MySQL性能优化(二)索引
文章目录
- 优化手段
-
- 准备
- 案例
- 索引的本质
- 索引的数据结构
- 不同存储引擎中索引的实践
-
- MyIsam (索引没有主次之分、都存放在MYI文件)
-
- 主键索引
- 其他索引
- InnoDB(数据即索引、索引即数据)
-
- 主键索引——聚集索引
-
- 聚集索引
- 其他索引
- 没有主键的情况?
- 索引的创建和使用原则
-
- 索引越多越好么?
- 列的离散度:count(distinct(column_name)):count(*)
- 联合索引的最左匹配原则
-
- 冗余索引
- 覆盖索引
- 索引条件下推(ICP)
- 建立索引的原则:
-
- 前缀索引
- 使用索引的原则
-
- 什么时候用不到索引
- 优化器
优化手段
- 表的索引越全越好么?
- 为什么不要在性别子弹常见索引?
- 为什么不建议使用身份证做主键?
- 模糊匹配like xx%,like %xx% , like %xx都不用到索引么?
- 为什么不建议使用select * ?
准备
create table user_innodb
(
id int not null primary key,
username varchar(255) null,
gender char(1) null,
phone char(11) null
) ENGINE=INNODB;
create table user_myisam
(
id int not null primary key,
username varchar(255) null,
gender char(1) null,
phone char(11) null
) ENGINE=myisam;
create table user_memory
(
id int not null primary key,
username varchar(255) null,
gender char(1) null,
phone char(11) null
) ENGINE=memory;
SET @i = 1;
INSERT INTO user_innodb (id, username,gender, phone)
SELECT @i := @i + 1 AS id,
CONCAT('user', LPAD(@i, 5, '0')) AS username,
IF(FLOOR(RAND() * 2) = 0, '1', '0') AS gender,
CONCAT('1', LPAD(FLOOR(RAND() * 10000000000), 10, '0')) AS phone
FROM INFORMATION_SCHEMA.TABLES,
INFORMATION_SCHEMA.TABLES AS t2
WHERE @i < 5000000;
select max(id) from user_innodb
案例
-- 没有索引的查询时间
select * from user_innodb where username = 'huathy'
> OK
> 时间: 5.872s
-- 为username字段加上索引
alter table user_innodb add index idx_user_innodb_name(username);
-- 走索引的name查询时间开销
select * from user_innodb where username = 'huathy'
> OK
> 时间: 0.017s
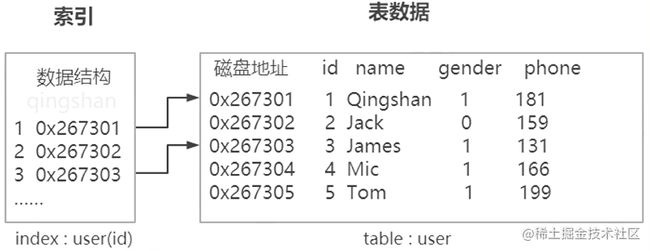
索引的本质
数据库索引:数据库管理系统中一个排序的数据结构,加快查询效率。
- 索引按列分类:单列索引、联合索引
- 索引类型:normal正常、spatial、unique唯一索引(空)、主键索引(非空)、fulltext全文索引(大文本字段、对于中文需要分词效果不佳、替代ES)
- 索引方法:B+树,hash索引
索引的数据结构
-
二分查找的链表结构:二叉查找树。
左子树的节点小于父节点,右子树的节点大于父节点。二叉树存在极端情况,当所有的节点都大于父节点的时候,二叉树会退化成为链表结构。
-
平衡二叉树(AVL Three)
左右子树的深度差绝对值不能超过1。
左左形->右旋,右右形->左旋。
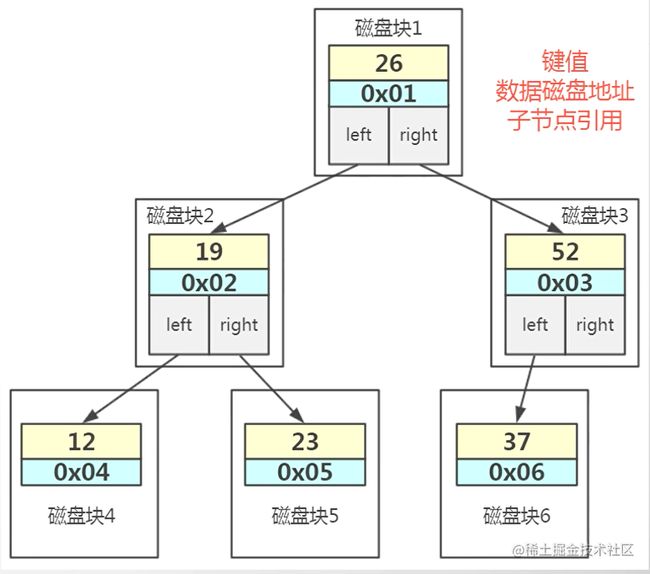
- 多路平衡搜索树(B树)
通过分裂与合并来保持平衡,这个分裂合并就是innodb页的分裂合并。
如果键是无序的,那么存储磁盘的时候可能导致碎片。所以身份证
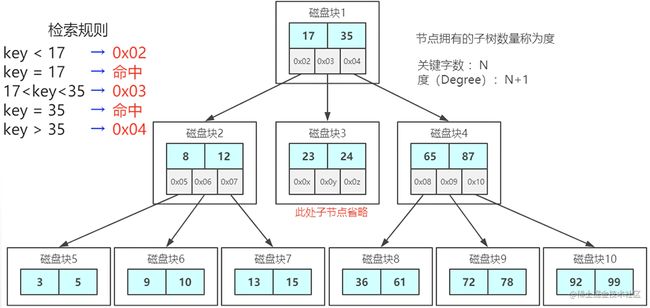
4. B+树 加强版多路平衡查找树
所有数据存放到叶子节点,叶子节点与叶子节点之间有双向指针形成链表结构。
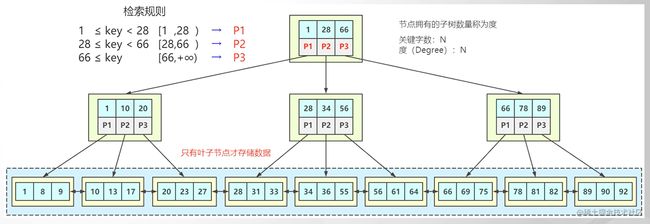
优势:
- B树解决了AVL树一个节点没有存满数据导致深度过深的问题。
- 扫库、扫表性能更强
- IO次数更少。磁盘读写能力更强
- 排序能力更强
- 效率更加稳定
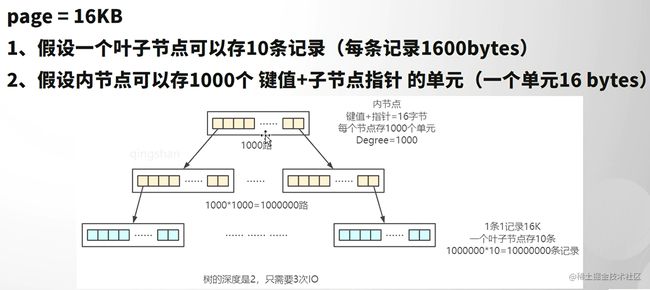
为什么MySQL不用红黑树来作为索引数据结构?红黑树的目的是最大深度不超过最小深度的2倍。红黑树不够平衡。不适用于磁盘数据结构。可以防止内存。
- 节点分为红色或黑色。
- 根节点必须是黑色。
- 叶子节点都是黑色的NULL节点。
- 红色节点的两个子节点都是黑色(不允许两个相邻的红色节点)。
- 从任意节点出发,到达每个叶子节点的路径中包含相同数量的黑色节点。
5. Hash索引 时间复杂度永远是O(1)
查询快。经过hash的数据本质上是无序的。所以比较数值比较耗时。Hash碰撞不可避免。
这种索引类型是不可以在InnoDB中使用的。但是可以在其他引擎使用。比如memory引擎。
不同存储引擎中索引的实践
MyIsam (索引没有主次之分、都存放在MYI文件)
主键索引

其他索引

InnoDB(数据即索引、索引即数据)
索引和数据存放在一个文件中。其B+树的叶子节点直接存放数据。
主键索引——聚集索引
叶子节点存储数据
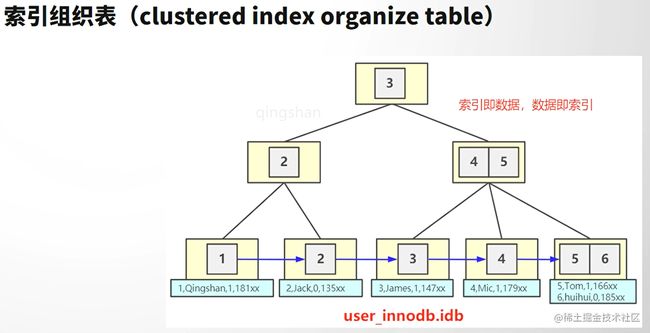
聚集索引
如果索引键值的顺序,与数据行的物理存储顺序一致,则成为聚集索引。
其他索引
叶子节点存储主键。
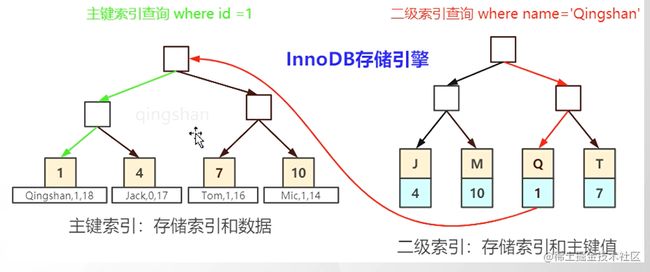
问题:为什么在二级索引上面存储的是数据的主键,而不是地址?
由于增删数据,B+树的分裂合并,地址是会改变的。
回表:查询到二级索引后,还要根据主键去表里面查询数据。图中最长的红线就是表示回表操作。
没有主键的情况?
官方回答:MySQL :: MySQL 5.7 Reference Manual :: 14.6.2.1 Clustered and Secondary Indexes
如果有主键索引,就使用主键索引。如果没有主键索引,就使用非空的唯一索引。如果没有合适的主键和唯一索引,就使用隐藏的rowID来当作索引。
// 但是我在这里查询的时候,好像提示以下错误信息:
// 1054 - Unknown column '_rowid' in 'field list'
select _rowid from test ;
这里找到了解释:https://blog.csdn.net/u011196295/article/details/88030451
当创建表时没有显示定义主键时.
- 首先判断表中是否有非空的整形唯一索引,如果有,则该列为主键(这时候可以使用 select _rowid from table 查询到主键列).
- 如果没有符合条件的则会自动创建一个6字节的主键(该主键是查不到的).
索引的创建和使用原则
索引越多越好么?
不是的。索引是会占用磁盘空间,以空间换时间。
列的离散度:count(distinct(column_name)):count(*)
gender和phone哪个离散度越高?phone离散度高。
所以不需要在离散度很低的键上面去建立索引。因为走索引会有回表操作,反而降低了性能。
联合索引的最左匹配原则
联合索引必须从第一个字段开始,不能中断。建议把查询最多的放到左侧。
alter table user_innodb add index comidx_name_phone(username,phone);
EXPLAIN select * from user_innodb t where t.phone = '13603108202' and t.username='huathy'; -- 使用索引
EXPLAIN select * from user_innodb t where t.username='huathy' and t.phone = '13603108202'; -- 使用索引
EXPLAIN select * from user_innodb t where t.username='huathy'; -- 使用索引
EXPLAIN select * from user_innodb t where t.phone = '13603108202'; -- 不使用索引

使用场景:
对于身份证号和考号这种必须要两个同时来检索的数据,可以使用联合索引。
冗余索引
有了上面的索引,我们是否有必要再为上面的查询建立一个这样的索引。不必要,索引冗余。
select * from user_innodb t where t.username='huathy';
alter table user_innodb add index idx_user_innodb_name(username);
覆盖索引
如果查询的列已经包含在了用到的索引中,那么就无需回表操作。这就称为覆盖索引。覆盖索引是使用索引的一种情况。
如何判断是否使用覆盖索引:在Extra中如果是Using Index表示使用了覆盖索引。
EXPLAIN select username,phone from user_innodb t where t.username='huathy'; -- 使用覆盖索引
EXPLAIN select username from user_innodb t where t.username='huathy' and t.phone = '13603108202'; -- 使用覆盖索引
EXPLAIN select username from user_innodb t where t.phone = '13603108202'; -- 使用覆盖索引
EXPLAIN select * from user_innodb t where t.username='huathy'; -- 不使用覆盖索引,不得不回表操作
索引条件下推(ICP)
innoDB自动开启,自动优化。
索引是在存储引擎实现的,存储引擎负责存储数据,数据的过滤、计算是在服务层实现的。如果可以根据索引查询,那么效率更高。将在本存储引擎中无法过滤的条件,先在存储引擎过滤一遍。这个动作就是索引条件下推。
如何判断是否使用了索引条件下推:在执行计划的Extra中存在Using index condition表示使用了索引条件下推。index condition全称:Index condition pushing down。
-- 创建员工表
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB ;
-- 在姓、名列上加上索引
alter table employees add index idx_lastname_firstname(last_name,first_name);
-- 进行查询
EXPLAIN SELECT * FROM employees t WHERE t.last_name = 'Wu' AND t.first_name like '%x'
-- 可以看到Extra中Using index condition表示用到了索引条件下推。
-- 查看操作开关是否开启索引条件下推
show global variables like '%optimizer_switch%';
-- index_condition_pushdown=on
-- 关闭索引条件下推
set optimizer_switch = 'index_condition_pushdown=off'
-- 再次查看是否使用了索引条件下推
EXPLAIN SELECT * FROM employees t WHERE t.last_name = 'Wu' AND t.first_name like '%x'
-- 可以看到返回 Using Where 表示在server层过滤
以上的查询方式,查询流程如下
- 如果不进行索引下推的流程:
二级索引检索数据 --回表–> 在主键索引叶子节点拿到完整记录 --> Server层过滤数据(不符合like条件的N条记录,需要server层自己过滤) - 进行索引下推的查询流程:二级索引检索数据 --> 过滤二级索引 Wu,x --回表–> 在主键索引叶子节点获取到完整记录 --> 返回给Server层(符合like条件的N条记录,不需要server层过滤)
建立索引的原则:
- 在用于where判断、order排序、join链接、group by分组字段上创建索引。
- 索引个数不宜过多。
- 区分度底的字段(列的离散度底),不需要建索引。
- 频繁更新的值,不要作为主键或索引。
- 不建议用无序的值(身份证、UUID)作为索引。会引起B+树大量结构调整,消耗计算性能。
- 复合索引,将离散度高的列放在前面。
- 常见符合索引,而不是修改单列索引。
- 过长的字段,创建前缀索引。
前缀索引
一些文本过长,我们只需要通过前缀来匹配,可以截取字串使用前缀索引。文本过长,占用存储空间,太短则没有区分度。这里就需要计算合适的长度。
-- 前缀索引:
CREATE TABLE `pre_test` (
`content` varchar(20) DEFAULT NULL,
KEY `pre_idx` (`content`(6))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
使用索引的原则
什么时候用不到索引
- 索引列上使用函数(replace、substr、concat、sum、count、avg)、表达式
- 字符串不加引号,出现隐式转换。
- like条件前面加了%。违反了最左匹配原则。当然索引条件下推的情况除外。
- 负向查询的情况无法确定:与优化器版本、数据库版本等相关
<>、!=、not in、not exists
优化器
- 基于成本的优化器(MySQL采用):IO、CPU
- 基于规则的优化器(Oracle早期版本):