(爬取猫眼电影TOP100的电影信息(含图片、评分等))
爬取猫眼电影TOP100的电影信息(含图片、评分等)
- 让我们直接进入正题
-
- 1.导入需要的库
- 2.获取页面
- 3.分析页面
- 4.保存文件
- 全部代码
让我们直接进入正题
对猫眼电影的网站进行分析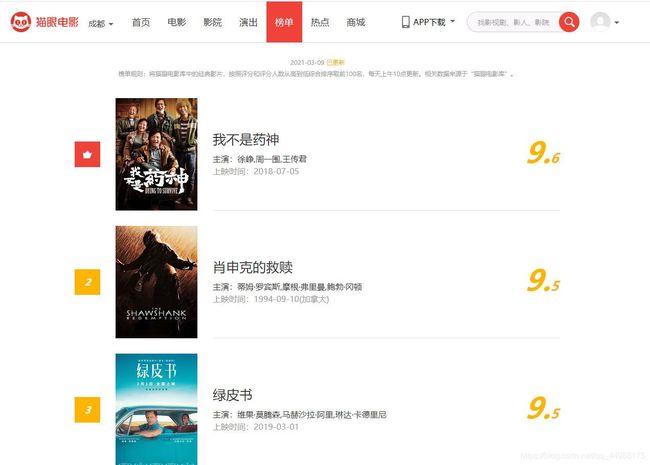
其链接为:https://maoyan.com/board/4?
1.导入需要的库
本次爬取任务主要依赖于python的requests、beautifulsoup等相关库,如果没有,可以使用pip命令安装
import requests
import re
import time
from bs4 import BeautifulSoup
import pandas as pd
2.获取页面
使用requests的get方法拿到相关的html内容:
def get_page(url,headers):
html=requests.get(url,headers=headers)
if html.status_code==200:
html.encoding=html.apparent_encoding
return html.text
else:
return None
3.分析页面
先用bs解析页面,再使用re库正则匹配需要的内容def get_data():
#创建空列表存贮相关的内容
name_box,link_box,actor_box,time_box,score_box=[],[],[],[],[]
for i in range(10):
#设定初始url
url_score='https://maoyan.com/board/4?'
#设定headers,url和headers两个参数用于调用上面的get_page()
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
}
#观察目标链接,设定每个单独页的url
url=url_score+'offset='+str(i*10)
#调用get_page()
html=get_page(url,headers)
#使用bs解析html的内容
bs=BeautifulSoup(html,'html.parser')
#其中图片链接被放在‘image-link’的标签里,电影名称被放在‘name’的标签里
pic=bs.find_all(class_='image-link')
name=bs.find_all(class_='name')
#正则表达式匹配
movies=re.compile('data-src="(.*?)"/>')
pic_links=re.findall(movies,str(pic))
for link in pic_links:
link=str(link)
link_box.append(link)
name_list=re.findall('href="/films/.*?">(.*?)',str(name))
for name in name_list:
name_box.append(name)
actor=bs.find_all(class_='star')
actors_list=re.sub('/n','',str(actor))
actors_list=re.findall(''
,str(actor),re.S)
for actor in actors_list:
re.sub('[\n]', '', actor)
actor_box.append(actor)
releasetime=bs.find_all(class_='releasetime')
time_list=re.findall('class="releasetime">(.*?)',str(releasetime))
for times in time_list:
time_box.append(time)
score=bs.find_all(class_='score')
integers=re.findall('(.*?)',str(score))
fractions=re.findall('(.*?)',str(score))
for j in range(len(integers)):
score=str(integers[j])+str(fractions[j])
score_box.append(score)
print('第{}页爬取成功'.format(i+1))
print('{}/10'.format(i+1))
#设置访问间隔,防止短时间多次访问导致出现验证的情况
time.sleep(1)
print('------------')
#返回列表里的内容
return name_box,link_box,actor_box,time_box,score_box
4.保存文件
def main():
#调用get_data(),返回几个列表
name_box,link_box,actor_box,time_box,score_box=get_data()
#利用pandas中的to_csv方法存放数据,也可以用to_excel方法
datas=pd.DataFrame({'电影':name_box,'链接':link_box,'演员':actor_box,'评分':score_box})
try:
#设置本地保存路径
datas.to_csv('机器学习\爬虫\maoyan_TOP100.csv',encoding='utf_8_sig')
print('保存成功')
except:
print('保存失败')
try:
for link in link_box:
s=requests.get(link).content
#电影封面图片爬取
with open('机器学习\爬虫\pic\img{:s}.jpg'.format(str(time.time())),'wb') as f:
f.write(s)
print('爬取图片成功')
except:
print("爬取失败")
全部代码
import requests
import re
import time
from bs4 import BeautifulSoup
import pandas as pd
#定义函数,url表示目标链接,header表示请求头
def get_page(url,headers):
html=requests.get(url,headers=headers)
if html.status_code==200:
html.encoding=html.apparent_encoding
return html.text
else:
return None
def get_data():
#创建空列表存贮相关的内容
name_box,link_box,actor_box,time_box,score_box=[],[],[],[],[]
for i in range(10):
#设定初始url
url_score='https://maoyan.com/board/4?'
#设定headers,url和headers两个参数用于调用上面的get_page()
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
}
#观察目标链接,设定每个单独页的url
url=url_score+'offset='+str(i*10)
#调用get_page()
html=get_page(url,headers)
#使用bs解析html的内容
bs=BeautifulSoup(html,'html.parser')
#其中图片链接被放在‘image-link’的标签里,电影名称被放在‘name’的标签里
pic=bs.find_all(class_='image-link')
name=bs.find_all(class_='name')
#正则表达式匹配
movies=re.compile('data-src="(.*?)"/>')
pic_links=re.findall(movies,str(pic))
for link in pic_links:
link=str(link)
link_box.append(link)
name_list=re.findall('href="/films/.*?">(.*?)',str(name))
for name in name_list:
name_box.append(name)
actor=bs.find_all(class_='star')
actors_list=re.sub('/n','',str(actor))
actors_list=re.findall(''
,str(actor),re.S)
for actor in actors_list:
re.sub('[\n]', '', actor)
actor_box.append(actor)
releasetime=bs.find_all(class_='releasetime')
time_list=re.findall('class="releasetime">(.*?)',str(releasetime))
for times in time_list:
time_box.append(time)
score=bs.find_all(class_='score')
integers=re.findall('(.*?)',str(score))
fractions=re.findall('(.*?)',str(score))
for j in range(len(integers)):
score=str(integers[j])+str(fractions[j])
score_box.append(score)
print('第{}页爬取成功'.format(i+1))
print('{}/10'.format(i+1))
#设置访问间隔,防止短时间多次访问导致出现验证的情况
time.sleep(1)
print('------------')
#返回列表里的内容
return name_box,link_box,actor_box,time_box,score_box
def main():
#调用get_data(),返回几个列表
name_box,link_box,actor_box,time_box,score_box=get_data()
#利用pandas中的to_csv方法存放数据,也可以用to_excel方法
datas=pd.DataFrame({'电影':name_box,'链接':link_box,'演员':actor_box,'评分':score_box})
try:
#设置本地保存路径
datas.to_csv('机器学习\爬虫\maoyan_TOP100.csv',encoding='utf_8_sig')
print('保存成功')
except:
print('保存失败')
try:
for link in link_box:
s=requests.get(link).content
#电影封面图片爬取
with open('机器学习\爬虫\pic\img{:s}.jpg'.format(str(time.time())),'wb') as f:
f.write(s)
print('爬取图片成功')
except:
print("爬取失败")
if __name__ == "__main__":
main()