ODI知识模块
http://trailblizer.blog.163.com/blog/static/5963036420102313745674/
ODI知识模块
·KM是通用的,它们不引用具体的物理对象。
·KM可用来对影响进行分析
·KM不能像过程一样被执行,他们需要从接口、数据存储和模型中得到元数据
IKM SQL Incremental Update
在sql兼容的目标表在增量更新模式下整合数据,这个知识模型创建临时中间区来存储数据流。不适合于大数据量。使用这个知识模型的时候中转区要与目标数据服务器在同一个地方。
IKM SQL to SQL Append
使用这个模型的时候,中转区与目标区必须不同在一个服务器上。
IKM Oracle Incremental Update
在oracle目标表中按照增量模式整合数据。这个知识模型创建一个临时区表来存储数据流。它与目标表中的内容对比,来判断哪些记录需要插入、哪些需要更新。这个知识模型适合大量数据处理。使用这个知识模型的时候中转区要与目标数据服务器在同一个地方。
Reverse-engineering Knowledge Modules (RKM)
RKM最主要的功能为对一个模型进行反向操作。RKM负责连接应用系统并把结果传送到ODI资料库。这些元数据被暂时写入SNP_REV_xx表,然后RKM调用ODI的API从这些表中读取并写到ODI的工作资料库中。典型RKM的工作步骤:
1.使用OdiReverseResetTable命令对上次执行中在SNP_REV_xx表中的数据进行清除
2.从SNP_REV_SUB_MODEL, SNP_REV_TABLE, SNP_REV_COL,SNP_REV_KEY, SNP_REV_KEY_COL, SNP_REV_JOIN, SNP_REV_JOIN_COL,
SNP_REV_COND 表中.检索子模型、数据存储、列、外键、主键等。
3.通过OdiReverseSetMetaData命令更新工作资料库中的模型。
Check Knowledge Modules (CKM)
CKM负责使用定义好的一致约束来对一组数据集做检查。CKM用来保持数据质量的完整性,有下列两种使用方式:
1.检查已有数据的一致性。设置STATIC_CONTROL为"YES";①检查目前在数据存储中的数据,对转换过程不关心;②接口中的目标数据存储在加载流数据后被检查;
2.在数据写入目标表前对数据做检查。FLOW_CONTROL;记录读取目标表的约束,检查I$表把违反约束的记录删掉。
CKM将错误信息存放在E$开头的表中。典型步骤:
1.在中转区创建以E$开头的错误表;
2.把检查出的错误记录放到E$表中;
Loading Knowledge Modules (LKM)
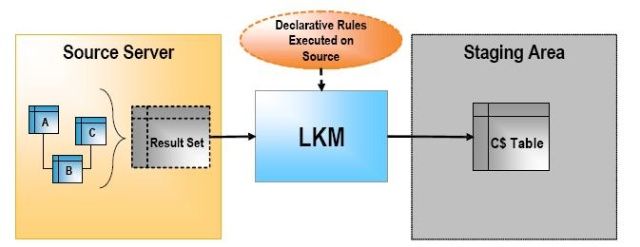
LKM负责从远端服务器装载数据到中转区。接口中使用,把加载的数据放到C$表中。步骤:
1.创建以C$开头的表,用来存放从源服务器加载的记录;
2.LKM保持一组在源端经过适当转换后的记录;
3.LKM把记录加载到C$表中。
如果数据存储和中转区在相同的数据服务器上时,不需要LKM。
Integration Knowledge Modules (IKM)
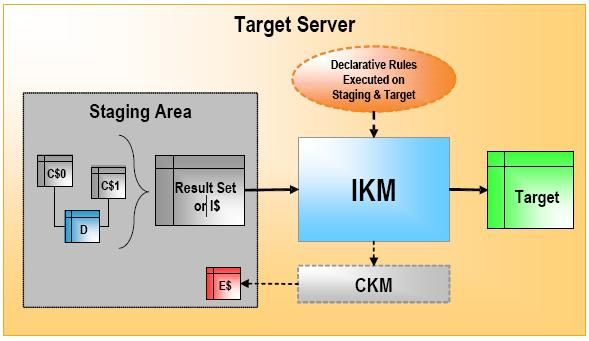
IKM负责把最终数据写入目标表中,每个接口只使用一个IKM。做这一步的时候假定源数据已经通过LKM被加载到中转区的临时表(C$)中了。IKM把数据装载到以I$开头的临时表。
当中转区与目标服务器在一起时:
1.从C$表中检索数据;
2.如果需要flow check,IKM调用CKM来隔离错误记录,清理I$表;
3.从I$表把记录写到目标表;
4.把I$表中记录删除
这种KM只工作在目标服务器上,对大数据量的处理效率高。
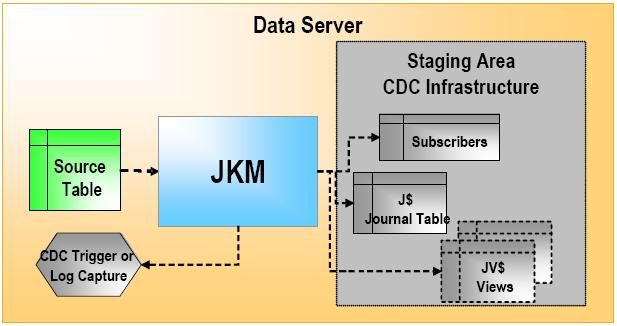
Journalizing Knowledge Modules (JKM)