GBDT算法梳理
GBDT梯度提升树
- CART(分类回归树)
这里为什么要第一个说分类回归树呢,因为GDBT实际上也是一种集成树的算法,而每棵子树其实都是分类回归树,这里的分类树和回归树其实在字面上就可以区分,分类树的叶子节点是我们样本的类别,或者可以说是标签,而回归树,是对样本数据的某个特征的回归,也可以说是拟合,比如给你一个人的工资,身高,爱好,等等特征,要你预测一下他的年龄,这个过程用到的就是回归树.
在之前的分类决策树中,我们选择最佳切分节点用的是特征矩阵的特征值,计算其信息增益的算法,但是这里的回归树一般处理地是连续型数据,可能也有人会说,我们可以把连续型的数据人为地替换成离散数据,例如我们可以自己设置阈值,满足条件地归为一类,不满足条件地归为其他类,但是这样会破环连续性数据的内在联系,而且我们所设的阈值一般都是根据自己的经验,而毫无科学依据.所以这里为成功构建以分段常数为叶节点的数,需要度量出数据的一致性,度量的标准就是使用方差来
2.加法模型
GBDT算法可以看成是由K棵树组成的加法模型:

其中T表示决策树, θ \theta θ表示内部参数,于一般的机器学习算法不同的是,加法模型不是学习d维空间中的权重,而直接是学习函数(决策树)集合
3.负梯度函数
GBDT与Adaboosting算法的思想不一样,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去,便可得到比价合理的权重,然后把各棵子树的结果安装权重累加,得最终结果。但在GBDT中,在GBDT的迭代中,在残差减少的梯度方向建立新的弱模型。直观上看,它用来训练第K轮弱模型的数据,来自于之前所有弱模型集成后的预测值和样本真实值的"差",准确来说损失函数梯度减少的方向,假设我们前一轮迭代得到的强学习器是ft−1(x), 损失函数是L(y,ft−1(x)), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失函数L(y,ft(x)=L(y,ft−1(x)+ht(x))最小,用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树。第t轮的第i个样本的损失函数的负梯度表示为:
r t i = − [ ∂ L ( y i , f ( x i ) ) ) ∂ ; f ( x i ) ] f ( x ) = f t − 1 ( x ) r_{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial;f(x_i)}\bigg]_{f(x) = f_{t-1}\;\; (x)} rti=−[∂;f(xi)∂L(yi,f(xi)))]f(x)=ft−1(x)
利用 ( x i , r t i ) ( i = 1 , 2 , . . m ) (x_i,r_{ti})\;\; (i=1,2,..m) (xi,rti)(i=1,2,..m),我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域 R t j , j = 1 , 2 , . . . , J R_{tj}, j =1,2,..., J Rtj,j=1,2,...,J。其中J为叶子节点的个数。
4 正则化
对训练集拟合过高会降低模型的泛化能力,需要使用正则化技术来降低过拟合。
1.对复杂模型增加惩罚项,如:模型复杂度正比于叶结点数目或者叶结点预测值的平方和等2.用于决策树剪枝3.叶结点数目控制了树的层数,一般选择4≤J≤8。4.叶结点包含的最少样本数目,防止出现过小的叶结点,降低预测方差5.梯度提升迭代次数M:增加M可降低训练集的损失值,但有过拟合风险
5.GDBT的优缺点
优点:预测阶段的计算速度快,通常不需要太大的决策树的深度就能达到很好的拟合效果, 树与树之间可并行化计算。在分布稠密的数据集上, 泛化能力和表达能力都很好,采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系, 并且也不需要对数据进行特殊的预处理如归一化等。
缺点:GBDT在高维稀疏的数据集上, 表现不如支持向量机或者神经网络。
GBDT在处理文本分类特征问题上, 相对其他模型的优势不如它在处理数值特征时明显。训练过程需要串行训练, 只能在决策树内部采用一些局部并行的手段提高训练速度。
6.GDBT的优缺点
一些主要参数
loss: 损失函数,GBDT回归器可选’ls’, ‘lad’, ‘huber’, ‘quantile’。
learning_rate: 学习率/步长。
n_estimators: 迭代次数,和learning_rate存在trade-off关系。
criterion: 衡量分裂质量的公式,一般默认即可。
subsample: 样本采样比例。
max_features: 最大特征数或比例。
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(load_boston().data, load_boston().target, test_size=0.2)
reg_model = GradientBoostingRegressor(
loss='ls',
learning_rate=0.02,
n_estimators=200,
subsample=0.8,
max_features=0.8,
max_depth=3,
verbose=2
)
prediction_train = reg_model.predict(X_train)
rmse_train = mean_squared_error(y_train, prediction_train)
prediction_test = reg_model.predict(X_test)
rmse_test = mean_squared_error(y_test, prediction_test)_70)
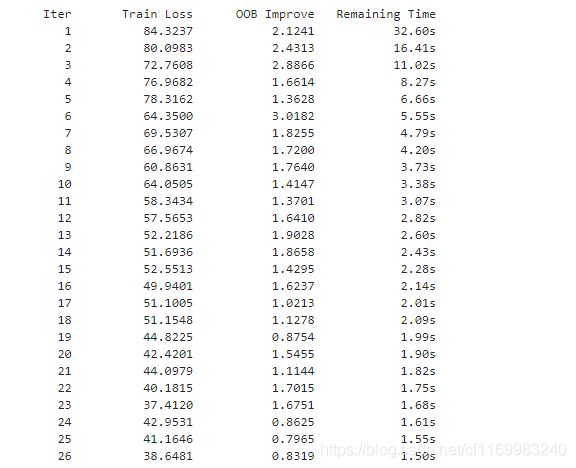
运行结果: