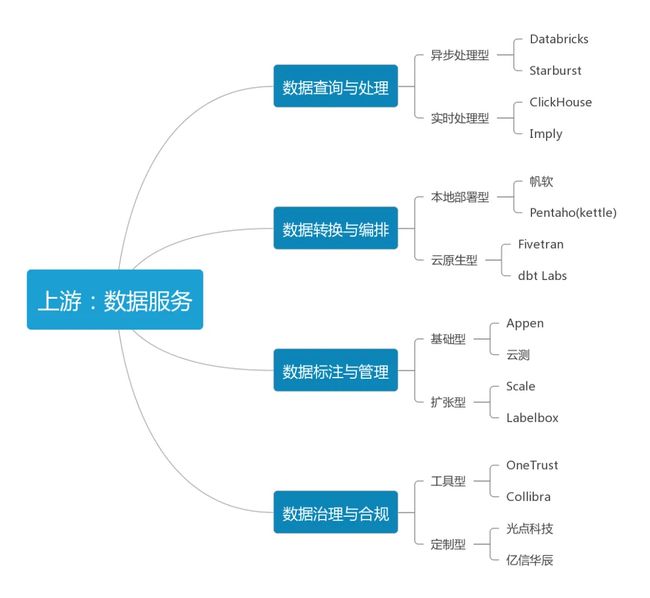
2.2 产业中游:算法模型
算法模型是AIGC最核心的环节,是机器学习的关键所在。通常包含三类参与者:专门实验室、企业研究院、开源社区。
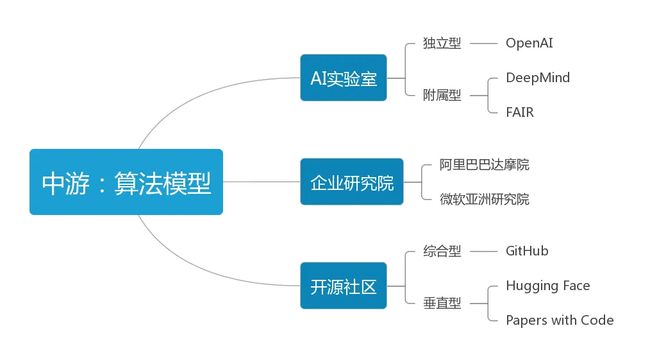
AI实验室:算法模型在AI系统中起决策作用,是它完成各种任务的基础,可以视为AI系统的灵魂所在。
企业研究院:一些集团型公司或企业往往会设立专注于前沿科技领域的大型研究院,下设不同领域的细分实验室,通过学术氛围更浓厚的管理方式为公司的科研发展添砖加瓦。
开源社区:社区对AIGC非常重要,它提供了一个共享成果、代码的平台,与其他人相互合作,共同推动AIGC相关技术的进步。根据覆盖领域的宽度和深度,这种社区可以分为综合型开源社区和垂直型开源社区。
2.3 产业下游:应用拓展
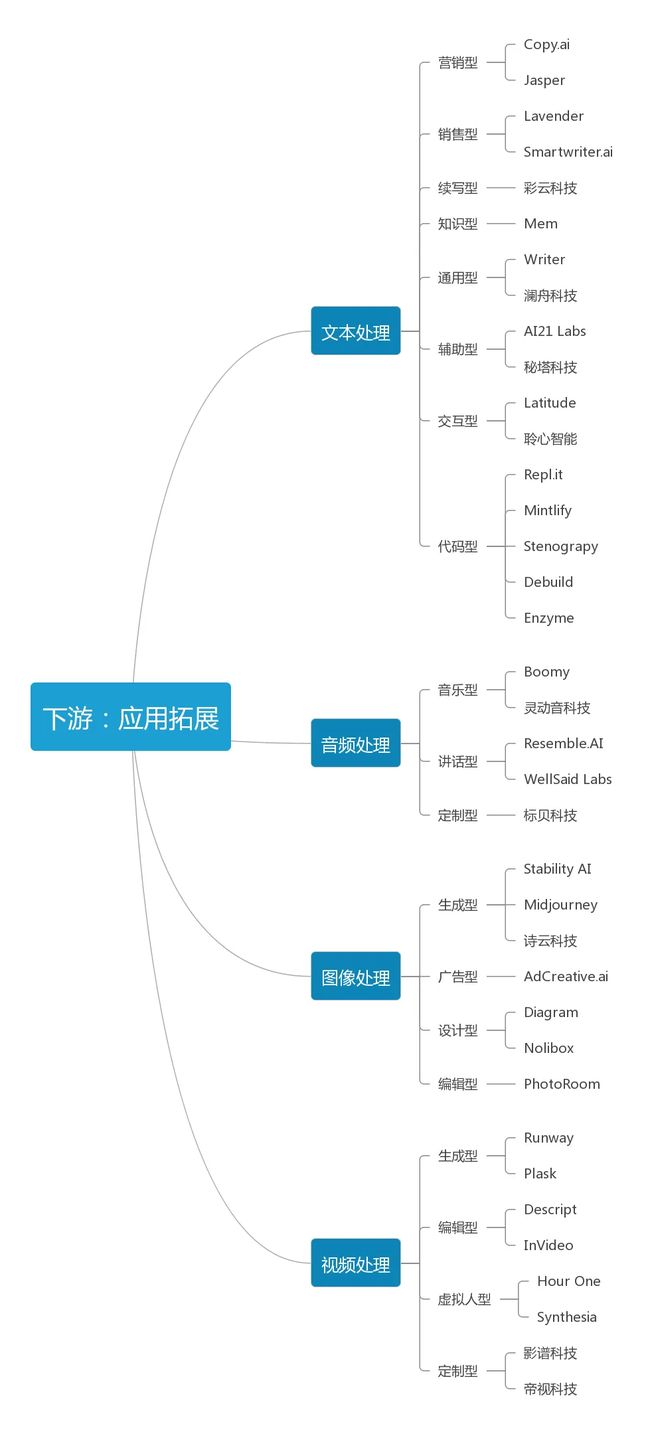
3、细分市场
3.1 文本处理
文本处理是AIGC相关技术距离普通消费者最近的场景,技术较为成熟。
一般说来文本处理可以细分为营销型、销售型、续写型、知识型、通用型、辅助型、交互型、代码型。

3.2 音频处理
目前的音频处理主要分为三类:音乐型、讲话型、定制型,AI的应用将优化供给效率,改善整体利润水平。
3.3 图片处理
图片的创作门槛比文字高,传递信息也更直观,随着AIGC应用的日益广泛,图片处理也就从广告、设计、编辑等角度带来更大更多的机遇。图片处理可细分为生成型、广告型、设计型、编辑型。
3.4 视频处理
视频日益成为新时代最主流的内容消费形态,将AIGC引入视频将是全新的赛道,也是技术难度最大的领域。视频处理可以细分为生成型、编辑型、定制型、数字虚拟人视频。

3.5 代码生成
以GitHub Copilot为例,Copilot是GitHub 和 OpenAI 合作产生的 AI 代码生成工具,可根据命名或者正在编辑的代码上下文为开发者提供代码建议。官方介绍其已经接受了来自 GitHub 上公开可用存储库的数十亿行代码的训练,支持大多数编程语言。
四、面临挑战
除了技术上亟待解决的算力、模型准确性之外,目前AIGC相关的挑战主要集中在版权、欺诈、违禁内容三方面。
1、版权问题
- AIGC是机器学习的应用,而在模型的学习阶段一定会使用大量数据,但目前对训练后的生成物版权归属问题尚无定论
- 为什么AI基于自己创作的作品生成的新作品却与自己无关?而且现行法律都是针对人类的行为规范而设立的
- AI只是一种工具,不受法律约束与审判,即便证据充分,作者的维权之路通常也难言顺利
- 不过对于AIGC与作者的关系将会随着时代发展而逐渐清晰,界定也将更有条理性
2、欺诈问题
- 高科技诈骗手段层出不穷,AI经过训练后也可以创作出以假乱真的音视频,“换脸”“变声”等功能,滥用危害甚大
- 部分诈骗分子利用“换脸”技术实施诈骗,也有不法分子恶意伪造他人视频,再转手兜售到灰色市场
3、违禁内容
- AIGC取决于使用者的引导,AI对恶意诱导会不加分辨或判断,会根据学习到的信息输出极端或暴力言论
- AIGC作为内容生产的新范式,也对国家相关法律法规机构及监管治理能力都提出了更高要求
参考资料
https://chat.openai.com/chat
https://arxiv.org/pdf/1706.03762.pdf
https://arxiv.org/pdf/1406.2661.pdf
https://arxiv.org/pdf/1409.2329.pdf
https://arxiv.org/pdf/2112.10752.pdf
https://arxiv.org/pdf/2106.09685.pdf
https://github.com/pbloem/former
https://github.com/haofanwang/Lora-for-Diffusers/blob/main/convert_lora_safetensor_to_diffusers.py
AIGC:内容生产力的革命—国海证券
AIGC发展趋势报告2023—腾讯研究院
2023AIGC行业研究报告—甲子光年