C++:二叉搜索树
⭐前言:学习二叉搜索树,是我们学好map和set的前提,因为二叉搜索树是map和set的特性。因此本篇文章意在努力将二叉搜索树相关的内容较完善地写出来!
二叉搜索树的介绍
二叉搜索树(BST, Binary Search Tree)又叫做二叉排序树,它可以是一颗空树,其性质如下:
①若它的左子树不为空,则左子树上所有的节点的值都小于根节点的值
②若它的右子树不为空,则右子树上所有的节点的值都大于根节点的值
③它的左右子树也分是二叉搜索树
④成形的二叉搜索树一般不能用来修改数据。因为一旦修改了,就可能不再是二叉搜索树了。

对二叉搜索树的操作
1. 查找:
①一般查找某个数据,就先根节点的值比较,若是查找的数据val小于根节点,那就去左子树找,val大于根节点的值,那就去右子树找。
②最多查找高度次,走到到空,还没找到,这个值不存在。
2.插入:
①如果是一颗空树,那么直接新增节点,赋值给root指针
②不是空树,则按二叉搜索树的性质插入数据
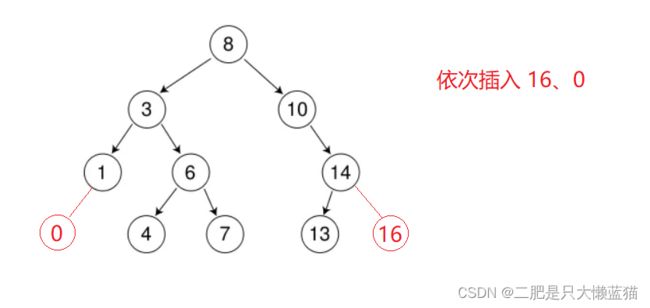
3.删除:
删除的情况就比较复杂,我们慢慢来看。
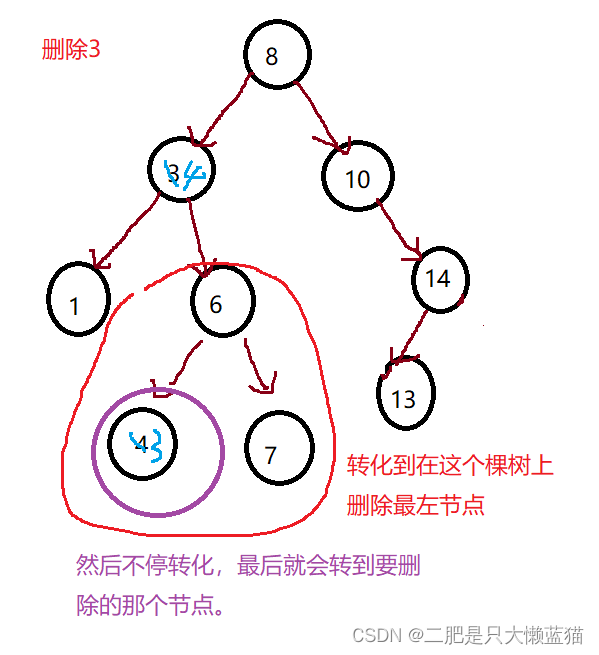
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
①要删除的节点无孩子结点。
操作:这种情况比较简单,删除该节点后,让该节点的父亲节点指向该节点的左孩子节点或右孩子节点。都可以,因为都是空指针。
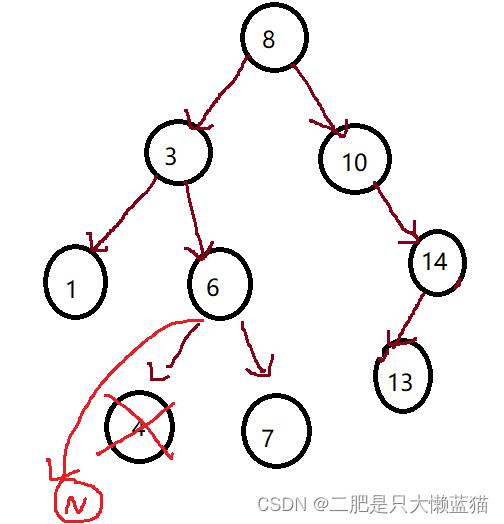
②要删除的节点只有左孩子节点.
操作:删除该节点后,让该节点的父亲节点指向该节点的左孩子节点
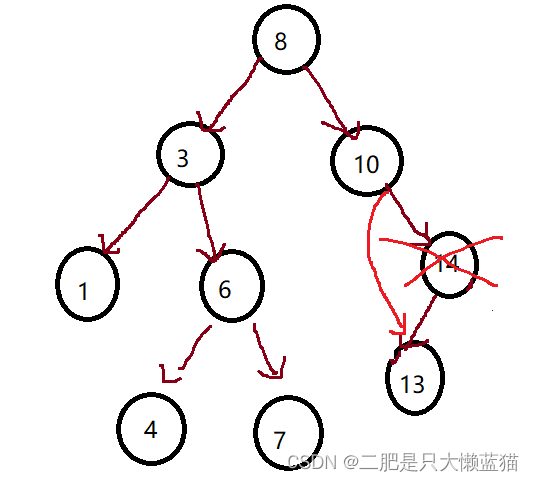
③要删除的节点只有右孩子节点
操作:删除该节点收,让该节点的父亲节点指向该节点的右孩子节点
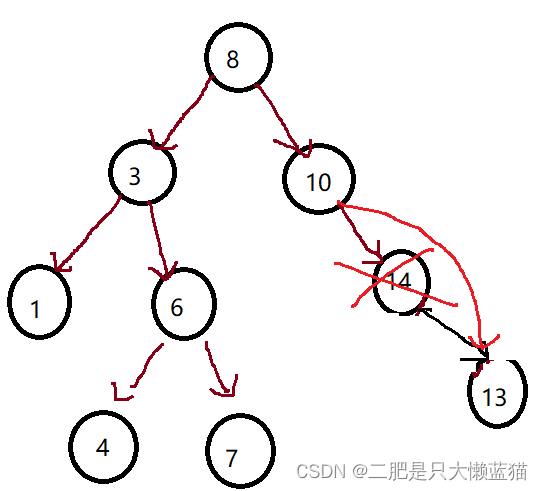
④要删除的节点有左右孩子。
第一种操作是替换法。
根据二叉搜索树的性质,右子树的值 > 根节点的值 > 左子树的值。因此,替换的意思是,重新选根,那么我们可以从左子树中选最大的那个来当新根,也可以从右子树中选最小的那个来当新根。这里我们使用右子树最小的那个来当新根。
当替换之后,我们就将这个节点删除,删除的时候需要注意,让其父亲节点指向它的右孩子,因为它可能还会带有右孩子。不可能是左孩子,如果是左孩子,那么寻找新根的行为还会往下,会找到最左,即最小的那个节点。
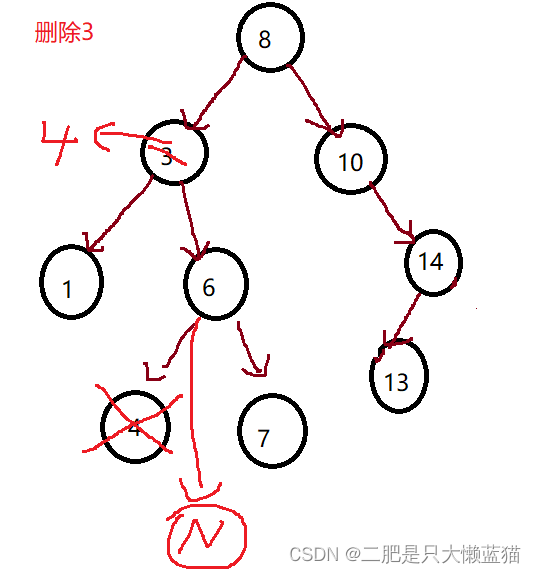
第二种操作是:使用交换法。将右子树最小的值,跟需要删除的节点的值交换。这也在删除之后就不会毁掉二叉搜索树的结构。然后转化到在右子树上删除节点。不过这种方法需要用到递归。
二叉搜索树的实现
这一步主要实现的是上面所提到的相关操作。
①先来创建节点。
template
struct BSTreeNode
{
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
BSTreeNode(const K& key)
:_key(key)
,_left(nullptr)
,_right(nullptr)
{}
}; 然后是框架的准备:
template
class BSTree
{
typedef BSTreeNode Node;
private:
Node* _root = nullptr;
};
} ②插入操作
非递归版:
先判断是否为空树,如果是,直接插入。如果不是空树,那么需要两个指针,一个是cur指针,用来找插入的位置,一个是parent指针,用来记录父节点,因为后面需要重新链接。
当发现树中已经有了相同的值,那么就直接返回false。
在链接新节点的时候,需要再重新判断一下这个节点的值是否大于父节点的值。
//非递归插入
bool Insert(const K& key)
{
//1.先判断是否为空树,如果是,直接插入
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//2.不是空树
Node* cur = _root;
Node* parent = cur;//用于记录父节点,删除后需要链接被删除节点的孩子节点
//开始找可以插入数据的位置
while (cur)
{
if (cur->_key < key)//插入的值比较大,则去右子树找
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)//插入的值比较小,则去左子树找
{
parent = cur;
cur = cur->_left;
}
else //如果发现已经有这个值了,那么直接返回false;
{
return false;
}
}
//找到可以插入的位置后
cur = new Node(key);
//链接操作,由于此时不知道cur来到的位置是左孩子还是右孩子,因此还需要再判断一次
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}递归版:
由于递归,需要用到私有成员变量_root,但私有成员变量不能暴露 出来。因此,这里选择私有插入操作的函数,在公有中额外写一个插入的函数用于调用它。
这里的递归,我认为它是一个点睛之笔,那就是Node*& root。对传入的节点的指针进行了引用!
对传入的节点的指针进行引用,意味着此时的root,是上一个root的左孩子或右孩子的别名,当此时的root到达了空指针,进行插入数据的操作后,就意味着是上一个root的左孩子或右孩子进行了插入数据!就不需要记录父节点来链接了,因为在插入数据的时候就已经链接成功了!
public:
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
private:
//注意这里的引用,这是这里的递归操作的点睛之笔
bool _InsertR(Node*& root, const K& key)
{
//老规矩,先判断是否为空树
if (root == nullptr)
{
root = new Node(key);
return true;
}
//不是空树,就去找位置
if (root->_key < key)
return _InsertR(root->_right, key);
else if (root->_key > key)
return _InsertR(root->_left, key);
else
return false;
}③删除操作
非递归版本
非递归的版本代码量比递归版本的多。
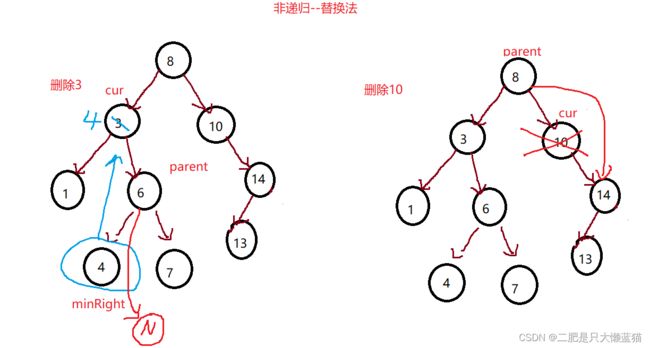
代码的思路是:①先找到要删除的节点。②然后判断这个要被删除的节点是如何的,是只有左子树,还是只有右子树,还是左右孩子都有。另外,叶子节点被包含在了前两个情况里面。③如果是左右孩子都有的节点,那么还需要找以这个被删除的节点为根,找它右子树的最小值,然后让这个值跟被删除的节点的值替换,此时在逻辑上,被替换掉的不仅仅是值,连要删除的节点也被替换掉了,被替换成这个右子树的最小值的节点了。④接着在链接的时候,需要判断被删除的节点是父节点的左孩子还是右孩子。
需要注意的额外情况是:被删除的节点可能是根节点。
//非递归
bool Erase(const K& key)
{
//用父节点来记录被删的节点的父节点
Node* parent = nullptr;
Node* cur = _root;
//先找要删除的节点
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cut = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else //找到了
{
//1.要删除的节点的左子树为空
//2.右子树为空
//3.左右都不为空,替换删除
//1.左子树为空--让父节点链接要删除节点的右子树
if (cur->_left == nullptr)
{
//还要判断一下要删除的节点是否为根节点
if (cur == root)
{
_root = cur->_right;
}
else //删除的节点不是根节点
{
//判断一下要删除的节点是父节点的左孩子还是右孩子
//如果是左孩子,那么就让父节点的左孩子指针链接被删除节点的右子树
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else//如果是右孩子,那么就让父节点的右孩子指针链接被删除节点的右子树
{
parent->_right = cur->_right;
}
}
delete cur;//最后删除节点
}
else if(cur->_right==nullptr)//右子树为空----让父节点链接被删除节点的左子树
{
if (root == cur)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
}
else//3.左右孩子都不为空---替换法
{
//要找到右子树的最小节点
Node* parent = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
parent = minRight;
minRight = minRight->_left;
}
//将根节点的值替换掉
cur->_key = minRight->_key;
//然后删除这个最小的节点
//如果它是父节点的左孩子,那就让父节点的左孩子的指针指向它的右孩子
//因为它已经是最左的那个了,没有左孩子了,可能会有右孩子
if (minRight == parent->_left)
{
parent->_left = minRight->_right;
}
else//右子树的最小节点,不一定是最左的节点。
{
parent->_right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}
递归的版本:
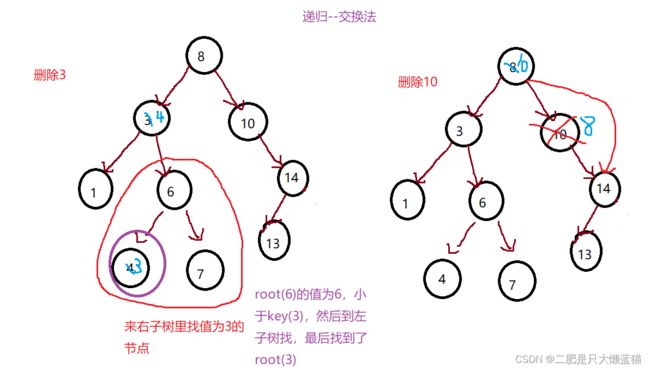
代码的思路是:①需要先判断树是否为空。②找要删除的节点。③找到后,判断这个节点是那种情况,然后进行链接。如果是左右都有孩子的节点,那么就使用交换法,让右子树最小值跟要删除的节点的值交换,此时原本要删除的那个节点,从物理上变成了原本的右子树的最小值的节点。然后通过递归,去右子树找这个节点。最后进行链接节点的右孩子或左孩子,最后删除。
public:
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
return _Erase(root->_right, key);
}
else if (root->_key > key)
{
return _Erase(root->_left, key);
}
else
{
Node* del = root;
if (root->_right == nullptr)
{
root = root->_left;
}
else if (root->_left == nullptr)
{
root = root->_right;
}
else//左右孩子都不为空---交换法
{
Node* minRight = root->_right;
while (minRight->_left)
{
minRight->_left;
}
//交换值
swap(root->_key, minRight->_key);
//交换后,此时原本要是删除的key,去到了minRight的节点上
//接下来进行递归,交给右子树去找这个节点
return _EraseR(root->_right, key);
}
delete del;
return true;
}
}
④查找
查找的操作很简单。
非递归版本:
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
return true;
}
return false;
}递归版本:
public:
bool FindR(const K& key)
{
return _FindR(_root, key);
}
private:
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
return _FindR(root->_right, key);
if (root->_key > key)
return _FindR(root->_left, key);
else
return true;
}⑤.中序遍历
中序遍历的顺序是左根右。学过简单数据结构中的二叉树的话,这里就洒洒水啦!
public:
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}⑥构造函数
不需要写什么构造函数,只需用初始化列表初始化一下私有成员变量_root即可。
BSTree()
:_root(nullptr)
{}⑦拷贝构造
写一个Copy函数,返回值是Node*,也就是返回节点的指针。先创建一个新的节点,赋值为拷贝目标的根的值,然后让其左孩子和右孩子递归,链接下一个值。
public:
BSTree(const BSTree& t)
{
_root = Copy(t._root);
}
private:
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newRoot = new Node(root->_key);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
} ⑧赋值
operator=()函数的话,不要传引用,然后交换一下_root即可。注意这里有些隐藏条件:this指针的_root必须初始化成空指针。
BSTree& operator=(BSTree t)
{
swap(_root, t._root);
return *this;
} ⑨析构函数
public:
~BSTree()
{
Destory(_root);
_root = nullptr;
}
private:
void Destory(Node* root)
{
if (root == nullptr)
return;
Destory(root->_left);
Destory(root->_right);
delete root;
}
二叉搜索树的应用
1.K模型
K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
用若干个单词(字典)组成一棵二叉搜索树, 然后在里面查找单词word,找到返回true,找不到返回false;
2.KV模型
KV模型:每一个关键码key,都有与之对应的值Value,即
只需在上面的代码的基础上,加上一个_value即可。
namespace KV
{
template
struct BSTreeNode
{
BSTreeNode* _left;
BSTreeNode* _right;
K _key;
V _value;
BSTreeNode(const K& key, const V& value)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
template
class BSTree
{
typedef BSTreeNode Node;
public:
bool Insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key, value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key, value);
if (parent->_key < key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
Node* Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return nullptr;
}
void Inorder()
{
_Inorder(_root);
}
void _Inorder(Node* root)
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_Inorder(root->_right);
}
private:
Node* _root = nullptr;
};
} 比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文
KV::BSTree dict;
dict.Insert("sort", "排序");
dict.Insert("string", "字符串");
dict.Insert("left", "左边");
dict.Insert("right", "右边");
string str;
while (cin >> str)
{
KV::BSTreeNode* ret = dict.Find(str);
if (ret)
{
cout << ret->_value << endl;
}
else
{
cout << "无此单词" << endl;
}
} 再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是
// 统计水果出现的次数
string arr[] = { "苹果", "西瓜", "香蕉", "草莓","苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
KV::BSTree countTree;
for (auto e : arr)
{
auto* ret = countTree.Find(e);
if (ret == nullptr)
{
countTree.Insert(e, 1);
}
else
{
ret->_value++;
}
}
countTree.Inorder(); 二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
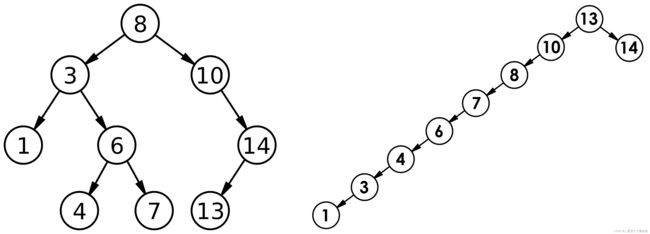
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),树是平衡的,则n个节点的二叉搜索树的高度为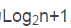 ,其查找效率为
,其查找效率为 ,近似于折半查找.其平均比较次数为:O(long(N))
,近似于折半查找.其平均比较次数为:O(long(N))
最差情况下,二叉搜索树退化为单支树(或者类似单支),深度达到N,其平均比较次数为:O(N)。