Spark SQL实战(07)-Data Sources
1 概述
Spark SQL通过DataFrame接口支持对多种数据源进行操作。
DataFrame可使用关系型变换进行操作,也可用于创建临时视图。将DataFrame注册为临时视图可以让你对其数据运行SQL查询。
本节介绍使用Spark数据源加载和保存数据的一般方法,并进一步介绍可用于内置数据源的特定选项。
数据源关键操作:
- load
- save
2 大数据作业基本流程
input 业务逻辑 output
不管是使用MR/Hive/Spark/Flink/Storm。
Spark能处理多种数据源的数据,而且这些数据源可以是在不同地方:
- file/HDFS/S3/OSS/COS/RDBMS
- json/ORC/Parquet/JDBC
object DataSourceApp {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local").getOrCreate()
text(spark)
// json(spark)
// common(spark)
// parquet(spark)
// convert(spark)
// jdbc(spark)
jdbc2(spark)
spark.stop()
}
}
3 text数据源读写
读取文本文件的 API,SparkSession.read.text()
参数:
path:读取文本文件的路径。可以是单个文件、文件夹或者包含通配符的文件路径。wholetext:如果为 True,则将整个文件读取为一条记录;否则将每行读取为一条记录。lineSep:如果指定,则使用指定的字符串作为行分隔符。pathGlobFilter:用于筛选文件的通配符模式。recursiveFileLookup:是否递归查找子目录中的文件。allowNonExistingFiles:是否允许读取不存在的文件。allowEmptyFiles:是否允许读取空文件。
返回一个 DataFrame 对象,其中每行是文本文件中的一条记录。
def text(spark: SparkSession): Unit = {
import spark.implicits._
val textDF: DataFrame = spark.read.text(
"/Users/javaedge/Downloads/sparksql-train/data/people.txt")
val result: Dataset[(String, String)] = textDF.map(x => {
val splits: Array[String] = x.getString(0).split(",")
(splits(0).trim, splits(1).trim)
})
编译无问题,运行时报错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 2 columns.;
思考下,如何使用text方式,输出多列的值?
修正后
val result: Dataset[String] = textDF.map(x => {
val splits: Array[String] = x.getString(0).split(",")
splits(0).trim
})
result.write.text("out")
继续报错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: path file:/Users/javaedge/Downloads/sparksql-train/out already exists.;
回想Hadoop中MapReduce的输出:
- 第一次0K
- 第二次也会报错输出目录已存在
这关系到 Spark 中的 mode
SaveMode
Spark SQL中,使用DataFrame或Dataset的write方法将数据写入外部存储系统时,使用“SaveMode”参数指定如何处理已存在的数据。
SaveMode有四种取值:
- SaveMode.ErrorIfExists:如果目标路径已经存在,则会引发异常
- SaveMode.Append:将数据追加到现有数据
- SaveMode.Overwrite:覆盖现有数据
- SaveMode.Ignore:若目标路径已经存在,则不执行任何操作
所以,修正如下:
result.write.mode(SaveMode.overwrite).text("out")
4 JSON 数据源
// JSON
def json(spark: SparkSession): Unit = {
import spark.implicits._
val jsonDF: DataFrame = spark.read.json(
"/Users/javaedge/Downloads/sparksql-train/data/people.json")
jsonDF.show()
// 只要age>20的数据
jsonDF.filter("age > 20")
.select("name")
.write.mode(SaveMode.Overwrite).json("out")
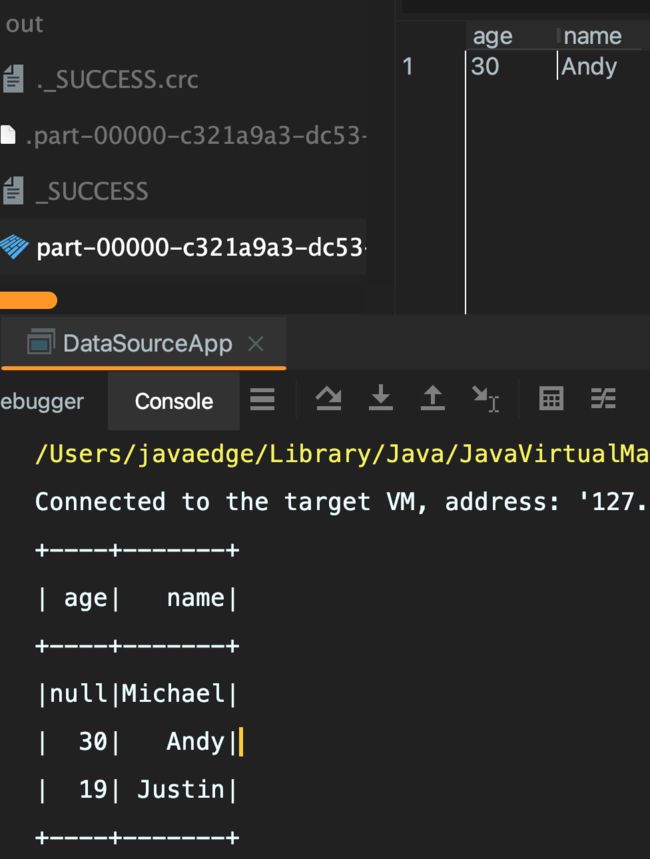
output:
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
嵌套 JSON
// 嵌套 JSON
val jsonDF2: DataFrame = spark.read.json(
"/Users/javaedge/Downloads/sparksql-train/data/people2.json")
jsonDF2.show()
jsonDF2.select($"name",
$"age",
$"info.work".as("work"),
$"info.home".as("home"))
.write.mode("overwrite")
.json("out")
output:
+---+-------------------+----+
|age| info|name|
+---+-------------------+----+
| 30|[shenzhen, beijing]| PK|
+---+-------------------+----+
5 标准写法
// 标准API写法
private def common(spark: SparkSession): Unit = {
import spark.implicits._
val textDF: DataFrame = spark.read.format("text").load(
"/Users/javaedge/Downloads/sparksql-train/data/people.txt")
val jsonDF: DataFrame = spark.read.format("json").load(
"/Users/javaedge/Downloads/sparksql-train/data/people.json")
textDF.show()
println("~~~~~~~~")
jsonDF.show()
jsonDF.write.format("json").mode("overwrite").save("out")
}
output:
+-----------+
| value|
+-----------+
|Michael, 29|
| Andy, 30|
| Justin, 19|
+-----------+
~~~~~~~~
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
6 Parquet数据源
6.1 简介
一种列式存储格式,在大数据环境中高效地存储和处理数据。由Hadoop生态系统中的Apache Parquet项目开发的。
6.2 设计目标
支持高效的列式存储和压缩,并提供高性能的读/写能力,以便处理大规模结构化数据。
Parquet可以与许多不同的计算框架一起使用,如Apache Hadoop、Apache Spark、Apache Hive等,因此广泛用于各种大数据应用程序中。
6.3 优点
高性能、节省存储空间、支持多种编程语言和数据类型、易于集成和扩展等。
private def parquet(spark: SparkSession): Unit = {
import spark.implicits._
val parquetDF: DataFrame = spark.read.parquet(
"/Users/javaedge/Downloads/sparksql-train/data/users.parquet")
parquetDF.printSchema()
parquetDF.show()
parquetDF.select("name", "favorite_numbers")
.write.mode("overwrite")
.option("compression", "none")
.parquet("out")
output:
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
7convert
方便从一种数据源写到另一种数据源。
存储类型转换:JSON==>Parquet
def convert(spark: SparkSession): Unit = {
import spark.implicits._
val jsonDF: DataFrame = spark.read.format("json")
.load("/Users/javaedge/Downloads/sparksql-train/data/people.json")
jsonDF.show()
jsonDF.filter("age>20")
.write.format("parquet").mode(SaveMode.Overwrite).save("out")
8 JDBC
有些数据是在MySQL,使用Spark处理,肯定要通过Spark读出MySQL的数据。
数据源是text/json,通过Spark处理完后,要将统计结果写入MySQL。
查 DB
写法一
def jdbc(spark: SparkSession): Unit = {
import spark.implicits._
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306")
.option("dbtable", "smartrm_monolith.order")
.option("user", "root")
.option("password", "root")
.load()
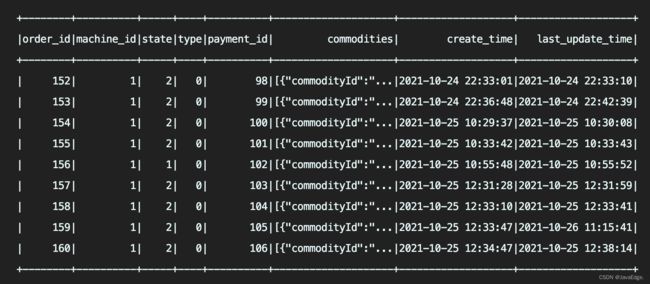
jdbcDF.filter($"order_id" > 150).show(100)
}
写法二
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")
val jdbcDF2: DataFrame = spark.read
.jdbc(url, srcTable, connectionProperties)
jdbcDF2.filter($"order_id" > 100)
写 DB
val connProps = new Properties()
connProps.put("user", "root")
connProps.put("password", "root")
val jdbcDF: DataFrame = spark.read.jdbc(url, srcTable, connProps)
jdbcDF.filter($"order_id" > 100)
.write.jdbc(url, "smartrm_monolith.order_bak", connProps)
若 目标表不存在,会自动帮你创建:

统一配置管理
如何将那么多数据源配置参数统一管理呢?
先引入依赖:
<dependency>
<groupId>com.typesafegroupId>
<artifactId>configartifactId>
<version>1.3.3version>
dependency>
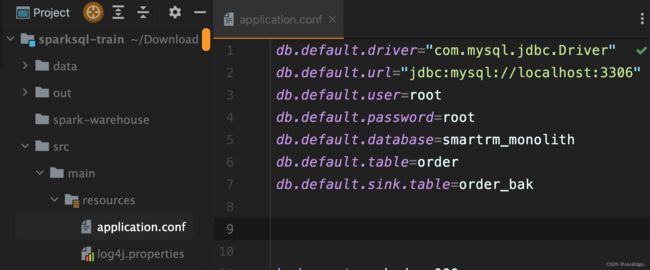
配置文件:
读配置的程序:
package com.javaedge.bigdata.chapter05
import com.typesafe.config.{Config, ConfigFactory}
object ParamsApp {
def main(args: Array[String]): Unit = {
val config: Config = ConfigFactory.load()
val url: String = config.getString("db.default.url")
println(url)
}
}
private def jdbcConfig(spark: SparkSession): Unit = {
import spark.implicits._
val config = ConfigFactory.load()
val url = config.getString("db.default.url")
val user = config.getString("db.default.user")
val password = config.getString("db.default.password")
val driver = config.getString("db.default.driver")
val database = config.getString("db.default.database")
val table = config.getString("db.default.table")
val sinkTable = config.getString("db.default.sink.table")
val connectionProperties = new Properties()
connectionProperties.put("user", user)
connectionProperties.put("password", password)
val jdbcDF: DataFrame = spark.read.jdbc(url, s"$database.$table", connectionProperties)
jdbcDF.filter($"order_id" > 100).show()
写到新表:
jdbcDF.filter($"order_id" > 158)
.write.jdbc(url, s"$database.$sinkTable", connectionProperties)
