〖Python网络爬虫实战⑧〗- requests的使用(二)
- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
〖Python网络爬虫实战⑥〗- 多线程和多进程
〖Python网络爬虫实战⑦〗- requests的使用(一)
⭐️requests的使用(二)
上一篇我们说了requests的简单用法,知道了如何发送请求,今天我们更深层次的来学习requests。我们看看高级一点的操作,比如讲文件上传,cookies设置,代理设置之类的。
1.文件上传
我们知道requests可以模拟提交一些数据,除此之外。有的网站需要我们上传文件,我们用requests同样也可以实现。比如讲,我们现在想上传文件,我们可以这样做。
import requests
f = {'f':open('a.text','rb')}
r = requests.post('http://httpbin.org/post',files = f)
print(r.text)我们运行一下程序,我们看有什么效果。

我们可以看到响应里面包含了files的这个字段,而form这个字段是空的,这证明了文件上传部分会单独有一个files字段来标识。
2.cookies
我们可以用cookies来维持登录状态,在浏览器里面,在开发者工具里面,我们可以找到cookies字段,我们可以直接复制即可。
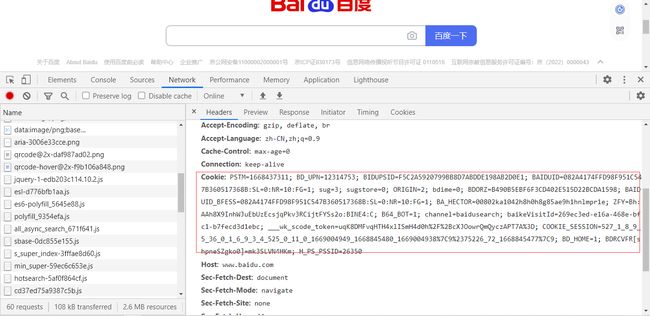
我们将cookies设置到headers里面,然后,发送请求,就可以登录了。示例代码如下:
import requests
headers = {
'Cookie': 'BIDUPSID=5A5A25DCD448BB79A207EED72F283FC9; PSTM=1673148180; BAIDUID=39FBDAC549C05F71A3F3F5A60CFA4D21:SL=0:NR=10:FG=1; newlogin=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=36549_38054_37910_38148_37990_38178_38170_37802_37923_38088_26350_38118_38096_38008_37881; BAIDUID_BFESS=39FBDAC549C05F71A3F3F5A60CFA4D21:SL=0:NR=10:FG=1; ab_sr=1.0.1_ZmZlMjZjM2MwNjRlZTEyMDg0YmIxNDc3ZDY4OWY5NDRiNzkwZjE0Yjk2YWJjMWQxOGJkZTUyMGM3MzBkMmUxYjYxYTM1NzZkYWY3ZWNkOWNjYzY5MzU4NDkyMWY5ODZjZGQ4OWFmM2I2YTY0MTA3OGY3Y2NhOWNjMGVmYmU1YmM4ZDM1YzBlZTJmZjZjZTI5Yzk2ZWVlZDhkZjYxNTNjYQ==',
}
res = requests.get('https://www.baidu.com/',headers=headers)
print(res.text)3.SSL证书验证
那么什么是SSL证书呢?
- SSL证书是一种数字证书,是一种电子副本,类似于驾驶证、护照和营业执照的电子副本。它由受信任的数字证书颁发机构(CA)签发,并且客户端和服务器都必须验证证书的有效性。
- SSL证书的主要功能是提供服务器身份验证和数据传输加密。它可以确保数据在传输过程中不被窃取或篡改,并且可以增强安全性,防止未经授权的人员访问服务器。
- 在SSL证书验证过程中,客户端和服务器都需要验证证书的有效性。
此外,requests还有证书验证的功能,当发送HTTP请求的时候,它会检查SSL证书,我们可以使用verify参数控制是否检查此证书。一般默认是打开的。
那我们的代码怎么写呢?
response = requests.get('http://www.baidu.com',verify = False)4.代理设置
对于一些网站,在测试的时候还能获取内容,一旦频繁爬取,就有可能被封IP,导致一段时间无法访问。那么,为了防止这种情况发生,我们就要设置代理来解决,这里就用到了proxies参数。
Proxy 是 Python 的一个内置模块,它可以用来创建代理对象,用于在网络上转发请求和响应。在 Python 中,可以使用 requests 库来发送 HTTP 请求,并使用 proxies 参数来指定代理对象。
下面是一个示例代码,演示如何使用 proxies 参数来设置代理对象:
import requests
# 创建一个 requests 对象
r = requests.get('http://example.com')
# 设置代理对象
r.proxies = {'http': 'http://proxy.example.com:80'}
# 发送请求并获取响应
response = r.send()
# 打印响应状态码和头部信息
print(response.status_code)
print(response.headers)
在上面的代码中,我们首先创建了一个
requests对象,并使用proxies参数设置了一个代理对象。在这个例子中,我们将http请求转发到了一个名为proxy.example.com的代理服务器上,并将代理服务器的地址设置为80。然后,我们使用
send方法发送了一个 HTTP GET 请求,并将代理对象作为参数传递给了它。最后,我们使用response.status_code和response.headers属性打印了响应状态码和头部信息。
5.超时设置
在网路不好的时候,或者服务器响应太慢,甚至有时候还会报错,为了防止服务器不能及时响应,我们可以设置一个超时设置,这里就用到了timeout参数。
response = requests.get('http://www.baidu.com',timeout= 30) request 对象的 timeout 属性用于设置请求超时时间。默认情况下,timeout 属性的值为 60,表示请求超时时间为 60 秒。如果需要更改超时时间,可以将其设置为一个更小的值,例如 30,表示请求超时时间为 30 秒。
如果需要在请求发送后立即返回一个响应,可以将 timeout 属性设置为 0。这将使 timeout 属性的值为 None,表示请求超时时间为 永远。
总结
今天我们更深层次的来学习requests。我们看看高级一点的操作,比如讲文件上传,cookies设置,代理设置之类的。下一篇,我们就来说说正则表达式的相关知识点。
