使用pd.cut进行分箱操作
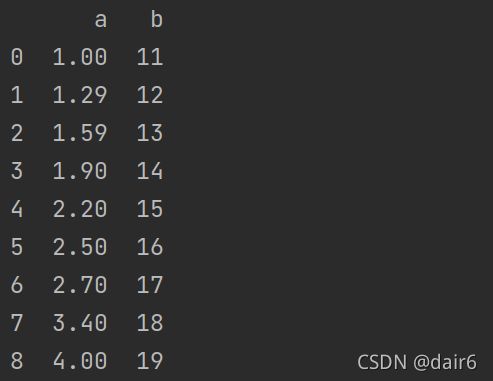
1.表格
2.需求
对表格中,a列下所有的数据进行分箱处理,使得每个箱子中出现的a的数值个数是一样的
3.代码如下
def test():
df = pd.DataFrame({'a':[1.0,1.29,1.59,1.9,2.2,2.5,2.7,3.4,4.0],'b':[11,12,13,14,15,16,17,18,19]})
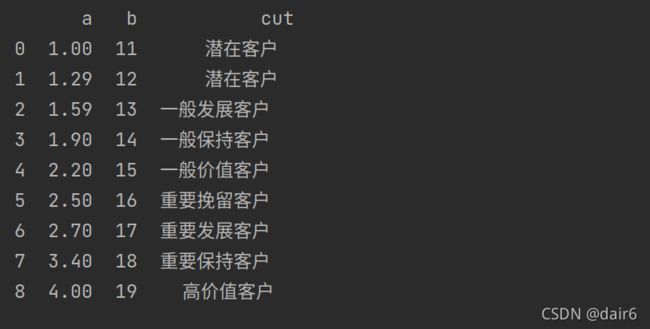
label = ['潜在客户', '一般发展客户', '一般保持客户', '一般价值客户', '重要挽留客户', '重要发展客户', '重要保持客户', '高价值客户']
df_bins = df['a'].describe([0.125,0.25,0.375,0.5,0.625,0.75,0.875,1]) # 求分位数,分位数间隔为0.125,describe中参数范围[0,1]
bin = [0,df_bins['12.5%'],df_bins['25%'],df_bins['37.5%'],df_bins['50%'],df_bins['62.5%'],df_bins['75%'],df_bins['87.5%'],df_bins['100%']]
print(df_bins)
print(bin)
df['cut'] = pd.cut(df['a'],bins=bin,labels=label)
print(df)
4.原理
(1)pd.cut
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’, ordered=True)[source]¶
官方文档:当您需要将数据值分段和排序到 bin 中时,请使用cut。此函数对于从连续变量到分类变量也很有用。例如,cut可以将年龄转换为年龄范围的组。支持分箱成相等数量的箱,或预先指定的箱阵列。
参数解释如下:
x :要分箱的一维数组。
bins:类型如果是整数,表示将一维数组x,分为等宽的bins个区间范围
如果是列表,比如说bins = [0,2,4,6],则表示将一维数组x按照数值大小,分别放到0~2,2~4~6三个箱体之中
因为是三个箱体,所以labels中标签的数 量,即每一个箱体的名字,必须有且只有3个,每个箱体对应一个命名
IntervalIndex :定义要使用的确切 bin。请注意,bin 的IntervalIndex必须不重叠。
right:默认为 True,即箱体范围中,右侧为闭区间,比如(0,2],(2,4],(4,6]
labels:类型为数组,默认无,指定返回的 bins 的标签。必须与生成的 bin 长度相同。如果为 False,则仅返回 bin 的整数指示符。当bins是 IntervalIndex时,将忽 略此参数。如果为 True,则引发错误。当ordered=False 时,必须提供标签。
retbins:bool值,默认为 False,是否归还垃圾箱。当 bins 作为标量提供时很有用。retbins=True会返回分界值
precision:整数,默认 3,存储和显示 bin 标签的精度。
include_lowest:bool值,默认为 False,第一个间隔是否应该包含在左侧。默认为(0,2],为True时,分箱包括左侧,结果为[0,2]
duplicates:{default 'raise', 'drop'},可选,如果 bin 边缘不唯一,则引发 ValueError 或删除非唯一值。
ordered:bool值,默认为 True
标签是否有序。适用于返回类型 Categorical 和 Series(使用 Categorical dtype)。如果为 True,则会对结果分类进行排序。如果为 False,则生成的分类将是无序的(必须提供标签)。